RhinoInside.Revitの機能をPythonで管理してみた



RhinoInside.RevitはPythonで書くと便利
RhinoInside.Revitで日々色々とツールを作っています。デフォルトのコンポーネントにも色々なコンポーネントが既につくられているので、コンポーネントベースでも使用は可能です。
ですが、例えば鉄筋系のコンポーネントはまだ出ていないようなので、そのような場合はRevitAPIを用いて、コードを書いて使ったりしています。
C#で書く方法と、Pythonで書く方法と両方ありますが、バージョンの変更の際に一々dllを設定し直さなくて良いため、最近はPythonを好んで使っています。

RhinoInside.RevitやRevitのバージョンが変わった際に面倒
この方法を取ると、RhinoInside.RevitのAPIとRevitのAPIをそれぞれ使うことになります。これらは割と変更があり、GHPythonコードにべた書きをしていると、変更のあった関数やプロパティを全て直す必要があり、割と面倒くさい、、、、気がする、、、、
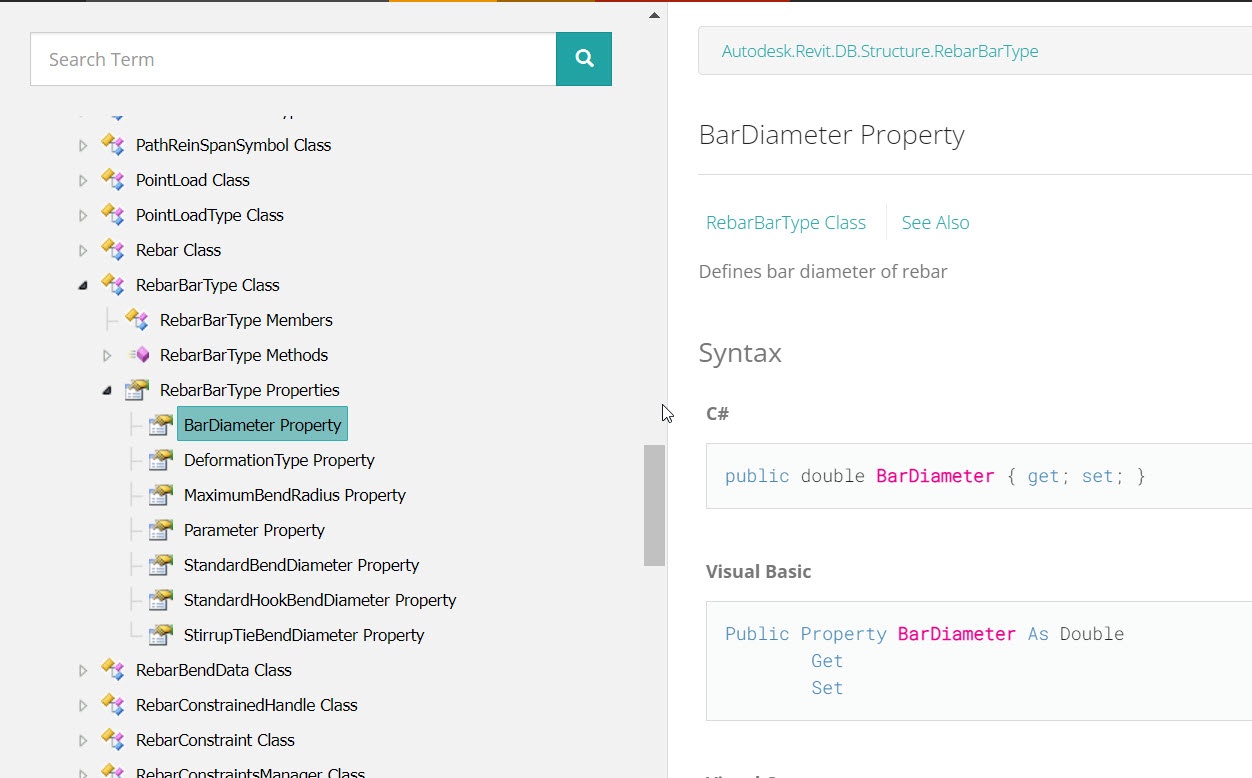
例えば鉄筋棒の直径のプロパティの取り方
RebarBarTypeから鉄筋棒の直径の大きさが取得できるのですが、Revit2023から取り方が変わりました。なんと、、、、微妙に名前が違う、、、、というか2種類ある、、、
こういうことが起きます。


