👏
Pytorchでhyperparmeter searchするための Docker-composeのセットアップ( MySQL )
目的: Optunaを分散環境で動かす, ついでにtensorbaordで可視化
完成したコードはここにあります。
手順
- docker 及び docker-composeの準備
- optunaのsimple exampleを書く
注意:mysqlのパスワードを直書きしたりしてるのでセキュリティ的によくないです
Dockerで環境構築
FROM pytorch/pytorch:1.1.0-cuda10.0-cudnn7.5-runtime
ARG PYTHON_VERSION=3.6
RUN apt-get update
RUN apt-get install -y wget
RUN apt-get -y install language-pack-ja-base language-pack-ja ibus-mozc
RUN update-locale LANG=ja_JP.UTF-8 LANGUAGE=ja_JP:ja
ENV LANG ja_JP.UTF-8
ENV LC_ALL ja_JP.UTF-8
ENV LC_CTYPE ja_JP.UTF-8
RUN pip install -U pip
RUN pip install numpy matplotlib bokeh holoviews pandas tqdm sklearn joblib nose pandas tabulate xgboost lightgbm optuna nose coverage
RUN pip install torch torchvision
# install tensorboardX to /tmp for hparams in tensorboardX
RUN pip install -e git+https://github.com/eisenjulian/tensorboardX.git@add-hparam-support#egg=tensorboardX --src /tmp
RUN pip install tensorflow==1.14.0
RUN pip install future moviepy
# mysqlclient
RUN apt-get install -y libssl-dev
RUN apt-get update
RUN apt-get install -y python3-dev libmysqlclient-dev
RUN pip install mysqlclient
可視化のためにtensorboardもいれた
version: '2.3'
services:
optuna_pytorch:
build: ./
container_name: "optuna_pytorch"
working_dir: "/workspace"
ports:
- "6006:6006"
- "8888:8888"
#runtime: nvidia
volumes:
- .:/workspace
tty: true
db:
image: mysql:5.7
container_name: 'db'
ports:
- "3306:3306"
volumes:
# 初期データを投入するSQLが格納されているdir
- ./db/mysql_init:/docker-entrypoint-initdb.d
# 永続化するときにマウントするdir
- ./db/mysql_data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_USER: root
MYSQL_ALLOW_EMPTY_PASSWORD: 'yes'
MYSQL_DATABASE: optuna
MYSQL_DATABASE: optuna を用意しておくのがポイント (optuna_pytorchからはmysqlはdbというドメインで参照可能になっている)
optunaのコード
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data.dataset import Subset
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import optuna
from tensorboardX import SummaryWriter
#optuna.logging.disable_default_handler()
from tqdm import tqdm_notebook as tqdm
BATCHSIZE = 128
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
train_set = MNIST(root='./data', train=True,
download=True, transform=transform)
subset1_indices = list(range(0,6000))
train_set = Subset(train_set, subset1_indices)
train_loader = DataLoader(train_set, batch_size=BATCHSIZE,
shuffle=True, num_workers=2)
subset2_indices = list(range(0,1000))
test_set = MNIST(root='./data', train=False,
download=True, transform=transform)
test_set = Subset(test_set, subset2_indices)
test_loader = DataLoader(test_set, batch_size=BATCHSIZE,
shuffle=False, num_workers=2)
classes = tuple(np.linspace(0, 9, 10, dtype=np.uint8))
h_params = {}
print('finish data load')
EPOCH = 10
writer = SummaryWriter()
class Net(nn.Module):
def __init__(self, trial):
super(Net, self).__init__()
self.activation = get_activation(trial)
