kube-rsを使ってRustで簡単なKubernetes Operatorを作ってみる
社内で行っているRustの勉強会でkube-rsを利用したKubernetes operatorを扱いました。
本記事ではそこで学んだkube-rsの使い方や仕組みについて書きます。
概要としては、Hello Custom Resourceを定義してmanifestをapplyすると、対応するDeploymentをoperatorが作成し、manifestを削除するとDeploymentを削除するまでを実装します。
TL;DR
- kube-rsを利用するとRustから簡単にkubernetes apiを利用できる
- CRDをrustで定義することができ、yamlも出力できる
- Operatorのための機能も提供されているのでreconcileの処理に集中できる
前提
Kubernetes clusterとkubectlが利用できること。
dependenciesは以下の通りです。
[dependencies]
anyhow = { version = "1.0", default_features = false, features = ["std"] }
futures = { version = "0.3.28", default_features = false }
garde = { version = "0.15.0" , features = ["derive"] }
kube = { version = "0.85.0", default_features = false, features = ["client", "rustls-tls", "derive", "runtime"] }
k8s-openapi = { version = "0.19.0", default_features = false, features = ["v1_27"] }
schemars = { version = "0.8.12", default_features = false, features = ["derive"] }
serde = { version = "1.0", default_features = false, features = ["derive"]}
serde_json = { version = "1.0.105", default_features = false }
serde_yaml = { version = "0.9.25", default_features = false }
thiserror = { version = "1.0.47", default_features = false }
tokio = { version = "1.32.0", default_features = false, features = ["rt-multi-thread", "macros", "signal"] }
tracing = { version = "0.1.37", default_features = false }
tracing-subscriber = { version = "0.3.17", default_features = false, features = ["registry","fmt", "ansi", "env-filter" }
作成するoperatorはcargo runでlocalで起動します。その際、kubernetes apiとの通信のためにKUBECONFIG環境変数を参照してkubectlの設定fileを探します。
そのため、KUBECONFIGに検証するclusterへの設定がなされている状態が必要です。
自分はk3sを利用したので、以下のように設定しました。
$env.KUBECONFIG = /etc/rancher/k3s/k3s.yaml
Custom Resource
まずは本記事で扱っていくCustom Resource、Helloを定義します。
use garde::Validate;
use kube::{Api, Client, CustomResource, ResourceExt};
use schemars::JsonSchema;
use serde::{Deserialize, Serialize};
/// See docs for possible properties
/// https://docs.rs/kube/latest/kube/derive.CustomResource.html#optional-kube-attributes
#[derive(CustomResource, Debug, PartialEq, Clone, Serialize, Deserialize, JsonSchema, Validate)]
#[kube(
// Required properties
group = "fraim.co.jp",
version = "v1",
kind = "Hello",
// Optional properties
singular = "hello",
plural = "helloes",
shortname = "hlo",
namespaced,
)]
pub struct HelloSpec {
#[garde(range(max = 20))]
pub replicas: u32,
}
Userが定義する必要があるのは、specに対応するstructです。
ここでは、HelloSpecとしています。このstructに#[derive(kube::CustomResource)]を指定します。
CustomResourceによって概ね以下のようなcodeが生成されます。
#[serde(rename_all = "camelCase")]
#[serde(crate = ":: serde")]
pub struct Hello {
#[schemars(skip)]
pub metadata: ::k8s_openapi::apimachinery::pkg::apis::meta::v1::ObjectMeta,
pub spec: HelloSpec,
}
impl Hello {
/// Spec based constructor for derived custom resource
pub fn new(name: &str, spec: HelloSpec) -> Self {
Self {
metadata: ::k8s_openapi::apimachinery::pkg::apis::meta::v1::ObjectMeta {
name: Some(name.to_string()),
..Default::default()
},
spec: spec,
}
}
}
impl ::kube::core::Resource for Hello {
type DynamicType = ();
type Scope = ::kube::core::NamespaceResourceScope;
// ...
