Event feedback article: Neo4j Study Event for beginners #1 (2024/11/4)
Docker で neo4j 環境構築
Docker が難しいという人は neo4j のクラウドサービスか Neo4j Desktop 使えばよし (Free)
学習コンテンツもある
プロパティグラフモデル
グラフデータベースで最も利用されているモデル
以下の要素で構築される
- ノード
- リレーション
ノード
グラフデータベースにおける、個々のエンティティやデータを指す
ノードは ラベル と プロパティ の情報が定義される
RDB ベースで語るなら、テーブルの 1 レコードみたいなもの
NoSQL ベースで語るなら、Document (MongoDB) や Row (Cassandra) に相当
| 項目 | 説明 |
|---|---|
| ラベル | ノードの役割を宣言するタグのようなもの 1 つのノードに 0 個以上定義可能 役割というと難しく聞こえるが、要はグルーピングする際のカテゴリ名のようなもの (例) 商品情報ノード: :Product顧客情報ノード: :Customer歌手ノード: :Singer楽曲ノード: :Song
|
| プロパティ | key-value で表現されるノードの属性情報のようなもの 1 つのノードに 0 個以上保持可能 簡単に言えば、RDB でいう列のようなもの (例) 商品名: iPhone 16 Pro容量: 256GB価格: 159,800 円歌手名: Perfume曲名: ポリリズム
|
リレーション
あるノードから別のノード (あるいは同一のノード) への向き (関係性) を定義しているもの
リレーションは タイプ と プロパティ の情報が定義される
必ず両端に 1 つのノードが存在し、始点と終点がある (始点と終点が同一ノードの場合もある)
RDB ベースで語るなら、外部キー (FK: Foreign Key) みたいなイメージだが、外部キーのように紐づけるキーが一致していなければならないなどの制約はない
| 項目 | 説明 |
|---|---|
| タイプ | ノード間の関係性を定義する ノード同士がどのように関係しているかを簡潔に明示している 1 つのリレーションには 1 つのタイプのみ定義できる (例) 人間ノードのリレーション: :LIKE,:FRIEND,:KNOW など歌手ノードと楽曲ノードのリレーション: :SING曲ノードと作詞/作曲者ノードのリレーション: :WRITE_LYRICS,WRITE_MUSIC
|
| プロパティ | リレーションのタイプを補足する追加情報 1 つのリレーションには 0 つ以上のプロパティを定義できる (例) FRIEND ラベルのプロパティ: SINCE,FRIENDSHIP_TYPE,CLOSENESS など |
プロパティグラフモデルは、ラベルやリレーション、タイプといったスキーマに対する準拠は強制しない
もし特定のラベルを持つノードが特定のプロパティを持つ必要がある場合は、ラベルに対して制約を適用し、プロパティの存在や値の位置異性を担保する
(ex. Person ラベル -> name プロパティ)
制約は、スキーマとスキーマレスの中間に位置するようなもの
データモデル全体をルールでがっちり固めることはしないが、要所要所で必要に応じてスキーマのような制約を持たせるという思想
なぜなら、グラフデータは時間経過に伴って変化するものであり、実データは不均一で不完全であることが多いため
ラベル付きプロパティグラフモデルにおけるラベルは、グラフ上のノード間の関係性を定義する情報は存在しない
(ex. Perfume が 日本の歌手/アイドルの特化であるという事実はラベルでは推論できない)
