Webアプリケーションにおけるタイムアウトについて
なぜ調べたか
実務でWebアプリケーションの開発をしていると、主にエラーハンドリングの文脈で タイムアウト という概念が度々登場します
Wikipediaの当該記事 を読むと、以下のような説明がなされています
- 一定時間に処理が完了しなかった時に、制御を打ち切って中止するための機構
- 処理完了までに永遠、または非常に長い時間がかかってしまうケースにおいて、計算資源の占有を抑止する
これは、タイムアウト制御の必要性とそれが解決する問題について端的に説明していますが、
具体的な対応方法や、実務においてどのような観点に気を配るべきかについては示されていません
私自身、十分な対応をおこなえていなかったことで、レスポンスタイムの低下や、最悪のケースではサービスダウンを引き起こしてしまったこともありました
そうした経験を踏まえ、シンプルなWebアプリケーションを想定したときに、 アーキテクチャ中の各レイヤでどのようにタイムアウトを設定すればよい か、整理することとしました
紹介する内容は主にPythonおよびAWSを前提としていますが、他の言語やインフラを利用するケースでも、同じような考え方で応用できるものと考えています
なお、ここで紹介する内容は個人的な調査に基づくもので、誤りが多分に含まれる可能性があります
あしからず🐾
歴史
記事の本旨とはずれるが、IETF Datatrackerを用いて、タイムアウト という概念が少なくともいつ頃に存在していたか簡単に確認してみる
今日のインターネットはTCP/IPにより実装されてるが、こちらによるとその前身となるARPANETにおいてはNCPというプロトコルが利用されていたようなので、NCPに関するRFCを検索した
すると、RFC 460 NCP Surveyにおいて、13 Time outsという節でタイムアウトへの言及が見られた
このRFCは、開発者にNCPに関するアンケートを取る目的で作成されたらしく、NCPにおけるタイムアウト処理をどのように実装しているか質問している
当RFCの発行日は 1973/2/13 なので、 タイムアウト という言葉は少なくとも50年前にはネットワーク用語として普遍的に利用されていたことがわかる
(もしも、より昔の時代に使われたことを知っている方がいましたら教えてもらえるとうれしいです🐑)
各レイヤにおけるタイムアウト設定
AWS上にALB、EC2、RDSを定義し、Djangoで動作するWebアプリケーションをホスティングする…といったシンプルなアーキテクチャにおいて、各レイヤのコンポーネントでどのようなタイムアウト設定が可能か、調査した内容を示す
(大きなサイズの図はこちら)
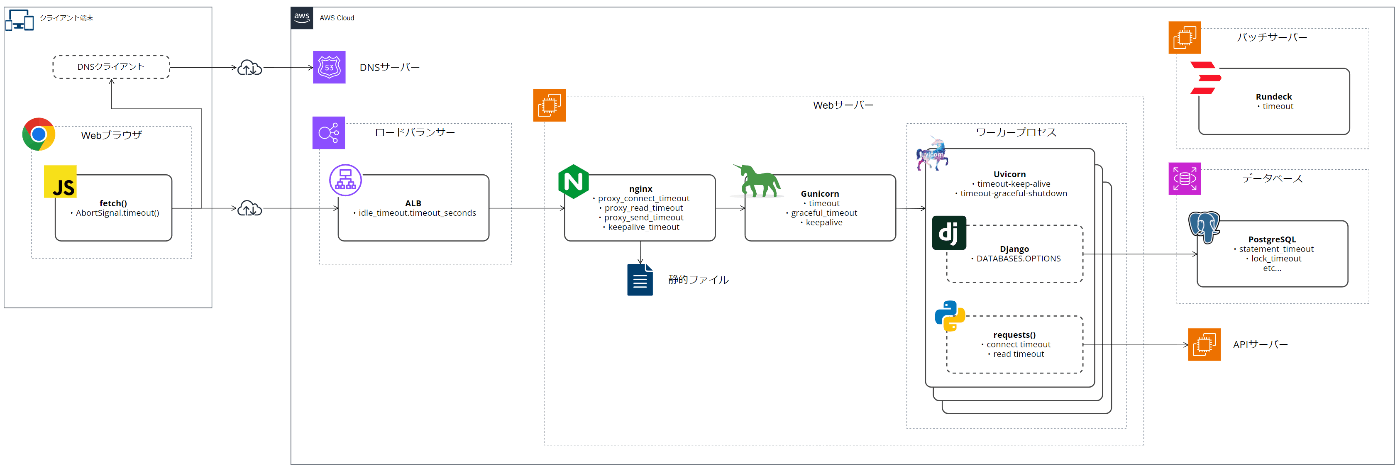
Webアプリケーションにおけるタイムアウト設定
上記を見てもわかるように、タイムアウト設定は基本的にすべてのレイヤ・コンポーネントで考慮が必要で、妥当に設定されている必要がある
正常に動作している限りには設定が不適切でも特に問題は生じないが、以下に示すような状況が発生した際には、レスポンスの低下やエラー率の上昇といったユーザー影響を引き起こす
- アプリケーションからの非効率なSQL呼び出しによるDBのCPUリソースやファイル、ネットワークI/Oの浪費
- アプリケーションが利用しているネットワークの不安定化、遅延
- 巨大で転送に時間がかかるファイルのダウンロード
1つ1つの設定について深堀する前に、全体感を理解するための大まかな分類を試みる
大まかな(独自)分類
一口にタイムアウトと言ってもその実態は観念的なものであるため、すべての実装に共通する普遍的な仕様が存在するわけではない
しかしながら、一般的に要求には送り手(≒クライアント)と受け手(≒サーバー)が存在するため、どちらのレイヤで実装されているタイムアウトか区別することで、大まかに役割や挙動を分類することができると考えられる
-
クライアント側で制御を打ち切るもの
-