配布していたGHファイルを回収するのが大変
また動かなくなった場合に、GHファイルを回収するのが大変です。GHファイルは、ユーザーも変更を加えて使うことが多いため、RevitAPIやRhinoInside.RevitのAPIが変更されたときに、その部分を見つけて、修正して配布し直すということがよく起きるのですが、その作業は思いのほか大変です。

(赤いコンポーネントばっかりだぜ、やれやれ)
解決案としてPythonのライブラリ化と配布用のインストーラーをつくってみる
解決案として、Pythonコードのライブラリ化と配布用のインストーラーをつくってみました。
この記事では、その方法を紹介したいと思います。
インストーラーの機能
GitHubからRelease情報を取得して、最新のバージョンのファイルをダウンロードします。
1,ユーザーオブジェクトをダウンロード
C:\Users[UserName]\AppData\Roaming\Grasshopper\UserObjects\RIR_PythonToolkit

2,ライブラリをダウンロード
C:\Users[UserName]\AppData\Local\GEL\RIR_PythonToolkit\my_package
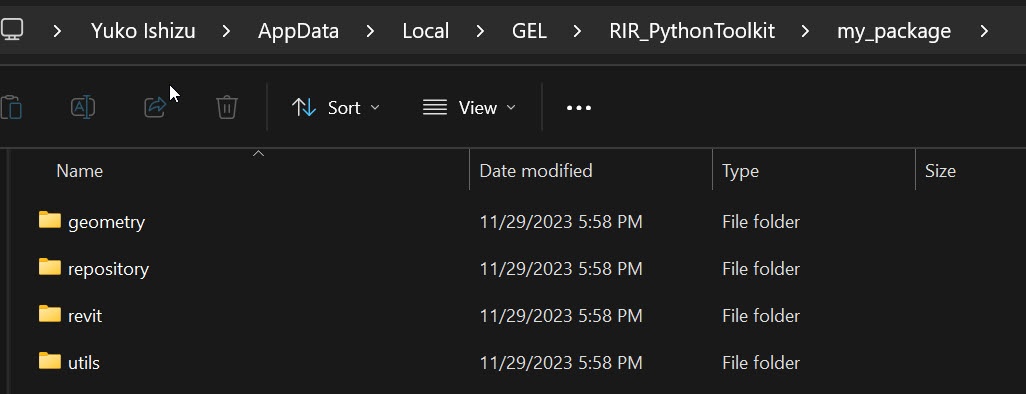
3,Pathを通す

