顔認証に使う学習モデルを作ろう!⭐️
対象とする読者
- MNIST(手書き数字認識)の次に何をしていいかわからない方
- 顔認識に興味がある方
- 画像認識の実践的なスキルを身につけたい方
- AIに興味がある高校生や大学生
はじめに: 挑戦への動機づけ
手書き数字(0〜9)を識別するプログラム「MNIST」は、機械学習、特に深層学習の入門として有名で、機械学習の「Hello World」と呼ばれるほど広く利用されています。電子工作で例えると、ラズベリーパイの「Lチカ」に相当すると思います。
それで次は何をしたらいいでしょう?
わたしの推しは、ずばり「顔認識」です。
え?YouTubeに色々あるって?いえいえ。ここだけの話ですが、あれって全部、既にあるサービス・ライブラリの利用方法を解説してるだけなんです。だいたい3つのパターンな感じです。
-
Pythonのライブラリを使用した顔認識の実装パターン
- face-recognitionライブラリを使用した顔認識の実装方法を解説
- OpenCV、Dlib、face_recognitionなどのライブラリを使用した顔認識の実装方法の紹介
-
特定のフレームワークを活用したパターン
- PythonライブラリのStreamlitとAzure Face APIを組み合わせた顔検出アプリ作成解説
- FACE01という顔認識フレームワークを使用した動画からの顔画像データ抽出方法
-
顔認識サービスのクラウドAPIを利用するパターン
- Google Cloud Vision APIを使用した顔検出機能の紹介: 動画内の顔の検出、境界ボックスの生成、顔の属性検出。
- Microsoft Face API、Amazon Rekognition、IBM Watson Visual Recognition APIなどの、クラウドサービスの顔認識機能の比較と使用方法の紹介
これら全てに共通しているのは、既にある学習済みモデルを利用している、ということなんです。
でもMNISTでは手書き数字を認識するための学習モデルをつくるコードを作り、学習させて、検証までやりました。
MNISTの場合は0〜9までの10クラス分類でした。MNISTの次に挑戦するなら、クラス数を増やした学習です。
CIFAR-100, Fashion-MNIST, Kuzushiji-Kanjiなどありますが、どうせなら実用的なものをやりたいですよね。
オープンセット分類をご存知ですか?
不良品の画像診断なんかに用いられるのですが、一言で言えば「クラス数無制限の分類」です。この分類は工場や農家で実際に使われているのです。
だから、MNISTを卒業したら、オープンセット分類をやりましょう!
とはいえ、画像データセットを用意するのはなかなか大変です。不良品のネジとか形の崩れたきゅうりの画像を沢山集めるのは現実的ではありません。
そこで偉大な先人たちは
- 大好きなアイドルの顔分類
- ポケモンの分類
などを「自らの修練」として選んだのです[1]。
しかしそうした偉人たちはさらに修練を進め、今ではより高みに登ってしまったがゆえ、今だったらこういうコードを書くのに、という状況に対応していません。
2024年、いや、2025年に是非挑戦してほしいオープンセット分類。イマドキのやり方で挑戦しませんか?
この記事を読み、この記事のコードを使えば、学習用のコードを動作させ、出来上がったモデルを検証することが出来ます。
さらに前処理済みの顔データセットも付属します!!スクレイピングや前処理の必要が無いのは嬉しいですね⭐️[2]
もちろん顔認証だけでなく、様々な画像分類に使うことが出来ます。

顔認証について小難しい〇〇をチラ見する
< 時間のない方はここを飛ばしてください。 >
顔認証というのはオープンセット分類だ、というのは先述しました。実際に現場で使える技術を学ぼう!という動機も書きました。
でもですね、実務で使えるレベルって小難しい沢山のことに対応しなきゃいけないんです。MNISTの次に挑戦するなら、そういった小難しい〇〇はすっ飛ばしたいですよね。
例えば照明、カメラの収差。レンズ選びと撮影距離によって、被写体は全く別物くらいに写ります。ワールド座標系・カメラ座標系とか。こういうのは実務に向き合う時に覚えればいいことです。[3]
ただ、顔データセットを作る時に、同じ人物(同じクラス)なのにどうしてこんなに写りが違うのだろう、と思ったら調べてみてください。
小難しい話はとばしたいところですが、学習モデルを作成するコードを書くにあたって、これはどんな目的のコードなのか?という点は押さえておきたいところです。
それは認証にはスコープがあるということです。どんな規模感で、どんなスコープを対象に使うか、ということですね。そういうのが違うと、求められる学習モデルが違ってくるので、必然的に学習コードが違ってくるわけです。
小規模タスク
特定環境、例えば企業内の認証システムなどでは、高精度な1対1認証が求められます。私感ですが、最もよく使用されるのは指紋認証のように感じます。スマホのロック解除にも使われますね。企業内の顔認証システム構築では一般的にこのスコープに含まれます。
このようなスコープで使われるのは1対1モードの認証です。

中規模タスク
公共の顔認識がこのスコープに含まれます。防犯カメラの映像解析やネットを対象にしたリサーチなどですね。あるいはコンサート会場の顔認証ゲートなんかです。
オープンソースで開発されているFACE01やその学習済みモデルはここに含まれます。
大規模タスク
全人種を対象にした顔認証システムがここに含まれます。航空機発着ゲートなんかに使われています。
【1対1モード】と【1対多モード】の違い
先程のスコープに対応させるため、認識システムには、大きく分けて2つのモードがあります。それぞれの特徴と使用シーンを見てみましょう。
【1対1モード】
「1対1」モードは、2つの顔画像を比較し、それらが同一人物かどうかを判定する手法です。このモードは、ペア単位の認証が求められるタスクに使われます。
- 類似度計算が中心
- ペア単位での判定(学習が比較的容易)
- データベースとの照合も行わないため、処理が簡潔。
通常、顔認証システムと呼ばれる多くが「1対1」モードであるといえます。正解データとの突き合わせをすればよいだけなので、(ちゃんとやれば)比較的簡単に精度を稼げます。
【1対多モード】
「1対多」モードは、1つの顔画像をデータベースと照合し、最も一致する人物を特定する方法です。監視カメラシステムや公共施設のアクセス制御など、大量の顔データを管理するシステムで一般的に使用されます。
- データベース全体と照合するため、計算コストが高い
- 顔IDの分類タスクとして設計される(学習が難しい)
- 複数の人物から候補を絞り込むことが前提
先ほど紹介したFACE01やその学習済みモデルはここに含まれます。
「1対多」モードは「1対1」モードを包含します。
なので1対多モード用に作られた学習モデルは1対1モードでも問題無く使用可能です。
| 特徴 | 1対1モード | 1対多モード |
|---|---|---|
| 概要 | 特定の個人の顔データと入力画像を比較する。 | 入力画像をデータベース内の複数の顔データと照合する。 |
| 特徴 | 比較対象が1人のみで誤認識が少ない。 | 誤認識を防ぐ高い精度が必要。 |
| 用途 | IDカードやICカードによる本人認証。 | 監視カメラや公共施設での人物特定。 |
ネットワークの設計
さて、ここからは実際に学習用のコードを設計していきましょう。
先程の小難しい話に、1対1モードと1対多モードの話がありましたが、ここでは設計が単純な1対1モードのコードを設計します。
ネットワークはSiamese Networkを用います。Siamese Networkを初めて目にする方は、先にはやぶさの技術ノート: 【深層距離学習】Siamese NetworkとContrastive Lossを徹底解説を読むと良いでしょう。とてもわかり易くまとまった良記事です。
誤解を恐れずに言えば、Siamese Networkとは2つの入力を受け取り、それらの類似度を学習する構造のことです。その構造の中身をどうするかは設計者が自由に取捨選択します。シンプルな考え方なので、実装も容易です。
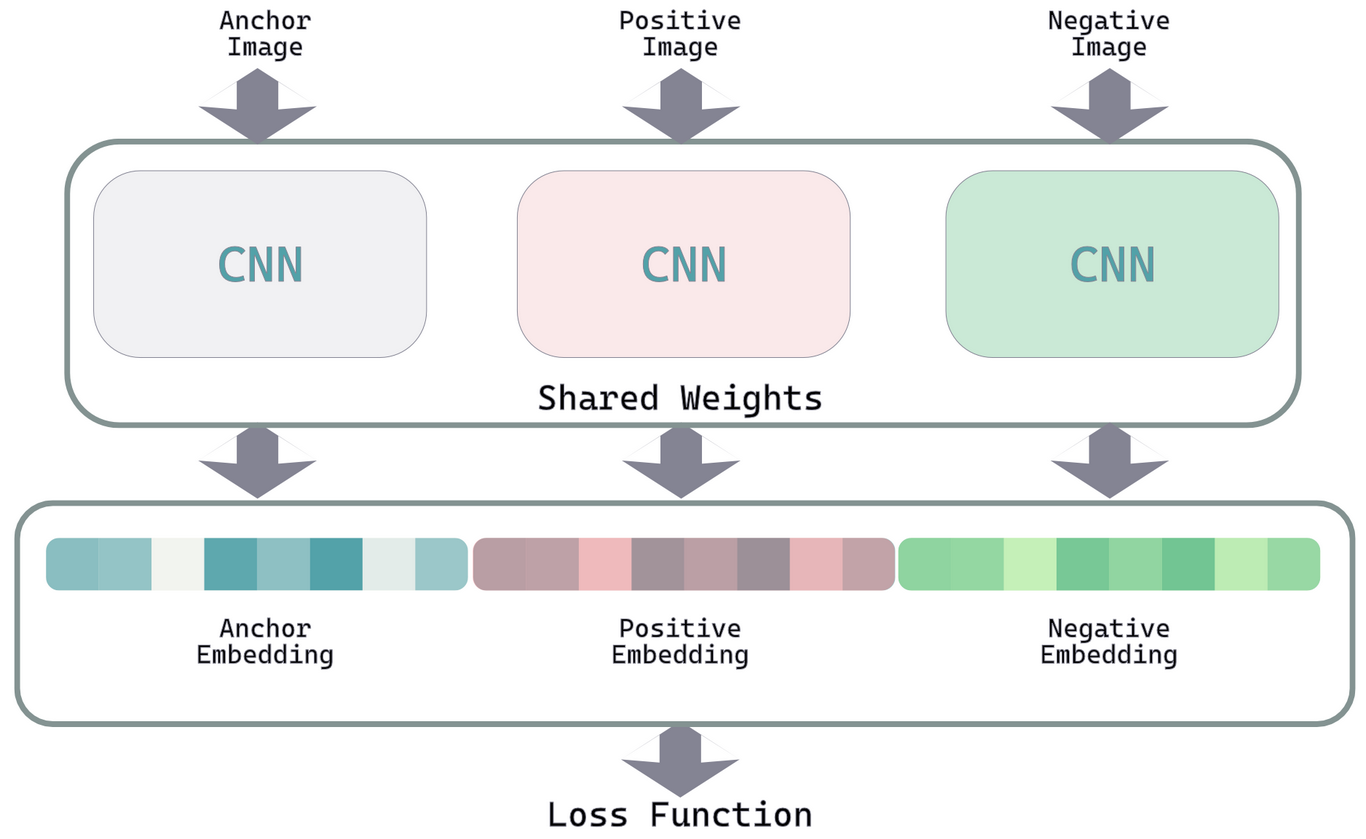
