LAPRAS株式会社でSREをしております、yktakaha4と申します🐧
最近、LAPRASにポートフォリオをユーザー自身でカスタマイズする機能がリリースされたのですが、
こちらに関連してSREとしてSorryページ(メンテナンスページ)を表示する機能を開発したので、
設計・実装にあたって意識した点などについて書き遺したいと思います✍
ことのおこり
弊社では毎朝エンジニア全員(10数名程度)で集まって朝会を実施しているのですが、
ある日、スクラムチームの naga3 から以下のようなアジェンダが出ました

今回の機能を実装するにあたって、そこそこレコード量が多くユーザー影響の大きいテーブルにカラム追加のマイグレーションをおこなう必要があり、
これについて作業手順上の不安があったので、夜間リリースで対処したい…という議題だったのですが、
そこから マイグレーションの失敗等に伴い本番環境の動作に支障するような状況に陥った際に、メンテナンス画面を表示できないか という議論に発展しました
過去に実装を検討していたこともあったのですが、その時は運用に乗るものとして完成するには至らず、以降 問題があったら何とかする というマインドで凌いできましたが、
システムが長期運用される中で利用者やトランザクション量も増えてきており、何よりもエンドユーザーに安心感をもって利用してもらえるシステムにより近づくため、
(個人的に こんなこともあろうかと と他のタスクを進めながらIssueを育てていた)Sorryページ開発プロジェクトを始動することとしました…🚀

ちなみにIssue Createdは2021年12月頃だった模様
仕様
早速、実装に入る前に検討していた仕様について列挙していきます
弊社のアプリケーションはAWS + Kubernetes(EKS)のインフラ上で稼働しているため、話の切り口はそういった観点が中心ですが、
恐らく他の技術スタックで構築されたものであっても有効な内容でないかと思います🐬
ステータスは503で返却する
基本的な要件ながらケアレスミスをしやすい点として HTTPステータスを200で返却してはいけない ということは有名な話と思います
以下のように検索エンジンにキャッシュされてしまい、メンテナンス後にも尾を引くことになるようです⚰️
ではどのようなステータスコードで返却すべきか…というと、 503 Service Unavailable が推奨されるそうです
ステータスそのものに 一時的な状態であり、レスポンスは頻繁にキャッシュされるべきではない ということで、botや対外システムからのアクセスがあるようなケースでも先方に考慮した挙動をしてもらえそうです
ただ、もしも本当に503ステータスしか返却しないと、以下のようなブラウザごとの素朴なエラー画面を見せることになるので、
サービスがメンテナンス中であることがユーザに伝わるHTML + 503ステータスをユーザーに返すのが一般的と思います

素朴なエラー画面の一例
URLリライトでコンテンツ表示する
コンテンツが決まったら、次はそれをどのようなURLでユーザーに提供するか検討します
一般的なWebサーバーには、ユーザーからあるURLに対してリクエストがあった際に、HTTPヘッダや送信元IPといった特定条件にマッチする場合に本来表示される想定だったものと別のコンテンツを出力する機能があります
(一般的な呼称か理解できていないのですが)大きく2つに区分けでき、特にSorryページを表示するという文脈では以下のような挙動をさせることになります
- リライト方式