}
impl ::kube::core::crd::v1::CustomResourceExt for Hello { /* ... */}
生成された各種処理がどのように利用できるかは実装を進めるとわかってきます。
概要としては
-
specに対応するrootのresource(Hello)はderiveで生成される - 生成されたstructには
kube::Resourcetraitが実装されており、PodやDeployment等、apiのresourceとして扱える - CRD関連の機能は
kube::CustomResourceExttraitの実装を通じて提供される
CRDのapi group等の指定は#[kube()] annotationによって行えます。
#[kube(
// Required properties
group = "fraim.co.jp",
version = "v1",
kind = "Hello",
// Optional properties
singular = "hello",
plural = "helloes",
shortname = "hlo",
namespaced,
)]
pub struct HelloSpec { /* ... */ }
CRDの2重管理を避けられるように、以下のようにCustomResourceExt::crd()を利用することで、CRD yamlを生成することができます。
use example::Hello;
use kube::CustomResourceExt;
fn main() -> serde_yaml::Result<()> {
serde_yaml::to_writer(std::io::stdout(), &Hello::crd())
}
cargo run --quiet out> manifests/helloes-crd.yaml
生成されたyaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: helloes.fraim.co.jp
spec:
group: fraim.co.jp
names:
categories: []
kind: Hello
plural: helloes
shortNames:
- hlo
singular: hello
scope: Namespaced
versions:
- additionalPrinterColumns: []
name: v1
schema:
openAPIV3Schema:
description: Auto-generated derived type for HelloSpec via `CustomResource`
properties:
spec:
description: See docs for possible properties https://docs.rs/kube/latest/kube/derive.CustomResource.html#optional-kube-attributes
properties:
replicas:
format: uint32
minimum: 0.0
type: integer
required:
- replicas
type: object
required:
- spec
title: Hello
type: object
served: true
storage: true
subresources: {}
生成されたyamlをapplyすることで、Hello CRDを定義できます。
kubectl apply -f manifests/helloes-crd.yaml
customresourcedefinition.apiextensions.k8s.io/helloes.fraim.co.jp created
kubectl get crds | rg helloes
helloes.fraim.co.jp
kube-rsを利用してCRDをapplyする例も用意されていましたが今回はkubectlを利用しました。
最初は、operator起動時にCRDをapplyする処理があれば、operatorのuserが自身でCRDを適用する必要がなく便利だと考えていました。
しかしながら、そのためにはoperatorにcluster scopeのCRD作成権限の付与が必要で、通常それは大きすぎる権限のため、operatorには処理に必要な権限のみ付与して、CRDの適用は別で行うほうがよいとアドバイスされていました。
自分がこれまでに扱ってきたoperatorでもoperatorのdeployとCRDの適用は別で行う必要があったので、そういう理由だったのかと納得できました。
CRDのValidation
kube-rsのSchema ValidationではCRDのvalidationとして、server-sideとclient-sideの2種類の方法があると紹介されています。
Server side validation
Server sideのvalidationはvalidationの情報を生成されるschemaに埋め込むものです。
少々複雑なのが、kube-rsはvalidationの機構をvalidatorからgardeに変更しているのですが、schema生成を担うschemarsではvalidatorを採用していることです。
その結果、structのfieldにvalidatorのannotationを書くとschemars側でrespectされて生成されたschemaに反映されたりします。
また、自前でschemaを生成することもできます。
Client side validation
kube-rsのdocではserver-sideとclient-sideが並列に扱われていますが、client sideは自前でoperatorのcodeにvalidationの呼び出しを書くだけで、なにかkubernetes apiやkube-rs側で特別扱いされているわけではありません。kube-rsもdev-dependencies以外ではgardeに依存していませんでした。
そのため、CRDのstructにgardeのannotationを付与して生成されるvalidation() methodもoperatorの処理で呼び出す必要があります。
Server side validationとの違いは、kubectl apply時にvalidationがerrorになるかどうかと理解しています。
Operator
CRDが適用できたので、次にこのCRをwatchするoperatorを動かしていきます。
まずmainを含めたOperatorの起動処理は以下のように行いました。
use anyhow::Context as _;
use example::Operator;
use kube::Client;
use tracing::{error, info};
async fn signal() {
tokio::signal::ctrl_c()
.await
.expect("Failed to listen signal");
info!("Receive signal");
}
async fn run() -> anyhow::Result<()> {
let kube_client = Client::try_default()
.await
.context("Expected a valid KUBECONFIG environment variable")?;
Operator::new().run(kube_client, signal()).await;
info!("Operator shutdown completed");
Ok(())
}
#[tokio::main]
async fn main() {
init_tracing(); // 省略
info!("Running...");
if let Err(err) = run().await {
error!("{err:?}");
}
}
kube::Client::try_default()がkubernetes clientの生成処理です。環境変数KUBECONFIGや~/.kube/configの設定fileを参照してくれます。operatorがclusterの中にいるか今回のように外にいる場合両対応してくれます。
Operator::new()が今回実装するoperatorです、第2引数のsignal()は終了を通知するfutureです。
use std::{fmt, future::Future, sync::Arc, time::Duration};
use futures::stream::StreamExt;
use k8s_openapi::api::apps::v1::Deployment;
use kube::{
api::ListParams,
runtime::{
self,
controller::Action,
events::{EventType, Recorder, Reporter},
finalizer::{finalizer, Event},
watcher, Controller,
},
Api, Client, Resource, ResourceExt,
};
pub struct Operator;
impl Operator {
pub fn new() -> Self {
Self
}
/// Initialize operator and start reconcile loop.
