BigQuery初心者を脱出したい2(パーティション分割テーブル)
BigQuery初心者を脱出しようと記事を書いていきます。その2。
前の記事:
・BigQuery初心者を脱出したい1(テーブル作成~検索)
今回は費用を節約するためのパーティション分割テーブルの使い方について学んでいきます。
BigQueryの費用について(再掲)2021/8/7時点
・ストレージ利用料金
| オペレーション | 料金(東京リージョン) | 詳細 |
|---|---|---|
| アクティブ ストレージ | $0.023 per GB | 毎月 10 GB まで無料。 |
| 長期保存 | $0.016 per GB | 毎月 10 GB まで無料。 |
・分析料金
| オペレーション | 料金(東京リージョン) | 詳細 |
|---|---|---|
| クエリ(オンデマンド) | $6.00 per TB | 毎月 1 TB まで無料です。 |
パーティション分割テーブルについて
パーティション分割テーブルについては以下のGoogle提供のドキュメントを参考にしていく。
そもそも何故パーティション分割を行うのか
- BigQueryはスキャンするデータ量によって分析料金が変わる。
- 一回のスキャン量が10TBの場合と1TBの場合で費用が10倍違ってくる。
- 普通にテーブルを作って普通にスキャンをしてしまうと毎回テーブルをフルスキャンすることになる。
- 一回のスキャン量を減らす為にパーティション分割テーブルというものが存在する。適切にパーティション分割テーブルを作り適切なクエリを発行すると、分割されたテーブルの内の必要なテーブルのみをスキャンするのでスキャン費用が節約できる。
以下の通り、パーティション分割テーブルの作成には何種類かやり方があるみたい。
- 時間単位の列: テーブルの TIMESTAMP、DATE、または DATETIME 列に基づいてテーブルが分割されます。
- 取り込み時間: BigQuery がデータを取り込む際のタイムスタンプに基づいてテーブルが分割されます。
- 整数範囲: テーブルは整数列に基づいて分割されます。
→例として、一番分かりやすそうなので今回は「時間単位の列」を作成していく。
テーブルに入れるデータを準備する
分割テーブルの概念・使い方が分かれば良いので今回も簡易なデータを用いて検証していく
users.csv
ID,Name,favorite,create_datetime
1001,田中 太郎,サッカー,2020-12-02 10:05:04.971
1002,鈴木 一郎,野球,2021-02-03 14:45:44.811
1003,山田 隆史,テニス,2021-05-04 21:35:11.071
パーティション分割テーブルを作成してデータを入れる
- 今回もローカルからCSVをアップロード
- 「時間単位の列」でパーティション分割する場合はスキーマを自分で指定しないといけないのでCSVと同じヘッダ名でスキーマを指定
- 「パーティションとクラスタの設定」でパーティショニングを行う列を「create_datetime」に指定
- パーティショニングタイプを一日ごとに指定
- 「パーティションフィルタを要求」にチェックを入れると、クエリ発行の際に対象列にフィルタをかけないとエラーが出るようにしてくれるみたい
 |
|---|
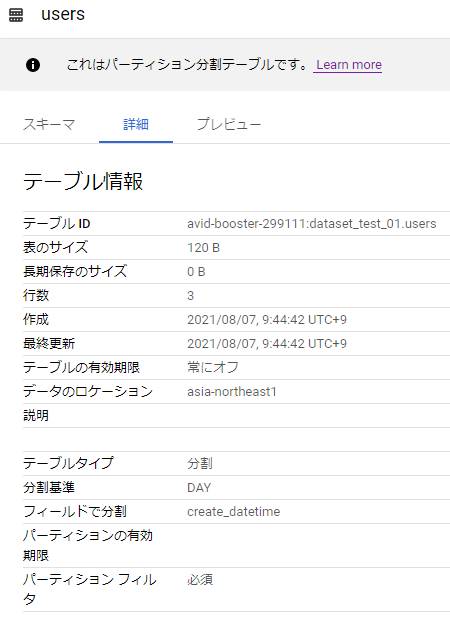
作成を押すと以下のようなテーブルが作成される。
 |
|---|
 |
 |
無事にパーティション分割テーブルとして作成されたよう
パーティション分割テーブルを検索する
クエリウインドウから検索をかけていく。
まずフィルタをかけずに全量スキャンをかけようとしたらエラーになった。
``SELECT * FROM `avid-booster-xxxxx.dataset_test_01.users```
 |
|---|
| 「パーティションフィルタを要求」のオプションが効いているよう。 |
次に全データが対象となるフィルタをかけて検索してみる。
SELECT * FROM `avid-booster-xxxxx.dataset_test_01.users` WHERE DATE(create_datetime) < "2021-12-31"
実行計画のスキャン量が120Bとなり、テーブル全体の大きさと一致したので想定通りフルスキャンになる結果となった。
 |
|---|
次に三件中、二件だけ一致するようなフィルタをかけて検索してみる。
SELECT * FROM `avid-booster-xxxxx.dataset_test_01.users` WHERE DATE(create_datetime) < "2021-3-31"
実行計画のスキャン量が80Bとなり、パーティション分割テーブルをうまく利用してスキャン量を減らすことができた。
 |
|---|
最後に、三件中、一件だけ一致するようなフィルタをかけて検索してみる。
SELECT * FROM `avid-booster-xxxxx.dataset_test_01.users` WHERE DATE(create_datetime) = "2021-2-3"
実行計画のスキャン量が37Bとなり、こちらも想定通りパーティション分割テーブルを利用してスキャン量を更に減らすことができた。
 |
|---|
これでパーティション分割テーブルの3種の内の一つについて理解出来るようになりました。
取り込み時間、整数範囲、についても基本的な考え方は同じだと思うのでどのようなデータを扱うか、どのような検索を行いたいのか、によって分割方法を決めればいいのかなと思います。
Discussion