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv1_drop = nn.Dropout2d(p=trial.suggest_uniform("dropout_prob", 0, 0.8))
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = self.activation(F.max_pool2d(self.conv1(x), 2))
x = self.activation(F.max_pool2d(self.conv1_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = self.activation(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
def test(model, device, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
return 1 - correct / len(test_loader.dataset)
def get_optimizer(trial, model):
optimizer_names = ['Adam', 'MomentumSGD']
optimizer_name = trial.suggest_categorical('optimizer', optimizer_names)
h_params['opt_name'] = optimizer_name
weight_decay = trial.suggest_loguniform('weight_decay', 1e-10, 1e-3)
if optimizer_name == optimizer_names[0]:
adam_lr = trial.suggest_loguniform('adam_lr', 1e-5, 1e-1)
h_params['adam_lr'] = adam_lr
optimizer = optim.Adam(model.parameters(), lr=adam_lr, weight_decay=weight_decay)
else:
momentum_sgd_lr = trial.suggest_loguniform('momentum_sgd_lr', 1e-5, 1e-1)
h_params['momentum_sgd_lr'] = momentum_sgd_lr
optimizer = optim.SGD(model.parameters(), lr=momentum_sgd_lr,
momentum=0.9, weight_decay=weight_decay)
return optimizer
def get_activation(trial):
activation_names = ['ReLU', 'ELU']
activation_name = trial.suggest_categorical('activation', activation_names)
h_params['activation'] = activation_name
if activation_name == activation_names[0]:
activation = F.relu
else:
activation = F.elu
return activation
def objective_wrapper(pbar):
def objective(trial):
global writer
writer = SummaryWriter()
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Net(trial).to(device)
optimizer = get_optimizer(trial, model)
writer.add_hparams_start(h_params)
for step in range(EPOCH):
train(model, device, train_loader, optimizer)
error_rate = test(model, device, test_loader)
writer.add_scalar('test/loss', error_rate, step)
trial.report(error_rate, step)
if trial.should_prune(step):
pbar.update()
raise optuna.structs.TrialPruned()
pbar.update()
writer.add_hparams_end() # save hyper parameter
return error_rate
return objective
TRIAL_SIZE = 50
with tqdm(total=TRIAL_SIZE) as pbar:
study = optuna.create_study(pruner=optuna.pruners.MedianPruner(), study_name='distributed-mysql', storage='mysql://root:root@db/optuna', load_if_exists=True)
study.optimize(objective_wrapper(pbar), n_trials=TRIAL_SIZE, n_jobs=2)
print(study.best_params)
print(study.best_value)
df = study.trials_dataframe()
print(df.head)
df.to_csv('result.csv')
本質は
- optuna.create_study を作り
- trial.suggest_loguniform, trial.suggest_categorical で探索の候補を決め
- study.optimize で探索を実行する
あたりである。
とくにcreate_studyはDBの指定とpruningのルールも指定するところなので重要
documentをみるとよい
枝刈りのルールも確認しておくと良いここ
使い方
run
# create env
docker-compose up -d
docker exec -it optuna_pytorch /bin/bash
# run
python main.py
# remove env
exit
docker-compose down
最適化の過程はmysqlに記録されるのでmysqlが参照できる場所でmain.pyを動かせば分散環境での最適化になる!
