インタビュー形式の動画から顔画像データを抽出する方法



はじめに
追記:2024年11月18日
顔画像データセットを作成する際、一昔前まで一般的にクローリングによって作成されていたかと思います。
しかしこの方法だと様々な問題が山積します。
- データセットとしてのプライバシーや肖像権の問題
- 自撮り加工が多すぎる
- 関連した別人が混ざる
- 年齢差が大きすぎるデータが混ざる
- ぼやけている
これらを解決する方法として、インタビュー形式の動画から顔画像データを抽出する方法が存在します。
この記事では後者の「インタビューなどの動画から顔画像データを抽出する方法」について、FACE01[1]を使って行います。
[!NOTE]
なおこの記事で取り扱うサンプル動画は記事を作成するための例であって、このサンプルを使って顔学習モデルを作製しているわけではないことをおことわりします。

ホスト環境
$ inxi -Sxxx --filter
System:
Kernel: 6.8.0-47-generic x86_64 bits: 64 compiler: N/A Desktop: GNOME 42.9
tk: GTK 3.24.33 wm: gnome-shell dm: GDM3 42.0
Distro: Ubuntu 22.04.5 LTS (Jammy Jellyfish)
今回、YouTubeの巨人 阿部監督の試合後インタビュー【巨人×DeNA】【CSファイナル第5戦】をinterview.mp4として使用します。
FACE01はRTSP、HTTPなどの入力を使用できますが、今回はそこが主眼ではないので予めinterview.mp4として用意しました。
FACE01とは
FACE01はオープンソースの顔認識フレームワークです。
FACE01顔認識フレームワークは、RTSP・HTTP・USBなどの入力プロトコルから顔認識・画像処理をかんたんに行えます。
詳細なドキュメントと多くのエグザンプルコードの他に、初心者の方を対象にした「ステップ・バイ・ステップ」が付属するので、どんな方でもかんたんに顔認識に付随する処理を行えます。
また付属している顔学習モデル(JAPANESE FACE V1[2])は日本人専用として学習されており、フリーで使える顔学習モデル[3]としては、おそらく日本一の精度を誇ります。
日本人の顔認証に特化した学習モデルは、一般的な顔認証システムが抱える問題(若年日本人女性に対する偽陽性)を解決しました。
たとえば、一般的な学習モデルの場合、以下に示すような若年日本人女性の判別が難しい場合があります。
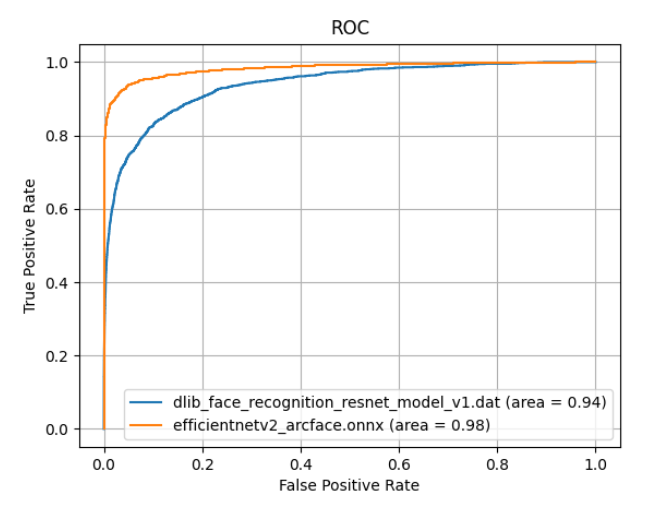
これに対し、新しく学習されたモデル「JAPANESE FACE」(下のグラフではefficientnetv2_arcface.onnx)では、精度を落とすことなく判別できていることが示されました。
若年日本人女性の顔画像に対して、DlibのAUCが0.94に対し、JAPANESE FACEは0.98を達成しています⭐️''。
くわしくは、「Dlib顔学習モデルの、若年日本人女性データセットにおける性能評価」からご覧いただけます。

この記事では「動画ファイル中の任意の人物の顔画像ファイルを、フレームごとに抽出・保存する」機能を使用します。
FACE01を使用する
FACE01をDOCKERで導入
下記に書いてあるとおりにDocker imageをプルします。
docker pull tokaikaoninsho/face01_gpu
ダウンロードしたイメージを確認します。(ここでは予めダウンロードしておいたDocker imageがリストされています。)
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tokaikaoninsho/face01_gpu 3.0.03_3 ce2952ad62d6 2 months ago 22.3GB
ドキュメントにあるように、GUIを使えるようにしておきます。
xhost +local:
この部分がよくわからない方は以下を参考にしてください。
DockerでGUIアプリケーションを開く基本的な押さえどころ
コンテナを起動する
ホストと共有するフォルダを指定しておきたいので、以下のようにしてコンテナを起動します。
docker run -it \
--gpus all -e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /path/to/host/folder:/path/to/container/folder \
<image id>
/home/user/ドキュメント/Face_Extraction/assets/ディレクトリにinterview.mp4としてテスト用動画を用意してあります。
今回はこの動画ファイルから顔画像ファイルを抽出したいので、このディレクトリを指定してコンテナを起動します。
docker run -it \
--gpus all -e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /home/user/ドキュメント/Face_Extraction/assets:/mnt/data \
ce2952ad62d6
コンテナを上記のように指定して起動すると、ホスト側の/home/user/ドキュメント/Face_Extraction/assetsディレクトリがコンテナ側の/mnt/dataディレクトリに接続されます。
(venv) user@user:~/ドキュメント/Face_Extraction$ docker run -it \
--gpus all -e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /home/user/ドキュメント/Face_Extraction/assets:/mnt/data \
ce2952ad62d6
==========
== CUDA ==
==========
CUDA Version 11.6.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the user and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
*************************
** DEPRECATION NOTICE! **
*************************
THIS IMAGE IS DEPRECATED and is scheduled for DELETION.
https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/support-policy.md
Python仮想環境をアクティベートする
docker@056e52013385:~/FACE01_DEV$ . bin/activate
ホストディレクトリが繋がっているか確認する
(FACE01_DEV) docker@056e52013385:~/FACE01_DEV$ ls /mnt/data
2024-10-23-16-34-21.png 2024-10-23-16-42-37.png eye-catch.png interview.mp4
/mnt/data/interview.mp4に対して、顔画像ファイル抽出処理をしていきます。
config.iniを調整する
FACE01では多様な使い方を想定してconfig.iniファイルを使って初期設定を行います。
config.ini編集のために、FACE01のDOCKERイメージにはgeditテキストエディタが付属します。vimも付属するので好きな方を選んで起動してください。
(FACE01_DEV) docker@a5f5d24d9fba:~/FACE01_DEV$ gedit config.ini
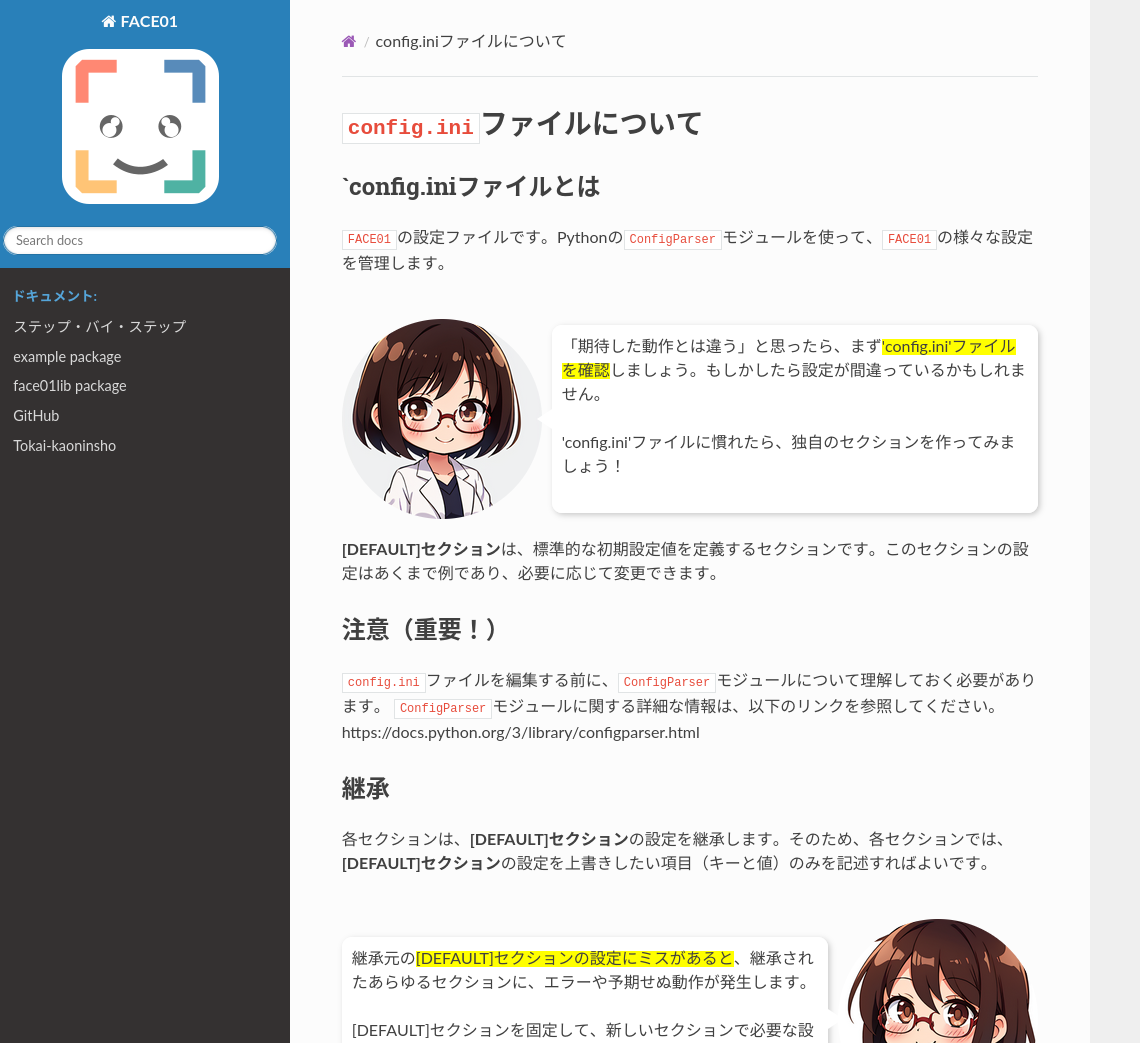
デフォルトで幾つかのセクションが用意されています。すべてのセクションは[DEFAULT]セクションを継承します。
新しいセクションを作成するには[DEFAULT]セクションから変更する部分だけを抽出して設定します。
くわしくはこちらをご参照ください。
今回は本格的な運用ではないため、予め用意されている[DISPLAY_GUI]セクションを直接編集しました。
追加として、[JAPANESE_FACE_V1_MODEL_GUI]の設定も載せます。これを使用する場合は以下のように入力してください。
(FACE01_DEV) docker@ea169daa7cbc:~/FACE01_DEV$ python example/display_GUI_window_JAPANESE_FACE_V1.py &
[DISPLAY_GUI]
# [DISPLAY_GUI] section is example for display window.
# [DISPLAY_GUI] section inherits from the [DEFAULT] section.
headless = False
deep_learning_model = 1
similar_percentage = 90
preset_face_images_jitters = 10
min_detection_confidence = 0.8
mode = cnn
use_pipe = False
same_time_recognize = 1
movie = interview.mp4
target_rectangle = True
show_overlay = True
show_percentage = True
show_name = True
frame_skip = 2
number_of_crops = 0
[JAPANESE_FACE_V1_MODEL_GUI]
headless = False
frame_skip = 10
movie = ../test/test6.mp4
deep_learning_model = 1
similar_percentage = 90.0
target_rectangle = True
draw_telop_and_logo = False
default_face_image_draw = False
show_overlay = False
alpha = 0.3
show_percentage = False
show_name = False
set_width = 1920
frequency_crop_image = 1
顔画像ファイルを設置する
顔画像ファイルを設置します。(224x224px)

