Amazon SESのEメール送信ログをAthenaでいい感じにクエリする
小ネタです 🍣
Amazon SESにはメールの送信時などのタイミングでSNSやKinesis Data Firehoseなどの他サービスにJSON形式のログを通知する機能があります
このログを何かしらのデータストアに格納してクエリする…という例は調べると色々な事例が出てきますが、
中でも S3にパーティション付きで連携したものをAthenaでクエリする というケースにおいてよさげなサンプルが見つけられなかったので、備忘録として残します ✍
前提
S3に以下のような感じで送信履歴ログが入っている状況まで作れていることを前提とします
$ aws s3 ls s3://example-log-bucket/ses/delivery/ | head -3
PRE d=2022-09-01/
PRE d=2022-09-02/
PRE d=2022-09-03/
$ aws s3 ls s3://example-log-bucket/ses/delivery/d=2022-09-23/ | head -3
2022-09-23 09:13:03 1914 2022-09-23T00:10_0.json
2022-09-23 09:25:03 1915 2022-09-23T00:22_0.json
2022-09-23 09:35:03 1915 2022-09-23T00:32_0.json
中身はこんな感じのJSONだとします
イメージがしやすいよう整形していますが、正確には、以下のドキュメントで示されているような形で格納されている必要があります
{
"timestamp": "2018-10-08T14:05:45 +0000",
"messageId": "000001378603177f-7a5433e7-8edb-42ae-af10-f0181f34d6ee-000000",
"source": "sender@example.com",
"sourceArn": "arn:aws:ses:us-east-1:888888888888:identity/example.com",
"sourceIp": "127.0.3.0",
"sendingAccountId": "123456789012",
"destination": ["recipient@example.com"],
"headersTruncated": false,
"headers": [
{
"name": "From",
"value": "\"Sender Name\" <sender@example.com>"
},
{
"name": "To",
"value": "\"Recipient Name\" <recipient@example.com>"
},
{
"name": "Message-ID",
"value": "custom-message-ID"
},
{
"name": "Subject",
"value": "Hello"
},
{
"name": "Content-Type",
"value": "text/plain; charset=\"UTF-8\""
},
{
"name": "Content-Transfer-Encoding",
"value": "base64"
},
{
"name": "Date",
"value": "Mon, 08 Oct 2018 14:05:45 +0000"
}
],
"commonHeaders": {
"from": ["Sender Name <sender@example.com>"],
"date": "Mon, 08 Oct 2018 14:05:45 +0000",
"to": ["Recipient Name <recipient@example.com>"],
"messageId": " custom-message-ID",
"subject": "Message sent using Amazon SES"
},
"delivery": {
"timestamp": "2014-05-28T22:41:01.184Z",
"processingTimeMillis": 546,
"recipients": ["success@simulator.amazonses.com"],
"smtpResponse": "250 ok: Message 64111812 accepted",
"reportingMTA": "a8-70.smtp-out.amazonses.com",
"remoteMtaIp": "127.0.2.0"
}
}
手順
Athenaのコンソールで以下のクエリを流します
テーブルを作成するデータベースやS3バケット、パスについては適宜変更してください
今回はPartition Projectionを使って、クエリ対象のパーティションが自動で判定されるようにしています
どのような値が設定できるかについては以下ドキュメントに詳しいです
あと、余談としてテーブル名に - を含めることは非推奨ですが、以下のようにバッククオートで囲うと問題なく作成できます
CREATE
EXTERNAL TABLE `example-db`.delivery (
notificationType string,
mail struct<`timestamp`:string,
source:string,
sourceArn:string,
sourceIp:string,
callerIdentity:string,
sendingAccountId:string,
messageId:string,
destination:array<string>,
headersTruncated:boolean,
headers:array<struct<name:string,value:string>>,
commonHeaders:struct<`date`:string,subject:string,`to`:array<string>,`from`:array<string>>>,
delivery struct<`timestamp`:string,
processingtimemillis:int,
recipients:array<string>,
smtpResponse:string,
remoteMtaIp:string,
reportingMTA:string>
)
PARTITIONED BY
(
d STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
"ignore.malformed.json"="true"
)
LOCATION 's3://example-log-bucket/ses/delivery/'
TBLPROPERTIES
(
"projection.enabled" = "true",
"projection.d.type" = "date",
"projection.d.range" = "2000-01-01,NOW",
"projection.d.format" = "yyyy-MM-dd",
"projection.d.interval" = "1",
"projection.d.interval.unit" = "DAYS",
"storage.location.template" = "s3://example-log-bucket/ses/delivery/d=${d}"
);
この時点でAthenaに対してクエリできるようになります
パーティショニングが効いており、スキャン量が抑えられているのがわかります
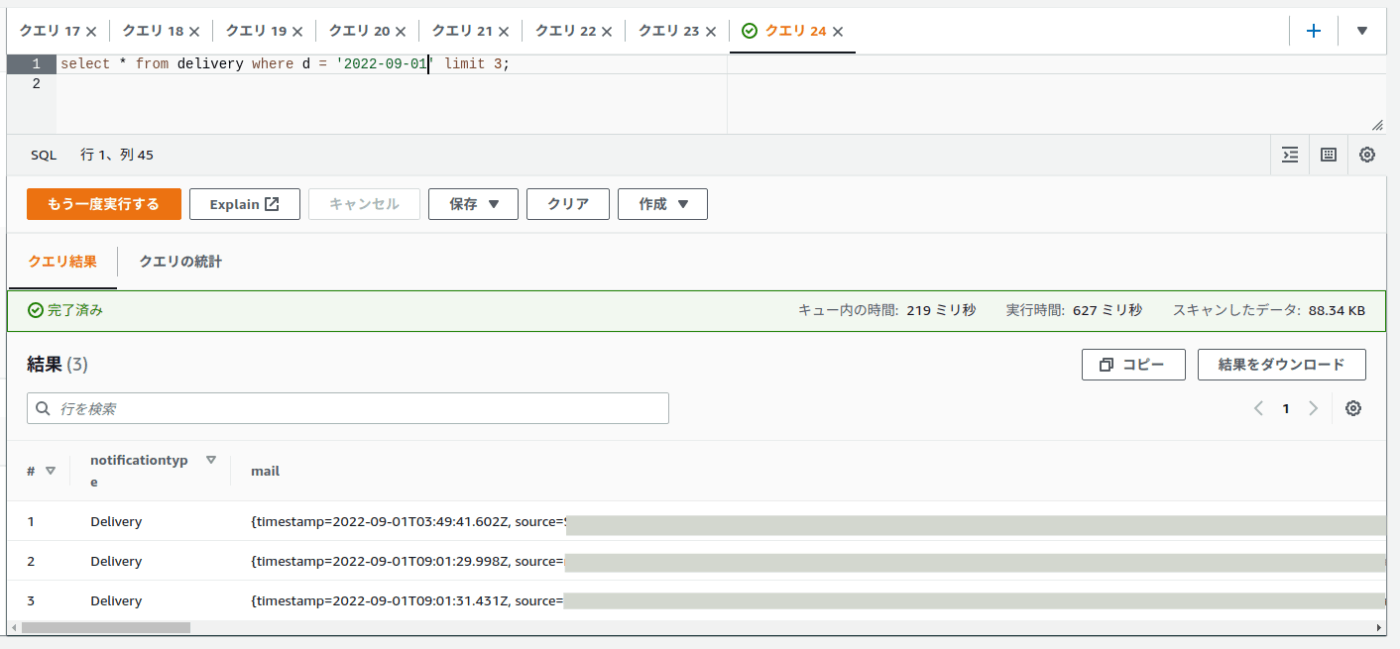
ただ、これだとJSONの構造を考慮して都度クエリを書くことになり少々面倒なので、
一般的なRDBのテーブル構造のようにフラットな格納状態のものを参照できるように、Viewを定義します
今回は、以下のような観点を考慮しました
- カラム名をキャメルケースからスネークケースに変える
- ネストが深いプロパティに対して
.を使ってクエリしなくていいようにする - 配列形式のデータについて、先頭要素をそのままクエリできるようにする
-
"from": ["Sender Name <sender@example.com>"]からSender Name <sender@example.com>を取り出せるカラムを定義
-
- オブジェクトの配列形式のデータについて、キーがマッチする最初の要素をそのままクエリできるようにする
-
"headers": [{"name": "From", "value": "\"Sender Name\" <sender@example.com>"}, {"name": "To", "value": "\"Recipient Name\" <recipient@example.com>"}から"Sender Name" <sender@example.com>を取り出せるカラムと"Recipient Name" <recipient@example.com>を取り出せるカラムをそれぞれ定義
-
クエリの作成にあたっては以下が参考になりました
DDLは以下になります
注意としては、CREATE TABLE時はハイフン付きのデータベース名はバッククオートだったのに対し、CREATE VIEWの場合はダブルクオートで括る必要があるようです(理由は不明)
CREATE VIEW delivery_pretty AS
select d,
notificationType as notification_type,
mail.timestamp as mail_timestamp,
mail.source as mail_source,
mail.sourceArn as mail_source_arn,
mail.sourceIp as mail_source_ip,
mail.callerIdentity as mail_caller_identity,
mail.sendingAccountId as mail_sending_account_id,
mail.messageId as mail_messageId,
element_at(mail.destination, 1) as mail_first_destination,
mail.destination as mail_destinations,
cardinality(mail.destination) as mail_destinations_length,
mail.headersTruncated as mail_header_truncated,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('Received')
),
1
).Value as mail_headers_first_received,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('Content-Type')
),
1
).Value as mail_headers_first_content_type,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('MIME-Version')
),
1
).Value as mail_headers_first_mime_version,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('Content-Transfer-Encoding')
),
1
).Value as mail_headers_first_content_transfer_encoding,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('Subject')
),
1
).Value as mail_headers_first_subject,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('From')
),
1
).Value as mail_headers_first_from,
element_at(
filter(mail.headers, el->lower(el.name) = lower('To')),
1
).Value as mail_headers_first_to,
element_at(
filter(
mail.headers,
el->lower(el.name) = lower('Date')
),
1
).Value as mail_headers_first_date,
element_at(mail.commonHeaders."from", 1) as mail_common_headers_first_from,
mail.commonHeaders."from" as mail_common_headers_from,
cardinality(mail.commonHeaders."from") as mail_common_headers_from_length,
mail.commonHeaders."date" as mail_common_headers_date,
element_at(mail.commonHeaders."to", 1) as mail_common_headers_first_to,
mail.commonHeaders."to" as mail_common_headers_to,
cardinality(mail.commonHeaders."to") as mail_common_headers_to_length,
mail.commonHeaders."subject" as mail_common_headers_subject,
delivery."timestamp" as delivery_timestamp,
delivery.processingTimeMillis as delivery_processing_time_millis,
element_at(delivery.recipients, 1) as delivery_first_receipient,
delivery.recipients as delivery_receipients,
cardinality(delivery.recipients) as delivery_receipients_length,
delivery.smtpResponse as delivery_smtp_response,
delivery.remoteMtaIp as delivery_remote_mta_ip,
delivery.reportingMTA as delivery_repoting_mta
from "example-db".delivery;
Viewに対するクエリのサンプルも貼っておきます
そのままのテーブルより可読性・使いやすさがアップしたのでないかと思います 🐠

そんだけ 😌
Discussion