リードタイムアウトや接続タイムアウトと呼ばれる場合が多い - クライアントのユーザーに対して早期に応答を返却する性質がある
- サーバー側で既に処理が始まっている場合、処理の中断はおこなわれない
-
-
サーバー側で制御を打ち切るもの
-
処理タイムアウトやセッションタイムアウトと呼ばれる場合が多い - サーバーのリソースを開放して早期に負荷を低減する性質がある
- 実行中の処理がある場合は基本的に中断される
-
それぞれについて、具体的な処理シーケンスを示す
なお、上記の分類は私がこの記事に際して独自に定義したもののため、現実世界の実装に直接当てはめられないことに注意すること
リードタイムアウト
クライアント側の実装で一般的なものとして リードタイムアウト / Read Timeout がある
以下のような特徴を持つ
- クライアントからサーバーへのリクエスト発行時にタイムアウト時間を設定する
- タイムアウト時間よりも早くサーバーから処理結果が返却された場合は、それを呼び出し元に返却する
- HTTPレスポンスオブジェクトの返却や、HTTPエラー応答を示す例外の送出
- タイムアウト時間まで待ってもサーバーから処理結果が返却され無かった場合は、タイムアウトを示す例外を発生させる
- その後にサーバーからHTTPレスポンスが返却されても破棄する
- 単に処理に時間がかかっただけの正常ケースもエラーとして処理される
シーケンス図を以下に示す
具体的な実装例をいくつか示す
昨今のWebアプリケーションはWebブラウザ上で動作するJavaScriptによってHTTPリクエストが発行されるケースが多いが、
fetch APIやXMLHttpRequestといったWeb標準により定義されている機能においてタイムアウトを設定可能になっている
ただし、これらは後述する接続タイムアウトを区別できない模様(エラーオブジェクト等から返却される文字列で区別することはできるかもしれない)
fetch APIにおいてはAbortSignalが、XMLHTTPRequestにおいてはtimeoutプロパティが対応する
一方、HTMLフォームの利用によってWebブラウザからHTTPリクエストが発生するケースにおいては、ブラウザによって制御がおこなわれるため、開発者にて任意のタイムアウト値を指定することは基本的に不可能である
PythonにおいてHTTPリクエストをおこなう際はrequestsというOSSを利用することが一般的だが、この時引数に timeout を指定するとリードタイムアウトが設定できる
nginxに代表されるようなWebサーバーアプリケーションは、HTTPS暗号化の終端やキャッシュとしての利用を目的にリバースプロキシ機能を持っており、クライアントに対してはサーバーとして振る舞う一方で、オリジンサーバーに対してはアクセス元のクライアントとして動作する
この時、proxy_read_timeoutによってオリジンサーバーからのレスポンス取得に対してタイムアウトを設定できる
AWSにおいてロードバランサーのマネージドサービスを提供するALB(Application Load Balancer)ではidle_timeout.timeout_secondsを用いてALBからターゲットに対するタイムアウトを設定できる
接続タイムアウト
リードタイムアウトが指定できる状況において、 接続タイムアウト / Connection Timeout が指定できる場合も多い
WebアプリケーションでHTTPによる通信をおこなうためには、TCPなどの下位の通信プロトコルによって宛先サーバーとのコネクションが確立していることが前提となる
リードタイムアウトがHTTPレイヤ(≒アプリケーションの応答返却)のタイムアウトを定義するのに対して、接続タイムアウトはその前段のDNSによる名前解決やTCPハンドシェイクの過程で処理遅延が生じた時のタイムアウトを定義する
リードタイムアウトと比較して以下の性質を持つ
- サーバーへの接続にかかる待機時間と接続後の実処理の待機時間を区別して設定できる
