本記事は、Snowflake Advent Calendar 2021 の12日目です。
本記事の概要
2020年の6月に、当時、データ分析基盤が一才なかった現在所属企業(在シンガポール)に初のデータエンジニアとして入社し、データ分析基盤をスクラッチで構築することになりました。まずは BI とアドホック分析をやりたいとなり、データサイエンティストと二人三脚で小規模な BI システムを構築し、デプロイ周りも改善し、最終的にはデータウェアハウスとして Snowflake も導入しました。
本記事では、筆者の知識や経験の棚卸しと整理を目的に比較的小規模に始まったデータ分析基盤の特にデプロイ周りをどう改善したか紹介します。
なお、現在は、大手金融企業と合併し、先方のオンプレ環境の大規模な BI システム(利用者数百名)のマイグレをやっていますが、それはまた別の機会にノウハウを紹介しようと思います。
データ分析基盤(BI・アッドホック分析環境)の要件
入社してすぐにデータサイエンティストおよびボス(Head of Engineering)に聞いた社内の現状や要件は以下の通りでした。ここまで何もない現場は初めてだったので、非常に驚きましたが、逆に言えばどう作るかは自分で決めて良いので良い機会だなと思いました。
- データ分析基盤が存在しないのでデータが欲しい場合は、Operation 系の DB を直接参照するか、エンジニアがデータベースから抽出したデータをデータサイエンティストやアナリスト(インターン大学生)がローカルで Excel で集計している。
- これがかなり手間な作業なので、BIやアドホック分析に必要なデータを自動的に整備できる分析環境を作りたい。
- 社内外のデータソースから分析データベースにデータを自動的に集約する。頻度は日次でOK。
- データソースは、社内のトランザクションデータ、モバイルバックエンド(Firebases)、マーケティングSaaSツールのデータなど。
- データベースで必要な集計処理を行う。
- BI でKPIの可視化を行う。BI はデータサイエンティストが前職で使っていた Tableau を利用する。
- 当初は小規模にやりたい。
- データ規模が比較的小さいので、なるべくスモールスタートしたい。データベースは RDS を使っているので、RDS を使う。
- Redshift を使うほどの規模はないし、高コストなものは避ける。
分析データベースおよび BI の導入
データチームで協議した結果、当初は以下のような構成になりました。
- 社内でクラウドサービスとして AWS を使っていたので、同じく AWS を使う。
- データベースとしては RDS Aurora PostgreSQL を利用する。
- データ量が比較的小さいので、データウェアハウス製品を使う必要性がない。
- データベース内でバッチ処理でデータを投入する先のスキーマと、データアナリストが集計結果を入れるスキーマは別にした。誤って生データを壊してしまうトラブルを防ぐ。
- データエンジニアはデータのロードまでを担当し、データ集計はアナリストが担当する。
- BI としては Tableau Online (SaaS 版) を利用する。
- データサイエンティストが前職で Tableau を利用していた。
- Tableau のインフラを管理をする専任のインフラエンジニアがいないため、運用負荷の低い Online (SaaS 版)を選択した。
- データベースは VPC 内にあるため、同じ VPC に Tableau Bridge をデプロイし、定期的に Tableau Online へデータをアップロードした。
- データソースからの ETL は Airflow で自動化した。
- Airflow を選定したのは、前職・前々職で私が利用して、慣れていたため。
- Airflow クラスタは運用コスト低減のため、 ECS Fargate にデプロイした。