それではバックボーンや損失関数、オプティマイザ・スケジューラを決めていきましょう。
ここではよく使われるものを紹介し、最後にどれを使うか説明します。
Siamese Networkにおけるバックボーン
バックボーンとしてEfficientNetV2やResNetなどを利用します。これらは、入力画像から特徴量を抽出(入力データを高次元の特徴ベクトルに変換)するのが仕事です。扱いやすいのはなんと言ってもモバイル系のネットワークです。それについては拙著のモバイル学習モデルの俯瞰: MobileNetV1からEfficientNetV2までをご参照ください。
モデルの大きさと学習の効率性からtimmから提供されているEfficientNetV2のB0事前学習済みモデルを採用します。この事前学習済みモデルはImageNetデータセットでトレーニングされています。これを転移学習することで、任意の画像分類に利用できるわけです。
よく使われる損失関数
Siamese Networkでは、以下のような損失関数をよく使います。
Contrastive Loss
Siamese Networkにおいて最も一般的です。
Triplet Loss
Triplet Lossは、アンカー、ポジティブ、ネガティブの3つの入力を用いて類似性を最適化します。この損失関数は、埋め込み空間での識別性を向上させる効果があります。dlibの学習済みモデルはこのトリプレットロスを採用しています。
-
D(a, p) a p -
D(a, n) a n -
\text{margin}
Binary Cross-Entropy Loss
2つの入力が同一か否かを確率的に予測します。
-
y_i -
\hat{y}_i -
N
これらの中で、ここでは顔認証タスクに定評のあるTriplet Lossを採用します。Triplet lossについては拙著顔認証が顔を識別する仕組みをご参照ください。
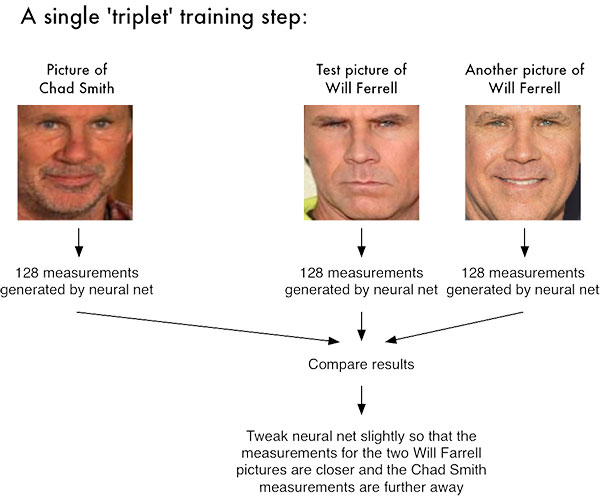
損失関数について補足
もしかしたら、「TripletMarginLossを使うなんて、もしかして時代遅れじゃない?」と思われる読者様もいるかもしれない、と思ったので追記します。
<顔認証について小難しい〇〇をチラ見する>の章で記載したスコープが、損失関数の選択に関わってきます。
この記事で作成する顔認証用学習モデルは1対1モード用です。この場合、ペア間の距離が重要になってきます。なので、クラス間分離において厳密性は問われません。それ故、学習も収束しやすく、記事として採用しました。
もし1対多認証用の学習モデルを作ろうと思ったら、ArcFace Lossなど、クラス間分離を厳密に分離する損失関数を使います。同じデータセットを使っても、こちらの方が(クラスセンターを計算したりするので)計算コストがうんと高いです。それに適当に学習率を決めると学習が収束しません。あとそもそもバッチサイズが重要になるのでGPUメモリをめっちゃ食います。普通のGPU、6〜8GBのVRAMくらいではあっという間にエラーで処理が止まってしまいます。
これではMNISTの次に挑戦するべき難易度ではなくなってしまいます。
というわけです。(補足終わり)
必要なID数(クラス数)の見積もり
データセットについて考えましょう。設計上、どこに気をつければよいのでしょうか?
クラス数(ID数)よりペア数が重要
通常、何も考えなければ、データセットのクラス数(ID)は多ければ多いほどよいとされます。ただ、そこにさけるパワーは有限ですし、そもそも画像を揃えられないこともしばしばです。
1対1認証では、IDの数そのものよりも生成可能なペアの数が重要です。
ですから人で考えれば、1枚ずつ1万人分の画像を集めるよりも、100枚ずつ100人分の画像を集めたほうがよいのです。
(だから1対1モードを選んだのですが)
データセットは人数分、名前をフォルダ名にしてまとめればよいでしょう。
ペア数のペアとは、以下のような考え方です。
-
同一ID内(Positiveペア)
- 同一人物間でのペア。
-
異なるID間(Negativeペア)
- 異なる人物間でのペア。
このペア数が、1対1認証では重要である、ということです。
また、推奨されるID数の目安も知っておくと良いでしょう。
- 小規模タスク 1000ID。
- 中規模タスク 1000~2000ID。
- 大規模タスク 5000ID以上。
その他、ペアの多様性や各IDに含まれる画像数がモデルの性能に影響を与えるため、顔画像データセットの質が重要です。(コレ自体でいくらでも精度が変わってしまう。。)
なんと付属の顔データセットは前処理済みです!やったね⭐️
オプティマイザとスケジューラの選択
学習をやっている方々だと、「いつもコレ」という鉄板の組み合わせがあるものです。わたしの推しは特に無いのですが、よく見かける組み合わせを記載します[4]。
Adam + CosineAnnealingLR
-
適用シーン
- 汎用的な学習タスク。とりあえずみんなコレ。
-
特徴
- Adamの安定した収束性能と、CosineAnnealingLRの柔軟な学習率調整を組み合わせた構成。
- 学習の中盤で学習率を徐々に下げ、収束をスムーズにする。
-
メリット
- 調整が少なくて済み、広範なタスクで安定した性能を発揮。他の組み合わせを選んだ挙句学習が収束しなくて、もしかしてオプティマイザが…という無益なストレスを受けずに済むのが最大のメリットかもしれない。
AdamW + ReduceLROnPlateau
-
適用シーン
- 大規模モデルや過学習が懸念される場合。
-
特徴
- AdamWがL2正則化で過学習を抑制し、ReduceLROnPlateauが学習の停滞時に動的に学習率を調整。
-
メリット
- モデルの安定性と精度向上を両立できる。
- 検証損失が改善しないタイミングで自動的に学習率を調整。
SGD + StepLR
-
適用シーン
- 大規模データセットや微調整が必要な場合。といいつつ、一発逆転を狙いたい時に使う。
-
特徴
- SGDによるシンプルで計算効率の良い更新と、StepLRによる段階的な学習率減少を組み合わせ。
-
メリット
- 長期間の学習や大規模データでのモデル改善に効果的。
Ranger + ExponentialLR
-
適用シーン
- 勾配の変動が激しい場合や学習が不安定な場合、らしい。あまり見かけない。
-
特徴
- RAdamとLookaheadを組み合わせたRangerが滑らかな収束を提供し、ExponentialLRが学習率を指数関数的に減少させる。
-
メリット
- 特に学習初期の不安定性を抑えつつ、後半での収束をスムーズにする、らしい。
schedule_free
「全ての学習率スケジューリングを過去にするOptimizer」で紹介されている彗星の如く登場した期待のオプティマイザ。
- warmup、learning rate scheduler、訓練終端時刻の指定、全て不要です。
- 安定かつ高速に収束します。多くの場合でAdamやAdamWより強いです。
詳しくは記事を参照してください。
特にこれで論文を書いたりするわけでもないので、新規に網羅的な性能実験などはおこなっていません。つまり、皆さんにとっては依然として「どこの馬の骨ともわからないoptimizer」の類ではあるわけですが、それをあなたにとっての新しい「これ使っときゃOK」にするかどうかは、あなたの好奇心次第です。
初期試行には鉄板の「Adam + CosineAnnealingLR」、一発逆転には「SGD + StepLR」、学習が不安定な場合には「Ranger + ExponentialLR」といった形です。個人的にはschedule_freeに期待を寄せています(が、まだ挑戦してません)。
PyTorch Metric Learning
PyTorch Metric Learningは、マイニングやトリプレットロスを用いた学習を簡単にするためのライブラリです。
わたしは多用するのですが、他であまり見かけないです。コードがスッキリしてとても良いです。
- Contrastive LossやTriplet Lossを楽に使える。
- ハードネガティブマイニング機能あり。(頑強なモデルがほしいなら)
- マイナーとか便利。
- モジュールが豊富で、なおかつドキュメントが充実してて扱いやすい。
実装例
では早速(やっと?)学習用コードを実装しましょう!
