5chスレッドを生成AIで分析してみた(GPT3.5+Claude3)

はじめに
この記事では、5chスレッドのコメントを大規模言語モデル(LLM)を使って分析する手法と、その過程で遭遇した課題や解決策を紹介します。
TL;DR
この記事では、5chスレッドのコメントを大規模言語モデル(LLM)を使って分析する手法と、その過程で遭遇した課題や解決策を紹介します。
分析対象のスレ → リップクリーム・リップケア総合スレ35本目
分析結果 → https://talk-analyzer.pages.dev/
大規模言語モデルを用いたテキスト分析の応用可能性
LLMを用いたテキスト分析は、様々な業務に活用できる可能性があります。
マーケティングにおける定性分析:
SNSやインタビューなどのテキストデータを分析し、顧客の価値観やニーズ、ブランドイメージなどを把握する。
企業にかかわる重要リスクの監視:
ニュース記事や企業の財務報告書などのテキストデータを分析し、潜在的なリスクを早期に発見し、アラートを上げる。
情報収集の自動化:
最新ニュースやブログ記事などのテキストデータを分析し、必要な情報だけを抽出し、メールやWeb等で配信する。
対象データ
今回の試みでは、実験的に「リップクリーム」に関する5chの過去スレッドのコメントを対象にしました。
リップクリーム・リップケア総合スレ35本目
分析の目的は「リップクリームのマーケティング調査」としました。具体的には、大規模言語モデルに入力するプロンプトすべてに「分析の目的」として以下の文章を含めています。
普段使っているリップクリームについての消費者の意見調査
調査の目的: リップクリームについて消費者の意見を調査し、製品の改善や新製品の開発に役立てる
調査の対象: 5chのスレッド「リップクリームについて」リップクリームについて消費者の意見を調査し、製品の改善や新製品の開発に役立てること
分析方法
SCATについて
今回の分析では、質的研究の手法の一つであるSCAT(Steps for Coding and Theorization)を参考にしています。SCATは、教育分野の研究者(大谷氏)が2008年に発表した質的データ分析手法で、主に教育学や看護学の分野で活用されています(私は質的研究の専門家ではないため、もし誤りなどがありましたらコメント等でお知らせください)。SCATを参考にしたのは、作業手順が明確でLLMで自動化することに向いていると考えたからです。
SCATでは、対象データを4つの作業ステップでコード化していきます。
- データから着目すべき語句を抽出する
- 語句の言い換えを行う
- 語句から浮かび上がるテーマ・構成概念を記述する
- テーマ・構成概念を紡いでストーリーラインと理論を記述する
今回は、LLMを用いて、SCATと似た分析手順を自動化しました。
コード化とは
コード化はコーディングとも呼ばれます。日本語版に項目がなかったので、英語版のWikipediaを引用します。
Wikipediaの説明:
In the social sciences, coding is an analytical process in which data, in both quantitative form (such as questionnaires results) or qualitative form (such as interview transcripts) are categorized to facilitate analysis.
One purpose of coding is to transform the data into a form suitable for computer-aided analysis. This categorization of information is an important step, for example, in preparing data for computer processing with statistical software.
コード化は質的研究で利用される分析方法で、量的、質的なデータを分析するためにコンピュータが扱いやすい形式に変換することとされています。質的研究では、人間が会話記録などを読み込んでコード化を行います。データに含まれる文章の引用やキーワード、言い換え、要約などが、1つ1つの「コード」になります。質的研究では、コード化を行い、それを分類したり組み合わせることで理論を組み立てていきます。
コード化の例: 「今まで冬は唇が切れるからって適当に安いリップクリーム買って塗ってたけどすぐ取れる。」
この文章から「コード」を取り出すと、以下のようになります。
- 「冬は唇が切れる」
- 「安いリップクリームはすぐ取れる」
SCAT以外の手法:
米国ではグラウンデッド・セオリーという手法が定着しているようです。詳しくは調べておりませんが、興味があったらWikipediaを参照ください。
利用技術
LLMと言語
- LLM: 主にGPT3.5 Turboを利用。一部にClaude 3 Opusを利用。