- Tableau Bridge と Tableau Online は本番環境のみ。
- ダッシュボードの動作確認に本番データが必要。
- 利用者が小規模なため、本番データが利用できる別環境を用意して、サーバ側で結合テストする必要性がなかった。
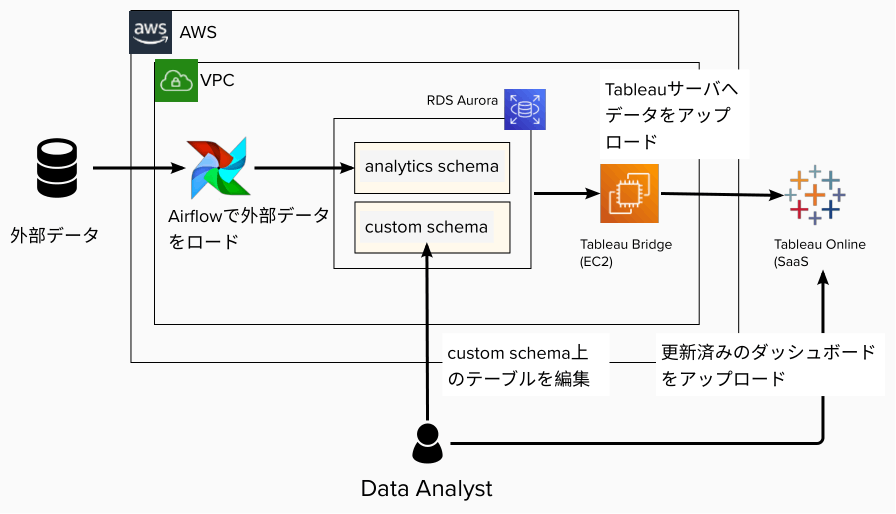
当初の分析基盤の課題および対策
上記のシステムを素早く数週間くらいで構築し、無事にローンチし、徐々に対応するデータソースを増やしていき、BI 利用者からも好評を得ましたが、数ヶ月経過後に以下のような課題が発生し、順番に解決していきました。
課題 (1) 一部クエリが非常に遅い、数時間応答が返らない
これはデータサイエンティスト・アナリストから報告を受けて調べましたが、結果としてはアナリストが作った Tableau 上のカスタム SQL に問題があることがわかりました。
このクエリでは、モバイルバックエンド Firebase から収集したイベントデータの日次集計を行っていました。本来であれば、最新の 1 日分を処理すれば良いものを彼らはその実装方法がわからず、まず全期間を毎回集計するようなクエリを書いたようでした。当初はデータ量が小さいため問題ありませんでしたが、だんだん集計対象のテーブルが大きくなるとメモリ使用量が拡大し、処理に時間がかかり、それ以外のクエリも応答が遅くなっていました。
そこで日次で集計する箇所の実装をデータエンジニア側で巻き取ることにしました。集計結果を格納するテーブルを新規に作成し、Airflow で集計を行い、結果を新規のパーティションに入れるクエリを日次で実行するようにしました。
Tableau 側ではカスタム SQL で集計を行わず、集計結果のテーブルを参照してもらうようにしました。これにより、集計にかかる処理負荷および結果の参照による RDS の負荷が激減したため、パフォーマンス問題は解消できました。
課題 (2) 生データのテーブルと集計結果のテーブルの関係性(データリネージ)が不明
プロジェクトの立ち上げを担当したデータサイエンティストが 1 年足たないうちに他のプロジェクトに移ってしまったため、データアナリストに引き継ぎを行なっていた所、データエンジニアが管理している生データのテーブル以外に無数のテーブルが存在していることがわかりました。
どういう目的で作成した何のテーブルか調査したところ、担当したデータサイエンティストやアナリストはビューの機能の存在を知らなかったため、本来はビューで済むような集計ロジックをクエリで実行し、新規テーブルに書き込んでいたようでした。
よって新規に BI から参照するテーブルなどを作成したくなった際は、必ずデータエンジニアがレビューに参加し、ビューで済むような集計は必ずビューで実装するようにしました。これによりビュー定義でどのような集計を行なっているか自明なため、テーブルとビューの関係性はすぐにわかるようになりました。
課題 (3) データサイエンティストやアナリストが本番環境の集計処理を手動で変更していた
上記の通り、データ集計は主にデータサイエンティストとアナリストが担当していましたが、彼らは DevOps のスキルがあるわけでもなく、手動で本番環境の Tableau にカスタム SQL を追加・修正することで、集計を行なっていました。
本番環境を気軽に手動で変更することはトラブルの元なので、データサイエンティストやアナリスト側でカスタム SQL の利用することは控えてもらい、データエンジニアがレビューしたテーブル・ビュー、あるいは集計クエリ(Airflowで実行)に置き換えてもらう作業をしました。また、それらのデプロイは CI/CD パイプラインでデプロイするようにしました。
最終的にデータサイエンティストやアナリストに残った部分は BI ダッシュボードですが、これは Tableau Desktop という製品でローカルで動作確認できるとのことなので、ダッシュボードの修正とデプロイは彼らで責任を持って対応してもらうことになりました。