以下はEfficientNetV2をバックボーンとしTriplet Lossを使用した学習コードです。
このコードはしっかり見てほしいので、アコーディオン表記やGitHubのコード表記をわざと避けてます。
"""siamese_network_training.py.
Summary:
このスクリプトは、PyTorchを使用してSiamese Networkを学習するためのコードです。
EfficientNetV2をバックボーンに採用し、損失関数としてTriplet Margin Lossを使用しています。
距離計量にはコサイン類似度を採用しています。
主な特徴:
- ハイパーパラメータを自由に設定可能(例: バッチサイズ、埋め込み次元、学習率など)。
- TensorBoardとの統合により、学習の進捗を可視化可能。
- バリデーション結果に基づいて、モデルを保存する仕組みを実装。
- PyTorch Metric LearningのDatasets機能を活用した簡潔なデータローダー設定。
Example:
1. `data_dir`にデータセットのパスを指定してください。
2. スクリプトを実行し、TensorBoardで進捗を確認してください(`tensorboard --logdir=runs`を使用)。
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import os
import torch
import torch.nn as nn
from pytorch_metric_learning import distances, losses, samplers
from timm import create_model
from torch.utils.data import DataLoader, random_split
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torchvision.datasets import ImageFolder
# ハイパーパラメータの設定
embedding_size = 512 # 埋め込みベクトルの次元数
batch_size = 32 # バッチサイズ
sampler_m = 4 # クラスごとにサンプリングする画像数
data_dir = "path/to/data" # データセットのディレクトリ
lr = 1e-4 # 学習率
weight_decay = 1e-5 # 正則化の強さ
eps = 1e-8 # AdamWのepsilon
T_max = 50 # 学習率スケジューラのサイクル長
eta_min = 1e-6 # 学習率の最小値
mean_value = [0.485, 0.456, 0.406] # 正規化の平均値 (EfficientNetV2用)
std_value = [0.229, 0.224, 0.225] # 正規化の標準偏差
model_save_dir = "saved_models" # モデル保存ディレクトリ
log_dir = "runs" # TensorBoardのログディレクトリ
num_epochs = 100 # 学習エポック数
margin = 0.1 # TripletMarginLossのマージン値
os.makedirs(model_save_dir, exist_ok=True)
os.makedirs(log_dir, exist_ok=True)
# TensorBoardのSummaryWriterを初期化
writer = SummaryWriter(log_dir=log_dir)
# データ変換の設定
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5), # 水平方向の反転
transforms.RandomRotation(degrees=15), # ランダムな回転
transforms.RandomResizedCrop(size=(224, 224), scale=(0.8, 1.0), ratio=(0.75, 1.33)), # ランダムなトリミング
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=mean_value, std=std_value),
])
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=mean_value, std=std_value),
])
# データセットの準備
train_dataset = ImageFolder(
root=data_dir,
transform=train_transform
)
# バリデーションとテストの分割
val_size = int(0.2 * len(train_dataset))
test_size = len(train_dataset) - val_size
val_dataset, test_dataset = random_split(train_dataset, [val_size, test_size])
# サンプラーの設定(トレーニングデータにのみ適用)
sampler = samplers.MPerClassSampler([label for _, label in train_dataset.samples], m=sampler_m, batch_size=batch_size)
# データローダーの準備
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, sampler=sampler, drop_last=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# Siamese Networkの定義
class SiameseNetwork(nn.Module):
def __init__(self, embedding_dim=embedding_size):
super(SiameseNetwork, self).__init__()
# EfficientNetV2をバックボーンとして使用(timmからインポート)
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=True, num_classes=0)
num_features = self.backbone.num_features # バックボーンの特徴次元数を取得
# 埋め込みサイズを指定して全結合層を追加
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.embedder(self.backbone(x))
# モデルの初期化
model = SiameseNetwork(embedding_dim=embedding_size)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# オプティマイザの設定
optimizer = torch.optim.AdamW(
model.parameters(),
lr=lr,
weight_decay=weight_decay,
eps=eps
)
# スケジューラの設定
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=T_max,
eta_min=eta_min
)
# 損失関数の設定
loss_fn = losses.TripletMarginLoss(
margin=margin,
distance=distances.CosineSimilarity(),
swap=False
)
# 学習ステップの例
best_loss = float('inf') # 最小の損失を追跡
for epoch in range(1, num_epochs + 1):
model.train()
epoch_loss = 0.0
for batch in train_dataloader:
optimizer.zero_grad()
inputs, labels = batch
inputs = inputs.to(device)
embeddings = model(inputs)
loss = loss_fn(embeddings, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
scheduler.step()
epoch_loss /= len(train_dataloader) # エポックあたりの平均損失
print(f"Epoch {epoch}, Loss: {epoch_loss:.4f}")
# TensorBoardへの書き込み
writer.add_scalar('Loss/train', epoch_loss, epoch)
# モデル保存の条件
if epoch_loss < best_loss:
best_loss = epoch_loss
model_path = os.path.join(model_save_dir, f"model_epoch{epoch}_loss{epoch_loss:.4f}.pth")
torch.save(model.state_dict(), model_path)
print(f"Model saved to {model_path}")
writer.close()
いかがでしょうか?思ったより短いコードだったのではないでしょうか?
転移学習のため、最終層を削ってゴニョゴニョしてる以外は、MNISTと変わらなかったんじゃないでしょうか?
AdamW + CosineAnnealingLRの組み合わせやTripletMarginLossの採用はわたしの趣味です。
tf_efficientnetv2_b0.in1kはわたしの中で実績があるので採用しました。グラボメモリに余裕のある方(お金持ち)はB0でなくSやMを選ぶと精度が上がります[5]。
検証
10クラス分のフォルダを用意し、それぞれに50枚程度の顔画像をセットし、siamese_network_training.pyを10エポック動作させmodel_epoch8_loss0.0010.pthを得ました。ファイル名にepoch8とあるのは、8エポック目以降にロスが減少しなかったためです。

ちなみに、如何に1対1認証用とはいえ、10クラス、各50枚程度の学習では実用に耐えません。が、これは「挑戦」なのでよしとしましょう。(してください…)
検証コード①
学習が終わったら検証をします。検証には様々な手法があるのですが、それをつぶさに解説・実装してもあまり意味がないため、最初に単純な画像比較、次に代表的なROC曲線プロットとAUCスコア算出を行います。
まずは画像比較です。
単純な画像比較
"""siamese_inference.py.
Summary:
このスクリプトは、学習済みのSiamese Networkモデルを使用して2つの画像間の類似度を計算します。
主な機能:
- 学習済みモデルのロード
- 画像の前処理
- 特徴ベクトルの抽出
- コサイン類似度の計算
Example:
python siamese_inference.py --model_path path/to/saved_model.pth --img1 path/to/image1.png --img2 path/to/image2.png
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm import create_model
from torchvision import transforms
from PIL import Image
import argparse
# Siamese Networkの定義
class SiameseNetwork(nn.Module):
def __init__(self, embedding_dim=512):
super(SiameseNetwork, self).__init__()
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=False, num_classes=0)
num_features = self.backbone.num_features
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.embedder(self.backbone(x))
def load_model(model_path, embedding_dim=512):
"""学習済みモデルをロードします。
Args:
model_path (str): モデルファイルのパス
embedding_dim (int): 埋め込みベクトルの次元数
Returns:
SiameseNetwork: ロードされたモデル
"""
model = SiameseNetwork(embedding_dim)
model.load_state_dict(torch.load(model_path, map_location="cpu"))
model.eval()
return model
def preprocess_image(image_path):
"""画像を前処理します。
Args:
image_path (str): 画像ファイルのパス
Returns:
torch.Tensor: 前処理済みの画像テンソル
"""
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
img = Image.open(image_path).convert("RGB")
return transform(img).unsqueeze(0) # バッチ次元を追加
def compute_similarity(model, img1_path, img2_path):
"""2つの画像間の類似度を計算します。
Args:
model (SiameseNetwork): Siamese Networkモデル
img1_path (str): 1枚目の画像のパス
img2_path (str): 2枚目の画像のパス
Returns:
float: コサイン類似度
"""
img1_tensor = preprocess_image(img1_path)
img2_tensor = preprocess_image(img2_path)
with torch.no_grad():
embedding1 = model(img1_tensor)
embedding2 = model(img2_tensor)
similarity = F.cosine_similarity(embedding1, embedding2).item()
return similarity
def main():
# 引数を解析
parser = argparse.ArgumentParser(description="Siamese Networkを用いた画像間類似度計算")
parser.add_argument("--model_path", type=str, required=True, help="学習済みモデルのパス")
parser.add_argument("--img1", type=str, required=True, help="1枚目の画像のパス")
parser.add_argument("--img2", type=str, required=True, help="2枚目の画像のパス")
args = parser.parse_args()
# モデルのロード
print("モデルをロード中...")
model = load_model(args.model_path)
# 類似度の計算
print("類似度を計算中...")
similarity = compute_similarity(model, args.img1, args.img2)
print(f"画像間の類似度: {similarity:.4f}")
if __name__ == "__main__":
main()
検証結果
上記の画像で学習した後、以下の学習に使っていない画像で類似度を計算しました。

(pytorch-metric-learning) user@user:~/bin/pytorch-metric-learning$ python siamese_inference.py --model_path /home/user/bin/pytorch-metric-learning/saved_models/model_epoch8_loss0.0010.pth --img1 /home/user/bin/pytorch-metric-learning/otameshi_data/つじかりん/つじかりん_wplw.jpeg..png.png.png_0_align_resize_refined.png --img2 /home/user/bin/pytorch-metric-learning/otameshi_data/つじかりん/つじかりん.png
モデルをロード中...