- 接続タイムアウトが発生したケースでは、一般に 主処理は発生しない
- 主処理の前提となるコネクションが成立していないため
- 実際の挙動は実装依存となるので必要ならば都度確認する
シーケンス図を以下に示す
前述したPythonのrequestsにおいて、 timeout の引数に (3.0, 5.0) のようにタプルを指定すると、1つ目の値が接続タイムアウトに、2つ目の値がリードタイムアウトにそれぞれ設定される
CLIツールのcurlにおいても、以下のように接続タイムアウト値を区別して指定できる
# 接続タイムアウトに3秒、リクエスト全体のタイムアウトに8秒を指定
curl --connect-timeout 3 --max-time 8 https://example.com/
前述したnginxにおいても、接続タイムアウトの指定としてproxy_connect_timeoutが利用できる
処理タイムアウト
先述したタイムアウトはいずれもクライアント側での処理中断に関するものだったが、サーバーで動作するアプリケーションにおいては、処理そのものの中断を目的とした 処理タイムアウト / Process Timeout が定義されていることがある
なお、ここでいう Process は 処理 の英訳として私が付与したもので、OSの文脈で用いられる プロセス とは関係ない
単に Timeout として用意されている場合も多い
以下の特徴を持つ
- 一定時間経っても完了しなかったサーバー処理を中断する
- クライアントからのリクエスト受付を担うサーバープロセスと、実処理を委譲されて動作するワーカープロセスがアーキテクチャとして分離されている時に設定できる場合が多い
- 処理の中断までにおこなわれた処理が取り消されるかは実装に依存する
- RDBのようにトランザクションを貼って処理をおこなうケースではロールバックが可能だが、ジョブサーバーがシェルスクリプトを呼び出すような場合は、シグナルをハンドリングして独自に終了処理を書く必要がある
処理タイムアウトが必要な理由として、サーバーアプリケーションは複数のユーザー要求を並列に処理する必要があり、それには処理リソースの適切な管理が求められるからである
時間がかかりすぎて結果を利用する見込みのない処理にリソースを割くことは、それをリクエストしたユーザーへのレスポンス遅延を招くだけでなく、他のリクエストにも影響を及ぼす
ワーカー処理をおこなうためのリソースを長期間にわたり占有してしまうことで、処理さえできれば高速にレスポンスが返却できるリクエストがバックログに積まれるようになり、システム全体のパフォーマンスが悪化したり、最悪の場合レスポンスが返却できなくなる
シーケンス図を以下に示す
図では簡便のため Server 内で処理を中断するような表現になっているが、実際はプロセスやスレッドによる処理の分離がおこなわれていて、処理受け付けをするサーバープロセス自体は動作を維持したまま実処理のみ中断するような設計になっている場合が多い
実装例をいくつか示す
PostgreSQLでは、statement_timeout や lock_timeoutといった、RDB内の処理の種類ごとにタイムアウトを指定する機能が備わっている
動作イメージは以下のようになる
オプションはユーザー単位やセッション単位に指定することができる
set statement_timeout to 1000;
SELECT pg_sleep(3);
上記SQLを発行すると、1秒後にタイムアウトエラーになったことが表示される
[2024-09-24 08:36:13] Connected
example> set statement_timeout to 1000
[2024-09-24 08:36:13] completed in 15 ms
example.public> SELECT pg_sleep(3)
[2024-09-24 08:36:14] [57014] ERROR: canceling statement due to statement timeout