課題 (4) 大手企業との合併が決まり、1年後に顧客規模や社内データ分析基盤利用者が数十倍になることが決まった
コロナの大騒動に慣れ始めた 2020 年 9 月頃、業界では東南アジア最大規模のディールで英系の保険企業との合併が決まりました。政府による合併などの審査があったり、本当に 1 つの会社に合併するのは1年近く先になるとのことですが、顧客規模や社内のデータ分析基盤の利用者は数十倍になることが確定し、なるべく運用コストをかけずにスケールするデータウェアハウスを選定しようということになりました。
この時の選定の状況については以下の記事を参照ください。結論としては、以下の理由により、Snowflake を導入することが決まりました。
- AWS上で完結する
- フルマネージドであり、管理運用コストが低い
- リソースが自動的にスケールし、パフォーマンスチューニングの労力がかからない
また、以下は最終的に単一のサービスを共有することが決まりました。
- ワークフロー(Airflow)
- データウェアハウス(Snowflake)
- MLOps(SageMaker)
一方、BI に関してはすでに多数のダッシュボードがあり、現時点で利用しているツール(Tableau)を継続利用することが決まりました。
新データ分析基盤での BI 関係のマイグレーション
Snowflake の採用が決まり、元々の分析データベースである RDS Aurora から Snowflake へのデータマイグレーションを以下の手順で行いました。マイグレーションが完了するまで、2つのデータベースに全く同じデータが入っている状態を維持し、安心してダッシュボードのデータソースを移行できるようにしました。
- Snowflake 側に同じテーブルを作成した。
- Airflow DAG を修正し、同じデータを RDS と Snowflake の両方にロードするようにした。
- これによりどちらのデータベースを参照しても同じデータが得られるようにした。
- Tableau Bridge に Snowflake からデータをアップロードするジョブを追加した。
- これにより Tableau Online 上に RDS と Snowflake の両方のデータが利用できるようにした。
- BI ダッシュボードの参照先を RDS から Snowflake に切り替える。
- マイグレーションが終わった段階で、RDS のユーザのアクセス権を剥奪し、Airflow DAG による RDS の更新も停止した。
新データ分析基盤での BI 関係のデプロイプロセス
新しい BI 環境では、以下のような観点で検討し、以下の図のようなデプロイプロセスになりました。
- 全体の構成やワークフローがシンプル
- インフラコストが安い
- データアナリストが BI ダッシュボードをテストしやすい
- 安全にリソースがデプロイできる(手動で本番環境を変更しない)
- 本番環境のデータでダッシュボードの動作確認ができる
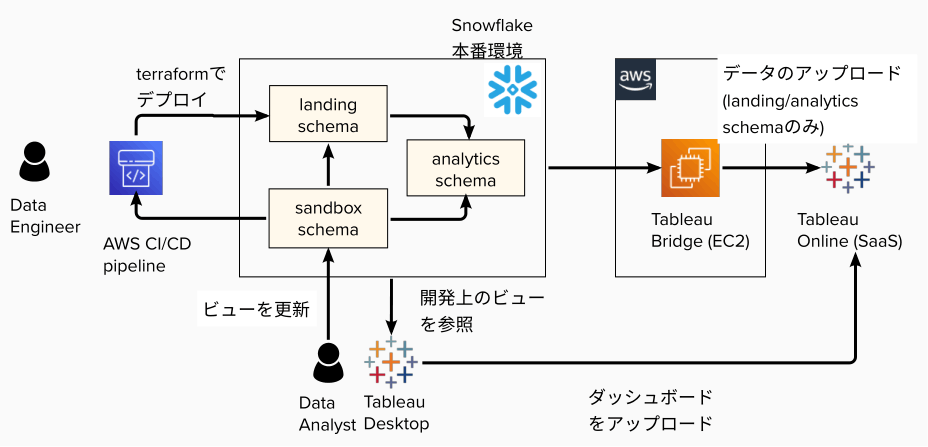
以前から変わらない点は以下の通りです。
- Snowflake 上のデータは Tableau Bridge でV Tableau Online へアップロードする。
- Snowflake へのアクセスは Private Link 経由のみ許可しているため。
- データアナリストが集計ロジックや BI ダッシュボードを作成する。ただし、デプロイはデータエンジニアが行う。
- 集計ロジックは主にビューで作成する。
- データリネージを明確にするため。ビューだと集計ロジックがビュー定義に残り、分かりやすい。
- ステートレスなため、ロジックを変更したい場合でも過去の集計結果のマイグレーションが発生しない。
- インフラや DB 上のテーブルなどは必ず CI/CD パイプラインでデプロイする。