- プログラミング言語: Go
Goを選択した理由: Goは文法がわかりやすく、読みやすいためです。また、軽量スレッドにより簡単に処理を並列化できる点もあります。プロンプトのトークン数のカウントにはtiktokenを利用しています。
プロンプトエンジニアリング
Open AIとAnthropicのガイドを参考にしました。
分析ワークフロー
LLMから期待通りの出力を得るには、タスクを細かく分割して、1つ1つをできるだけシンプルにする必要があります。今回はSCATの4段階のコーディング方法を参考に以下のステップに分割することにしました。
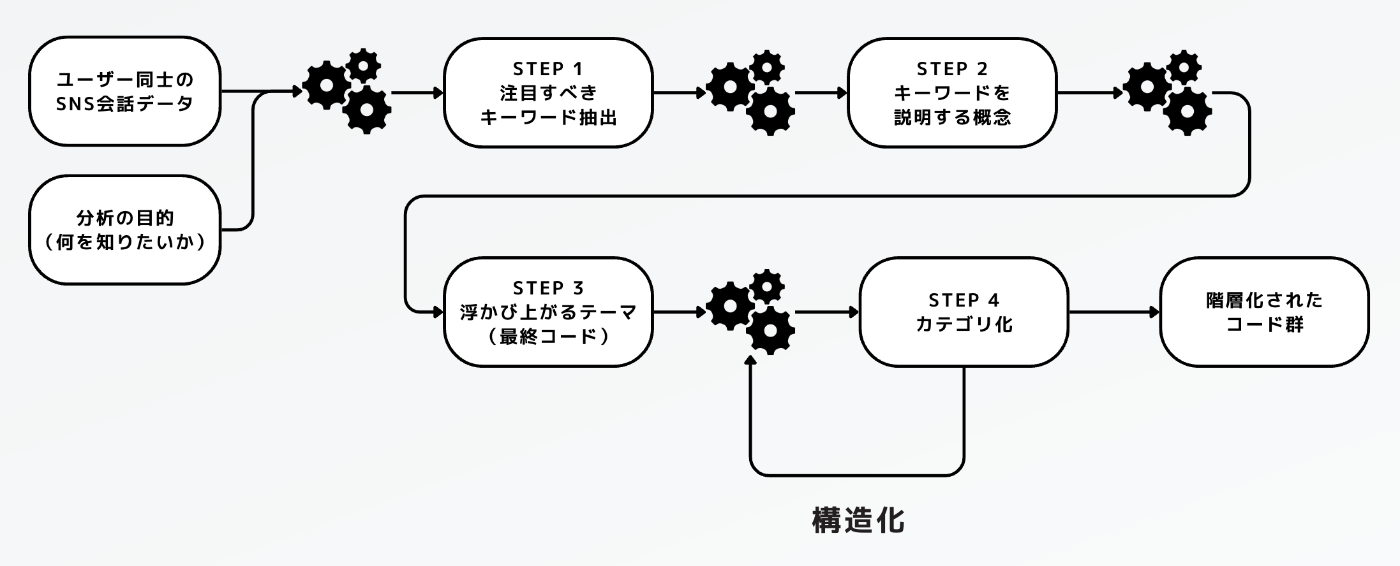
LLMを用いたテキスト分析のステップ:
- スレッドの各コメントから注目すべきキーワードを抽出させる
- キーワードを説明する概念を説明させる
- 1,2の結果をグルーピングさせる
- 1,2の結果から考えられる結論(仮説)を出力させる
プロンプトの例
例えば、以下のようなプロンプトを用いています(一部)。あわせてJSONスキーマと出力例もプロンプトに含めることで動作が安定します。
ステップ1 キーワード抽出:
As a qualitative researcher, your task is to conduct Qualitative Coding on a given research object for subsequent qualitative analysis. You will be provided with a research object and conversation logs from a consumer forum. Your goal is to carefully analyze and code the users' comments to capture a deep understanding of their needs, desires, and experiences related to the research object.
When coding, follow these guidelines. These are highly important and must be strictly adhered to:
1. Codes must be keywords or short phrases that are clipped from the user's comments AS IS.
2. It is essential that you do not overlook any comments that could be relevant, even if their meaning is unclear or ambiguous. Err on the side of inclusion to ensure a comprehensive analysis.
日本語訳:
あなたの仕事は、質的研究者として、与えられた研究対象に対して質的コーディングを行い、その後の質的分析を行うことです。あなたには、調査対象と消費者フォーラムの会話ログが提供されます。あなたの目標は、ユーザーのコメントを注意深く分析し、調査目的に関連するニーズ、欲求、 経験を深く理解してコード化を行うことです。
コード化の際は、以下のガイドラインに従ってください。これらは非常に重要であり、厳守しなければなりません:
1. コードは、ユーザーのコメントから切り取ったキーワードまたは短いフレーズをそのまま使用すること。
2. たとえ意味が不明確または曖昧であっても、関連する可能性のあるコメントを見落とさないことが重要です。包括的な分析を確実にするため、含める側に回ること。
分析結果
以下のWebページにアップロードしてあります。分析結果をクリックすると、根拠となったコメントを表示できます。
所要時間とAPIコスト
- 処理時間: 198秒
-
APIコスト: $3.25
- GPT3.5: $2.05
- Claude 3 Opus: $1.2
遭遇した問題点と解決策
LLMを用いてテキストを分析する中で発生した問題点と解決策について共有します。
Context Windowの制限
ユーザーの会話データが長く、ContextWindowの最大値を超えてしまう。
解決方法1: 入力データを一定のトークン数で分割し、個別に処理する。
解決方法2: Claude3 Haiku を利用する。Claude3 Haiku はContext Windowのトークン数ではGPT3.5の10倍ほどあります。Haikuを利用すれば、1回のバッチサイズを相当大きくできます。ただしTierを上げないと大量のテキスト分析に利用するのは難しいです。
GPT3.5ではグループ化と要約が難しい
複数のバッチに分けてグループ化を行ったところ、GPT3.5は既存のグループ分けを無視して、微妙に異なるグループを作ってしまうことが多いです。プロンプトの調整だけでは限界があるように思いました。また、要約についてもGPT3.5は文章を切ってつなげたような表層的な要約をすることが多いです。