pub async fn run<F>(self, client: Client, shutdown: F)
where
F: Future<Output = ()> + Send + Sync + 'static,
{
let crd_api: Api<Hello> = Api::all(client.clone());
let context: Arc<Context> = Arc::new(Context::new(client.clone()));
let wc = watcher::Config::default().any_semantic();
// Check whether CRD is installed
if let Err(err) = crd_api.list(&ListParams::default().limit(1)).await {
error!("Failed to list CRD: {err:?}. make sure CRD installed");
std::process::exit(1);
}
let deployment = Api::<Deployment>::all(client.clone());
let deployment_wc = watcher::Config::default()
.any_semantic()
.labels("operator.fraim.co.jp/managed-by=example-operator");
Controller::new(crd_api, wc)
.graceful_shutdown_on(shutdown)
.owns(deployment, deployment_wc)
.run(Operator::reconcile, Operator::handle_error, context)
.for_each(|reconciliation_result| async move {
match reconciliation_result {
Ok(echo) => info!("Reconciliation successful. Resource: {echo:?}"),
Err(reconciliation_err) => {
error!("Reconciliation error: {reconciliation_err:?}")
}
}
})
.await;
}
// ...
}
順番にみていきます。
let crd_api: Api<Hello> = Api::all(client.clone());
kube::Apiは以下のように定義されています。
#[derive(Clone)]
pub struct Api<K> {
/// The request builder object with its resource dependent url
pub(crate) request: Request,
/// The client to use (from this library)
pub(crate) client: Client,
namespace: Option<String>,
/// Note: Using `iter::Empty` over `PhantomData`, because we never actually keep any
/// `K` objects, so `Empty` better models our constraints (in particular, `Empty<K>`
/// is `Send`, even if `K` may not be).
pub(crate) _phantom: std::iter::Empty<K>,
}
基本的には、impl<K: Resource> Api<K> {}でKがResource traitを実装している前提となっています。
Resource traitはKubernetesのresourceの情報取得用のmethodを定義しているtraitです。DynamicTypeはcompile時に情報のないResourceを扱う仕組みのようですが、本記事では割愛します。
pub trait Resource {
type DynamicType: Send + Sync + 'static;
type Scope;
fn kind(dt: &Self::DynamicType) -> Cow<'_, str>;
fn group(dt: &Self::DynamicType) -> Cow<'_, str>;
fn version(dt: &Self::DynamicType) -> Cow<'_, str>;
// ...
Api<Hello>とできるのは、#[derive(CustomResource)]でHelloにResource traitが実装されているからです。(DynamicType = ())
let context: Arc<Context> = Arc::new(Context::new(client.clone()));
Contextはreconcile時に引き回す型で、自前で定義したものです。
let wc = watcher::Config::default().any_semantic();
kube::runtime::watcher::Configはkubernetes apiにResourceを問い合わせる際のparameterです。
any_semantics()についてはこちらを参照。
// Check whether CRD is installed
if let Err(err) = crd_api.list(&ListParams::default().limit(1)).await {
error!("Failed to list CRD: {err:?}. make sure CRD installed");
std::process::exit(1);
}
Operator起動時に対象のclusterにCRDがinstallされているかを確認しています。
let deployment = Api::<Deployment>::all(client.clone());
let deployment_wc = watcher::Config::default()
.any_semantic()
.labels("operator.fraim.co.jp/managed-by=example-operator");
今回は、Helloresourceに基づいてDeploymentを作成するために、Deployment用のApiを生成しています。
watcher::Configには監視対象のリソースのselectorを指定できるようになっており、関心があるDeploymentはこのoperatorによって作成されたものだけなので、labelを付与しています。
Controller::new(crd_api, wc)
.graceful_shutdown_on(shutdown)
.owns(deployment, deployment_wc)
.run(Operator::reconcile, Operator::handle_error, context)
.for_each(|reconciliation_result| async move {
match reconciliation_result {
Ok(echo) => info!("Reconciliation successful. Resource: {echo:?}"),
Err(reconciliation_err) => {
error!("Reconciliation error: {reconciliation_err:?}")
}
}
})
.await;
kube::runtime::Controllerがkube-rsが提供してくれているOperatorの実装です。実態としてはkube-runtime crateをre-exportしたものです。
-
