tokio-metricsでruntimeとtaskのmetricsを取得する
本記事では、tokio-metricsを利用してtokioのruntimeとtaskのmetricsを取得する方法について書きます。
Versionは0.3.1です。
[dependencies]
tokio-metrics = { version = "0.3.1", default-features = false, features = ["rt"] }
Task Metrics
async fn my_task() {
// ...
}
#[tokio::main]
async fn main() {
tokio::spawn(my_task()).await.ok();
}
上記の処理で、my_task()が遅いとわかった場合、以下の理由が考えられます。
- CPU bound
- I/Oの完了を待っている
- Runtimeのqueueにいる時間が長い
特に3が厄介で、my_taskが問題ではなく、問題は他のtaskにあるケースなのでこれらのmetricsを取得できると調査の際に有用だと思いました。
tokio_metricsのTaskMonitorを利用すると各種metricsから上記1,2,3の影響の程度を計測することができます。
Taskの計装方法
計測したいtaskのmetricsを取得する方法は簡単で
use std::time::Duration;
use tokio_metrics::TaskMonitor;
async fn my_task() {
// ...
}
async fn run(monitor: TaskMonitor) {
monitor.instrument(my_task()).await;
}
#[tokio::main]
async fn main() {
let monitor = TaskMonitor::new();
{
let monitor = monitor.clone();
tokio::spawn(async move {
for interval in monitor.intervals() {
// handle metrics
println!("{:?}", interval);
tokio::time::sleep(Duration::from_secs(10)).await;
}
});
}
run(monitor).await;
}
TaskMonitorを生成したのち、計測したいtaskをTaskMonitor::instrument()に渡します。
#[derive(Clone, Debug)]
pub struct TaskMonitor {
metrics: Arc<RawMetrics>,
}
TaskMonitorはArcで内部のデータ構造をwrapしているのでclone()できます。
instrumentしたtaskのmetricsを取得するにはTaskMonitor::intervals()でmetricsを返すiteratorを取得して、loop内でmetricsを処理します。
Task metricsのtemporality
TaskMonitorはtaskのmetricsをcumulative(起動時からの合計)な値とdelta(前回の計測からの差分)の二つの方法で提供してくれます。
Cumulativeな値を利用する場合はTaskMonitor::cumulative()を利用します。
Delataを利用する場合は上記の例のようにTaskMonitor::intervals()を利用します。
どちらを利用しても取得できるmetricsはTaskMetricsです。(intervals()はそのiterator)
内部の実装はsimpleで
pub fn cumulative(&self) -> TaskMetrics {
self.metrics.metrics()
}
pub fn intervals(&self) -> impl Iterator<Item = TaskMetrics> {
let latest = self.metrics.clone();
let mut previous: Option<TaskMetrics> = None;
std::iter::from_fn(move || {
let latest: TaskMetrics = latest.metrics();
let next = if let Some(previous) = previous {
TaskMetrics {
instrumented_count: latest
.instrumented_count
.wrapping_sub(previous.instrumented_count),
dropped_count: latest.dropped_count.wrapping_sub(previous.dropped_count),
// Construct metrics...