- リクエストされたURLに関わらず、 一律
503 Service UnavailableとSorryコンテンツを返却 - ユーザからみると リクエストしたURLのコンテンツが書き換えられた ような見た目になり、 リロードをすると同一URLへリクエストがおこなわれる
- リクエストされたURLに関わらず、 一律
- リダイレクト方式
-
302 Foundなどのステータスと共にSorryコンテンツの配置された別ドメイン(maintenance.example.comなど)にリダイレクトさせてSorryコンテンツを提供 - ユーザからみると リクエストしたURLとは違うサイトに誘導された ような見た目になり、 リロードをすると別のURLへリクエストがおこなわれる
-
どちらを選択すべきかについては Sorryページを表示する主目的がどこにあるか によるものと思います
ユーザビリティの観点で考えると、リライト方式は メンテナンス解消後にページリロードするとユーザが当初期待していたページを表示できる メリットがありそうです(セッションやコンテンツが維持されていることが前提ですが…)
他方リダイレクト方式は、別ドメインにリクエストを振り分けることになり、結果リロードをした場合もそちらのドメインに対してリクエストがおこなわれるので、
メンテナンスページの表示を通じてリクエスト先のサーバを振り分けることで、ユーザーの大量アクセス等に対してのサーキットブレーカー 的な効果が期待できるかもしれません
(こちらも、サーバー構成次第ではありますが…)
なお、本システムにおいては、タイムセール等による特定時刻へのアクセス集中や、テレビ放映に伴う突発的な大量アクセスといった業務特性が無かったこともあり、
リダイレクト方式を選択するメリットが思い当たらなかったためリライト方式で実装をおこなうこととしました
社内からのアクセス時はSorryページを迂回する
Sorryページはシステムのエンドユーザーに対してサービスが非稼働状態であることを伝えるためのものですが、
エンジニア含む社内メンバーにも同じ挙動をしてしまうと、メンテナンス作業や検証がしづらくなってしまいます
社内メンバーからのアクセスがあった際にはSorryページの表示処理を迂回しつつ、エンドユーザーと極力同じ通信経路でアプリケーションにアクセスできるとよさそうです
エンジニア操作で有効・無効を手動切り替え可
今回Sorryページを出力したい動機は 本番作業前に予めメンテナンス状態に移行することで、移行トラブル発生時にエンドユーザーに対して不正な稼働状態のアプリケーションを提供しないようにする ことだったため、
仮にアプリケーションが200のステータスを返す場合であっても、手動でSorryページの表示有無を切り替えられる必要がありそうです
アプリ・DBレイヤでの障害時も利用できる
今回のそもそもの要望は DBマイグレーション中にメンテナンスページを表示する だったので、
Sorryページの有効・無効の切り替えにあたってデータベースが稼働していることを前提にしてしまうと、
例えばメンテナンス失敗時のリカバリでDBバックアップからのリストアが必要になってしまうケース等において正しく動作させられない可能性が出てきます
仮にDBが停止していてもSorryページを表示できるように設計する必要がありそうです
また、今後も継続利用していくにあたって意識したこととして、 EKSが正常動作していない時でも利用できる という要件も加えることとしました