graceful_shutdown_on(): 渡したfutureがreadyになった際にshutdownしてくれます。-
shutdown_on_signal()も用意されており、この場合Controller側でsignalを監視してくれます。unit test時にはsignalに頼ることなく終了を制御できるので、futureを渡すほうが自分は好きです。
-
-
owns(): 監視するsub resourceを指定します。今回はDeploymentresourceを作成するので、owns()にdeployment用のapiとwatch::Configを渡しています。- これによって管理している
Deploymentの変更があった場合にもreconcile処理がcallされます -
metadata.ownerReferencesを設定する必要があります
- これによって管理している
-
run(): Operatorのreconcile処理とerror時のretry設定、引き回すcontextを指定します -
for_each(): reconcileの結果を処理します。- これは
Controllerのmethodではなく、run()の戻り値、futures::Stream(StreamExt)のmethodです。
- これは
というように基本的にuser側で、clientの初期化、監視対象リソースの指定を行った後にreconcile処理を渡すだけで、operatorを動かせるようになっています。
Reconcile
次にメインとなるreconcile処理をみていきます。まず、kube::runtime::Controller::run()のsignatureは以下のようになっています。
pub fn run<ReconcilerFut, Ctx>(
self,
mut reconciler: impl FnMut(Arc<K>, Arc<Ctx>) -> ReconcilerFut,
error_policy: impl Fn(Arc<K>, &ReconcilerFut::Error, Arc<Ctx>) -> Action,
context: Arc<Ctx>,
) -> impl Stream<Item = Result<(ObjectRef<K>, Action), Error<ReconcilerFut::Error, watcher::Error>>>
where
K::DynamicType: Debug + Unpin,
ReconcilerFut: TryFuture<Ok = Action> + Send + 'static,
ReconcilerFut::Error: std::error::Error + Send + 'static,
{ /* ... */}
第1引数のreconcilerにはreconcile関数を渡します。Arc<K>はここでは、Arc<Hello>となります。
結果はTryFutureなので、asyncで、Result<kube::runtime::controller::Action,MyError>を返します。
Actionはreconcile処理の結果で、kube-runtimeのControllerの中にschedulerに渡され次回のreconcileのschedulingに反映されます。
impl Action {
/// Action to the reconciliation at this time even if no external watch triggers hit
///
/// This is the best-practice action that ensures eventual consistency of your controller
/// even in the case of missed changes (which can happen).
///
/// Watch events are not normally missed, so running this once per hour (`Default`) as a fallback is reasonable.
#[must_use]
pub fn requeue(duration: Duration) -> Self {
Self {
requeue_after: Some(duration),
}
}
/// Do nothing until a change is detected
///
/// This stops the controller periodically reconciling this object until a relevant watch event
/// was **detected**.
///
/// **Warning**: If you have watch desyncs, it is possible to miss changes entirely.
/// It is therefore not recommended to disable requeuing this way, unless you have
/// frequent changes to the underlying object, or some other hook to retain eventual consistency.
#[must_use]
pub fn await_change() -> Self {
Self { requeue_after: None }
}
}
となっており、明示的にAction::requeue()で次回のscheduling期間を定めるか、Action::await_change()でResource(Hello)に変更があるまで、reconcileを指定しなことが選べます。ここでどちらの方法を選択しても、監視Resourceが変更された場合にはreconcile処理は起動されるので、await_change()でいいのではと思いましたが、コメントで指摘されているとおり、kubernetesの各種eventは様々な要因で、operatorに伝わらないことがあり得るので、短い頻度で変更されることがわかっている状況以外では、requeue()が良さそうです。
第2引数のerror_policy: impl Fn(Arc<K>, &ReconcilerFut::Error, Arc<Ctx>) -> Actionはerror時の挙動を制御するためのものです。
ReconcilerFut::Errorはuserが定義するので、errorの要因が外部にある場合には、短くrequeueの時間を指定して、回復できるかを確認するといったことができそうです。
第3引数のcontext: Arc<Ctx>はreconcileで引き回す情報で、今回は定義したContextが使われます。定義は以下です。
use kube::Client;
use kube::runtime::events::Reporter;
pub struct Context {
client: Client,
reporter: Reporter,
}
Reporterはkubernetesのeventを出力するための仕組みで、のちほど使い方をみていきます。
ということでreconcile処理の実装を行っていきます。
impl Operator {
#[tracing::instrument(skip_all)]
async fn reconcile(hello: Arc<Hello>, context: Arc<Context>) -> Result<Action, Error> {
// Validate spec
if let Err(err) = hello.spec.validate(&()) {
context
.recorder(&hello)
.publish(runtime::events::Event {
type_: EventType::Warning,