}
} else {
latest
};
previous = Some(latest);
Some(next)
})
}
cumulative()は実はなにもしておらず保持している値をそのまま返していて、intervals()は前回の値をiterator側で保持していて、最新(cumulative)の値から前回の値を引いて返してくれています。
TaskMetricsのmetrics
taskへの計装方法とmetricsの取得方法がわかったので次に具体的に取得できるmetricsについて見ていきます。
全てのmetricsや詳細についてはdocumentを確認してください。ここでは実際に自分が利用したmetricsについて述べます。
まずtaskのlifecycleの概要としては自分は以下のように理解しています。(multi thread scheduler前提)
task(future)が生成されると、runtimeからpollされる。その中で.awaitした際にI/Oが発生すると、taskはidle(I/O待ち)になる。この際、OSのthreadはyieldされず(CPU上で引き続き実行される)、mio等のI/O driverにI/Oの完了の通知を登録して、runtimeは別のtaskを実行する。I/Oが完了すると、Wakerによってtaskはruntimeのqueueに入り、再びpollされるまで待機する。(このあたりはAsynchronous Programming in Rustがわかりやすかったのでオススメです。)
ということで最初の出発点として、taskのpollに掛かっている時間、I/Oを待機している時間、queueで再scheduleを待っている時間を計測できるようにしようと思いました。
pollのmetrics
pollのmetricsとして以下を利用しました
pollの平均期間と"slow"なpollの平均時間です。
これらのmetricsが増加した場合、CPU boundな処理か、誤ってblockingな処理(stdのI/O等)を実行してしまっているか疑います。pollが"slow"と判定される閾値はDEFAULT_SLOW_POLL_THRESHOLDで50μsとなっていました。
また、slow pollの比率をslow_poll_ratioから取得できます。
I/Oのmetrics
I/O(外部event)の完了を待機している時間については
を利用しました。このmetricsはpollが完了してから(Poll::Pendingを返してから)、awokernされるまでの期間という認識です。この値が増加した場合はそのtask内で実行しているI/Oをさらに調査します。
Queueのmetrics
Runtimeのqueueに入ってから再実行までの期間のmetricsについては
を利用しました。それぞれ、最初にpollされるまでの時間、queueに入ってから再度pollされるまでの時間を表しています。
これ以外にもslow poll同様にlong_delay_ratioとmean_long_delay_durationも用意されています。
このmetricsを取得することで、pollも速くて、I/Oでもなく、他のtaskが詰まっていると判断できるようになると思っています。
Taskのmetricsの概要は以上です。
Runtime Metrics
tokio-metricsでは個々のtaskだけでなく、tokio runtime自体のmetricsも取得できます。
runtimeのmetricsを取得するには、tokio_unstableとrt featureを有効にする必要があります。
tokio-metircsのrt featureを有効にし、projectの.cargo/config.tomlに以下を追加しました。
[build]
rustflags = ["--cfg", "tokio_unstable"]
Runtimeの計装方法
use tokio_metrics::RuntimeMonitor;
#[tokio::main]
async fn main() {
let handle = tokio::runtime::Handle::current();
let runtime_monitor = RuntimeMonitor::new(&handle);
tokio::spawn(async move {
for interval in runtime_monitor.intervals() {
// handle metrics
println!("{:?}", interval);
tokio::time::sleep(Duration::from_secs(10)).await;
}
});
}
RuntimeMonitorは特定のtaskに紐づける必要はなく、tokio::runtime::Handle::current()の値を渡すだけで良いようです。内部的に各workerのmetricsを合計してくれているので、どのworker threadで実行するかは気にしなくて良いと思っています。
RuntimeMetricsのmetrics
Runtimeに関してはどの様なケースで、どのmetricsが役に立つか手探りの状態です。
自分は以下のmetricsの取得から始めました。
Runtimeの内部構造についてもっと知れたらこのmetricsが欲しいとなると思うので調べていきたいです。
実際の利用例
ここまではsample codeで概要の話でしたので、次に実際の利用例について見ていきます。
今回は趣味で作っているTUIのfeed viewerのgraphql backendにtokio-metricsを組み込んだ例を見ていきます。
利用しているlibraryはaxumとasync-graphqlです。
最初の出発点として、graphql taskのmetricsを取得することにしました。
特定のresolverにしようかと迷ったのですが、どちらにせよgraphql全体のmetricsがあったほうが、特定のresolverに計装した際に比較できて便利だと、考えまずはgraphqlの取得から始めました。
pub async fn serve(
listener: TcpListener,
dep: Dependency,
shutdown: Shutdown,
) -> anyhow::Result<()> {
let Dependency {
// ...
monitors,
} = dep;
let cx = Context {
gql_monitor: monitors.gql.clone(),
schema: gql::schema_builder().finish(),
};
tokio::spawn(monitors.monitor(config::metrics::MONITOR_INTERVAL));
let service = Router::new()
.route("/graphql", post(gql::handler::graphql))
.layer(Extension(cx))
// serve ...