- 利用者に管理者権限を渡さずに本番環境を安全に変更できるため。
- 手動作業によるミスを防止できるため。
今回、変更した点は以下の通りです。今回は利用者も小規模なため、本番環境のデータを利用したテストが可能な本番環境のみ用意し、
- 本番環境に影響を与えず、集計ロジックや BI ダッシュボードを作成するため、PoC 用のスキーマでダッシュボードの動作確認ができるようにした。
- 新たに sandbox スキーマという実験用に使えるスキーマを用意し、新規の集計ロジック用のビューは sandbox スキーマ上に作成してもらった。
- Tableau Desktop 上で BI ダッシュボードと sandbox 上のビューを結合し、ローカルで動作確認する。
- 新規のビューに問題ない場合は、データエンジニアがスクリプトで Terraform ファイルを作成し、CI/CD パイプラインでビューを本番環境へデプロイする。
- この時、デプロイ先は analytics スキーマとする。
- (注)Tableau Bridge からは sandbox スキーマを参照不可にし、データサイエンティスト・アナリストによる手動の集計ロジック変更を不可とした。
デプロイプロセス改善の効果
上記のデプロイプロセスに変更したことにより、以下の効果がありました。
- データアナリストにとってのメリット
- sandbox スキーマに新規の変更を適用した上で、Tableau Desktop を使ってローカルでダッシュボードの動作確認ができる。以前のテストと全く同じなため、大きな負担はなし。
- データエンジニアとってのメリット
- データアナリストがレビューなしで負荷の高いSQL をカスタム SQL で実行される心配がなくなった。
- 保守性の低い方法で集計結果を作成することがなくなった。集計ロジックはビュー定義に残るので、何のロジックで集計しているか理解しやすい。
- デプロイが自動化されているので、本番環境を変更する権限をデータアナリストに渡すことなく、安全に本番環境を変更できるようになった。
今後の課題 - 合併先の BI システムの移行で 2 環境の構築が必要
今回の記事で紹介した内容は、主に合併決定以前から所属していたチームの BI 開発に焦点を当てていました。一方で、実は合併先の企業はオンプレに BI のシステムを保有しており、利用者も数百人とかなり大規模です。
こちらは数百人が使う大規模なシステムであり、小規模に本番環境でクイックに修正してデプロイといった簡易的な方法が取れません。本番環境に影響を与えずにテストするため、以下のような工夫を検討しています。
- 本番環境とステージング環境は別の AWS アカウント、Snowflake アカウントに構築する。
- 本番環境とステージングの VPC を接続し、ステージング環境から本番環境の Snowflake アカウントのデータを利用できるようにする。
- まずはステージング環境にデプロイし、本番環境のデータと結合し、動作確認する。
- 問題なければダッシュボードや各種バッチジョブなどを本番環境へデプロイする。
おわりに
本記事では、データ分析基盤がゼロの状態から始まったデータ分析基盤に対して、開発・運用で発生した課題を解決していった過程を紹介しました。現状の BI システムが比較的小規模なものであるため、簡易的な方法を取り、安全性と生産性の向上で成果が得られました。今後は大規模な BI システムをオンプレから移行する予定のため、これまでとは全く違った要件の対応を求められることが予想されることを紹介しました。
本記事が皆様にとって参考になれば幸いです。
なお、2022 年は SageMaker と Snowflake を使った MLOps にも挑戦する予定ですので、そちらもまた記事にしたいと思います。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion