防犯カメラの動体検知を実装する③: なりすまし防止機能の実装
はじめに
防犯カメラの動体検知を実装する②ではdamo-yoloを使い人物の検出を行いました。その際、リポジトリにあったdemo.pyをそのまま使用しましたが、この記事ではアプリケーションに組み込める形を作っていきます。
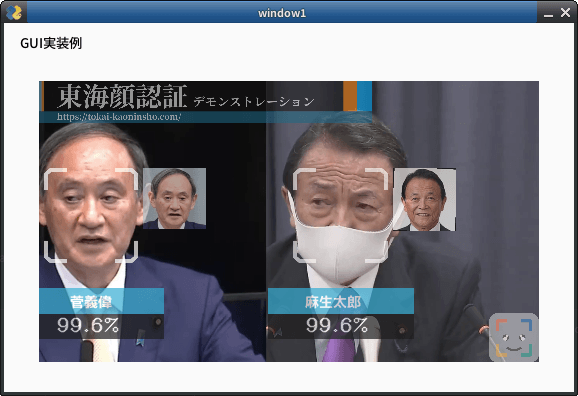
最初に完成したプログラムの出力をみてみましょう。

-
標準出力
スマホのお姉さん 類似度 96.4% 座標 (77, 492, 181, 388) 時刻 2024,12,03,09,33,14,628409 出力 ------- 物体検出結果: 物体: person, スコア: 0.88, バウンディングボックス: [117.251564 22.69603 343.45676 734.7988 ] 物体: cell phone, スコア: 0.53, バウンディングボックス: [221.03716 520.6959 259.49316 670.29706] 物体: potted plant, スコア: 0.53, バウンディングボックス: [4.2177245e-02 2.9340579e+02 5.6148739e+01 7.3426111e+02] 物体: laptop, スコア: 0.53, バウンディングボックス: [7.0365340e-01 6.0334821e+02 1.1288249e+02 7.3260529e+02] -
元動画:PIXABAY
リアルタイムで顔とスマホの座標が得られると、なにが嬉しいのでしょうか?
顔認証において、アンチスプーフィング(なりすまし防止)は永遠の課題です。
ディープラーニングを採用したり画像解析を行ったりするわけですが、どのような光源でも変わらない性能(汎化性能)を担保するのは制限があり、完璧なアンチスプーフィングは存在しません。
- 顔なりすましの微細な痕跡を可視化!なりすましの痕跡を応用したFace Anti-spoofingモデル「STDN」によって高精度を達成!
- 新しい畳み込み演算CDCによる堅牢なFace Anti-spoofing(なりすまし防止)モデル
- 顔認証の時、本人がその場にいるか写真かを判定する技術

しかしながら、必ずしも新規技術を開発する必要はないのではないかとも思います。というのも、紙にプリントされた顔の場合、紙を持つ手や紙そのものを検出できればいいわけです。あるいはプリントされた顔画像は目の動きや顔の角度が不変なので、それを検出する方法は複数あり、実際に実装した例を記事としてだしてます。



それではスマホに写した顔画像や顔動画はどうでしょうか?
この場合はスマホそれ自体を検出できればいいわけです。スマホの座標と顔の座標を計算し、スマホ座標の内側に顔座標があれば、それはスマホで表示した顔である、と分かるわけです。

この記事では顔とスマートフォンを検出し、座標を返すプログラムを考えていきます。
具体的には、DAMO-YOLO技術をFACE01で扱えるコードとして完成させます。
FACE01とは
FACE01とはコミュニティライセンスの顔認証フレームワークです。日本人専用の顔学習済みモデルが同梱されています。

FACE01では、内部のジェネレーターによって、入力動画の1フレームずつに様々な情報が付与されたオブジェクトが取り出せます。顔の座標、信頼度、類似度、人名ほか、色々な情報が次々と得られるわけです。
FACE01のジェネレーターは以下のように定義されます。
# ジェネレータを生成
gen = Core().common_process()
# ジェネレータオブジェクトからフレームごとの情報を取得
for i in range(0, 100):
frame_data = gen.__next__()
この中にはnumpy形式の画像そのものも含まれるわけですが、これをDAMO-YOLOの学習済みモデルに渡して、何が写っていたか情報をえる、という方法をとります。
Inferモジュールの実装
demo.pyを参考に、Inferクラスとしてモジュール化したスクリプトをbase.pyとして作成しました。
"""
Summary:
このスクリプトは、DAMO-YOLOを使用して画像内の物体を検出するプログラムです。
指定された画像をモデルに入力し、検出された物体のクラス、スコア、バウンディングボックスを出力します。
スコアが0.5以上の検出結果のみを表示します。
"""
import numpy as np
import torch
from face01lib.damo_yolo.damo_internal.config.base import parse_config
from face01lib.damo_yolo.damo_internal.detectors.detector import build_local_model
from face01lib.damo_yolo.damo_internal.structures.bounding_box import BoxList
from face01lib.damo_yolo.damo_internal.utils import postprocess
from face01lib.damo_yolo.damo_internal.utils.demo_utils import transform_img
from PIL import Image
# クラスIDからクラス名へのマッピング
COCO_CLASSES = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange",
"broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed",
"dining table", "toilet", "TV", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven",
"toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"
]
class Infer:
"""
画像内の物体を検出するための推論クラス。
Attributes:
config: モデルの設定ファイル。
ckpt_path: 学習済みモデルのチェックポイントのパス。
infer_size: 推論時の画像サイズ(デフォルトは640x640)。
device: 推論を行うデバイス(デフォルトはCUDA)。
engine_type: 推論に使用するエンジンタイプ(torch、onnx、tensorRTのいずれか)。
"""
def __init__(self, config, ckpt_path, infer_size=[640, 640], device='cuda', engine_type='torch'):
"""
初期化メソッド。
Args:
config: モデルの設定ファイル。
ckpt_path: 学習済みモデルのチェックポイントのパス。
infer_size: 推論時の画像サイズ(デフォルトは640x640)。
device: 推論を行うデバイス(デフォルトはCUDA)。
engine_type: 推論に使用するエンジンタイプ(torch、onnx、tensorRTのいずれか)。
"""
self.device = device if torch.cuda.is_available() else 'cpu'
self.config = config
self.infer_size = infer_size
self.engine_type = engine_type
self.model = self._build_model(ckpt_path)
def _build_model(self, ckpt_path):
"""
モデルを構築します。
Args:
ckpt_path: 学習済みモデルのチェックポイントのパス。
Returns:
構築されたモデル。
"""
print(f'{self.engine_type}エンジンを使用してモデルを構築中...')
if self.engine_type == 'torch':
model = build_local_model(self.config, ckpt=ckpt_path, device=self.device)
# ckpt = torch.load(ckpt_path, map_location=self.device)
ckpt = torch.load(ckpt_path, map_location=self.device, weights_only=True) # モデルの重み(パラメータ)のみを使用し、その他のオブジェクト(トレーニングの状態やカスタムクラスのインスタンスなど)は読み込まない。標準出力の警告文回避。
model.load_state_dict(ckpt['model'], strict=True)
model.eval()
elif self.engine_type == 'onnx':
raise NotImplementedError("この例ではONNXエンジンは未実装です。")
elif self.engine_type == 'tensorRT':
raise NotImplementedError("この例ではTensorRTエンジンは未実装です。")
else:
raise ValueError(f"サポートされていないエンジンタイプです: {self.engine_type}")
return model
def preprocess(self, image_path):
"""
画像を前処理します。
Args:
image_path: 処理対象の画像ファイルのパス。
Returns:
前処理後の画像テンソルと元画像の形状。
"""
origin_img = np.asarray(Image.open(image_path).convert('RGB'))
img = transform_img(origin_img, 0, **self.config.test.augment.transform, infer_size=self.infer_size)
img = img.tensors.to(self.device)
return img, origin_img.shape[:2]
def postprocess(self, preds, origin_shape):
"""
推論結果を後処理します。
Args:
preds: モデルの推論結果。
origin_shape: 元画像の形状。
Returns:
バウンディングボックス、スコア、クラスインデックスのリスト。
"""
if self.engine_type == 'torch':
output = preds
elif self.engine_type == 'onnx':
scores = torch.Tensor(preds[0])
bboxes = torch.Tensor(preds[1])
output = postprocess(scores, bboxes,
self.config.model.head.num_classes,
self.config.model.head.nms_conf_thre,
self.config.model.head.nms_iou_thre)
else:
raise ValueError(f"サポートされていないエンジンタイプです: {self.engine_type}")
if len(output) > 0:
output = output[0].resize(origin_shape)
bboxes = output.bbox.cpu().numpy()
scores = output.get_field('scores').cpu().numpy()
cls_inds = output.get_field('labels').cpu().numpy()
else:
bboxes, scores, cls_inds = [], [], []
return bboxes, scores, cls_inds
def forward(self, image):
"""
画像を推論します。
Args:
image: 推論対象の画像(ファイルパスまたは numpy.ndarray)。
Returns:
推論後のバウンディングボックス、スコア、クラスインデックスのリスト。
"""
with torch.no_grad(): # 推論時に勾配追跡を無効化
if isinstance(image, str): # ファイルパスの場合
origin_img = np.asarray(Image.open(image).convert('RGB'))
elif isinstance(image, np.ndarray): # numpy.ndarray の場合
origin_img = image
else:
raise ValueError("`image` はファイルパスまたは numpy.ndarray でなければなりません。")
# 前処理
img = transform_img(origin_img, 0, **self.config.test.augment.transform, infer_size=self.infer_size)
img = img.tensors.to(self.device)
# 推論
preds = self.model(img)
# 後処理
return self.postprocess(preds, origin_img.shape[:2])
ディレクトリ構造は以下のようになっています。DAMO-YOLO由来のファイルのすべてのimport文を、矛盾の無いように書き換えてあります。
FACE01_DEV/face01lib/damo_yolo$
./
├── __init__.py
├── __pycache__/
│ ├── __init__.cpython-310.pyc
│ └── base.cpython-310.pyc
├── assets/
│ ├── dog.jpg
│ ├── input.png
│ └── input_1.mp4
├── base.py
├── configs/
│ ├── __pycache__/
│ │ └── damoyolo_tinynasL20_T.cpython-310.pyc
│ └── damoyolo_tinynasL20_T.py
├── damo_internal/
│ ├── __init__.py
│ ├── __pycache__/
│ │ └── __init__.cpython-310.pyc
│ ├── apis/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── detector_inference.py
│ │ ├── detector_inference_trt.py
│ │ └── detector_trainer.py
│ ├── augmentations/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── box_level_augs/
│ │ └── scale_aware_aug.py
│ ├── base_models/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── backbones/
│ │ ├── core/
│ │ ├── heads/
│ │ ├── losses/
│ │ └── necks/
│ ├── config/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── augmentations.py
│ │ ├── base.py
│ │ └── paths_catalog.py
│ ├── dataset/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── build.py
│ │ ├── collate_batch.py
│ │ ├── datasets/
│ │ ├── samplers/
│ │ └── transforms/
│ ├── detectors/
│ │ ├── __pycache__/
│ │ └── detector.py
│ ├── structures/
│ │ ├── __init__.py
│ │ ├── __pycache__/
│ │ ├── bounding_box.py
│ │ ├── boxlist_ops.py
│ │ └── image_list.py
│ └── utils/
│ ├── __init__.py
│ ├── __pycache__/
│ ├── boxes.py
│ ├── checkpoint.py
│ ├── debug_utils.py
│ ├── demo_utils.py
│ ├── dist.py
│ ├── imports.py
│ ├── logger.py
│ ├── metric.py
│ ├── model_utils.py
│ ├── timer.py
│ └── visualize.py
├── pretrained_models/
│ └── damoyolo_tinynasL20_T_420.pth
└── requirements.txt
32 directories, 44 files
FACE01側では、display_GUI_window_JAPANESE_FACE_V1_with_YOLO.pyからbase.pyのInferクラスを呼び出して使えるようにしました。
"""
顔画像と物体を検出し、回転・クロップ・表示するウィンドウアプリケーション.
Summary:
このプログラムは、顔認識モデルとDAMO-YOLO物体検出モデルを使用して、
動画フレーム内の顔と物体を検出し、それらの情報をリアルタイムで表示します。
GUIウィンドウ上に処理結果を表示し、詳細情報をターミナルに出力します。
Usage:
.. code-block:: bash
python display_GUI_window_JAPANESE_FACE_V1_with_YOLO.py <exec_times>
Features:
- 顔認識と物体検出をリアルタイムで実行
- 検出結果(類似度、座標、物体名など)をターミナルに表示
- GUIウィンドウ上で処理結果を更新表示
- 処理回数または検出件数に応じてプログラムを終了
Example:
.. code-block:: bash
python display_GUI_window_JAPANESE_FACE_V1_with_YOLO.py
Result:
- GUIウィンドウで処理結果をリアルタイム表示
- ターミナルに検出データの詳細を出力
"""
import sys
import os
dir: str = os.path.dirname(__file__)
parent_dir, _ = os.path.split(dir)
sys.path.append(parent_dir)
import tkinter as tk
from tkinter import Button, Label
from typing import Dict
import cv2
from PIL import Image, ImageTk
from face01lib.Core import Core
from face01lib.Initialize import Initialize
from face01lib.damo_yolo.base import Infer, COCO_CLASSES # base.pyをモジュールとして使用
from face01lib.damo_yolo.damo_internal.config.base import parse_config
def main(exec_times: int = 50) -> None:
"""
ウィンドウを表示し、顔と物体を検出するメイン関数.
Args:
exec_times (int, optional): 処理を実行する回数. デフォルトは50回.
Returns:
None
"""
# 初期化処理
CONFIG: Dict = Initialize('JAPANESE_FACE_V1_MODEL_GUI').initialize()
# DAMO-YOLOモデルの設定
config_file = "face01lib/damo_yolo/configs/damoyolo_tinynasL20_T.py"
ckpt_path = "face01lib/damo_yolo/pretrained_models/damoyolo_tinynasL20_T_420.pth"
# 設定ファイルを解析してconfigを作成
config = parse_config(config_file)
damo_infer = Infer(config=config, ckpt_path=ckpt_path)
# tkinterウィンドウの作成
root = tk.Tk()
root.title('FACE01 example with JAPANESE_FACE_V1 and DAMO-YOLO')
root.geometry('800x600')
# 画像を表示するためのラベル
display_label = Label(root)
display_label.pack()
# 終了ボタンの設定
def terminate():
"""ウィンドウを終了する関数."""
root.destroy()
terminate_button = Button(root, text="terminate", command=terminate)
terminate_button.pack(pady=10)
# ジェネレータを生成
gen = Core().common_process(CONFIG)
try:
# カウント変数を初期化
count = 0 # フレーム全体でカウントを維持
max_count = 200 # 最大回数を設定
# 'exec_times' 回処理を繰り返す
for i in range(0, exec_times):
# ジェネレータオブジェクトから次の値を取得
frame_datas_array = gen.__next__()
for frame_datas in frame_datas_array:
# 顔認識結果をターミナルに出力
for person_data in frame_datas['person_data_list']:
if not person_data['name'] == 'Unknown':
print(
person_data['name'], "\n",
"\t", "類似度\t\t", person_data['percentage_and_symbol'], "\n",
"\t", "座標\t\t", person_data['location'], "\n",
"\t", "時刻\t\t\t", person_data['date'], "\n",
"\t", "出力\t\t\t", person_data['pict'], "\n",
"-------\n"
)
count += 1 # カウントをインクリメント
if count >= max_count: # カウントが最大に達したらループを抜ける
raise StopIteration # 外側のループも終了するために例外を送出
# DAMO-YOLOで物体検出を実行
bboxes, scores, cls_inds = damo_infer.forward(frame_datas['img'])
# 検出結果をターミナルに表示
print("物体検出結果:")
for bbox, score, cls_ind in zip(bboxes, scores, cls_inds):
if score >= 0.5: # スコアが0.5以上の物体のみ出力
class_name = COCO_CLASSES[int(cls_ind)] # クラス名を取得
print(f"物体: {class_name}, スコア: {score:.2f}, バウンディングボックス: {bbox}")
# 画像をPIL形式に変換
img = cv2.cvtColor(frame_datas['img'], cv2.COLOR_BGR2RGB) # OpenCVのBGRをRGBに変換
img = Image.fromarray(img) # OpenCVの画像をPIL画像に変換
img = ImageTk.PhotoImage(img) # PIL画像をImageTkに変換
# 新しい画像でラベルを更新
display_label.config(image=img)
display_label.image = img
# ウィンドウを更新
root.update_idletasks()
root.update()
except StopIteration:
# 動画の供給が終了、またはカウントが最大に達した場合の処理
print("処理が完了しました。プログラムを終了します。")
root.destroy() # ウィンドウを閉じる
except Exception as e:
# その他の予期しないエラーが発生した場合の処理
print(f"予期しないエラーが発生しました: {e}")
root.destroy() # エラーが発生した場合もウィンドウを閉じる
finally:
# 終了処理
print("終了処理を行っています...")
if __name__ == '__main__':
# メイン関数を呼び出す
main(exec_times=200)
動作確認
このエグザンプルスクリプトを動作させると、記事冒頭で紹介しているウィンドウがリアルタイムで表示されます。
- 標準出力
スマホのお姉さん 類似度 96.4% 座標 (77, 492, 181, 388) 時刻 2024,12,03,09,33,14,628409 出力 ------- 物体検出結果: 物体: person, スコア: 0.88, バウンディングボックス: [117.251564 22.69603 343.45676 734.7988 ] 物体: cell phone, スコア: 0.53, バウンディングボックス: [221.03716 520.6959 259.49316 670.29706] 物体: potted plant, スコア: 0.53, バウンディングボックス: [4.2177245e-02 2.9340579e+02 5.6148739e+01 7.3426111e+02] 物体: laptop, スコア: 0.53, バウンディングボックス: [7.0365340e-01 6.0334821e+02 1.1288249e+02 7.3260529e+02]
標準出力は1フレームごとの情報が出力され続けます。
さて、この出力を見ると顔の座標とスマホの座標はそれぞれ以下のようになっています。
- 顔:(77, 492, 181, 388)
- スマホ:[221.03716 520.6959 259.49316 670.29706]
もしスマホの座標の内側に顔の座標が存在したとすれば、それはスマホで表示した顔画像であり、「なりすまし」であると判断できるでしょう。
さいごに
YOLO系の中でもDAMO-YOLOは使いやすいライセンスであり、また速度と精度のバランスが取れた学習済みモデルを提供しています。FACE01のようにリアルタイム性を重視したアプリケーションにも馴染みやすいと思います。
また追加学習も比較的簡単なことから、「バールのような物」を持っている人物を検出なども可能になる拡張性を持っています。
以上です。ありがとうございました。
Discussion