解決方法1: プロンプトで必ずグループ化の1/2の数になるよう指示し、その結果をさらに再帰処理することを繰り返すようにした。
解決方法2: 最後の分析結果の出力のみ、より高性能なモデルである Claude 3 Opus を用いた。
API実行に時間がかかる
入力データを分割してAPIを繰り返し実行するため、順番に実行していると非常に時間がかかってしまう。
解決方法: Go言語に組み込まれた軽量スレッドであるGoroutineで並列化した。Claude3に関しては1分あたりのリクエスト回数の上限(RateLimit)が低いので、Channelなどを用いて同時APIの実行数が制限を超えないようにした。
Claude3のRateLimitにかかる
Claude 3 Haiku APIが公開されたため、GPT3.5の代わりに使用できるか試しましたが、すぐに1日あたりのRateLimitにかかってしまいました(実行回数、合計トークンに1日あたりの上限が設定されている)
解決方法: 全体的にHaikuを使うのではなく、一部分のみ利用するようにした。
たまに不完全なJSONが出力される
GPT3.5もClaude 3のどちらも、1回のAPI実行での出力トークン数に上限があります。出力データが長いと、途中で出力が終了して不完全なJSONが返されることがあります。
解決方法: 出力されるデータを圧縮した (JSON構造のフィールド名をすべて1文字にする等)。
LLMを活用する利点
会話の文脈を踏まえてテキストを分類できる
テキストをチャンク化する際に一部オーバーラップさせることで、会話の文脈を踏まえてAIにテキストを分類させることができます。例えば、会話の中で、主語がない断片的な発言であっても感情や対象を理解し、発言を分類できます。
AIに分析の目的を伝えられる
プロンプトに分析の目的を含めることによって、目的に沿った出力結果が得られます。今回のプロトタイプでは、分析目的をあまり明確にしていませんでしたが、たとえば「好きなリップクリームのブランドと理由」といったように目的を明確にすれば、ソフトウェアを変えずに、個別の案件に応じた分析結果が得られます。
調査、分析の工数を削減できる
1,000コメント程度であれば人間がざっと読むのと大して差はありませんが、これが10倍以上の量になれば、人間よりも圧倒的に短い時間で内容を把握することが可能になります。
まとめ
LLMを使用したテキスト分析はとても有望ですが、現時点ではコストを考慮する必要があります。LLMで自動化するにはワークフローの各ステップを、なるべく単純化する必要があります。分析の手法について、今後は専門家の意見を聞き、実務で役立つ手順、方法を模索したいと思います。また、ビジュアライゼーションについても同様です。
参考文献
- 質的研究の考え方ー研究方法論からSCATによる分析まで
- OpenAI による Prompt engineering guide
- Anthropic による Prompto engineering guide
- Anthropic Models overview
- https://en.wikipedia.org/wiki/Coding_(social_sciences)
ワークフローエンジンの紹介
今回のようなワークフローを開発するには、入力ファイルを分割して並列実行したり、特定のタスクだけを再実行できる仕組みがあると便利です。例えば、一部のタスクでエラーが発生したときに、ワークフロー全体を再実行するのは非効率的で、余計なAPIの費用がかかってしまいます。
そのためのツールが「ワークフローエンジン」と呼ばれるソフトウェアです。最も有名なワークフローエンジンの1つが、Airbnbが開発したApache Airflowです。
「Dagu」はバイナリを配置するだけで使えるワークフローエンジンです。簡単なYAMLでワークフローを定義し、管理できるのが特長です。データベースや複雑な設定が不要なため、Cronジョブの延長くらいの手間で導入できます。
Go言語向けの文分割ライブラリの紹介
GoSBDは、テキストを文(センテンス)単位に分割するためのGo言語用ライブラリです。高速かつ精度の高いPython向け文分割ライブラリであるPySBDと同じルールで動作します。
GoSBDは、RAG(Retrieval-Augmented Generation)を実装する上で欠かせない、文境界を判定する機能を提供します。現在、日本語、英語、中国語など複数の言語に対応しています。
まだ発展途上のライブラリですが、Go言語でのテキストの前処理に有用になるはずです。もし興味がありましたら、ぜひコントリビューションをお待ちしています。
Discussion
コードの公開は予定されていますか?
Likeありがとうございます。コードの公開は予定しておりませんが、もしご興味がありましたらミーティングなどで説明できます。よろしくお願いいたします。
返信、ありがとうございます。興味あるので頃合いをみてご連絡します。
承知しました。よろしくお願いいたします。