結果をtensorboardで確認
# on host
docker exec -it optuna_pytorch /bin/bassh
tensorboard --logdir runs
# access to http://localhost:6006/#hparams on browser
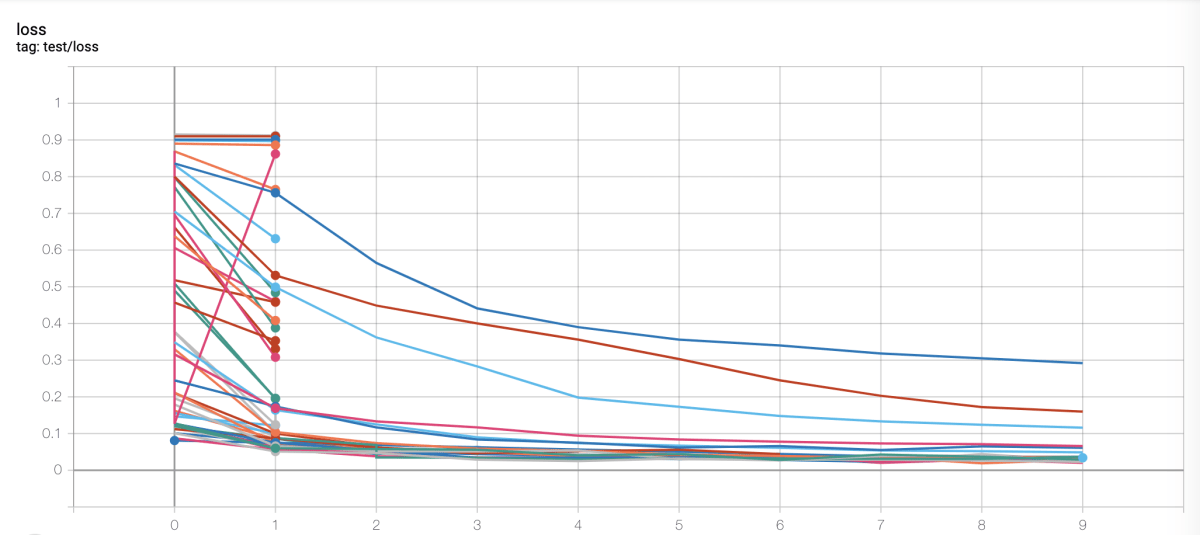
枝刈りが行われてるのがわかる

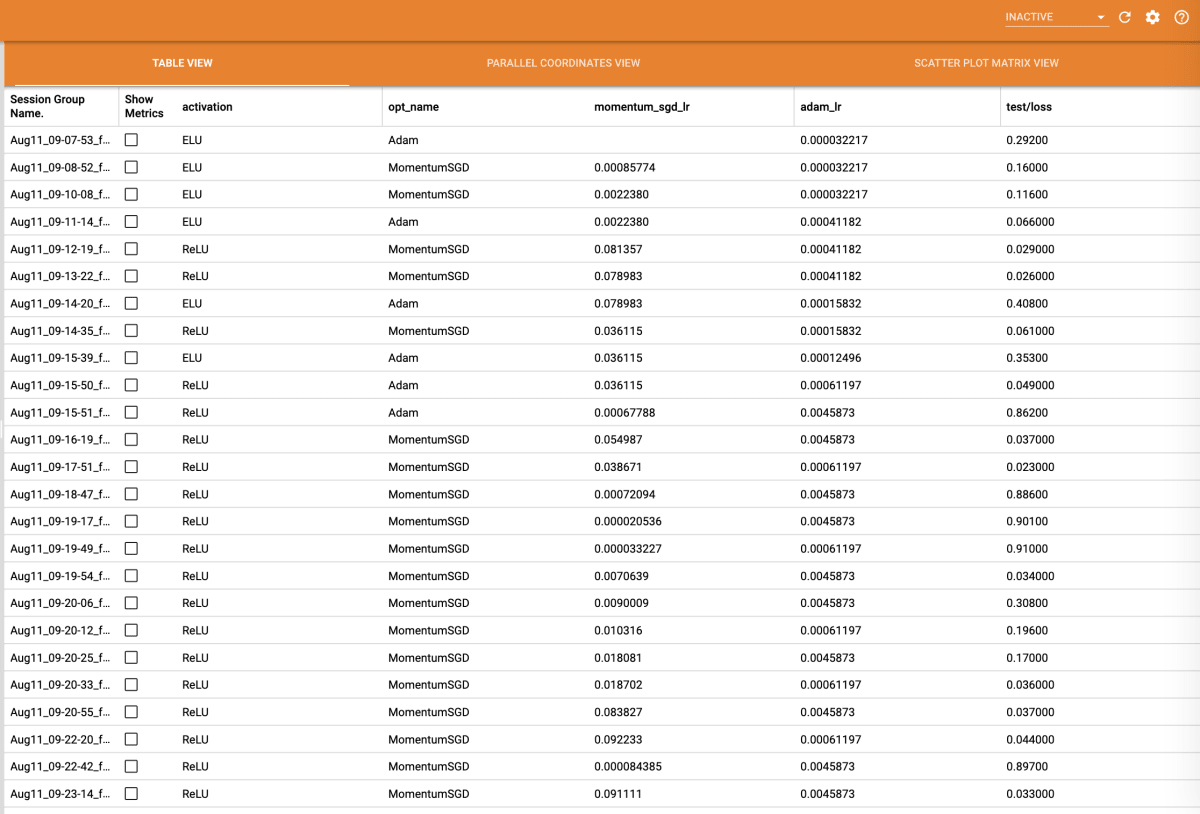
結果をmysqlから確認
# on host
# install mysql
brew install mysql