類似度を計算中...
画像間の類似度: 0.9428
類似度は0.9428となり、本人であることが強く示唆されました。
検証コード②
それでは既存のクラスだけではなく、未知のクラスへの汎用性はどうでしょうか?
検証のために、**学習では用いなかった20クラス分(未知の20人)**のフォルダを用意し、それぞれに50枚程度の顔画像をセットしました。
で、ここでも注意点なのですが、1対1モードの場合と1対多モードでは検証コードが異なります。先に言ってしまうと、1対1モードで学習されたモデルに1対多モードの検証コードを適用するのは意味がないどころか有害です。精度が悪く出てしまいますから。
でも練習なので、ここでは両方の検証コードを作り、結果を見てみます。
aoc_plot_siamese_1-N.pyというAUCスコアとROC曲線をプロットするコードを書いて検証します。1対多モードの検証コードです。
1対多モードのROC曲線検証コード
"""aoc_plot_siamese_1-N.py.
Summary:
このスクリプトは、学習済みのSiamese Networkモデルを用いて
ROC曲線(AOC曲線)をプロットするためのコードです。
このスクリプトは1対1モードではなく、1対Nモードの精度を検証します。
1対1モードで学習されたモデルを評価した場合、一般的に精度は低く出力されます。
主な機能:
- 検証用データセットから埋め込みベクトルを生成。
- 埋め込みベクトル間のコサイン類似度を計算。
- ROC曲線を描画し、AUCスコアを算出。
- プロット画像をカレントディレクトリに保存。
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from sklearn.metrics import roc_auc_score, roc_curve
from timm import create_model
from torchvision import datasets, transforms
from tqdm import tqdm
# SiameseNetworkクラスの定義
class SiameseNetwork(nn.Module):
"""
Siamese Networkのクラス定義。
EfficientNetV2をバックボーンとして使用。
Args:
embedding_dim (int): 埋め込みベクトルの次元数。
"""
def __init__(self, embedding_dim=512):
super(SiameseNetwork, self).__init__()
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=True, num_classes=0)
num_features = self.backbone.num_features
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.embedder(self.backbone(x))
# 学習済みモデルの読み込み
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_path = "/home/user/bin/pytorch-metric-learning/saved_models/model_epoch8_loss0.0010.pth"
model = SiameseNetwork(embedding_dim=512) # 学習時と同じモデル構造を再現
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval().to(device)
# 検証用データのパス
test_data_dir = "/home/user/bin/pytorch-metric-learning/otameshi_kensho/"
# 検証用データの変換
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# データセットの作成
test_dataset = datasets.ImageFolder(root=test_data_dir, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
def calculate_similarity(embedding1, embedding2):
"""
埋め込みベクトル間のコサイン類似度を計算する。
Args:
embedding1 (torch.Tensor): 埋め込みベクトル1。
embedding2 (torch.Tensor): 埋め込みベクトル2。
Returns:
float: コサイン類似度。
"""
return torch.nn.functional.cosine_similarity(embedding1, embedding2).item()
def compute_embeddings(loader, model):
"""
データローダーを用いて埋め込みベクトルを計算。
Args:
loader (torch.utils.data.DataLoader): データローダー。
model (torch.nn.Module): 学習済みSiameseモデル。
Returns:
dict: クラスごとの埋め込みベクトルの辞書。
"""
embeddings = {}
for img, label in tqdm(loader, desc="Computing Embeddings"):
with torch.no_grad():
img = img.to(device)
embedding = model(img)
embeddings[label.item()] = embeddings.get(label.item(), []) + [embedding]
return embeddings
def calculate_similarities_and_labels(embeddings):
"""
クラスごとの埋め込みベクトルを用いて類似度とラベルを計算。
Args:
embeddings (dict): クラスごとの埋め込みベクトルの辞書。
Returns:
tuple: 類似度リスト、ラベルリスト。
"""
similarities = []
labels = []
class_keys = list(embeddings.keys())
for i, class_label_1 in enumerate(class_keys):
for embedding1 in embeddings[class_label_1]:
# 同じクラスとの比較(ラベル=1)
for embedding2 in embeddings[class_label_1]:
if not torch.equal(embedding1, embedding2): # 同じ画像はスキップ
sim = calculate_similarity(embedding1, embedding2)
similarities.append(sim)
labels.append(1) # 同じクラスはラベル1
# 異なるクラスとの比較(ラベル=0)
for j, class_label_2 in enumerate(class_keys):
if i != j: # 異なるクラスのみ
for embedding2 in embeddings[class_label_2]:
sim = calculate_similarity(embedding1, embedding2)
similarities.append(sim)
labels.append(0) # 異なるクラスはラベル0
return similarities, labels
def plot_roc_curve(similarities, labels, output_path="roc_curve.png"):
"""
ROC曲線をプロットし、画像として保存する。
Args:
similarities (list): 類似度リスト。
labels (list): ラベルリスト。
output_path (str): プロット画像の保存パス。
"""
fpr, tpr, thresholds = roc_curve(labels, similarities)
auc = roc_auc_score(labels, similarities)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f"AUC = {auc:.4f}")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend()
plt.grid()
plt.savefig(output_path) # 画像を保存
plt.show()
if __name__ == "__main__":
# 埋め込みベクトルの計算
embeddings = compute_embeddings(test_loader, model)
# 類似度とラベルの計算
similarities, labels = calculate_similarities_and_labels(embeddings)
# ROC曲線のプロットと保存
plot_roc_curve(similarities, labels, output_path="roc_curve.png")
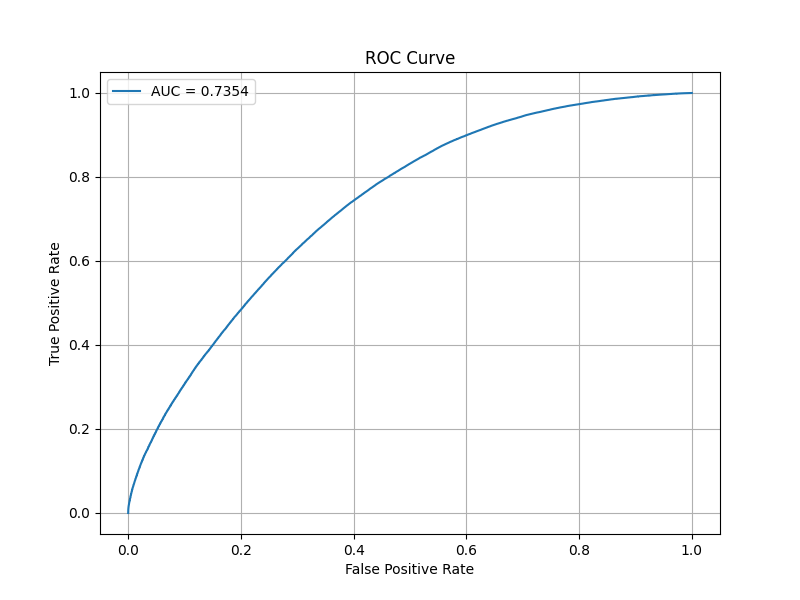
さすがに10クラスしか学習していない学習済みモデルでは、未知の20クラスに対してまともな精度は出せないですね。
検証コード③
とはいえ、今のは1対多モード用のコードでした。次は1対1モード用のROC曲線作成コード(aoc_plot_siamese_1-1.py)を用意して実行してみます。
1対多モードのROC曲線検証コード
"""aoc_plot_siamese_1-1.py.
