Datadog Istio インテグレーションのメトリクスを使ってサービス間通信の平均レスポンスタイムを可視化する方法
この記事は、 ドワンゴアドベントカレンダー 2023 の 4 日目の記事です。
ニコニコ生放送 Web フロントチームの ymiz です。
ニコニコ生放送では Istio を利用しています。 また、Datadog も利用しています。
Datadog の Istio インテグレーションを使って、 メトリクスを取得できます。
このメトリクスを元にサービス間通信の平均レスポンスタイムをダッシュボードに表示しようとした時、 Web 上に沢山あるとありがたかった情報を紹介します。
(「レスポンスタイム」は「レイテンシ」や「リクエスト待ち時間」とも表現できると思いますが、個人的に馴染みのある「レスポンスタイム」を使います。)
サービス間通信の平均レスポンスタイム
結論から書くと、下記計算式でサービス間通信の平均レスポンスタイムを算出できます。
- a:
sum:istio.mesh.request.duration.milliseconds.sum.total{source_app:foo,destination_app:bar,reporter:source}.as_count() - b:
sum:istio.mesh.request.count.total{source_app:foo,destination_app:bar,reporter:source}.as_count() - 平均レスポンスタイム:
a / b
a は、ある時間区間の、foo から bar へのリクエストにかかった時間の合計を意味します。
b は、ある時間区間の、foo から bar へのリクエスト数合計を意味します。
a / b で、ある時間区間の、foo から bar へのリクエストにかかった時間の平均を算出できます。
ある時間区間 は、より具体的には、線グラフであればグラフの点が表現する時間区間を指します。
これにより、下記のような情報を可視化できます。
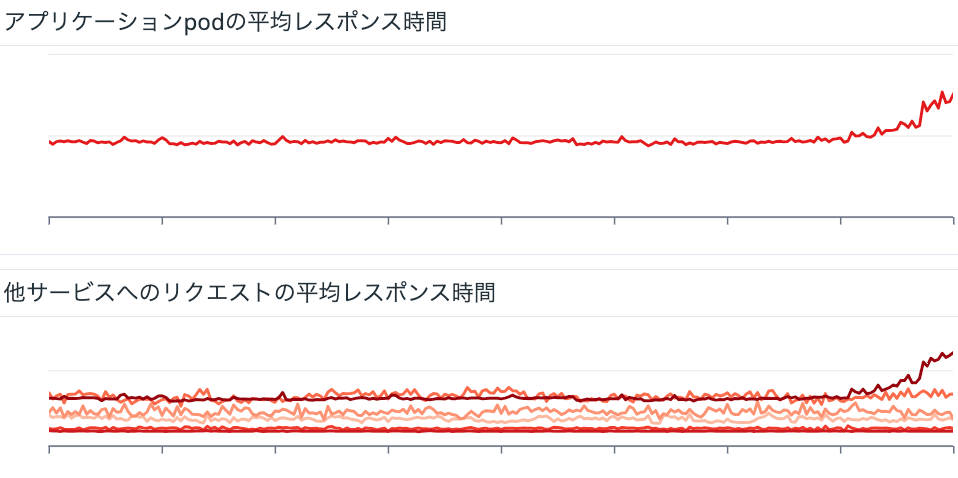
BFF (Backend For Frontend)の平均レスポンスタイム
ニコ生 Web フロントでは、 ニコニコ生放送 WebフロントエンドのKubernetes移行ハンドブック 2022 にある通り、Ingress Gateway を利用しています。
Ingress Gateway の後ろに BFF の pod があります。
なので、Ingress Gateway pod から BFF pod へのリクエストの平均レスポンスタイムを利用することで、BFF の平均レスポンスタイムを可視化できます。
レスポンスタイムのメトリクスを BFF から Datadog に送っているアプリケーションも一部あるのですが、その平均値と概ね一致する値が算出されています。
他サービスへのリクエストの平均レスポンスタイム
同様に、BFF pod から k8s クラスタ内の他サービスにリクエストした場合の平均レスポンスタイムを可視化できます。
BFF の平均レスポンスタイムと組み合わせることで、例えば BFF の平均レスポンス時間が悪化した際にどのサービスへのリクエスト起因なのかがより分かりやすくなります。
また、後で振り返る際に、どういう状況だったのかをより把握しやすくなります。
余談
istio.mesh.request.duration.milliseconds.count.total は使えないのか
上記では、foo から bar へのリクエストにかかった時間の合計に istio.mesh.request.duration.milliseconds.sum.total を使い、foo から bar へのリクエスト数合計に istio.mesh.request.count.total を使っています。
istio.mesh.request.duration.milliseconds.sum.total と似た名前のメトリクスに istio.mesh.request.duration.milliseconds.count.total があり、これで割れば平均レスポンスタイムを出せるように見えます。
が、少なくとも私が試した限りはうまくいきませんでした。
で、このことが議論されています。
メトリクスが正しい単位で扱われていない場合があるらしく、このことに起因するようです。
https://github.com/DataDog/integrations-core/issues/7074#issuecomment-655683117 によれば、メトリクスの単位を変えることで期待する値を取れるようになるとのことです。