# check tables on Optuna db
mysql -h 127.0.0.1 --port 3306 -uroot -proot -D optuna -e 'show tables'
# check results on Optuna db
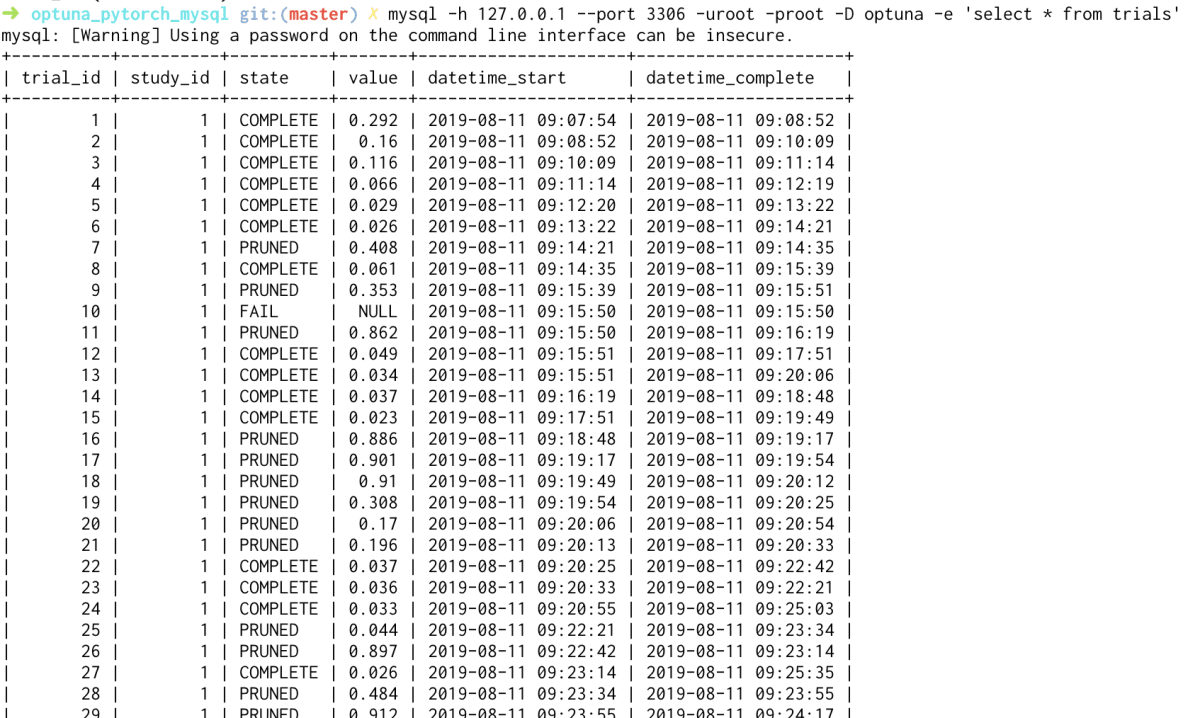
mysql -h 127.0.0.1 --port 3306 -uroot -proot -D optuna -e 'select * from trials'
結果の削除
mysql -h 127.0.0.1 --port 3306 -uroot -proot -D optuna -e 'drop database optuna'
Discussion