Summary:
このスクリプトは、学習済みのSiamese Networkモデルを用いて
1対1モードにおけるROC曲線(AOC曲線)をプロットするためのコードです。
特定の登録者(テンプレート)と他の画像との類似度を計算し、
登録者本人のデータ(Positive)と他人のデータ(Negative)を区別する能力を評価します。
1対Nモードと異なり、特定のクラスを基準としてROC曲線とAUCスコアを算出します。
主な機能:
- 検証用データセットから埋め込みベクトルを生成。
- 登録者(テンプレート)と他の画像の間でコサイン類似度を計算。
- ROC曲線を描画し、AUCスコアを算出。
- プロット画像をカレントディレクトリに保存。
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from sklearn.metrics import roc_auc_score, roc_curve
from timm import create_model
from torchvision import datasets, transforms
from tqdm import tqdm
# SiameseNetworkクラスの定義
class SiameseNetwork(nn.Module):
"""
Siamese Networkのクラス定義。
EfficientNetV2をバックボーンとして使用。
Args:
embedding_dim (int): 埋め込みベクトルの次元数。
"""
def __init__(self, embedding_dim=512):
super(SiameseNetwork, self).__init__()
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=True, num_classes=0)
num_features = self.backbone.num_features
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.embedder(self.backbone(x))
# 学習済みモデルの読み込み
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_path = "/home/user/bin/pytorch-metric-learning/model_epoch8_loss0.0010_2024年12月14日.pth"
model = SiameseNetwork(embedding_dim=512) # 学習時と同じモデル構造を再現
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval().to(device)
# 検証用データのパス
test_data_dir = "/home/user/bin/pytorch-metric-learning/otameshi_kensho/"
# 検証用データの変換
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# データセットの作成
test_dataset = datasets.ImageFolder(root=test_data_dir, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
def calculate_similarity(embedding1, embedding2):
"""
埋め込みベクトル間のコサイン類似度を計算。
Args:
embedding1 (torch.Tensor): 埋め込みベクトル1。
embedding2 (torch.Tensor): 埋め込みベクトル2。
Returns:
float: コサイン類似度。
"""
return torch.nn.functional.cosine_similarity(embedding1, embedding2).item()
def compute_embeddings(loader, model):
"""
データローダーを用いて埋め込みベクトルを計算。
Args:
loader (torch.utils.data.DataLoader): データローダー。
model (torch.nn.Module): 学習済みSiameseモデル。
Returns:
dict: クラスごとの埋め込みベクトルの辞書。
"""
embeddings = {}
for img, label in tqdm(loader, desc="Computing Embeddings"):
with torch.no_grad():
img = img.to(device)
embedding = model(img)
embeddings[label.item()] = embeddings.get(label.item(), []) + [embedding]
return embeddings
def evaluate_one_to_one(embeddings, target_class):
"""
1対1モードに基づき、特定のクラスとのROC曲線を評価。
Args:
embeddings (dict): クラスごとの埋め込みベクトルの辞書。
target_class (int): 評価対象クラス(登録者)のラベル。
Returns:
tuple: 類似度リスト、ラベルリスト。
"""
similarities = []
labels = []
target_embeddings = embeddings[target_class]
# 登録者 vs 本人(Positive: 1)
for embedding in target_embeddings:
for other_embedding in target_embeddings:
if not torch.equal(embedding, other_embedding): # 同じ画像はスキップ
sim = calculate_similarity(embedding, other_embedding)
similarities.append(sim)
labels.append(1) # 本人認証(Positive)
# 登録者 vs 他人(Negative: 0)
for other_class, other_embeddings in embeddings.items():
if other_class != target_class:
for other_embedding in other_embeddings:
for target_embedding in target_embeddings:
sim = calculate_similarity(target_embedding, other_embedding)
similarities.append(sim)
labels.append(0) # 他人認証(Negative)
return similarities, labels
def plot_roc_curve(similarities, labels, output_path="roc_curve_1to1.png"):
"""
ROC曲線をプロットし、画像として保存する。
Args:
similarities (list): 類似度リスト。
labels (list): ラベルリスト。
output_path (str): プロット画像の保存パス。
"""
fpr, tpr, thresholds = roc_curve(labels, similarities)
auc = roc_auc_score(labels, similarities)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f"AUC = {auc:.4f}")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend()
plt.grid()
plt.savefig(output_path) # 画像を保存
plt.show()
if __name__ == "__main__":
# 埋め込みベクトルの計算
embeddings = compute_embeddings(test_loader, model)
# 評価対象クラス(例: 最初のクラス)
target_class = 0 # フォルダ構造によるクラスID
# ROC曲線用データの計算
similarities, labels = evaluate_one_to_one(embeddings, target_class)
# ROC曲線のプロットと保存
plot_roc_curve(similarities, labels, output_path="roc_curve_1to1.png")
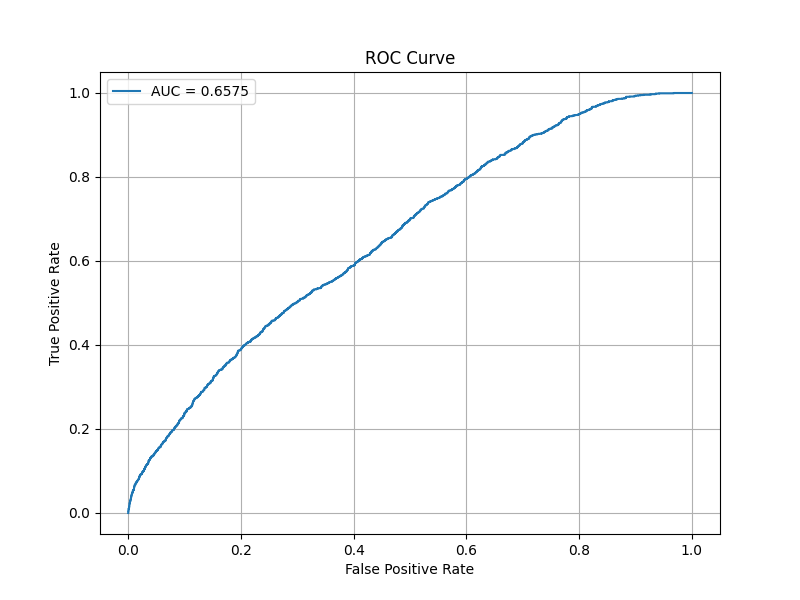
orz...あれれれ?
さっきより悪い結果が出ました。
まぁ、10クラス(各クラス50枚程度の顔画像ファイル)で10エポックしか学習していないわけですからこんなものです。まともな結果を出したければ1000クラス以上(各クラス100枚以上の顔画像ファイル)がどうしたって必要です。
とはいえ、さすがに悔しくなりました。
現在、2000クラスに対して学習をさせているところです。
…が、記事作成時点で1エポックしか終わってませんでした。先は長そうです。
追記:
↓ イマココ
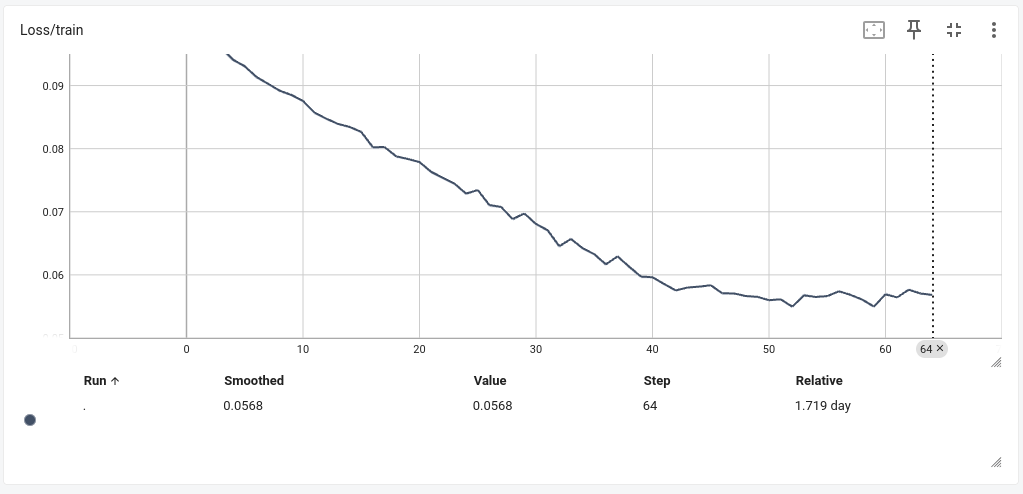
Model saved to saved_models/model_epoch52_loss0.0549.pth
2000クラス52エポック時点の学習済みモデルにて、未知の23クラス(各20〜30枚程度)に対して1対1モードの検証を行いました。
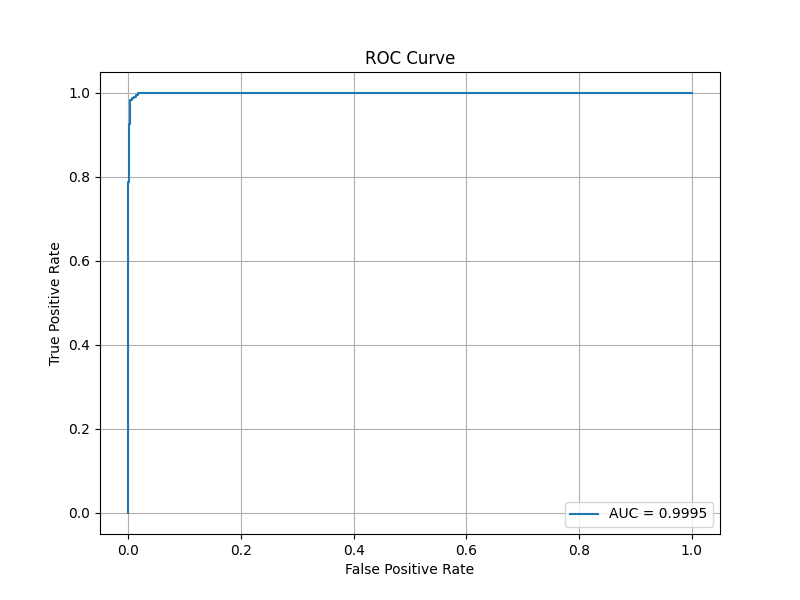
全く未知の人物ペアに対し、非常に高い精度を出しました!これは未知データへの汎化性能が優れていることを表しています。
…。
ちょっと出来すぎてますね。未知データセットで検証したのでオーバーフィッティングは起こしてないはずですが。
予定していませんでしたが、他の検証もやってみましょう🤔
ROC曲線は全体的な性能を評価します。なので次はPR曲線をプロットしてみたいとおもいます。未知データセットに不均衡はないのですが、ここでは1対1用の学習済みモデルの性能評価なので。
コードは以下のとおりです。
1対多モードのPR曲線検証コード
"""pr_curve_plot_siamese_1-1.py.