弊社の主要なプロダクトはEKS上に構成されたKubernetes環境に展開されており、SRE・インフラエンジニアの立場としてはEKSを安定運用することが事業面で見ても重要事項となっています
プロダクション環境でk8sを運用されている方であれば馴染みのある話と思いますが、Kubernetesはバージョンアップのサイクルが早く、定期的なクラスタのアップデートが求められます
本番環境のアップデート作業によりEKSクラスタ、引いてはアプリケーションの動作に不具合を生じてしまったケースにおいても利用できる仕組みにできると、より広いユースケースで活用できるものになると考え、実装手法の選択時の指標のひとつとしました
メンテコストが低い
Sorryページの表は重要な機能ではあるものの、そう頻繁に利用されるものではありません(そうならないように努めます…)
いざ使いたい!となった時に機能が故障していて、結果うまく切り替えられなかった…といった悲劇を防ぐ意味でも、
各種マネージドサービスを活用してインフラ・ミドルウェアの維持コストを最小化することが重要そうです
今回見送った要件
今回の実装では上述した要件を満たすことを重視しましたが、
検討段階で思いついたものの最終的に優先度を下げたものも幾つかありましたので、ここに供養したいと思います🙏
メンテナンス理由を表示する
Googleで メンテナンスページで画像検索 すると様々なデザインのものが出てきますが、
メンテナンスの期間や理由を説明しているものが結構出てきます
ユーザーの視点から考えてもとても重要な機能ではありますが、今回の当初の要求である マイグレーションの失敗等に伴い本番環境の動作に支障するような状況に陥った際に、メンテナンス画面を表示できないか に立ち返ると、
本番環境が機能不全に陥った際にユーザーからのアクセスを安全に遮断する機能を極力早く提供することが重要と考えたこと、
また、まず最小限の機能でリリースした後、必要性が生じてからの機能改修でも充分に対応可能な要件であると判断し、今回は見送ることとしました🏈
今後の課題としたいと思います
システム高負荷時でも安定して稼働できる
これは、 URLリライトでコンテンツ表示する の項目でも説明した内容になりますが、
弊社のシステムは高トラフィックにおかれることを前提としたものではなく、またAWSのマネージドサービスを利用していればそれだけで充分な水準の可用性を得ることができると判断し、見送りました
今後の新機能や事業のスケールに伴って、実際にそうした要求が出てきた時に考えたいと思います
AWS障害時に稼働できる
弊社のシステムはマルチAZなどによりAWS内で一定の冗長化を図ってはいるもののマルチクラウド構成にはなっておらず、
ESKクラスタの毀損以外でも、Route 53やALB、CloudFrontといったサービスで障害が発生するとSorryページを表示できないリスクが生じます
これについては悩む部分もありましたが、
あらゆるユースケースを単一のSorryページ表示機能でカバーしようとせず、実際にそのような問題に直面した際に発見したニーズに適合したものを都度作っていく方が、
よりスマートな実装を実現できそうに考え保留することとしました
設計
要件とその優先度がある程度はっきりしたところで、実際にシステム上のどのポインでにSorryコンテンツを返却できそうか、検討をおこないました
結果、以下の5案が洗い出されたので、それぞれについてPros/Consを考えていきました
- 案1:Route53でDNSフェイルオーバー
- 案2:ALBで固定レスポンス返却