pub async fn graphql(
Extension(Context {
schema,
gql_monitor,
}): Extension<Context>,
req: GraphQLRequest,
) -> GraphQLResponse {
TaskMonitor::instrument(&gql_monitor, schema.execute(req).instrument(foo_span!()))
.await
.into()
}
概要としては、axumの仕組みでrequestの度に実行されるgraphqlの処理(handler)にTaskMonitorを渡しています。
(TaskMonitor::instrumentとtracing::Instrumentが衝突してしまったので、わかりづらい形となってしまっています。)
Metricsの生成についてはtokio::spawn(monitors.monitor(config::metrics::MONITOR_INTERVAL))で行なっています。
Metricsに関しては上記で述べたmetricsを取得しているだけです。
impl Monitors {
pub fn new() -> Self {
Self {
gql: TaskMonitor::new(),
}
}
pub async fn monitor(self, interval: Duration) {
let handle = tokio::runtime::Handle::current();
let runtime_monitor = RuntimeMonitor::new(&handle);
let intervals = runtime_monitor.intervals().zip(self.gql.intervals());
for (runtime_metrics, gql_metrics) in intervals {
// Runtime metrics
metric!(monotonic_counter.runtime.poll = runtime_metrics.total_polls_count);
metric!(
monotonic_counter.runtime.busy_duration =