action: "Reconcile".into(),
reason: "Invalid spec".into(),
note: Some(format!("Invalid Hello spec: {err}")),
secondary: None,
})
.await?;
return Err(Error::invalid_spec(err));
}
let client = context.client.clone();
let api = hello.api(client)?;
let action = finalizer(&api, RESCOUCE_DOMAIN, hello, |event| async {
match event {
Event::Apply(hello) => Self::reconcile_hello(hello, context).await,
Event::Cleanup(hello) => Self::cleanup_hello(hello, context).await,
}
})
.await
.map_err(|e| Error::FinalizerError(Box::new(e)))
}
}
順番に見ていきます。まず関数のsignatureですが
async fn reconcile(hello: Arc<Hello>, context: Arc<Context>) -> Result<Action, Error> { }
Reconcileが必要なHello resourceが渡されます。Helloのspecを確認してあるべき状態を実現したのちに次にいつreconcileをschedulingするかを返すのがreconcile()の役割です。
このsignatureでまず思ったことが、どうしてreconcileがtriggerされたかの理由が与えられていないことです。
そのため、Helloが削除されたのか、作成されたのか、更新されたのかが与えられていないので、Helloの定義やmetadataを確認してあるべき状態を判定するのもoperatorの責務となります。kube-rsのdocでは、これは意図的な設計とされています。
どういうことかというと、仮にreconcileのsignatureが以下のようにreconcileの理由も与えられるものだったとします。
async fn reconcile(hello: Arc<Hello>, context: Arc<Context>, reason: ReconcileReason /* 👈 */ ) -> Result<Action,Error> { }
Reconcileの理由がわかっているとuserとしては以下のような処理を書きたくなります。
async fn reconcile(hello: Arc<Hello>, context: Arc<Context>, reason: ReconcileReason /* 👈 */ ) -> Result<Action,Error> {
match reason {
ReconcileReason::Created(obj) => crete_hello(obj),
ReconcileReason::Modified(obj) => update_hello(obj),
ReconcileReason::Deleted(obj) => delete_hello(obj),
// ...
}
}
しかしながら、このような実装してしまうとなんらかの理由でDeleted eventを見逃してしまうと(operatorの再起動等)、Hello resourceを削除するタイミングを逸してしまいます。
そこで、意図的にreconcileの理由に依存させないようにするために現在のsignatureになっていると理解しています。
Validation
Reconcile時にまずvalidationを行うようにしました。
// Validate spec
if let Err(err) = hello.spec.validate(&()) {
context
.recorder(&hello)
.publish(runtime::events::Event {
type_: EventType::Warning,
action: "Reconcile".into(),
reason: "Invalid spec".into(),
note: Some(format!("Invalid Hello spec: {err}")),
secondary: None,
})
.await?;
return Err(Error::invalid_spec(err));
}
hello.spec.validate(&())は最初にHelloSpecに定義したgarde::Validateによるものです。 (引数はgardeの機構でvalidation時に引数渡せる仕組みなのでここでは())
#[derive(CustomResource, /* ... */ garde::Validate /* 👈 これ */)]
#[kube(
// Required properties
group = "fraim.co.jp",
version = "v1",
kind = "Hello",
// ...
)]
pub struct HelloSpec {
#[garde(range(max = 20))] // 👈 これがvalidation
pub replicas: u32,
}
Helloのspecがvalidationに違反している場合、rencocileを継続できません。
Operatorとしてはlogに出力する以外でuserにこのこと伝えることはできるでしょうか。
ここでは、kube-rsが用意してくれたevent出力の仕組みを利用して、Kubernetesのeventとしてvalidation違反を表現してみます。
kube::runtime::events::Recorderはevent出力の詳細を隠蔽してくれている型で、事前にoperatorの名前やResourceの識別子から生成できます。
Eventを出力すると以下のようにkubectlから確認できます。
> kubectl get events --field-selector 'involvedObject.kind==Hello,type=Warning'
LAST SEEN TYPE REASON OBJECT MESSAGE
5m44s Warning InvalidSpec hello/hello Invalid Hello spec: replicas: greater than 20
5m34s Warning InvalidSpec hello/hello Invalid Hello spec: replicas: greater than 20
上記はHelloSpec.replicasの値をmaxを超えて指定したものです。gardeとあわせてわかりやすいメッセージが出力できています。
Validationが済んだので次はHelloのreconcile処理です。
まず行う必要があるのが、Helloを削除すべきなのか、作成/更新すべきかの判断です。
これを判断するには、metadata.deletionTimestampが設定されているかを確認します。
また、仮にmetadata.deletionTimestampが設定されている場合は、Helloの関連Resourceを削除したのち、metadata.finalizersの更新が必要です。
このあたりの判定や処理はoperator共通の約束ごとに基づくものなので、kube-rs側で便利な処理を提供してくれています。
それがkube::runtime::finalizer::finalizerです。
use kube::runtime::finalizer::finalizer;
async fn reconcile(hello: Arc<Hello>, context: Arc<Context>) -> Result<Action, Error> {
// ...
let client = context.client.clone();
let api = hello.api(client)?;
finalizer(
&api,
&format!("fraim.co.jp/{}", Operator::NAME),
hello,
|event| async {
match event {
Event::Apply(hello) => Self::reconcile_hello(hello, context).await,
Event::Cleanup(hello) => Self::cleanup_hello(hello, context).await,
}
},
)
.await
.map_err(|e| Error::FinalizerError(Box::new(e)))
}
ここでの必要な処理は以下です。
-
Hello初回作成時はmetadata.finalizersに識別子を追加したのち、reconcile処理を実行 - 更新時はreconcile処理のみ実行
- 初回削除時は、削除用のreconcile処理を実行したのち、
metadata.finalizersから追加した識別子を削除 -
metadata.finalizersに自身の識別子がない場合の削除時はなにもしない
kube::runtime:finalizer::finalizerは削除の判定やfinalizerの処理を適切に実施したのちに、userからclosureで渡されたreconcile処理を実行してくれます。
その際、applyかcleanupかを教えてくれるので、そこで処理を分岐させます。
実装をみてみると、metadata.finalizers: ["aaa", "bbb"]のようなarray型の更新をatomic(競合しないように)に処理してくれており、参考になります。
実際に操作することでFinalizersの仕組みの理解が進みました。operator作ってみることでkubernetesのことをいろいろ調べられるので楽しいです。
Hello Apply
Validation, finalizer処理が済んだのでいよいよ、Helloの実態のDeploymentを作成していきます。
#[tracing::instrument(skip_all)]
async fn reconcile_hello(hello: Arc<Hello>, context: Arc<Context>) -> Result<Action, Error> {
let name = hello.name_any();
let namespace = hello.namespace().ok_or_else(Error::no_namespace)?;
let owner_ref = hello
.controller_owner_ref(&())
.expect("Hello has owner_reference");
deploy(
context.client.clone(),
&name,
hello.spec.replicas,
owner_ref,
&namespace,
)
.await?;
info!("Reconcile hello");
Ok(Action::requeue(Duration::from_secs(60 * 10)))
}
use k8s_openapi::api::apps::v1::Deployment, DeploymentSpec;
pub async fn deploy(
client: Client,
deployment_name: &str,
replicas: u32,
owner_ref: OwnerReference,
namespace: &str,
) -> Result<Deployment, kube::Error> { /* ... */ }
Helloから必要な情報を抽出して、KubernetesのDeploymentを作成する処理を呼び出します。
hello.name_any()はmetadata.nameがあれば利用し、設定されていなければgenerateされたものを利用します。
hello.namespace()はmetadata.namespaceを参照します。manifestに設定されていなければerrorとします。
hello.controller_owner_ref(&())はmetadata.ownerReferencesを取得するものです。作成するDeploymentのmetadataに付与することで、依存関係を表現します。これを付与しておかないと作成したDeploymentの変更でoperatorのreconcileがtriggerされないので注意が必要です。
続いてDeploymentをapplyする処理です。
use std::collections::BTreeMap;
use k8s_openapi::{
api::{
apps::v1::{Deployment, DeploymentSpec},
core::v1::{Container, ContainerPort, PodSpec, PodTemplateSpec},
},
apimachinery::pkg::apis::meta::v1::{LabelSelector, OwnerReference},
};
use kube::{
api::{DeleteParams, ObjectMeta, Patch, PatchParams},
error::ErrorResponse,
Api, Client,
};
pub async fn deploy(
client: Client,
deployment_name: &str,
replicas: u32,
owner_ref: OwnerReference,
namespace: &str,
) -> Result<Deployment, kube::Error> {
let mut labels = BTreeMap::<String, String>::new();
labels.insert(
"app.kubernetes.io/name".to_owned(),
deployment_name.to_owned(),
);
labels.insert(
"operator.fraim.co.jp/managed-by".to_owned(),
"example-operator".to_owned(),
);
let deployment: Deployment = Deployment {
metadata: ObjectMeta {
name: Some(deployment_name.to_owned()),
namespace: Some(namespace.to_owned()),
owner_references: Some(vec![owner_ref]),
labels: Some(labels.clone()),
..Default::default()
},
spec: Some(DeploymentSpec {
replicas: Some(replicas as i32),
selector: LabelSelector {
match_expressions: None,
match_labels: Some(labels.clone()),
},
template: PodTemplateSpec {
metadata: Some(ObjectMeta {
labels: Some(labels),
..Default::default()
}),
spec: Some(PodSpec {
containers: vec![Container {
name: deployment_name.to_owned(),
image: Some("nginxdemos/hello:0.3-plain-text".to_owned()),
ports: Some(vec![ContainerPort {
container_port: 8080,
..ContainerPort::default()
}]),
..Container::default()
}],
..PodSpec::default()
}),
},
..DeploymentSpec::default()
}),
..Deployment::default()
};
let api: Api<Deployment> = Api::namespaced(client, namespace);
api.patch(
deployment.metadata.name.as_deref().unwrap(),