- 案3:ALBでSorryサーバーに振り分け
- 案4:EKS内でSorryコンテンツに振り分け
- 案5:アプリケーションでSorryコンテンツを表示
構成図にざっくり配置してみると以下のような感じです
実線の矢印が正常応答時のリクエスト経路、破線がSorryコンテンツ表示時の経路になります
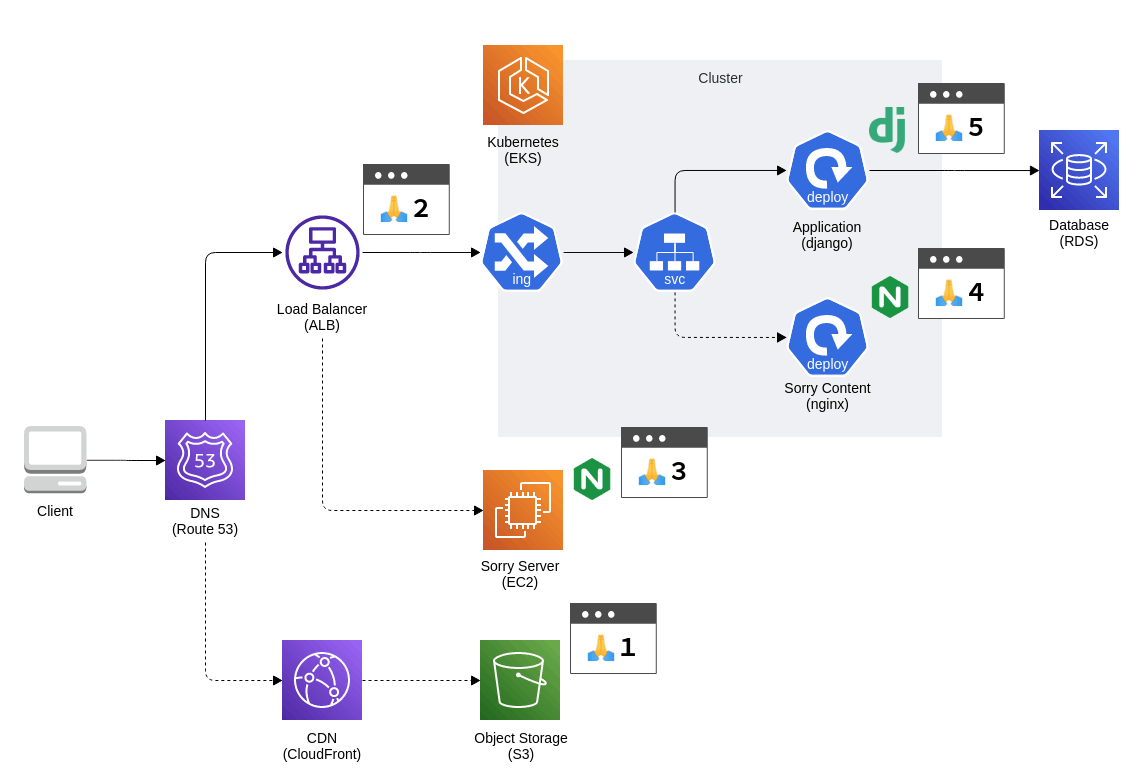
ひとつずつ見ていきましょう🔍
案1:Route53でDNSフェイルオーバー
これは、Route 53のDNSフェイルオーバー機能を用いて、Route 53から任意のエンドポイントにヘルスチェックのリクエストを定期実行し、
バックエンドが正常応答しない場合にセカンダリのリソース(CloudFront+S3で構成されたSorryページ)を提供する…というものです
ネットを調べると具体的な事例も多く見つかり、安心感のある実装と言えそうです
考えられる懸念としては、DNSの向き先レベルで切り替えがおこなわれることになるため、
社内からのアクセス時はSorryページを迂回する という要件を満たすのに工夫が要りそうです
開発者のWebブラウザから Origin ヘッダを偽装してALBに直接アクセスするといった方法はあるかもしれませんが、
普段と違う方法でアクセスすることで意図しない挙動が発生してしまうという二次災害が起きる可能性もあるので、好ましくはなさそうです
また、機能として フェイルオーバー と説明している通り、
手動で意図的に稼働させる仕組みというよりは、人間が介在できないような状況で問題が発生している時に安全に機能停止させる…といった用途を想定した機能である認識のため、
アプリケーションの最終防衛ラインとして別途設計・実装すべきもののようにも感じられます🐵
案2:ALBで固定レスポンス返却
こちらは、ALBのリスナールールで定義できる、固定レスポンスを返却する…という機能を用いてSorryページを提供する方法です
固定レスポンス返却はテキスト列を任意の Content-Type とHTTPステータスを付与して返却できる機能で、まさにSorryページを実装するために用意されている機能と言えそうです
通常時は、ALBにやってきたリクエストを後ろにあるEKSクラスタ上のアプリケーションにフォワードしていますが、このルールを操作してSorryコンテンツを返せば要求が実現できそうです
また、ALBのリスナールールは振り分け条件をかなり柔軟に設定することができ、
特定IPアドレスからリクエストが来た場合といった、社内ユーザーからのアクセスを振り分けたいというユースケースにはうってつけの条件も用意されています
懸念点としては、返却できるテキスト列は 1024文字以下(バイトでないことに注意) が求められるため、
以下の記事などの幾つかのSorryページ実装で言及されている 単一ファイルで完結させる という仕様を満たすことが難しくなります
これについては、 返却するデザインを極力シンプルにし1024文字以下に収める か 画像やCSSをCloudFront(CDN)から配信することを許容する というふたつの選択肢がありましたが、
AWS障害時に稼働できる という要件の優先度を下げたことから、EKSとRDSに依存しない範囲であれば複数のAWSサービスに依存するのは許容することとしました
(弊社のUXDである kotaki さんに作成してもらった、素敵なデザインを尊重したいという個人的な感情もありました)
案3:ALBでSorryサーバーに振り分け