Summary:
このスクリプトは、学習済みのSiamese Networkモデルを用いて
1対1モードにおけるPR曲線をプロットするためのコードです。
特定の登録者(テンプレート)と他の画像との類似度を計算し、
登録者本人のデータ(Positive)と他人のデータ(Negative)を区別する能力を評価します。
主な機能:
- 検証用データセットから埋め込みベクトルを生成。
- 登録者(テンプレート)と他の画像の間でコサイン類似度を計算。
- PR曲線を描画し、AP(Average Precision)スコアを算出。
- プロット画像をカレントディレクトリに保存。
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from sklearn.metrics import average_precision_score, precision_recall_curve
from timm import create_model
from torchvision import datasets, transforms
from tqdm import tqdm
class SiameseNetwork(nn.Module):
"""Siamese Networkのクラス定義."""
def __init__(self, embedding_dim=512):
super(SiameseNetwork, self).__init__()
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=True, num_classes=0)
num_features = self.backbone.num_features
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.embedder(self.backbone(x))
# 学習済みモデルの読み込み
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_path = "/home/user/bin/pytorch-metric-learning/saved_models/model_epoch52_loss0.0549.pth"
model = SiameseNetwork(embedding_dim=512)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval().to(device)
# 検証用データの設定
test_data_dir = "/home/user/bin/pytorch-metric-learning/otameshi_kensho/"
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
test_dataset = datasets.ImageFolder(root=test_data_dir, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
def calculate_similarity(embedding1, embedding2):
"""埋め込みベクトル間のコサイン類似度を計算."""
return torch.nn.functional.cosine_similarity(embedding1, embedding2).item()
def compute_embeddings(loader, model):
"""データローダーを用いて埋め込みベクトルを計算."""
embeddings = {}
for img, label in tqdm(loader, desc="Computing Embeddings"):
with torch.no_grad():
img = img.to(device)
embedding = model(img)
embeddings[label.item()] = embeddings.get(label.item(), []) + [embedding]
return embeddings
def evaluate_one_to_one_pr(embeddings, target_class):
"""1対1モードに基づき、PR曲線データを生成."""
similarities = []
labels = []
target_embeddings = embeddings[target_class]
for embedding in target_embeddings:
# Positive: 登録者 vs 本人
for other_embedding in target_embeddings:
if not torch.equal(embedding, other_embedding):
sim = calculate_similarity(embedding, other_embedding)
similarities.append(sim)
labels.append(1)
# Negative: 登録者 vs 他人
for other_class, other_embeddings in embeddings.items():
if other_class != target_class:
for other_embedding in other_embeddings:
sim = calculate_similarity(embedding, other_embedding)
similarities.append(sim)
labels.append(0)
return similarities, labels
def plot_pr_curve(similarities, labels, output_path="pr_curve_1to1.png"):
"""PR曲線をプロットし、画像として保存."""
precision, recall, _ = precision_recall_curve(labels, similarities)
ap_score = average_precision_score(labels, similarities)
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, label=f"AP = {ap_score:.4f}")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.legend()
plt.grid()
plt.savefig(output_path)
plt.show()
if __name__ == "__main__":
# 埋め込みベクトルの計算
embeddings = compute_embeddings(test_loader, model)
# 評価対象クラス(例: クラスID 0)
target_class = 0
# PR曲線用データの計算
similarities, labels = evaluate_one_to_one_pr(embeddings, target_class)
# PR曲線のプロットと保存
plot_pr_curve(similarities, labels, output_path="pr_curve_1to1.png")
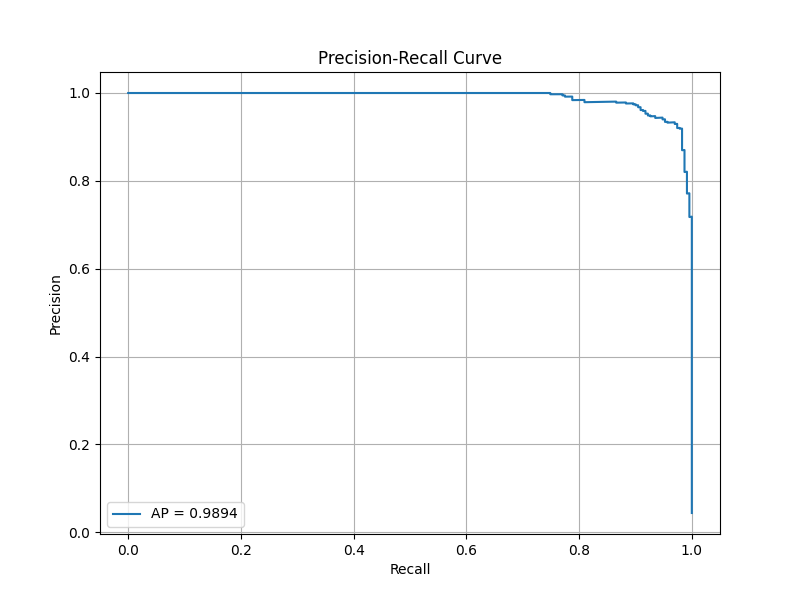
フム…。なかなかいいんじゃないでしょうか?未知データセットが今回23クラスだったので、若干右上がギザギザしていますが。
APスコアが0.9894なので、精度として問題ないかと。(
学習は現在進行形で進めてますし、より良い学習済みモデルが出来上がったら検証後に公開します。(JAPANESE FACE V1のように独立してリポジトリをたてると思います。)