&PatchParams::apply(Operator::NAME),
&Patch::Apply(&deployment),
)
.await
}
labelを設定したのち、基本的にはDeploymentのmanifestと同じ情報を設定していきます。
let api: Api<Deployment> = Api::namespaced(client, namespace);
api.patch(
deployment.metadata.name.as_deref().unwrap(),
&PatchParams::apply(Operator::NAME),
&Patch::Apply(&deployment),
)
.await
Api::patch()でPatch::Applyを利用するとServer side applyが利用できます。&PatchParams::apply()にはServer side applyで利用するfield managerを指定します。
Hello delete
最後はdelete処理を確認します。
#[tracing::instrument(skip_all)]
async fn cleanup_hello(hello: Arc<Hello>, context: Arc<Context>) -> Result<Action, Error> {
let name = hello.name_any();
let namespace = hello.namespace().ok_or_else(Error::no_namespace)?;
delete(context.client.clone(), &name, &namespace).await?;
context
.recorder(&hello)
.publish(runtime::events::Event {
type_: EventType::Normal,
action: "Deleting".into(),
reason: "DeleteRequested".into(),
note: Some(format!("Delete {name}")),
secondary: None,
})
.await?;
info!("Cleanup hello");
Ok(Action::await_change())
}
pub async fn delete(client: Client, name: &str, namespace: &str) -> Result<(), kube::Error> {
let api: Api<Deployment> = Api::namespaced(client, namespace);
match api.delete(name, &DeleteParams::default()).await {
Ok(_) => Ok(()),
Err(kube::Error::Api(ErrorResponse { code: 404, .. })) => Ok(()),
Err(err) => Err(err),
}
}
基本的な流れは同様です。削除後にeventを出力するようにしてみました。
いまいち、eventの出力基準がわかっていないので既存のresourceや他のoperatorの処理を参考にどんなeventを出力していくと良いか調べていきたいです。
tracing
Reconcile時のtracingについて。まずreconcile時にspanを作成したくなりますが、kube-rs側で作成してくれています。
let reconciler_span = info_span!(
"reconciling object",
"object.ref" = %request.obj_ref,
object.reason = %request.reason
);
reconciler_span
.in_scope(|| reconciler(Arc::clone(&obj), context.clone()))
// ...
上記のようなspanの中でuser側のreconcile処理を呼んでくれているので、user側でresourceの識別子をlogにだす必要がありません。
INFO reconciling object{object.ref=Hello.v1.fraim.co.jp/hello.default object.reason=object updated}:reconcile: "User Message!"
概ね上記のようなspanになっていました。
また、LOG_LOG=kube=debugのようにkube moduleにdebugを指定すると
DEBUG HTTP{http.method=GET http.url=https://127.0.0.1:6443/apis/fraim.co.jp/v1/helloes?&limit=500&resourceVersion=0&resourceVersionMatch=NotOlderThan otel.name="list" otel.kind="client"}: /foo/.cargo/registry/src/index.crates.io-6f17d22bba15001f/kube-client-0.85.0/src/client/builder.rs:127: requesting
otel.name,otel.kindのようにtracing-opentelemetryを利用して、opentelemetry用のtraceも作ってくれて素晴らしいです。
検証
最後に作成したoperatorを動かして、manifestをapply,deleteしてみます。
適用するmanifestは以下です。
apiVersion: fraim.co.jp/v1
kind: Hello
metadata:
name: hello
spec:
replicas: 2
> kubectl apply -f manifests/hello.yaml
hello.fraim.co.jp/hello created
> kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
hello 2/2 2 2 9s
> kubectl port-forward deployments/hello 8000:80
Forwarding from 127.0.0.1:8000 -> 80
Forwarding from [::1]:8000 -> 80
# another terminal
> curl http://localhost:8000
Server address: 127.0.0.1:80
Server name: hello-b7f675f9-pcd7p
Date: 10/Sep/2023:12:19:19 +0000
URI: /
Request ID: 7152be71c211a7c507ec5d61ca47ae83
無事、deployできています。
次にvalidationに違反したmanifestをapplyしてみます。
---
apiVersion: fraim.co.jp/v1
kind: Hello
metadata:
name: hello
spec:
replicas: 100 # Invalid (max: 20)
> kubectl apply -f manifests/hello.yaml
> kubectl get events --field-selector 'involvedObject.kind==Hello,type=Warning'
LAST SEEN TYPE REASON OBJECT MESSAGE
5m4s Warning InvalidSpec hello/hello Invalid Hello spec: replicas: greater than 20
> kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
hello 2/2 2 2 9m24s
Validationに違反しており、eventの出力も確認できました。
ただ、apply自体はできてしまうので、表現できるならserver side validationのほうが良いのかなと思いました。
最後にmanifestをもとにもどして削除してみます。
> kubectl delete -f manifests/hello.yaml
hello.fraim.co.jp "hello" deleted
> kubectl get deployments
No resources found in default namespace.