これは、ALBを分岐点にするという意味では案2と似ていますが、固定レスポンスでなくEC2等の任意のサーバーにフォワードさせ、そちらのサーバーでSorryコンテンツを提供するというものになります
ALBの後ろに置くものは固定IPを持てるものなら何でもよいため、AWS外のVPSやレンタルサーバーなどにフォワードするようにすればAWSへの依存度を下げられますし、
動的なレスポンス返却も容易になるので、お知らせコンテンツを表示するといったリッチなSorryページの提供もしやすそうです
ただ、 メンテコストが低い かどうかという観点で考えると、
EC2サーバーを1台持つだけでOSやnginx等のアップデートに対する考慮や、Sorryサーバそのものの可用性をどの程度、どのように担保するか…といった懸念が生じるため、
よほどの事情がなければ選択すべきでない案のようにも感じます
案4:EKS内でSorryコンテンツに振り分け
こちらは、ALBの後ろにあるEKSクラスタ内でServiceリソースの書き換えをおこないSorryページへ誘導する方法です
事例調査の過程で、以下のように実現されている方がいらっしゃいました
Sorryサーバを追加定義する必要がなく、また任意のコンテンツをアプリケーションに変更を加えず構築できるというメリットは魅力的ですが、
今回は 社内からのアクセス時はSorryページを迂回する や アプリ・DBレイヤでの障害時も利用できる という要件があったため、こうした方法は取らないこととしました
案5:アプリケーションでSorryコンテンツを表示
最後に、比較用として、EKS上で稼働するアプリケーションからフィーチャーフラグ のような機能を用いてSorryページへの振り分けをおこなうパターンについても検討しておきます
メリットとしては、普段アプリケーション開発者が触っているリポジトリへの機能改修で実現でき、かつ返却できるレスポンスも柔軟にできますが、
今回達成したい重要な要件である アプリ・DBレイヤでの障害時も利用できる を満たせないため、こちらも見送りとしました
星取表
…といった検討の結果をざっくりまとめると、以下のようになりました🐞
今回の要件に最も合致しそうなのは 案2:ALBで固定レスポンス返却 ということが分かりましたので、こちらで実装を進めていくことにします
| \ | 案1 | 案2 | 案3 | 案4 | 案5 |
|---|---|---|---|---|---|
| ステータスは503で返却する | ◯ | ◯ | ◯ | ◯ | ◯ |
| URLリライトでコンテンツ表示する | ◯ | ◯ | ◯ | ◯ | ◯ |
| 社内からのアクセス時はSorryページを迂回する | ✕ | ◯ | ◯ | ✕ | ◯ |
| エンジニア操作で有効・無効を手動切り替え可 | △ | ◯ | ◯ | ◯ | ◯ |
| アプリ・DBレイヤでの障害時も利用できる | ◯ | ◯ | ◯ | ✕ | ✕ |
| メンテコストが低い | ◯ | ◯ | ✕ | ◯ | ◯ |
実装
記事作成のモチベーションが Sorryページを設計する際に注意したほうがよいこと だったので、ここまで書いてそこそこ満足してしまったのですが、
実装にあたって検討したことについても簡単にまとめたいと思います
Sorryコンテンツ
UXDに起こしてもらったデザインのHTML化は弊社のフロントエンド兼筋肉担当たる kawamata さんにやってもらったのですが、
ある日の14時に依頼をしたところ翌日の9時には初版が送られてきてすげえ…となりました

早すぎワロタ