ジョブサーバーのRundeckにおいては、Timeoutというプロパティでジョブを中断させることができる
PythonのアプリケーションサーバーであるGunicornでは、timeoutというプロパティによってワーカーのタイムアウト秒数を指定できる
注意としては、本設定値が処理タイムアウトとして機能するのは同期ワーカー(sync workers)として動作している場合のみで、非同期の場合はワーカーの正常性確認のための値になる
セッションタイムアウト
前述してきた各種タイムアウトは、単一のリクエストにおいてそれぞれのレイヤで処理を中断することを目的としたものであった
しかし、HTTPはCookieなどを用いて複数のリクエスト間でユーザー状態を維持するセッション機構であったり、キープアライブ機能を用いて単一のコネクションを複数のリクエストで再利用する仕組みが存在し、これらについてもタイムアウトが意識される
同時に保持できるコネクションはクライアント、サーバー共に有限であるため、利用されていないものについては
また、一定時間以上操作の無かったHTTPセッションを開放することは、セッション管理に必要なリソースの開放だけでなく、
Cookieによるセッションタイムアウト機構のシーケンス図を以下に示す
PythonのWebフレームワークであるDjangoでは、 SESSION_COOKIE_AGE にてセッションの有効期間を指定することができる
HTTPステータスコード
Webアプリケーションの文脈においては、HTTPのレイヤでタイムアウトに関する仕様がいくつか定義されている
発生したエラーに対してどのようなHTTPステータスコードが返却されるかは基本的に実装依存になるが、どのような設定状態の時にエラーが発生するか理解できているとトラブルシューティングの時に役立てられるため、nginxをサンプルに例示する
408 Request Timeout
HTTPサーバーは、クライアント(ブラウザ)から受け取ったHTTPリクエストを解釈してHTTPレスポンスを生成するが、
ネットワーク品質やクライアントの実装不備に起因してリクエスト全体が到着するのに長時間かかるケースにおいて、サーバー側から一方的にコネクションを閉じることが仕様上認められている
前述した分類においては、セッションタイムアウトのパターンに近い動作と言える
発生方法の一例を以下に示す
ターミナルを開き、nginxコンテナをポート8080番で起動する
これがサーバーの役割となる
cat <<EOF > /tmp/custom.conf
server {
client_header_timeout 5s;
}
EOF
docker run -p 8080:80 -v "/tmp/custom.conf:/etc/nginx/conf.d/custom.conf" nginx
別のターミナルを開き、telnetコマンドを用いて8080ポートに接続する
HTTPリクエストは連続する2つの改行(CRLF)によりリクエストが終了したことを区別するため、1行目のみ
telnet localhost 8080
# ターミナルに以下の文字を入力し、改行を1回だけおこなう
GET /index.html HTTP/1.1
nginxのclient_header_timeoutに対して5秒を設定したため、一定秒待つと408レスポンスが返却される
172.17.0.1 - - [23/Sep/2024:12:41:41 +0000] "GET /index.html HTTP/1.1" 408 0 "-" "-" "-"
クライアント側のログは以下のようになる
$ telnet localhost 8080
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
GET /index.html HTTP/1.1
Connection closed by foreign host.