これを~/FACE01_DEV/preset_face_images/ディレクトリにコピーします。
コピーする際パスワードを聞かれたらdockerと入力します。
(FACE01_DEV) docker@a5f5d24d9fba:~/FACE01_DEV$ ls /mnt/data
2024-10-23-16-34-21.png 2024-10-23-19-17-39.png eye-catch.png interview.mp4
2024-10-23-16-42-37.png 2024-10-23-20-32-42.png face_crop.py 阿部慎之助_default.png
(FACE01_DEV) docker@a5f5d24d9fba:~/FACE01_DEV$ cp /mnt/data/阿部慎之助_default.png ~/FACE01_DEV/preset_face_images/
cp: 通常ファイル '/home/docker/FACE01_DEV/preset_face_images/阿部慎之助_default.png' を作成できません: 許可がありません
(FACE01_DEV) docker@a5f5d24d9fba:~/FACE01_DEV$ sudo !!
sudo cp /mnt/data/阿部慎之助_default.png ~/FACE01_DEV/preset_face_images/
[sudo] docker のパスワード:
エグザンプルコードを動作させる
コードはexample/display_GUI_window.pyを使用します。
(FACE01_DEV) docker@b8ddca6a1b03:~/FACE01_DEV$ python ./example/display_GUI_window.py
実行すると以下のようなウィンドウが開き、処理が進んでいきます。