ラベル間に関係性が存在しないという事実もデータの 1 つの特長であり、バグではない
グラフデータベースでは、単純にデータと構造のみを取り扱うため、型システムやポリモーフィズム[1]は意識しない
型システムやポリモーフィズムはアプリケーションレベルでは意識するものの、それはグラフデータベースで対応するのではなく、アプリケーション側で拡張できる余地を残している
-
Polymorphism (多態性)、複数のデータ型を 1 つのインターフェイスにまとめたもの、オブジェクトなどのデータ型に関する操作が統一的であること (ex. int/float/long/double etc.) ↩︎
ラベルは、継承 (extends) の性質を持たない
ラベルはあくまで、グラフデータベース上の 1 ノードの役割を示すもの
そのため、ラベルをアプリケーション内のオブジェクトの型にマッピングするかどうかは、設計判断(システムの開発者次第)
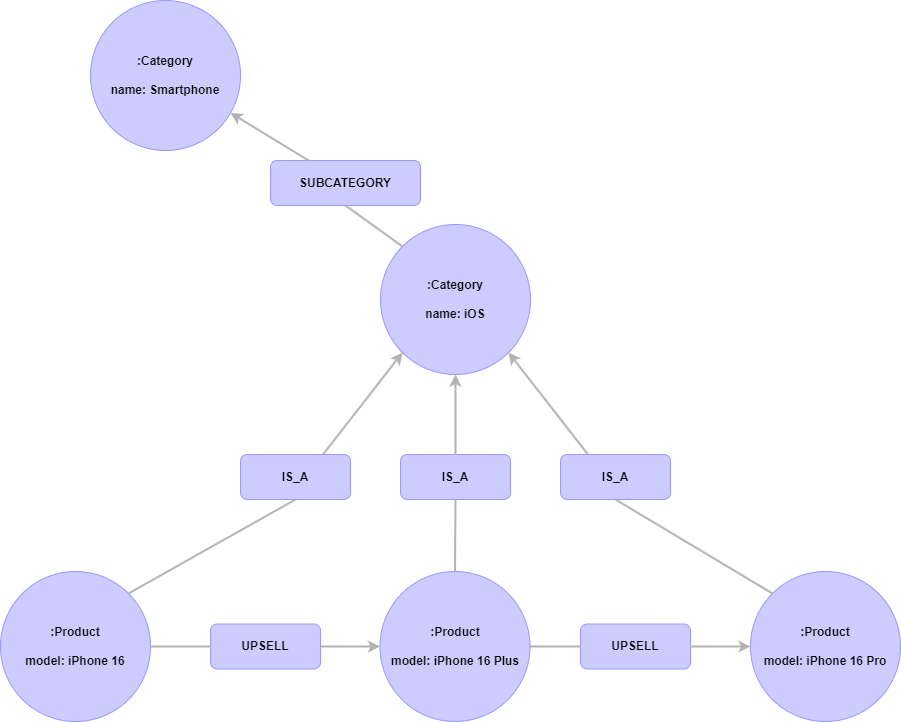
Cypher クエリ
ノードの記述
括弧 ( ) でノードを定義
括弧内にコロン : に続いてラベルを定義
括弧内に波括弧 { } でプロパティを定義
(:Song {name: 'ポリリズム', year: 2007, genre: 'Technopop'})
(:Singer {name: 'Perfume', debut: 1999})
リレーションの記述
亀甲括弧 [ ] でリレーションを定義
亀甲括弧内にコロン : でタイプを定義
亀甲括弧内に波括弧 { }でプロパティを定義
ノード間のリレーションの向き (矢印) を示すため、接続元に-、接続先に->を付与
-[:SING {first_time: '2007/7/5', first_place: '代官山UNIT', times_live: 255, type_mic: 'portable '}]->
CREATE
データ挿入の Cypher クエリ
SQL でいうところの INSERT
注意としては、CREATE 句は常に新しいデータを生成するため、クエリを重複実行すると同じノードやリレーションも重複して作成される点に注意
CREATE (:Singer {name: 'Perfume', debut: 1999})-[:SING {first_time: '2007/7/5', first_place: '代官山UNIT', times_live: 255, type_mic: 'portable '}]->(:Song {name: 'ポリリズム', year: 2007, genre: 'Technopop'})
MATCH
クエリ内で定義したパターンのデータを取得する Cypher クエリ
MATCH 句は、それ単体で使用することはなく、後続にRETURNやFINISH、UPDATEなどの句と合わせて使用される
SQL でいうところの SELECT のイメージだが条件を明示する部分もあるので WITH 句に近いかもしれない
MATCH (n) RETURN n

DELETE
指定した条件 (MATCH) に該当するデータを削除する Cypher クエリ
SQL と同じ DELETE だが、WHERE 句の有無に関係なく MATCH 句を使うところが SQL と異なる
単なる DELETE 句の場合、削除対象のノードにリレーションが紐づいている場合は、リレーションだけが残ってしまうことを避けるためにエラーとなる
MATCH (n) DELETE n
Cannot delete node<0>, because it still has relationships. To delete this node, you must first delete its relationships.
ノードに合わせてリレーションも削除する場合は、DELETE の前にDETACHを追加する
SQL でいうところの CASCADE のイメージ
MATCH (n) DETACH DELETE n
リレーションだけ削除したい場合は、MATCH 句でリレーションを定義して削除する
MATCH ()-[r:SING]->() DELETE r
MERGE
MATCH と CREATE を合わせたような Cypher クエリ
DB2 なら merge があったと思うが、SQL でいうところの IF NOT EXIST ~ INSERT INTO ... のイメージ
パターンに完全一致した場合はレコードを作成せず、それ以外の場合は CREATE を実行する
例えば、以下の場合は、前段で CREATE しているので作成はエラーになるが
MERGE (:Singer {name: 'Perfume', debut: 1999})-[:SING {first_time: '2007/7/5', first_place: '代官山UNIT', times_live: 255, type_mic: 'portable '}]->(:Song {name: 'ポリリズム', year: 2007, genre: 'Technopop'})
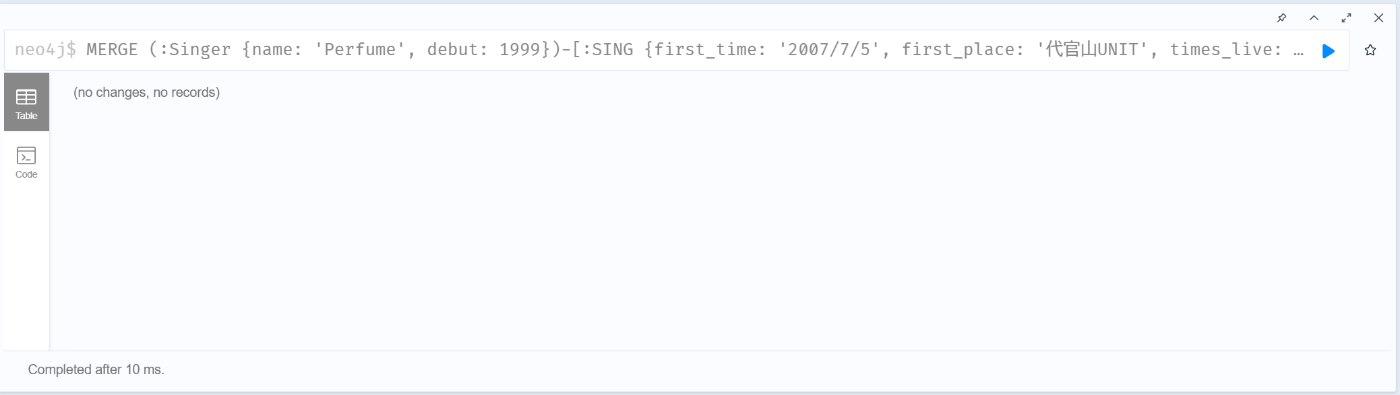
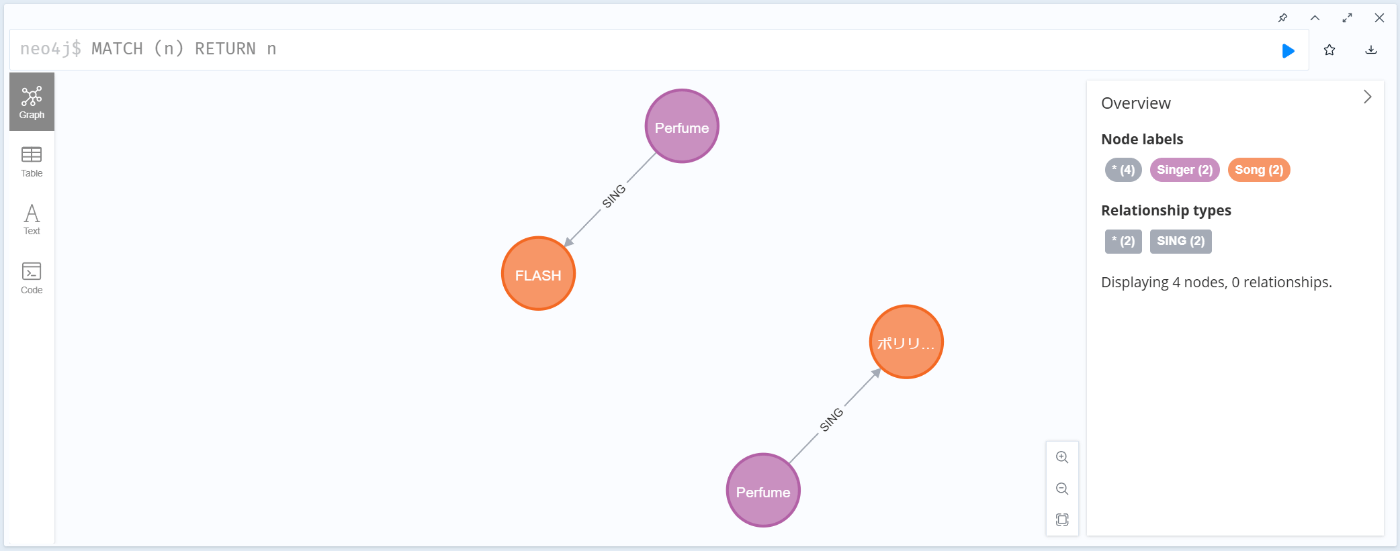
以下の場合は、完全一致でないため、Singer ノードについても重複で作成される
MERGE (:Singer {name: 'Perfume', debut: 1999})-[:SING {first_time: '2016/5/3', first_place: 'グランディ・21 セキスイハイムスーパーアリーナ', times_live: 107, type_mic: 'headset '}]->(:Song {name: 'FLASH', year: 2016, genre: 'j-pop'})
制約 (CONSTRAINT)
neo4j Enterprise Edition または Neo4j Desktop であれば、SQL でいう PRIMARY KEY を利用できる
CREATE CONSTRAINT no_duplicare_singer FOR (s:Singer) REQUIRE (s.name, s.debut) IS NODE KEY
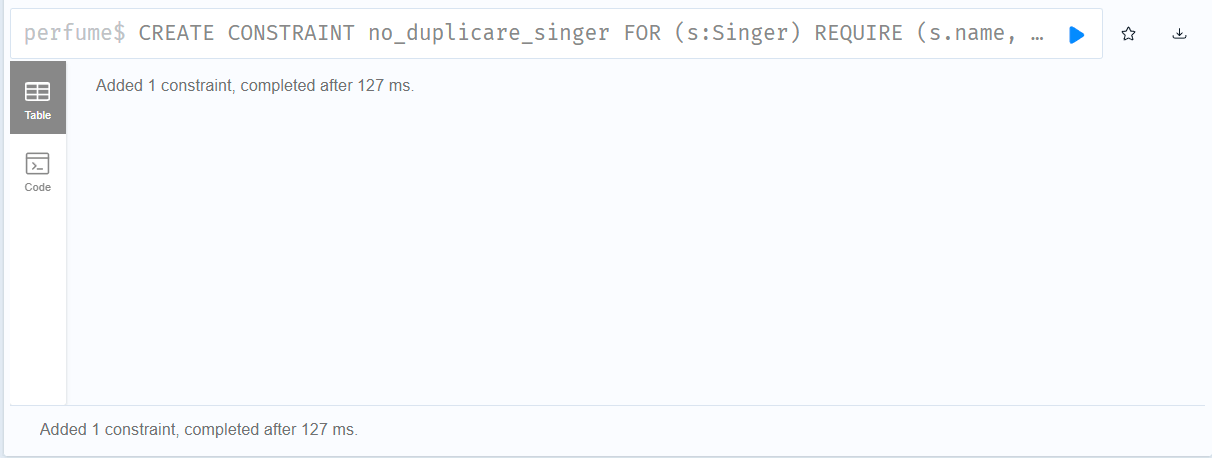
この例だと、:Singer ノードの name プロパティと debut プロパティの複合制約による一意性が保証されているため、エラーになる
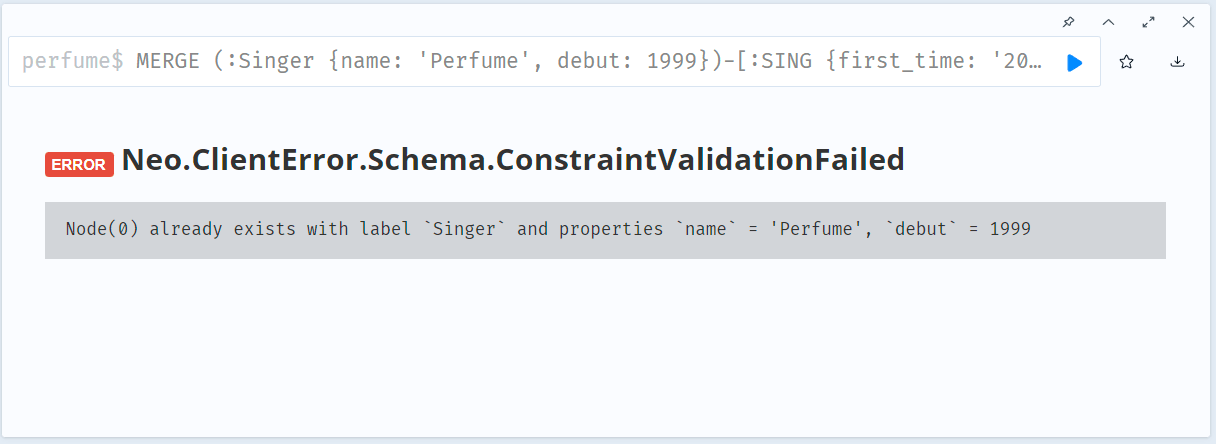
制約がある際の MERGE
MERGE クエリはグラフ上でのパターン作成や検出を排他的に行うことができるため、変数にバインドする形で
- ノードを作成または検出し、変数にバインド
- ノード間のリレーションを作成または検出
この流れを組めばよい
MERGE (perfume:Singer {name: 'Perfume', debut: 1999})
MERGE (polyrhythm:Song {name: 'ポリリズム', year: 2007, genre: 'Technopop'})
MERGE (perfume)-[:SING {first_time: '2007/7/5', first_place: '代官山UNIT', times_live: 255, type_mic: 'portable '}]->(polyrhythm)
MERGE (flash:Song {name: 'FLASH', year: 2016, genre: 'j-pop'})
MERGE (perfume)-[:SING {first_time: '2016/5/3', first_place: 'グランディ・21 セキスイハイムスーパーアリーナ', times_live: 107, type_mic: 'headset '}]->(flash)
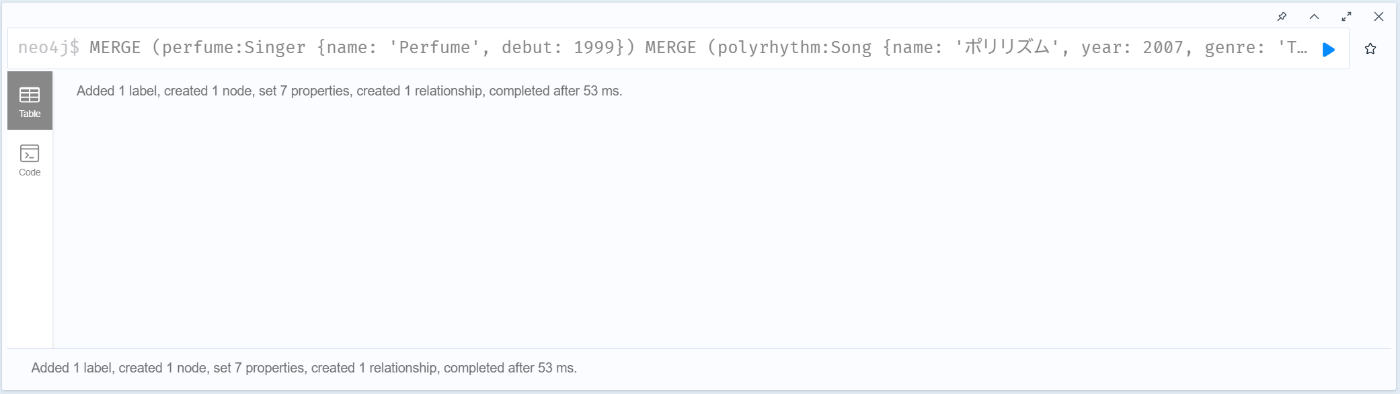
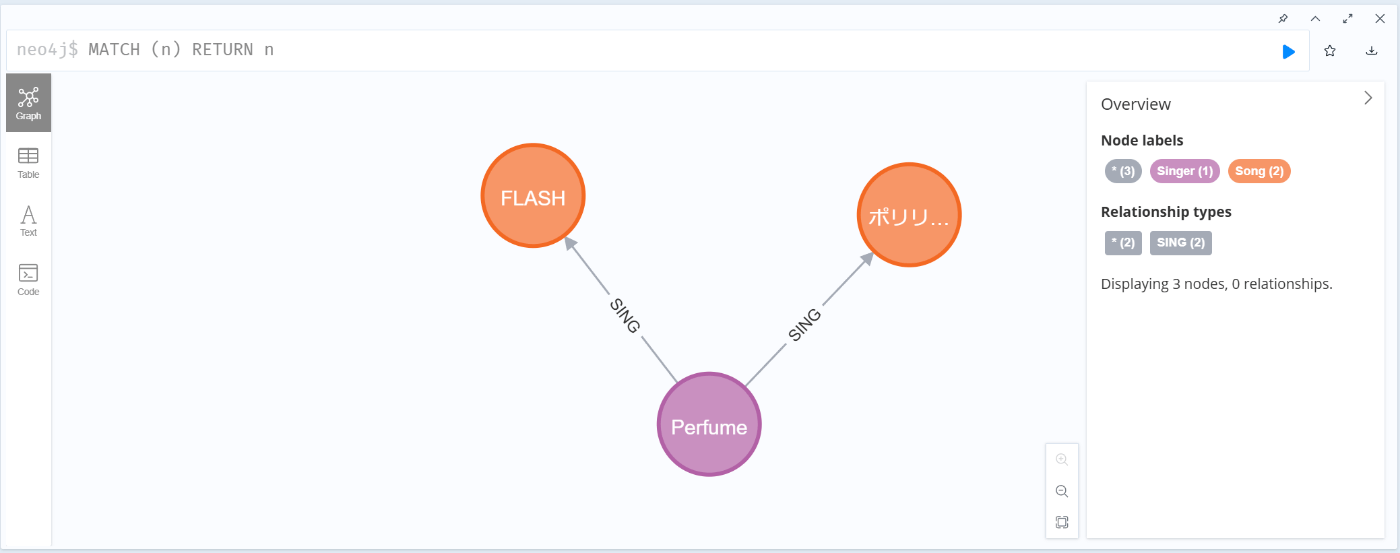
SET
ノードやリレーションを削除せずにプロパティのデータを更新する Cypher クエリ
SQL でいうところの UPDATE のイメージ
例えば、以下のようにノードを特定した後、プロパティを更新することも可能
MATCH (p:Song)
WHERE p.name = 'ポリリズム'
SET p.genre = 'j-pop'
REMOVE
ノードやリレーションを削除せずにプロパティだけを削除する Cypher クエリ
DELETE 句はノードやリレーションを削除するが、
例えば、以下のように特定のノードを明示した後、指定のプロパティを削除する
MATCH (p:Song)
WHERE p.name = 'ポリリズム'
REMOVE p.genre
※ここまで、勉強会(Neo4j 入門 #1)にて解説済み
イベント内での質問1
Q:
SQL だとデータ量が増えたりすると、クエリのレイテンシが大きくなると思いますが、neo4j (グラフデータベース) においてクエリのレイテンシが大きくなる理由はありますか?(どういった点に気をつければよいですか?)
A:
グラフの走査(ノードからリレーションを経由して別のノードに移動する処理のこと)の量が多ければ多いほど、クエリのレイテンシは比例して多くなります。
