Closed6
SnowflakeにおけるApache Icebergの利用
DWHとしてSnowflake + Apache Icebergを使ってみようか、ということになったのですが、
Volume, Tables, Catalog, Snowflake Open Catalogなどの概念が初見だと難しいな、と思ったので調べていきます。
従前数多のページでまとめられていますが、自分用まとめとして。
(本当はハンズオンまでやりたかったけどまずは下調べから)
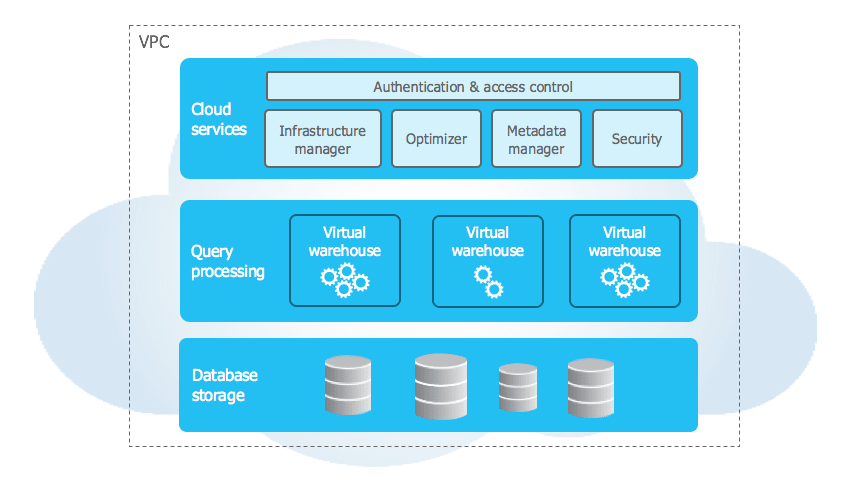
アーキテクチャ概要
Snowflakeのユニークなアーキテクチャは、3つの重要なレイヤーで構成されています。
データベースストレージ
クエリ処理
クラウドサービス
Apache Icebergと組み合わせて使う場合にポイントとなるのは "データベースストレージ" の部分。
クエリ処理を行う Virtual warehouse やクラウドサービスはSnowflakeを共通基盤のSaaSとして使いながら、データベースストレージを「外部ボリューム」として「データを持っている人各々で別途用意できるようになる」、というのがメリット。
外部ボリューム
Snowflakeテーブルは通常、Snowflakeが管理するストレージを使用します。対照的に、Snowflakeの Apache Iceberg™ テーブルでは、外部ストレージを使用し、それを構成して維持します。
外部ボリュームは名前付きのアカウントレベルのSnowflakeオブジェクトで、SnowflakeをIcebergテーブル用の外部クラウドストレージに接続するために使用します。
- 「Snowflakeが管理するストレージ」は、Snowflakeによって提供されるデータレイク
- Snowflakeフルマネージドのカタログ・メタデータ・データ形式を使用 (= Snowflake SaaSにロックイン)
- 外部ストレージは、データオーナーが用意するデータレイク (AWS S3やAzure Storage等)
- Snowflakeは「外部ボリューム」というオブジェクトで外部ストレージを管理する
- Apache Icebergのカタログ・メタデータ形式と、Apache Parquet形式のファイル形式を使用 (= いずれもオープンソースかつデファクトのためSaaSロックイン回避を指向)
| Snowflakeストレージ | 外部ストレージ (外部ボリューム) | |
|---|---|---|
| データストレージの用意 | Snowflake | データを持っている人(データオーナー) |
| データストレージの場所 | Snowflake SaaS | 任意のパブリッククラウド(AWS, Azure, GCP) |
| カタログ形式 | Snowflake独自 | Apace Iceberg |
| メタデータ形式 | Snowflake独自 | Apace Iceberg |
| データ形式 | Snowflake独自 | Apache Parquet |
Apache Icebergにおける「カタログ」の概念
Catalog (カタログ)
- データベースのMetadata file管理 (ライフサイクル管理)
- Metadata fileに対するポインタを保持しバージョン管理を実現
Metadata file
- テーブルのスキーマ、プロパティ、データのSnapshotをManifest listとして保持
Manifest list
- SnapshotタイミングのManifest fileの一覧を保存するリスト
Manifest file
- テーブルのデータ (data files) への操作を記録するメタデータ
- テーブル状態が変更されると新たなManifestが作成される

Iceberg 外部ボリュームにおけるカタログの扱い
カタログを「誰が保持するか」の概念により分類される。
| SnowflakeをIcebergカタログとして使用 | 外部Icebergカタログを使用 | |
|---|---|---|
| イメージ |  |
 |
| カタログ保持の主体 | Snowflake | 外部ストレージ (AWS等) |
| メタデータ管理の主体 | Snowflake | 外部カタログ (AWS Glue Data Catalog等) |
| Snowflakeによるカタログの読み込み | ○ | ○ |
| Snowflakeによるカタログの書き込み | ○ | × (Snowflakeから見ると外部システムのため) |
| Snowflakeとのカタログ同期 | 不要 | カタログ統合により実現 |
まとめ
以下のようなケースでは、Snowflake + Apache Iceberg (外部カタログ) が良いのかなと理解。
- Snowflakeの外にデータを管理している主体がすでに存在している
- 管理されているデータのそれぞれについて、統一的な手段で相互に参照したい
- クエリエンジンは共通のものを利用したい
今後はハンズオンなども実施していきたいところ。
このスクラップは4ヶ月前にクローズされました