なお、当該サーバーに対してcurlなどの正常にHTTPリクエストをおこなうクライアントで接続すると、適切なHTTPレスポンスが返却される
$ curl -sv "http://localhost:8080/index.html" > /dev/null
* Trying 127.0.0.1:8080...
* Connected to localhost (127.0.0.1) port 8080 (#0)
> GET /index.html HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.27.1
< Date: Mon, 23 Sep 2024 13:28:59 GMT
< Content-Type: text/html
< Content-Length: 615
< Last-Modified: Mon, 12 Aug 2024 14:21:01 GMT
< Connection: keep-alive
< ETag: "66ba1a4d-267"
< Accept-Ranges: bytes
<
{ [615 bytes data]
* Connection #0 to host localhost left intact
504 Gateway Timeout
アプリケーションサーバーの前にnginxなどのプロキシサーバーを配置しているケースにおいては、プロキシサーバーはウェブブラウザに対してはサーバーの役割を、アプリケーションサーバーに対してはクライアントの役割を果たすことになる
この時、アプリケーションサーバーから期待するHTTPレスポンスが得られなかった時に、専用のステータスコードでHTTPレスポンスをおこなうことが仕様として認められている
前述した分類においては、接続タイムアウトやリードタイムアウトのパターンが発生しうる
発生方法の一例を以下に示す
ターミナルを開き、nginxコンテナをポート8080番で起動する
この時、proxy_passを用いてプライベートIPアドレスを指定することで、コネクションが成立しない状態にする
cat <<EOF > /tmp/default.conf
server {
listen 80;
location / {
proxy_pass http://10.0.0.0;
proxy_connect_timeout 5;
}
}
EOF
docker run -p 8080:80 -v "/tmp/default.conf:/etc/nginx/conf.d/default.conf" nginx
別のターミナルを開き、curlコマンドを用いて8080ポートに接続する
curl --head -v "http://localhost:8080"
nginxのproxy_connect_timeoutに対して5秒を設定したため、一定秒待つと504レスポンスが返却される
また、今回は割愛しているが、プロキシ先サーバーに接続後のレスポンス待機時間を示すproxy_read_timeoutという値も存在する
2024/09/23 13:24:06 [error] 33#33: *9 upstream timed out (110: Connection timed out) while connecting to upstream, client: 172.17.0.1, server: , request: "HEAD / HTTP/1.1", upstream: "http://10.0.0.0:80/", host: "localhost:8080"
172.17.0.1 - - [23/Sep/2024:13:24:06 +0000] "HEAD / HTTP/1.1" 504 0 "-" "curl/7.81.0" "-"
クライアント側のログは以下のようになる
$ curl --head -v "http://localhost:8080"
* Trying 127.0.0.1:8080...
* Connected to localhost (127.0.0.1) port 8080 (#0)
> HEAD / HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 504 Gateway Time-out
HTTP/1.1 504 Gateway Time-out
< Server: nginx/1.27.1
Server: nginx/1.27.1
< Date: Mon, 23 Sep 2024 13:24:06 GMT
Date: Mon, 23 Sep 2024 13:24:06 GMT
< Content-Type: text/html