runtime_metrics.total_busy_duration.as_secs_f64()
);
// Tasks poll metrics
metric!(
monotonic_counter.task.graphql.mean_poll_duration =
gql_metrics.mean_poll_duration().as_secs_f64()
);
metric!(
monotonic_counter.task.graphql.mean_slow_poll_duration =
gql_metrics.mean_slow_poll_duration().as_secs_f64()
);
// Tasks schedule metrics
metric!(
monotonic_counter.task.graphql.mean_first_poll_delay =
gql_metrics.mean_first_poll_delay().as_secs_f64(),
);
metric!(
monotonic_counter.task.graphql.mean_scheduled_duration =
gql_metrics.mean_scheduled_duration().as_secs_f64(),
);
// Tasks idle metrics
metric!(
monotonic_counter.task.graphql.mean_idle_duration =
gql_metrics.mean_idle_duration().as_secs_f64(),
);
tokio::time::sleep(interval).await;
}
}
}
let intervals = runtime_monitor.intervals().zip(self.gql.intervals());
runtimeとtaskそれぞれ、intervals()でiteratorを返すので、zipして、一つのiteratorにしました。
Metricsの出力はtracing -> tracing_opentelemetry::MetricsLayer -> opentelemetry-collectorとしています。
ここで実際にserverにrequestを行いました。feedを取得するtoolなので登録しているfeedの数だけ、http requestが実行される処理です。
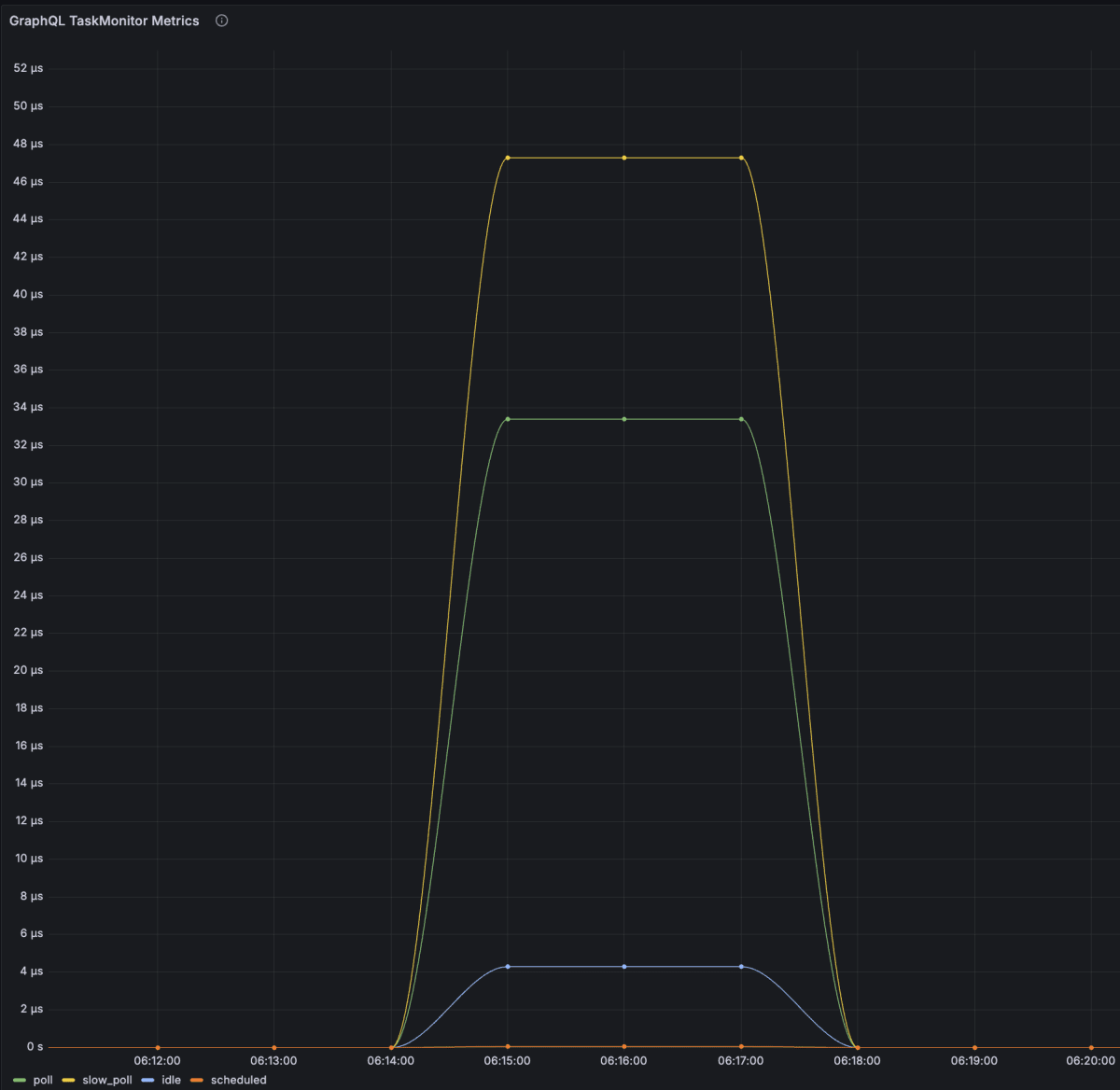
実際に試してみると以下のようなmetricsを取得できました。
青がidle、黄色がslow poll, 緑がpoll, 赤がscheduleを表しています。
Task metrics
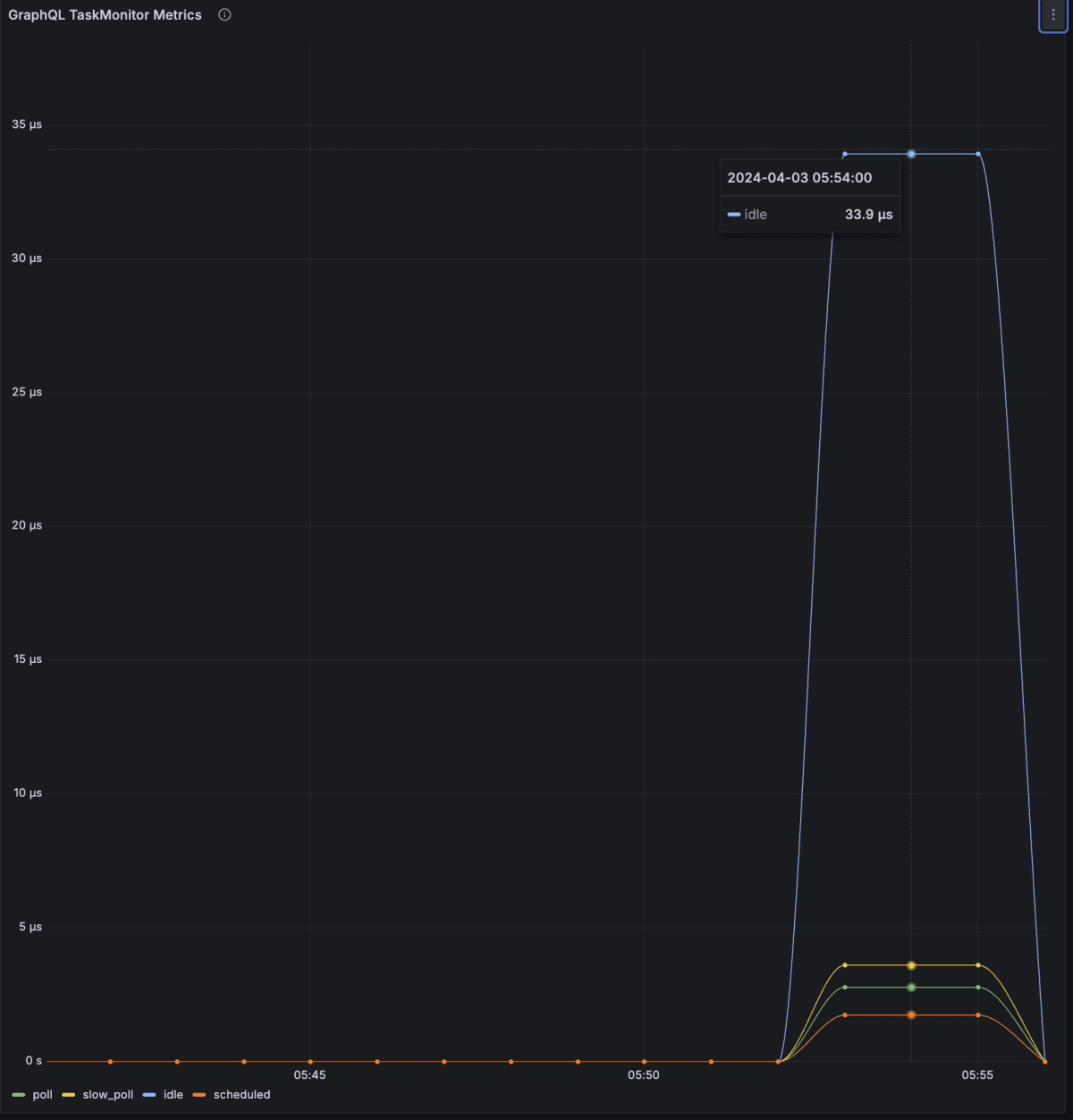
idleのmetricsが上昇しており、I/Oを待機していることがわかります。
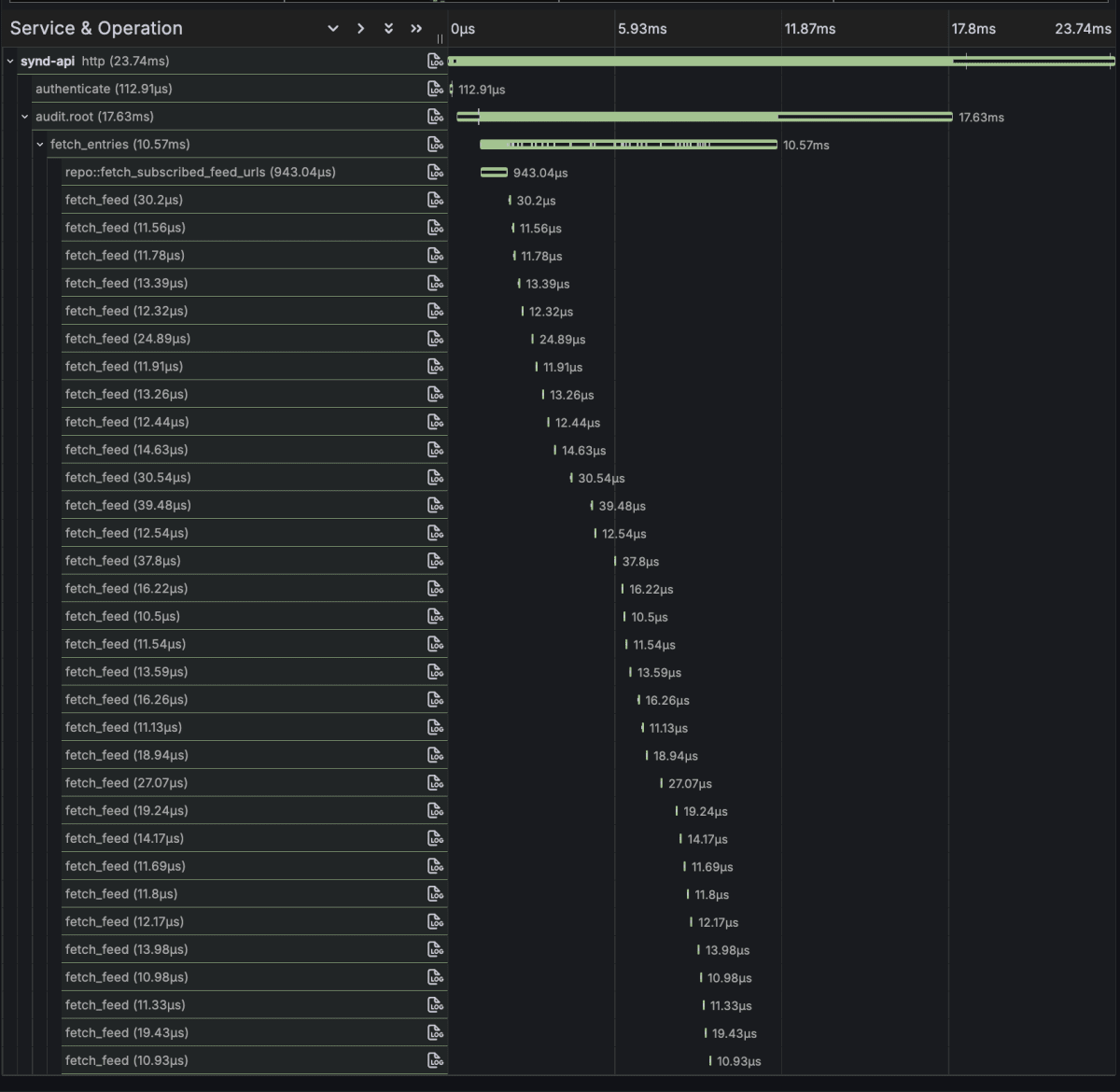
処理のtraceは以下のようになっています。
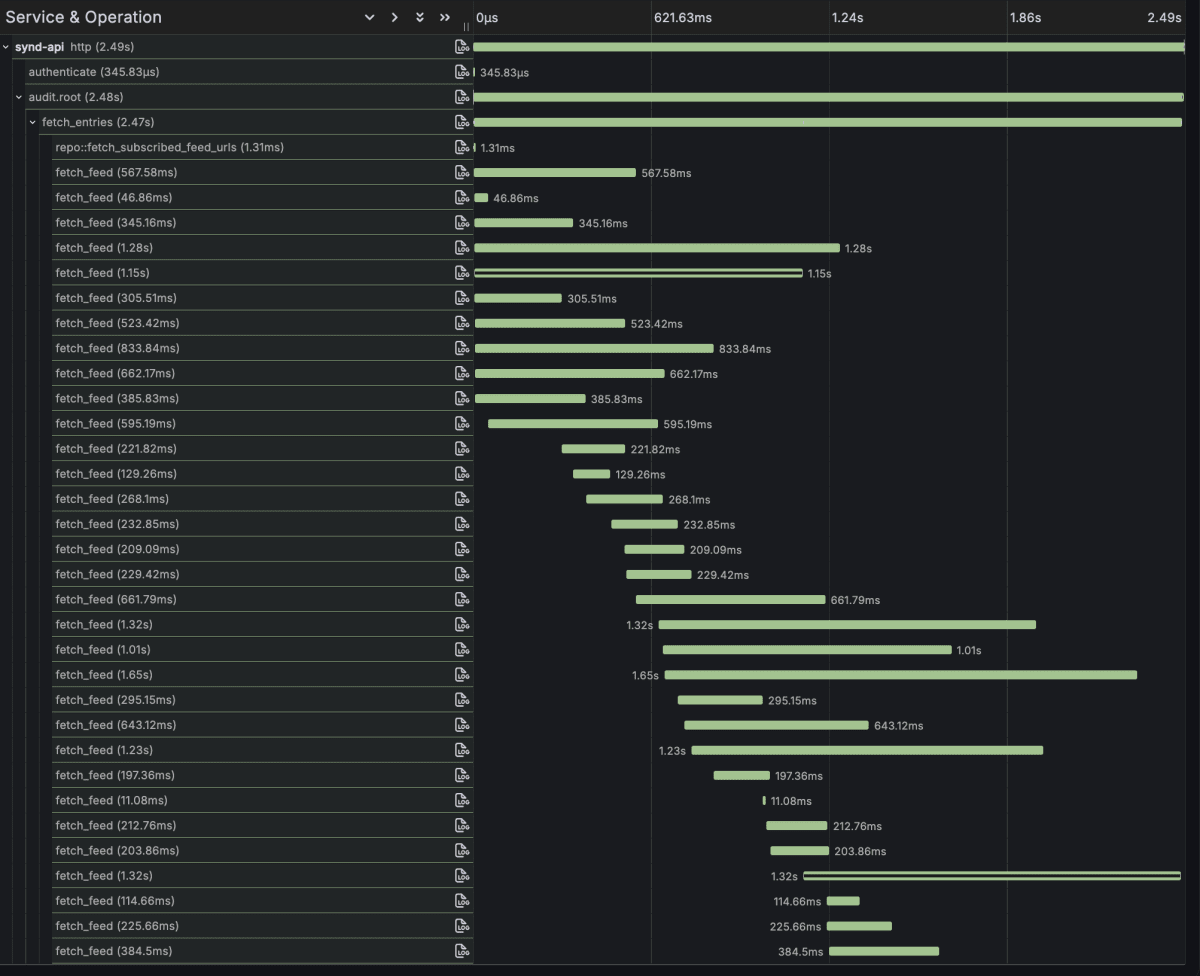
fetch_feed spanが1 Feedの取得処理を表しており、http requestの待機をmetricsで表現できていそうです。