ホスト側に顔画像ファイルを移動する
コンテナからホストのディスクに顔クロップ画像をコピーしましょう。
(FACE01_DEV) docker@b8ddca6a1b03:~/FACE01_DEV$ mv ./output/*.png /mnt/data/output/
これによって、以下のように顔クロップ画像が収集できました。

あるいはexample/display_GUI_window_JAPANESE_FACE_V1.pyを使用する場合、最終行を以下のようにgeditで修正します。これは動画の処理が途中で終了するのを防ぐためです。
- main(exec_times=200)
+ main(exec_times=20000)
顔画像をアライメントする
ドキュメントのexample.aligned_crop_face moduleをご参照ください。


使用法
(FACE01_DEV) docker@ea169daa7cbc:~/FACE01_DEV$ python example/aligned_crop_face.py ../test
ソースコードはこちらです。
今回はDocker image内のexample/aligned_crop_face.pyを以下のように変更して使用しました。
- utils.align_and_resize_maintain_aspect_ratio(
- path,
- upper_limit_length=1024,
- padding=0.1,
- size=400
- )
+ utils.align_and_resize_maintain_aspect_ratio(
+ path,
+ upper_limit_length=1024,
+ padding=0.1,
+ size=400
+ )
おわりに
FACE01顔認識フレームワークを使用すると、dockerに抵抗ない方なら顔認識関連の処理がかんたんに行えます。
じつは大量の動画ファイルから顔画像をクロップして保存する作業があり、FACE01のドキュメントを見ながら作業を行いました。
とっかかりは面倒くさそうですけど、コンテナに入ってしまえば後は楽ちんでした。ぜひ皆様もつかってみてください。
最後までお読み頂きありがとうございました。
追記
2024年11月28日
一連のコマンドをまとめておきます。各コマンドをコピペするだけでインタビュー入力動画からアラインメントされた顔画像を抽出することが出来ます。
xhost +local:
docker run -it \
--gpus all -e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /home/terms/ドキュメント/FACE01_mnt_Folder:/home/docker/test \
1c63aae7b15d
. bin/activate
gedit config.ini &
--------------------------------------
[JAPANESE_FACE_V1_MODEL_GUI]
headless = False
frame_skip = 5
movie = ../test/test8.mp4
deep_learning_model = 1
similar_percentage = 90.0
target_rectangle = True
draw_telop_and_logo = False
default_face_image_draw = False
show_overlay = False
alpha = 0.3
show_percentage = False
show_name = False
set_width = 1920
frequency_crop_image = 1
--------------------------------------
gedit example/aligned_crop_face.py &
--------------------------------------
utils.align_and_resize_maintain_aspect_ratio(
path,
upper_limit_length=1024,
padding=0.1,
size=600
)
--------------------------------------
gedit example/display_GUI_window_JAPANESE_FACE_V1.py &
--------------------------------------
# tkinterウィンドウの作成
root = tk.Tk()
root.title('FACE01 example with JAPANESE_FACE_V1 model')
root.geometry('100x100')
--------------------------------------
python example/display_GUI_window_JAPANESE_FACE_V1.py && zenity --info --text="display_GUI: Done"
ls *.png | xargs -P 7 -I {} mogrify -resize 600x600! -unsharp 2x1+2+0 {} && zenity --info --text="mogrify: Done"
python example/aligned_crop_face.py ../test && zenity --info --text="Face_Crop: Done"
--------------------------------------
python example/display_GUI_window_JAPANESE_FACE_V1.py && mv output/*.png ../test && python example/aligned_crop_face.py ../test && zenity --info --text="Face_Crop: Done"
--------------------------------------
xhost -local:
Discussion