Content-Type: text/html
< Content-Length: 167
Content-Length: 167
< Connection: keep-alive
Connection: keep-alive
<
* Connection #0 to host localhost left intact
考慮すべき事柄
全体感が理解できたところで、個人的な経験と一般的に言及されていることを踏まえて、タイムアウト設定について検討する時に注意すべき事柄についてまとめる
タイムアウトを設定しないことは危険である
第一に、タイムアウトはほとんどのケースで設定することが推奨されるものである
タイムアウトを設定しないとその処理はフリーズする可能性があり、リソースの占有によってシステムのパフォーマンス低下を引き起こす原因となりかねない
特に ネットワークI/Oを発生させる処理に対してリードタイムアウト / 接続タイムアウトが設定されているか確認するとよい
Webアプリケーションにおいては、外部APIやRDB、キャッシュDBのような自身のプロセス外に存在するコンポーネントと通信するケースが多いが、これらがパフォーマンスやネットワークの安定性の問題から応答を返却できなくなるケースは容易に発生しうる
明示的にタイムアウトを指定しなかったとしても、デフォルト値によってタイムアウトがおこなわれる状況も多いため、まずは利用しているコンポーネントの設定状況を確認・整理することから始めるとよい
クライアント側だけタイムアウトするのは危険である
前項でタイムアウト設定の重要性について説明したが、特定のレイヤ(特にフロントエンド)にだけタイムアウトを設定することは望ましくない
クライアントにのみ短いタイムアウト設定をした際にどのような事象が発生するか、シーケンス図で示す
この図では、クライアント側にのみタイムアウト設定をおこなったことで以下のような処理フローが生じている
説明をわかりやすくするために比較的悲観的な状況を示しているが、処理量の多いコンポーネントにおける設定ミスの影響の大きさが理解できる
- ①クライアントがサーバーにリクエスト1を送信し、DBがクエリ1の処理を開始する
- ②クライアント側でタイムアウトが発生し、再実行を促すエラーメッセージが表示される
- この時、DBでは依然としてクエリ1を処理している
- ③クライアントがサーバーにリクエスト2を送信し、DBがクエリ2の処理を開始する
- ⚰️クエリ1と2が並列に実行されることで、DBの負荷が増加する
- ⚰️サーバーにおいてリクエスト1と2が同時に受け付けされており、ワーカーを占有する
- ⚰️ワーカー数が2だった場合、この時にリクエスト3を受け付けても要求はバックログに送信され処理待ちが発生する
- 💀処理待ちによりヘルスチェックなどのエンドポイントでリクエストが返却できなくなると、サーバーダウン発生のリスクが高まる
- ⚰️ワーカー数が2だった場合、この時にリクエスト3を受け付けても要求はバックログに送信され処理待ちが発生する
- ④クエリ2の処理が完了し、結果がクライアント側に返送される
- ⚰️クエリ1と並列に実行されたことで、本来よりもパフォーマンスが悪くなる可能性がある
- ⑤クエリ1の処理が完了し、結果がクライアントに返送される
- ⚰️既にクエリ2の結果によって画面描画がおこなわれているため、結果は破棄される
対処法としては、アプリケーションにおいて最も奥側にあるコンポーネントについてタイムアウトを指定することが効果的である
一般的なWebアプリケーションにおいては、RDBの負荷がシステム全体のパフォーマンスに大きく影響を及ぼすためSQLコマンドの処理タイムアウトについては設定したほうがよいと思われる
タイムアウト値の長短によるトレードオフを理解する
タイムアウトは異常系(Negative)におけるエラーハンドリング手法のひとつであるため、あらゆるケースで機械的に値を短く、あるいは長くすればよいものではない
タイムアウトの値の長短によって、以下のような傾向が生じる
- タイムアウトまでの時間が短い🐇
- ✅ユーザーに対して早期にエラーレスポンスを表示し、再処理を促せる
- ✅仕様としてレスポンスタイムを一定未満に収める必要が生じ、開発時にシステムの応答性が考慮されやすくなる
- ⚠️データ量などに依存して、特定ユーザのみ処理遅延が生じてエラーになるといった状況が生じやすい
- ⚠️ネットワーク負荷の一時的なスパイクをタイムアウトとして判定しやすくなる
- タイムアウトまでの時間が長い🐢
- ✅時間がかかるだけで処理成功できるケースがエラーにならない
- ⚠️処理リソースを長期間占有することでシステムのパフォーマンスが低下する