追記:
↓ イマココ
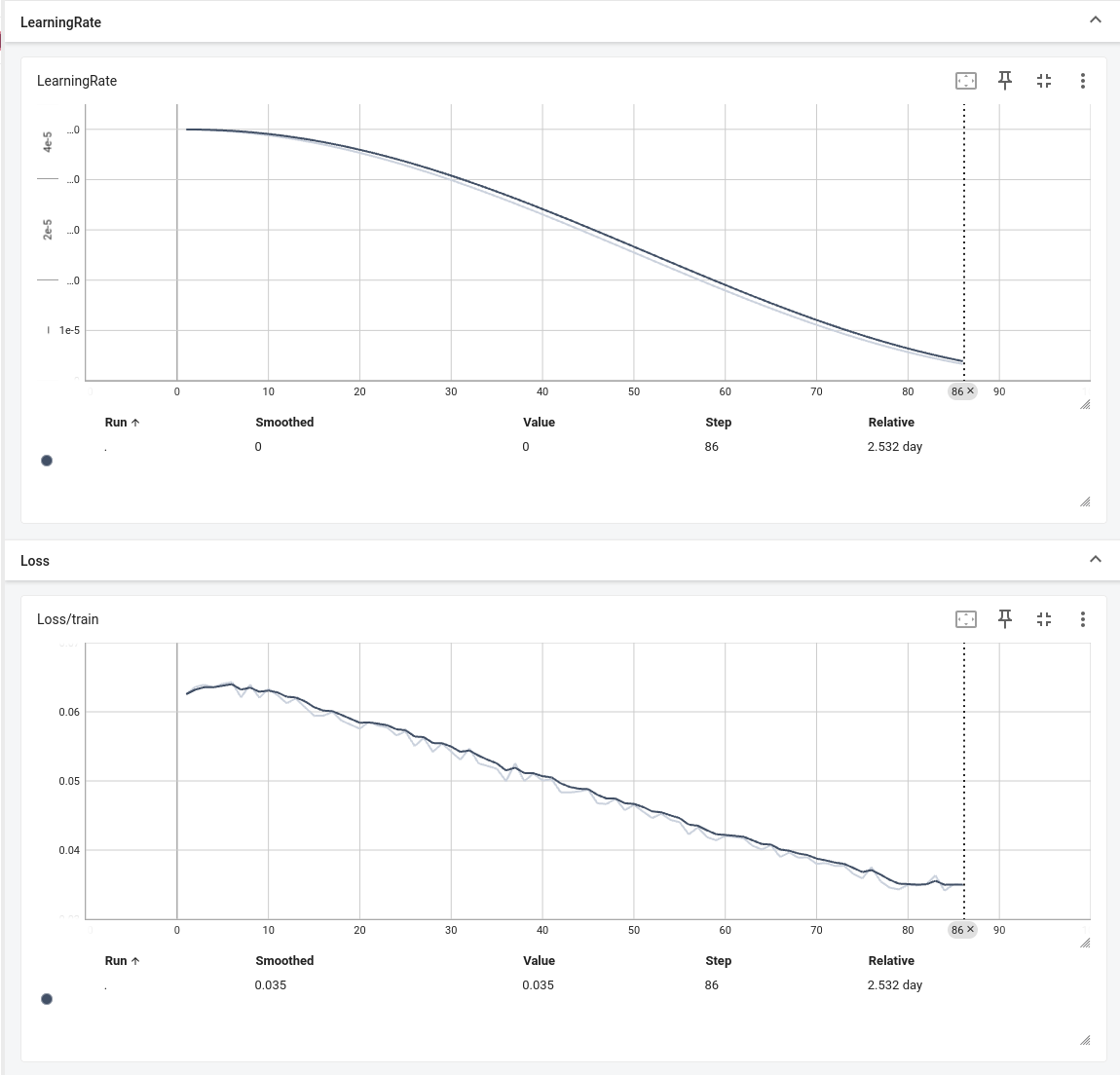
2日半、熟成させてロスが0.0341まで下りました。(saved_models/retrain_model_epoch84_loss0.0341.pth)
このモデルでのROC曲線、AUCスコア、PR曲線、APスコアを用いた評価を行います。
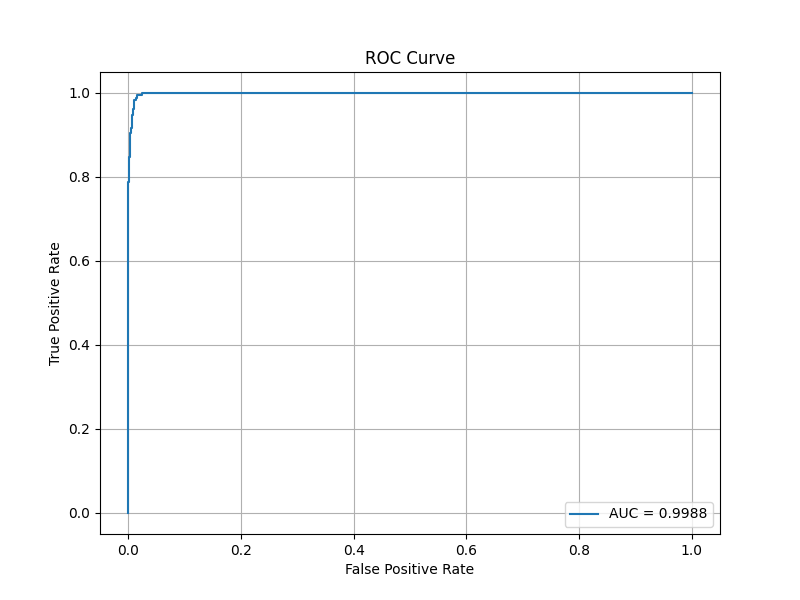
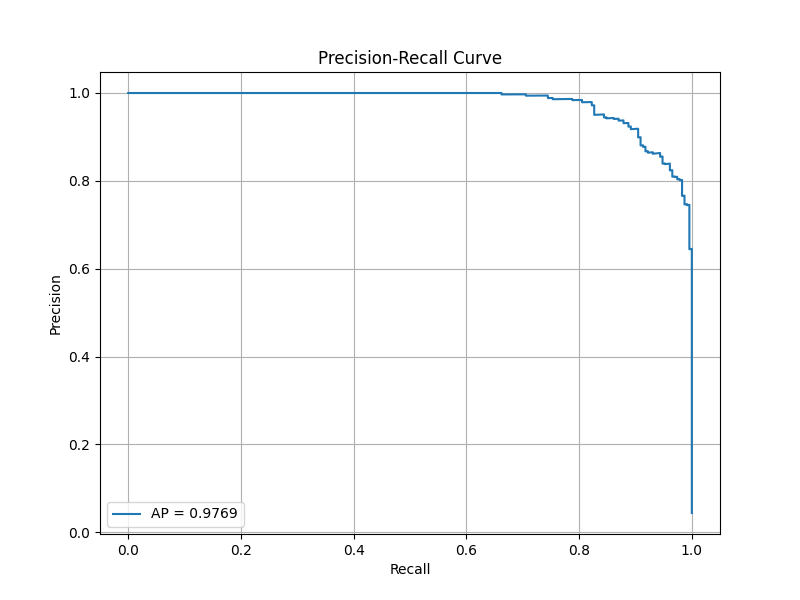
フム…、AUCスコアとAPスコアの両方が若干下がっていますね。過学習かもしれません。
この地点が過学習だと仮定して、だとするとこれまでの自動保存された学習済みモデルのなかにベストな学習済みモデルが存在するはずです。ちょっと探してみましょう。
学習済みモデルはすべてsaved_modelディレクトリにあります。これら全てを対象にAUCスコアとAPスコアを算出するコードを書いてみましょう。
すべての学習済みモデル: AUC、APスコア評価コード
"""calculate_auc_ap_for_all_models.py.
Summary:
このスクリプトは、学習済みのSiamese Networkモデルを用いて
1対1モード(Verificationタスク)におけるAUCスコアおよびAPスコアを算出し、
複数の学習済みモデルに対して評価を行うコードです。
特定の登録者(テンプレート)クラスを基準に、
同一クラス内の画像間類似度(Positive)および他クラス画像との類似度(Negative)を取得します。
これにより、入力画像が登録者本人か否かを判別する性能を評価できます。
主な機能:
- 検証用データセットから埋め込みベクトルを生成(ImageFolderを使用)
- 特定の登録者クラスを指定し、そのクラスをPositiveの基準として類似度を計算
- Positive(本人 vs 本人)およびNegative(本人 vs 他人)ペアを作成し、コサイン類似度を算出
- ROC AUCスコアおよびAverage Precision (AP)スコアを計算して評価
- 複数の学習済みモデル(.pth)ファイルを横断的に評価
Example:
1. `test_data_dir`に評価用データセットのパスを指定してください。
2. `target_class`に評価対象クラスIDを指定してください。
3. スクリプトを実行すると、全てのモデルファイルに対してAUCおよびAPスコアが出力されます。
License:
This script is licensed under the terms provided by yKesamaru, the original author.
"""
import glob
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.metrics import average_precision_score, roc_auc_score
from timm import create_model
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
class SiameseNetwork(nn.Module):
"""
Siamese Networkモデル定義クラス
EfficientNetV2をバックボーンとして使用し、
その出力特徴量を全結合層で圧縮して埋め込みベクトルを生成する。
Attributes:
backbone (nn.Module): EfficientNetV2のバックボーン
embedder (nn.Linear): 埋め込み用の全結合層
"""
def __init__(self, embedding_dim=512):
super(SiameseNetwork, self).__init__()
# EfficientNetV2をバックボーンとして使用
self.backbone = create_model('tf_efficientnetv2_b0.in1k', pretrained=True, num_classes=0)
num_features = self.backbone.num_features
self.embedder = nn.Linear(num_features, embedding_dim)
def forward(self, x):
# 入力画像xから特徴を抽出して埋め込みベクトルを返す
features = self.backbone(x)
embeddings = self.embedder(features)
return embeddings
def extract_embeddings(model, dataloader, device):
"""
テストデータからモデルの埋め込みベクトルを抽出する関数
Args:
model (nn.Module): 学習済みSiamese Networkモデル
dataloader (DataLoader): テストデータローダー
device (torch.device): デバイス(CPUまたはGPU)
Returns:
(dict):
クラスIDをキーとし、そのクラスの画像埋め込みを格納した辞書を返す。
形式: { class_id: [embedding_tensor, embedding_tensor, ...], ... }
"""
model.eval() # 評価モードへ
embeddings_dict = {} # クラスID毎に埋め込みを貯める辞書
with torch.no_grad():
for images, labels in tqdm(dataloader, desc="Extracting embeddings"): # 埋め込み抽出進捗バー
images = images.to(device) # 画像をデバイスへ移動
emb = model(images) # 埋め込み取得
# バッチ内のサンプルをクラスごとに格納
for e, l in zip(emb, labels):
class_id = l.item()
if class_id not in embeddings_dict:
embeddings_dict[class_id] = []
embeddings_dict[class_id].append(e.cpu()) # CPU上に保存
return embeddings_dict
def compute_auc_ap_one_to_one(embeddings_dict, target_class):
"""
1対1認証(Verification)タスクとしてAUCとAPを計算する関数
特定のクラス(target_class)を「登録者」とみなし、
- Positiveペア: target_class内の異なる画像間ペア
- Negativeペア: target_classの画像と他クラス画像間ペア
からコサイン類似度を算出し、AUCおよびAPを求める。
Args:
embeddings_dict (dict): { class_id: [embedding1, embedding2, ...] }形式の辞書
target_class (int): 評価対象のクラスID
Returns:
(float, float): (auc, ap)
auc: ROC AUCスコア
ap: Average Precisionスコア
"""
similarities = []
labels = []
# ターゲットクラスの埋め込みリスト取得
target_embeddings = embeddings_dict.get(target_class, [])
# ターゲットクラスが存在しない、または画像が少なすぎる場合は例外対応
if len(target_embeddings) < 2:
# 正常な評価ができないのでそのまま返す
return float('nan'), float('nan')
# Positiveペア作成(同クラス内で異なる画像同士)
# target_embeddings内の全組み合わせペアを生成する
for i in range(len(target_embeddings)):
for j in range(i + 1, len(target_embeddings)):
emb_i = target_embeddings[i].unsqueeze(0) # (1, D)
emb_j = target_embeddings[j].unsqueeze(0) # (1, D)
# コサイン類似度計算
sim = F.cosine_similarity(emb_i, emb_j).item()
similarities.append(sim)
labels.append(1) # Positive
# Negativeペア作成(target_classと他クラスのペア)
# 他クラスの埋め込みを総当たり
for cls_id, emb_list in embeddings_dict.items():
if cls_id == target_class:
continue
for e_target in target_embeddings:
for e_other in emb_list:
emb_t = e_target.unsqueeze(0)
emb_o = e_other.unsqueeze(0)
sim = F.cosine_similarity(emb_t, emb_o).item()
similarities.append(sim)
labels.append(0) # Negative
# numpy配列へ変換
y_true = torch.tensor(labels).numpy()
y_score = torch.tensor(similarities).numpy()
# AUCおよびAP計算
auc = roc_auc_score(y_true, y_score)
ap = average_precision_score(y_true, y_score)
return auc, ap
def evaluate_model(model_path, test_dataloader, device, target_class=0):
"""
単一モデルに対し、1対1認証評価用のAUCスコアとAPスコアを計算する関数
Args:
model_path (str): モデルファイルのパス(.pth)
test_dataloader (DataLoader): テストデータローダー
device (torch.device): デバイス情報
target_class (int): 評価対象のクラスID(登録者)
Returns:
(float, float): (auc, ap)
"""
# モデルインスタンス化
model = SiameseNetwork(embedding_dim=512)
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device) # デバイスへ移動
embeddings_dict = extract_embeddings(model, test_dataloader, device) # 埋め込み抽出
auc, ap = compute_auc_ap_one_to_one(embeddings_dict, target_class) # 1対1認証でのAUC, AP計算
return auc, ap
if __name__ == "__main__":
# デバイス設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# テスト用ディレクトリ(1対1認証を評価するデータセット)
test_data_dir = "/home/user/ドキュメント/Building_a_face_recognition_model_using_Siamese_Network/assets/otameshi_kensho/"
# テストデータ用の変換(学習時と同等)
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
test_transform = transforms.Compose([
transforms.Resize((224, 224)), # 画像を224x224にリサイズ
transforms.ToTensor(), # テンソル化
transforms.Normalize(mean=mean_value, std=std_value) # 正規化
]) # テスト用変換定義
# テストデータセットとローダー作成
test_dataset = datasets.ImageFolder(root=test_data_dir, transform=test_transform)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 評価対象のターゲットクラスを指定(0番目のクラス)
target_class = 0 # ターゲットクラスID
# 評価対象モデルが格納されているディレクトリ
model_dir = "/home/user/bin/pytorch-metric-learning/saved_models/"
model_paths = glob.glob(os.path.join(model_dir, "*.pth")) # pthファイルの全取得
# 各モデルに対して1対1認証のAUCとAPを計算・表示
for mp in model_paths:
auc_score, ap_score = evaluate_model(mp, test_dataloader, device, target_class) # 個別モデル評価
print(f"Model: {mp}, AUC: {auc_score:.4f}, AP: {ap_score:.4f}")
標準出力をスプレッドシートに貼り付けてグラフ化したものが以下になります。グラフが2つあるのは当初の学習と、一度学習が止まってしまったのでベストロスから再学習させたものがあるからです。
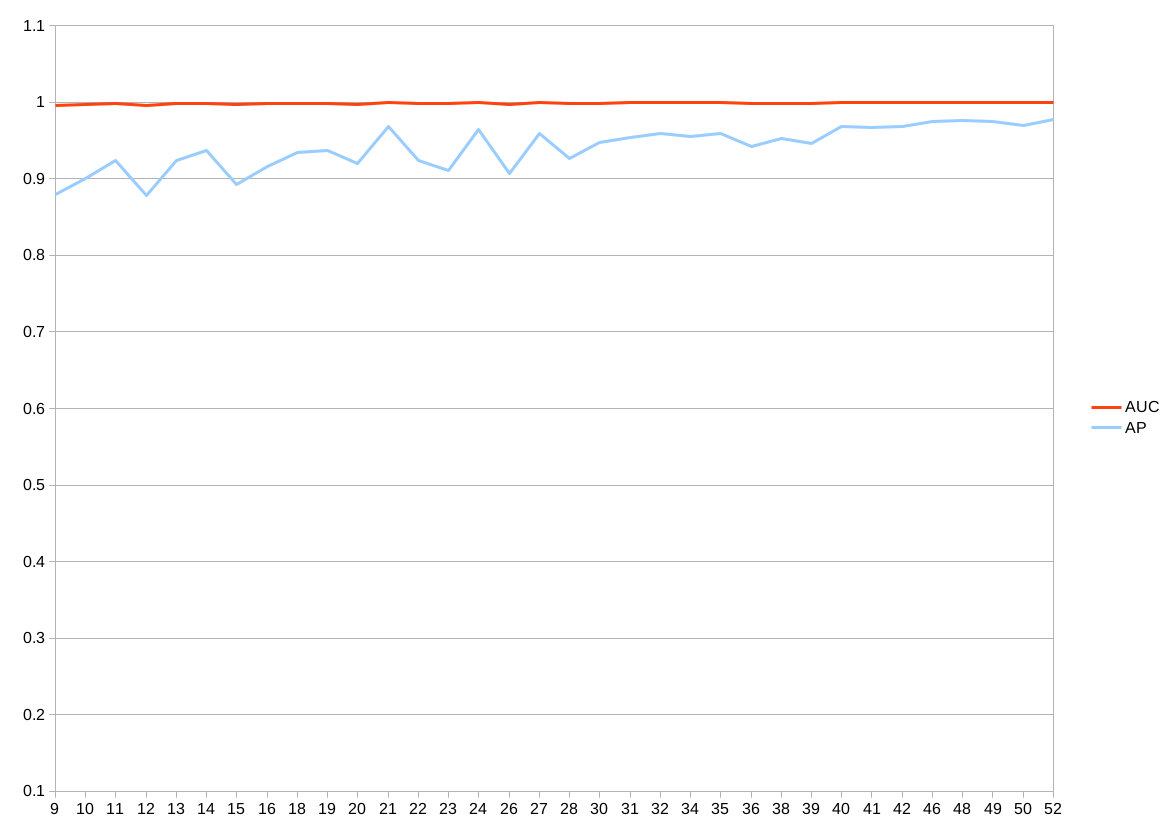
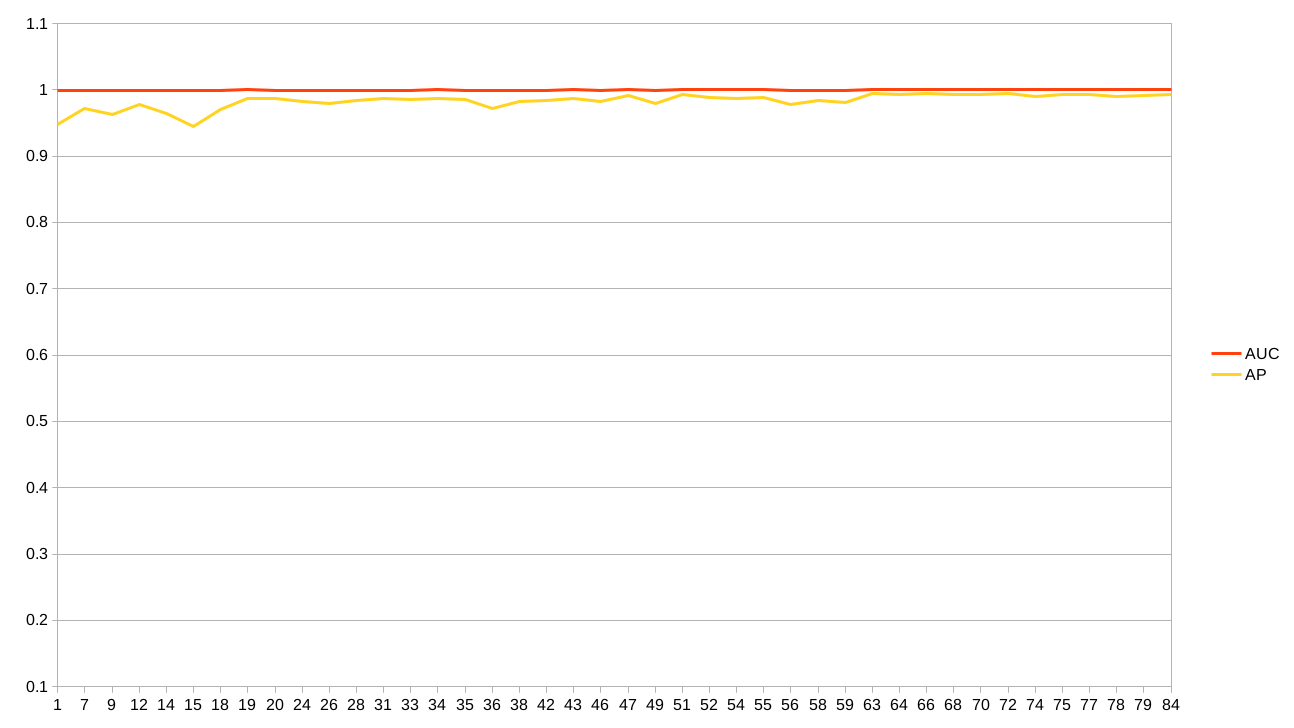
APスコアが揺れているのは検証用の各クラスが20枚程度しかないからかも。評価クラスを増やすか、全ペア総当りの評価コードを書いて実行するかの2通りです。どちらも用意しましたが、この記事の趣旨からどんどんずれていくので、この辺でやめておきます。。
さいごに
本記事は<記事投稿コンテスト「今年の最も大きなチャレンジ」>のために執筆しました。
わたしにとってもチャレンジ(2000クラスに対して学習)ですが、AI・機械学習を志すすべての人のチャレンジとなるように、学習コード・データセット・検証コードをセットにしました。
その中で、1対1モードがどういうものか、認証界隈の解説(認証のスコープなど)も簡単ですが加えました。
好奇心とGPUがあれば、あなた専用の学習モデルが作れちゃいます😀
個人開発でサービスを立ち上げて、キラキラな技術スタックを解説するようなのではなく、MNISTの次に挑戦できるものを作った感じです。需要はあるはずですが、地味ですね。リポジトリから前処理済みのデータセットもダウンロードできるのが売りです。これを用意するほうが大変でした💦
以上です。ありがとうございました。
おまけ
1対多モードの学習モデルはJAPANESE FACE V1として以下で配布してます。
使ってみてね⭐️

参考文献リスト
- 拙著記事
- 拙作リポジトリ
- その他
Discussion