(が、私は試していません)
reporter: source とは
istio.mesh.request.duration.milliseconds.sum.total などのいくつかの Istio メトリクスには reporter というタグが付与されています。
reporter には、 source と destination の二種類があります。
Datadog のドキュメント等で明言されている箇所を私は見つけられていませんが、利用した限りでは、reporter は Istio メトリクスの Reporter と同等と考えて良さそうです。
Reporter: This identifies the reporter of the request. It is set to destination if report is from a server Istio proxy and source if report is from a client Istio proxy or a gateway.
reporter: source は、クライアント Istio proxy からのレポートということになります。
foo から bar を参照している場合の reporter: source のメトリクスは、 foo が報告した情報ということです。
クエリに reporter を指定しない場合、実際の倍程度の値(source と destination の合算値)がグラフに現れることがあるので注意が必要です。
なお、あるメトリクスにどういったタグが付いているかといった情報は Metrics Summary から確認できます。
istio.mesh.request.duration.milliseconds.sum と istio.mesh.request.duration.milliseconds.sum.total の違い
ざっくり書くと、 istio.mesh.request.duration.milliseconds.sum は累積値で、 istio.mesh.request.duration.milliseconds.sum.total は累積値の差分です。
ドキュメント的には下記です。
-
istio.mesh.request.duration.milliseconds.sumTotal sum of observed values for duration of requests in ms. This metric is sent as gauge by default in OpenMetrics V1.
-
istio.mesh.request.duration.milliseconds.sum.totalTotal sum of observed values for duration of requests as monotonic count
monotonic count = 単調カウントについては、 に説明があります。
この関数は、増加し続ける未加工の COUNT メトリクスを追跡するために使います。Datadog Agent は各送信の間の差を計算します。
(中略)
例えば、サンプル 2、3、6、7 を送信すると、最初のチェックの実行中に 5 (7-2) が送信されます。同じ monotonic_count でサンプル 10、11 を送信すると、次のチェックの実行中に 4 (11-7) が送信されます。
例えば、.sum において時刻 t で 100、時刻 t+1 で 300 が送られた場合、.sum.total では時刻 t+1 で 200 が送られる、ということになります。
なので、 istio.mesh.request.duration.milliseconds.sum を diff すると、istio.mesh.request.duration.milliseconds.sum.totalと概ね一致したグラフが得られます。
- 例:
diff(sum:istio.mesh.request.duration.milliseconds.sum{source_app:foo, destination_app:bar, reporter:source}.rollup(max)) - また、例えば 15 分のような短い時間幅で表示すると
istio.mesh.request.duration.milliseconds.sum.totalの方がばらつきが大きくなるという現象を確認しており、この原因は掴めていません。
Next
明日は同じチームの misuken さんの記事です。是非読んでみてください。
Discussion