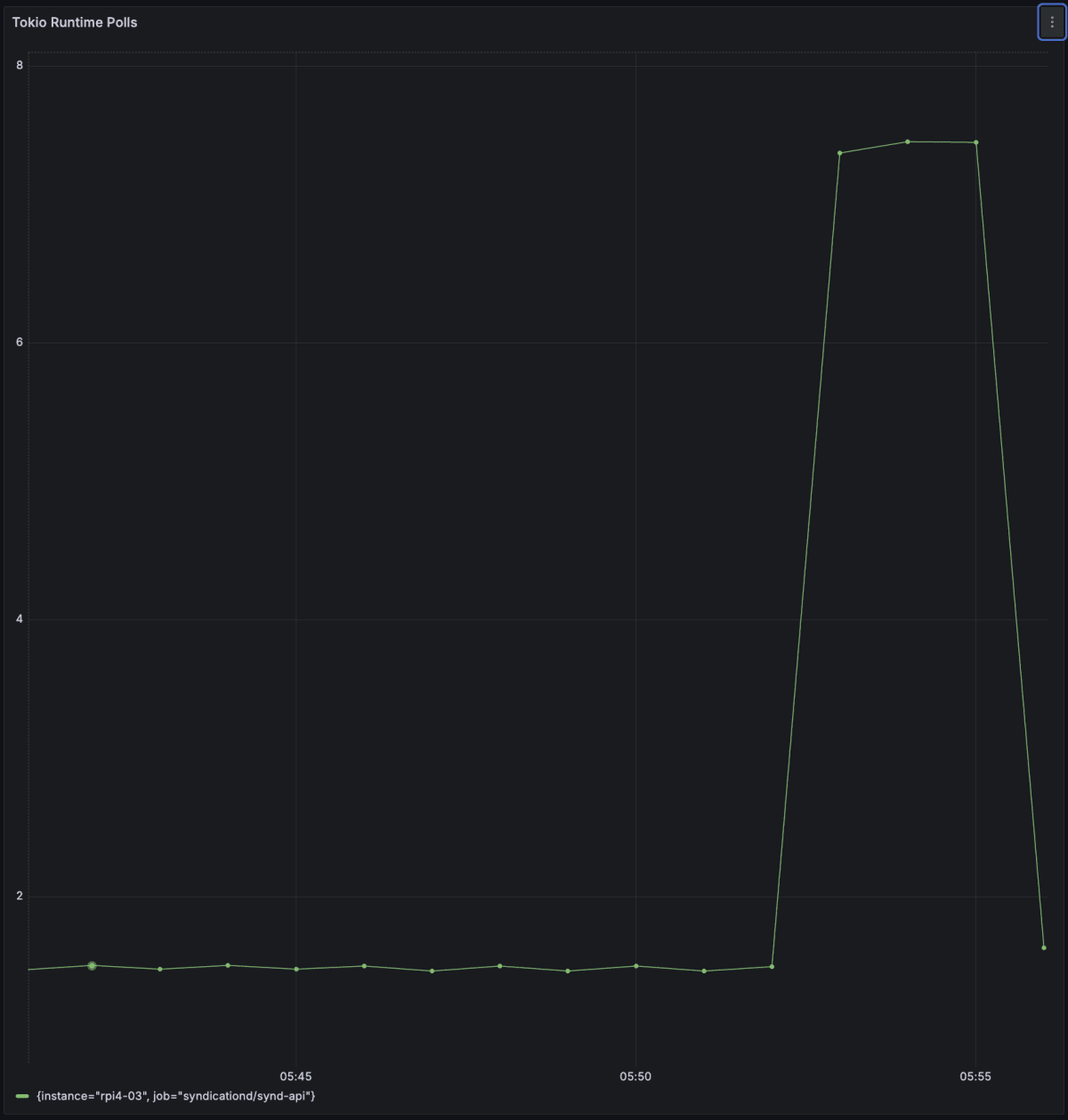
Runtime poll
Runtime busy
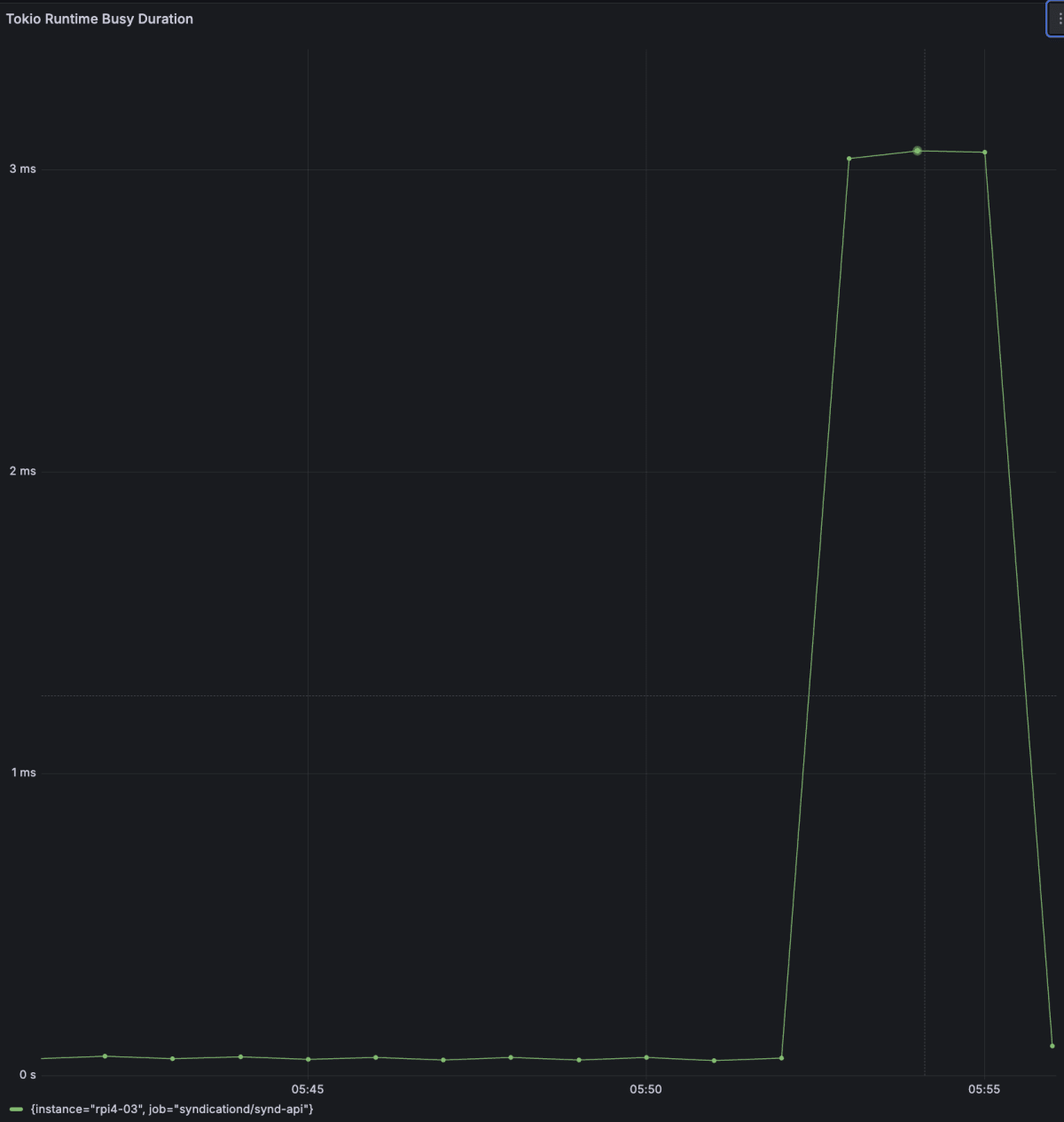
Runtimeのmetricsも増加を確認できました。
requestされたfeedはserver側で一定時間cacheしています。連続してさきほど行なったfeed取得をrequestした場合、cacheにhitするので、http requestは行われません。
Metricsをみてみると今度は、idleが低くなっていることがわかります。
Traceを確認するとfeedはcacheから取得しているので、確かにI/Oは行われていなさそうです。
まとめ
tokio-metricsを利用して、taskとruntimeのmetricsの取得を始めることができました。
まだまだ生かしきれていないmetricsがあるので、運用しながらいろいろなmetricsを試していきたいと思っています。
ここまでお読みいただきありがとうございました。
Discussion