無事削除できました。
まとめ
kube-rsを利用して簡単なoperatorを作ることができました。
ResourceのCRUD apiだけでなく、reconcile関連(kube_runtime)や、finalizer, event等の仕組みも用意されており、userがreconcileに集中できるようになっていることがわかりました。
参考
-
kube-rsのdoc
- 特に内部の実装の解説が非常にありがたかったです
- 勉強会で題材にしたoperatorのtutorial blog
- kube-rs projectで管理されている参照実装
-
Kubertes Operators オライリー本。
- FRAIMでは福利厚生でOreilly LearningのSubscriptionを利用できます📚
ボーナストラック
本記事では以下のようにapi(client)とwatchの設定を渡すとreconcile処理が呼ばれるとしました。
Controller::new(crd_api, wc)
// ...
.run(Operator::reconcile, Operator::handle_error, context)
// ...
ただ、内部の実装がどのようになっているかは気になるところです。
また、kube-rsのdocを読んでいるとwatcherや、reflectorといったコンポーネントへの言及がしばしばなされます。
実装の詳細な理解は長くなってしまうので別の記事にしたいと思いますが、ここではkube-rsが内部的にやってくれていることのメンタルモデルだけでも持てればと思います。
実際にはもっと複雑なのですが、概要としては、Controller::new()からController::run()にいたるまでのkube_runtimeの処理はすべてfutures::stream::Stream指向となっており、非常に感銘をうけました。
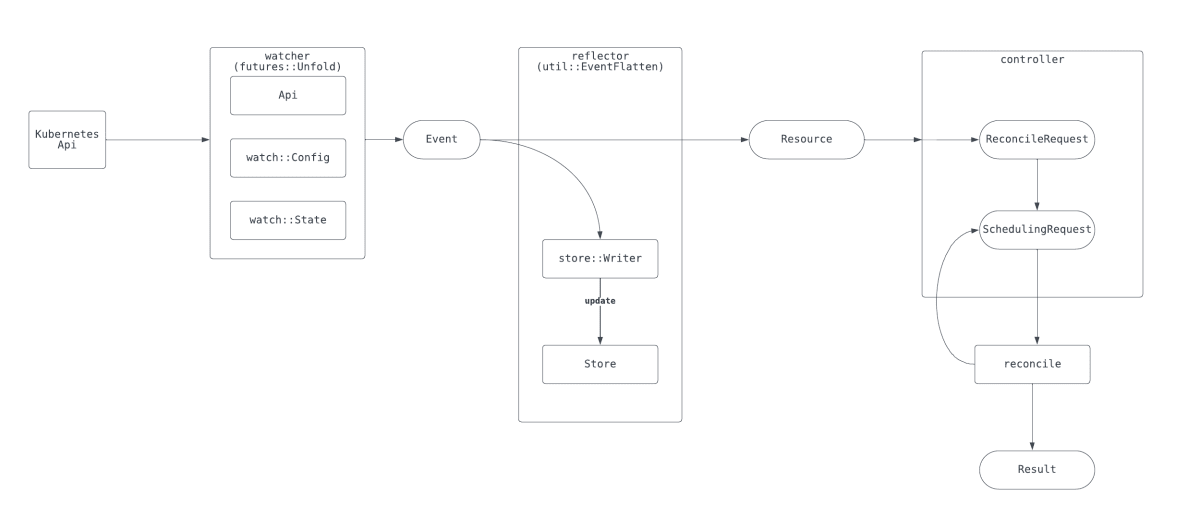
Streamは大きく、watcher, reflector, controllerで処理されています。
watcherは実際にkubernetes apiをcallしてresourceの監視結果を取得します。
reflectorは内部的にArc<RwLock<AHashMap<ObjectRef<Resource>,Arc<Resource>>>>型のstoreを保持しており、そこにresourceの情報をcacheしています。
controller側では、それらの情報や終了処理のsignal, scheduling等を行い、最終的にuserのreconcile処理をtriggerしています。
watcherやreflectorもpubとして公開されているので、operatorの実装以外でもkubernetes関連のtoolを作成する際には利用できそうだと思いました。
Discussion