作ってみての所感をkawamataさんにコメント頂いたので掲載します💪
Sorry ページはとても単純な HTML なのですが、Production ビルド時に HTML の Minify と、画像・CSS リソースの URL を CloudFront の URL へ差し替えるという制約があったためビルドツールを利用することにしました。
候補として Webpack や最近話題の Vite なども検討したのですが、JS が絡まないことと、エントリーポイントの HTML が 2 つあるということから、今回は config 不要で CLI からすぐ開発サーバーの起動や Production ビルドが行える Parcel を利用することにしました。
Parcel なら HTML の Minify は標準で対応し、さらにリソースの URL の差し替えもビルドコマンドにオプションで --public-url を指定するだけで OK でした。結果素早く、シンプルに要件を満たせたので良かったかなと思います。
インフラ
インフラの構築については私が担当しました
とは言っても大したことはしておらず、作成してもらったSorryコンテンツを元々利用していたCloudFront + S3でできたアセット配信の仕組みにアップロードするスクリプトの作成と、
Sorryコンテンツを返却するALBのリスナールールを AWS Load Balancer Controllerから設定する…といったことをやりました
AWS Load Balancer Controllerは、KubernetesのIngressリソース経由でAWSのALBを定義するカスタムコントローラーです
ルールの書き方については、以下のドキュメントに詳しいです
留意したこととしては、Sorryページを表示しない通常時においても、特定のパスにおいてはSorryコンテンツを常に表示しておくようにして
Sorryコンテンツの内容の検証や、社内ユーザーからアクセスした際にはSorryを迂回する(404が表示されるかどうか)といったテストができるようにしています🐾
関連するk8sマニフェスト定義のイメージを示します
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/conditions.web-internal: '[{ ...社内からのアクセスであることを判断できるCondition... }]'
alb.ingress.kubernetes.io/actions.sorry: >
{"type":"fixed-response","fixedResponseConfig":{"contentType":"text/html","statusCode":"503","messageBody":"<!DOCTYPE html> ...Sorryページのコンテンツ... </html>"}}
spec:
rules:
- host: example.com
http:
paths:
# 社内ユーザーのSorryページ迂回用の定義
- path: /*
pathType: "Prefix"
backend:
service:
name: web-internal
port:
number: 81
# Sorryページの定義
# 有効化する場合 path を /* とする
- path: /xxxxxxxxxxxxxx
pathType: "Prefix"
backend:
service:
name: sorry
port:
name: use-annotation
# 一般ユーザーのサービスへのアクセス用の定義
- path: /*
pathType: "Prefix"
backend:
service:
name: web
port:
number: 80
---
apiVersion: v1
kind: Service
metadata:
name: web
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
selector:
# この先にアプリケーションがいる
app: web
---
apiVersion: v1
kind: Service
metadata:
name: web-internal
spec:
ports:
- port: 81
targetPort: 80
protocol: TCP
type: ClusterIP
selector:
# この先にアプリケーションがいる
app: web
運用
ステージングでの検証も済んだので、実際に本番適用して動作を見てみます🔥
適用にあたっては、普段は上記ymlのIngressのSorryページのパスを /* に変更したものを kubectl apply することを想定していますが、
EKSの障害時にはALBのリスナールールに同様の操作を手動で加えれば簡単に発動できます

ただ、その場合はAWS Load Balancer ControllerをEKS上から削除しておかないと自動的にIngressの定義内容で復元されてしまうので、
適用手順については実際に利用しながらブラッシュアップしていく必要があると思っています
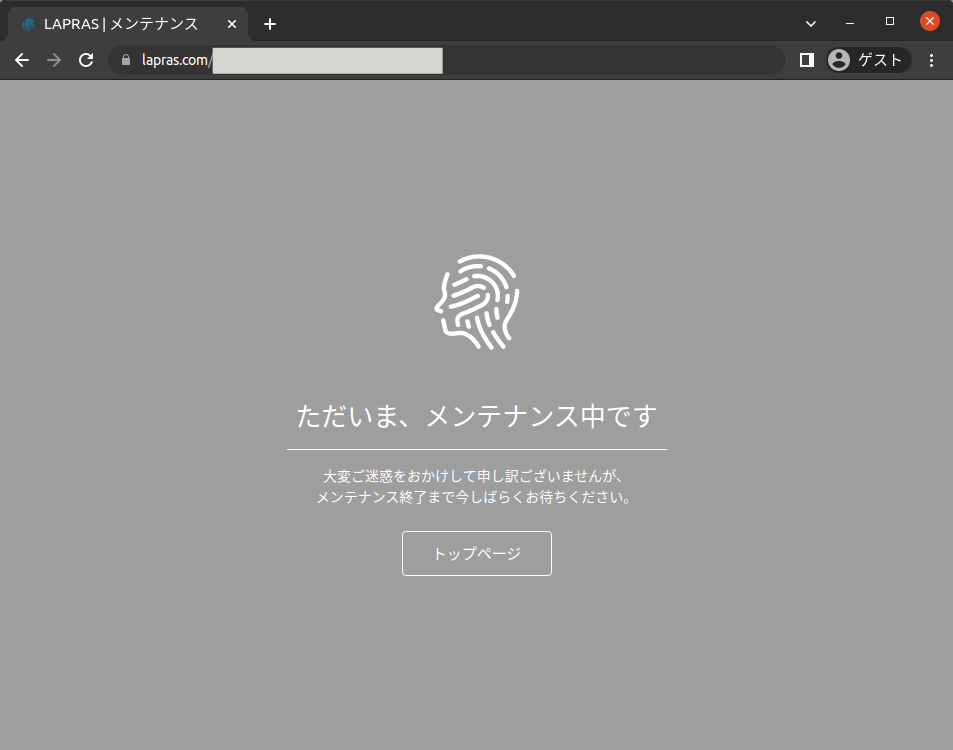
実際に本番環境で動いている様子もお見せしておきましょう…🍰
こちらがLAPRASのSorryページで、
こちらがLAPRAS SCOUTのSorryページです
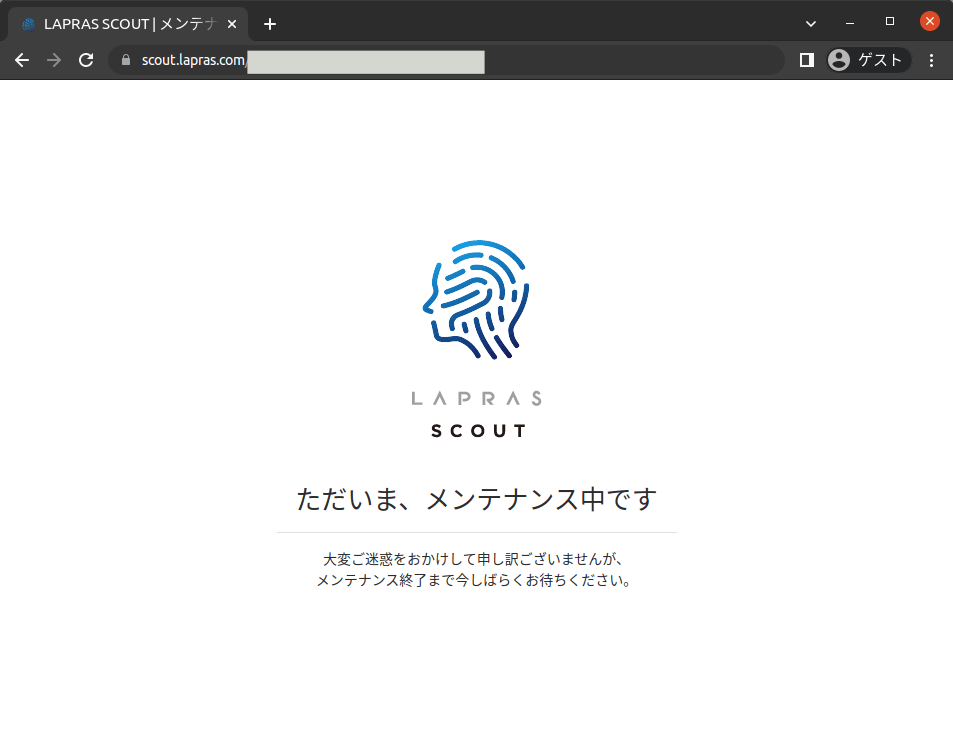
レスポンスもバッチリ503で返却されておりよさそう

なお、肝心のマイグレーションのリリース作業にあたっては、想定していたよりも遥かに早い時間で成功 & 完了してしまい若干拍子抜けの感があったのですが、
今後も色んな用途で使えそうな仕組みをスピーディに本番適用できたので、個人的にはよい機会になったなと思いました🐔
夜半にリリース対応してたらCTOがUniposでほめてくれてうれしかったです💗

おわりに
弊社ではSRE・インフラエンジニアを絶賛募集中です🐠
ポジションに興味を持って頂けた方がいらっしゃいましたらお話しましょう
CTOのrockyさんとの面談はこちら🐡
お待ちしております!

Discussion
素敵な記事ありがとうございます。
訪問したユーザーから見ると理由があると嬉しいですよね。具体的な理由を503ページへ掲載する代わりに、固定で公式Twitterへのリンクを貼るという手もあるようです!メンテナンス予定や障害情報などをTwitterでピンドメしておけば訪問したユーザーへ理由を説明できるかもしれません。
ありがとうございます!
なるほど…Twitterを埋め込むのはQiitaなどでも実装されているようですね
今回は、ALBから返却できるコンテンツサイズの制限が思いの他厳しく、UXDの方へもそれに伴い最小限にしてほしいとオーダーしたのでシンプルな画面になりましたが、
一度リリースできたことで残文字数がはっきりしましたので、サイズ制限とも相談しながらぜひ検討したいと思います!