- ⚠️開発に置いてレスポンスタイムがあまり顧みられず、応答性の悪いシステムになりやすい
上記のようなトレードオフがある中で、異常系としてハンドリングしたい処理時間をアプリケーションの実稼働状況などを見ながら判断していく必要がある
すぐに適正値が決められない場合は、まずは十分に長い値を設定して様子を見ながら、少しずつ閾値を狭めていくと漸進的に導入しやすい
なお、データ指向アプリケーションデザインという書籍の中で、分散システムにおけるネットワークトラフィックの正常性確認にタイムアウトを設定する時の指針として、
しかしながら、現実的にはどちらも流動的な値のため、前述したように実際のレスポンスタイムを計測した上で判断する必要がある
外側ほどタイムアウトを長くする
各レイヤにおいてタイムアウトを指定する際にレイヤ間で注意すべき事柄として、タイムアウト時間が クライアント側タイムアウト > サーバー側タイムアウト の大小関係を持っているかどうか確認した方がよい
理由について説明するため、以下のシーケンス図を示す
上記の図では、クライアントからnginxなどのリバースプロキシを通じてWebアプリケーションに対してHTTPリクエストをおこなう仮定で、サーバー処理の実装不備などによりタイムアウトが発生した状況を想定している
このようなケースにおいて クライアント(Proxy)側タイムアウト < サーバー(Server)側タイムアウト の大小関係でタイムアウトを設定していた場合、クライアントに対して返却されるHTTPステータスコードはプロキシに由来するものとなり、サーバー側のレスポンスはプロキシによって破棄されてしまうこととなる
クライアント側の実装でHTTPステータスコードを用いて処理分岐をおこなっていた場合に、予期しない動作を引き起こす原因になることに加え、開発者にて原因調査をおこなう際にも混乱を生みやすい
実際はレスポンス遅延はどのレイヤで生じるかはわからないため、大小関係を整理したからと言って必ずしも前述の状況を避けられるとは限らないが、初期実装時の指針として考慮して検討できるとよい
レイヤ毎に処理状況をロギングする
先ほどに類似したパターンとして、以下のシーケンス図で示すような状況について考える
ここでは、サーバーにて処理遅延が発生したことをプロキシにて検知しタイムアウトを返却したものの、実際には処理は成功しており、ユーザーに通知した状況とシステム内部の状況に不整合が生じてしまっている
タイムアウトが異常系のハンドリングを目的としたものである性質上、こうした状況が起きること自体は避けられないが、システムのエラー監視をアプリケーションサーバーの監視のみでおこなっていてプロキシのアクセスログを確認していなかった場合、ユーザーからの指摘が発生するまで問題を検出できないことになってしまう
上記のような状況を避けるため、ログの収集及び監視はすべてのコンポーネントにて実施することが望ましい
すぐに対応することがむずかしい場合は、サーバーサイドにおいて一番外側のコンポーネントのログを取得することから始めるとよい
例えばAWSであれば、ALBのアクセスログは数行の設定変更でS3に取得できる
リトライ制御は慎重に
タイムアウト発生時のエラーハンドリングとして処理をリトライすることが思いつくが、単純に処理要求を再送すると思わぬ副作用を生む場合がある
第一に、リトライをおこなう処理は冪等性を持っていることが期待される
例えばHTTP POSTリクエストに対して履歴レコードを1件作成するケースにおいては、リクエストの度に同一内容の履歴レコードが複数作られないようにするため存在チェックをおこなうなど、再送処理を複数回おこなっても最終的な結果が同じになるように処理を設計するとよい
また、リトライ処理の送信頻度についても一定のスロットリングがなされるように設計にできるとよい
リトライ回数に上限を定めた上で、タイムアウトが発生する度に再送までの時間を指数バックオフ(Exponential backoff)などの戦略を用いて徐々に伸ばしていくと、リトライ処理による負荷急増を緩和できる
しかしながら、再送までの時間を伸ばすとエンドユーザーに対するレスポンスはその分遅延するため、同期処理中のリトライは最小限に留めることが望ましいと思われる
処理がユーザー要求に対して非同期に実行できるものである場合は、リトライに失敗したリクエストをデッドレターキュー(DLQ)に格納すると、調査や時間を置いての再処理が容易になる
おわりに
今までなんとなくタイムアウトを設定していましたが、文章にしてみると知らないことや注意すべき観点が思った以上にたくさんあり、ためになりました🐣
誤りや、加筆すべき観点が他にあれば教えていただけると嬉しいです
Discussion