逆に言えば、RDB のように、データのサイズ(グラフデータベースで言うならグラフのサイズ)に比例してクエリのレイテンシが大きくなることは基本ありません。
ただし、グラフを走査する過程において、多くのプロパティに頻繁にアクセスするなどの場合においても、クエリのレイテンシが大きくなることはあります。
グラフデータベースのクエリは、本来、まずグラフ構造を走査した後、目的のノードとリレーションを特定し、それらのプロパティを取得する、というのが基本ですが、プロパティの内容によって走査の内容(先)を変更する高度なクエリを書く場合もあります。
なぜグラフの走査の量でレイテンシが大きくなるのかについては、グラフデータベース(neo4j)が持つデータの構造(非索引型隣接: index-free adjacency)が背景にありますが、これについては次回の勉強会の座学部分で触れようと思います。
イベント内での質問2
Q:
RDB だとモデリングとして論理設計時には E-R 図を作成しますが、グラフデータベースの時は何を作成しますか?
A:
グラフデータのダイヤグラム的なもの(データモデル設計書)だったり、クエリ設計書(Cypher クエリの設計)などを作成すると思いますが、E-R 図の代替は何になるかと言われれば、おそらくデータモデル設計書あたりかな、と思います。
データのモデリングに関しては
- どういうラベルのノードが存在し
- あるラベルのノードから別のラベルのノードには、どのようなタイプのリレーションが有り得るか
- ノードのプロパティには何が入り得るか
という部分が E-R 図同様に示したい内容かと思います。
これらは、neo4j の場合、Neo4j Labs の Arrows.app だったり、すでにデータ元となる CSV などがある場合は Neo4j Data Importer などを使ってモデリングを行うと思います。
詳細は、以下のあたりを参照してみてください。