__author__ = "ykish"
__version__ = "2023.11.24"
ghenv.Component.Name = 'TAEC RIR Toolkit Installer'
ghenv.Component.NickName = 'RIR Install'
ghenv.Component.Category = 'TAECRIRToolkit'
import clr
clr.AddReference("System.Net")
import os
import io
import subprocess
import System.Net
import System.Windows.Forms
import shutil
from distutils import dir_util
import Rhino
from Rhino.RhinoApp import Version as RHINO_VERSION
from Grasshopper.Folders import UserObjectFolders, DefaultAssemblyFolder
from Grasshopper.Kernel import GH_RuntimeMessageLevel as Message
from System import Array
from System.Net import WebClient
from System.IO import Path, Directory
import zipfile
import json
def remove_directory(path):
""" Remove a directory and all its contents """
if os.path.exists(path):
shutil.rmtree(path)
message = "Removed directory: {}".format(path)
else:
message = "Directory not found: {}".format(path)
return message
def remove_from_python_search_paths(path):
""" Remove a path from Rhino's Python script search paths """
current_paths = list(Rhino.Runtime.PythonScript.SearchPaths)
if path in current_paths:
current_paths.remove(path)
Rhino.Runtime.PythonScript.SearchPaths = Array[str](current_paths)
message = "Removed from Python search paths: {}".format(path)
else:
message = "Path not found in Python search paths: {}".format(path)
return message
def get_latest_release_zip_url(repo):
"""GitHubのAPIを使用して最新のリリースのZIPファイルのURLを取得する"""
api_url = "https://api.github.com/repos/{}/releases/latest".format(repo)
client = WebClient()
client.Headers.Add("User-Agent", "request")
release_info = client.DownloadString(api_url)
release_data = json.loads(release_info)
return release_data["zipball_url"]
def download_zip_from_url(url, save_dir):
"""指定されたURLからZIPファイルをダウンロードし、指定されたディレクトリに保存する"""
client = WebClient()
client.Headers.Add("User-Agent", "request")
filename = os.path.join(save_dir, "latest_release.zip")
client.DownloadFile(url, filename)
return filename
def unzip_file(zip_filepath, dest_dir, folders_to_extract, specific_destinations,tool_name):
with zipfile.ZipFile(zip_filepath, 'r') as zip_ref:
for item in zip_ref.infolist():
path_parts = item.filename.split('/')
# 2番目のフォルダ名を取得(トップレベルフォルダが1つのみの場合)
second_level_folder = path_parts[1] if len(path_parts) > 1 else None
# 2番目のフォルダが特定のフォルダに属する場合、適切なディレクトリに解凍
if second_level_folder in folders_to_extract:
destination = specific_destinations.get(second_level_folder, dest_dir)
# 完全な解凍先のパスを生成
full_path = os.path.join(destination, *path_parts[1:])
# ディレクトリの作成
if item.filename.endswith('/') and not os.path.isdir(full_path):
print(full_path)
os.makedirs(full_path)
# ファイルの解凍
elif not item.filename.endswith('/'):
# 解凍先ディレクトリが存在しない場合は作成
if not os.path.exists(os.path.dirname(full_path)):
os.makedirs(os.path.dirname(full_path))
# 元のフォルダ構造を無視して特定のパスにファイルを解凍
with zip_ref.open(item) as source, open(full_path, 'wb') as target:
shutil.copyfileobj(source, target)
# ZIPファイルの解凍が完了した後、特定のフォルダ名を変更
if 'userObjects' in folders_to_extract:
original_path = os.path.join(specific_destinations['userObjects'], 'userObjects')
new_path = os.path.join(specific_destinations['userObjects'], tool_name)
if os.path.exists(original_path) and not os.path.exists(new_path):
os.rename(original_path, new_path)
os.remove(zip_filepath)
if _install:
message =[]
# リポジトリのユーザー名/名前
repo = "yishizu/TAEC_RIR_PythonToolkit"
tool_name = "RIR_PythonToolkit"
# 保存するディレクトリ
save_dir = os.path.join(os.environ["LOCALAPPDATA"], "GEL", tool_name)
my_package_dir = os.path.join(save_dir,"my_package")
if not os.path.exists(save_dir):
os.makedirs(save_dir)
else:
message.append(remove_directory(save_dir))
message.append(remove_from_python_search_paths(my_package_dir))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 最新のリリースZIPのURLを取得
latest_release_url = get_latest_release_zip_url(repo)
print(latest_release_url)
ver = latest_release_url.split('/')[-1].lstrip('v')
ghenv.Component.Message = ver
userObject_dir =""
for folder in UserObjectFolders:
if "UserObjects" in folder:
userObject_dir = folder
folders_to_extract = {'my_package', 'gh_scripts', 'data','userObjects'}
specific_destinations = {
'my_package': save_dir,
'gh_scripts': save_dir,
'data':save_dir,
'userObjects': userObject_dir
}
# ZIPファイルをダウンロードして解凍
zip_path = download_zip_from_url(latest_release_url, save_dir)
message.append('zip file downloaded...')
#print(zip_path)
unzip_file(zip_path, save_dir,folders_to_extract,specific_destinations,tool_name)
message.append('unzip...')
current_paths = list(Rhino.Runtime.PythonScript.SearchPaths)
new_path = os.path.join(save_dir,"my_package")
if new_path not in current_paths:
current_paths.append(new_path)
Rhino.Runtime.PythonScript.SearchPaths = Array[str](current_paths)
print(Rhino.Runtime.PythonScript.SearchPaths)
message.append('Added Path...')
message.append(Rhino.Runtime.PythonScript.SearchPaths[-1])
message.append("Success!!!")

Pythonのライブラリを使用してみる
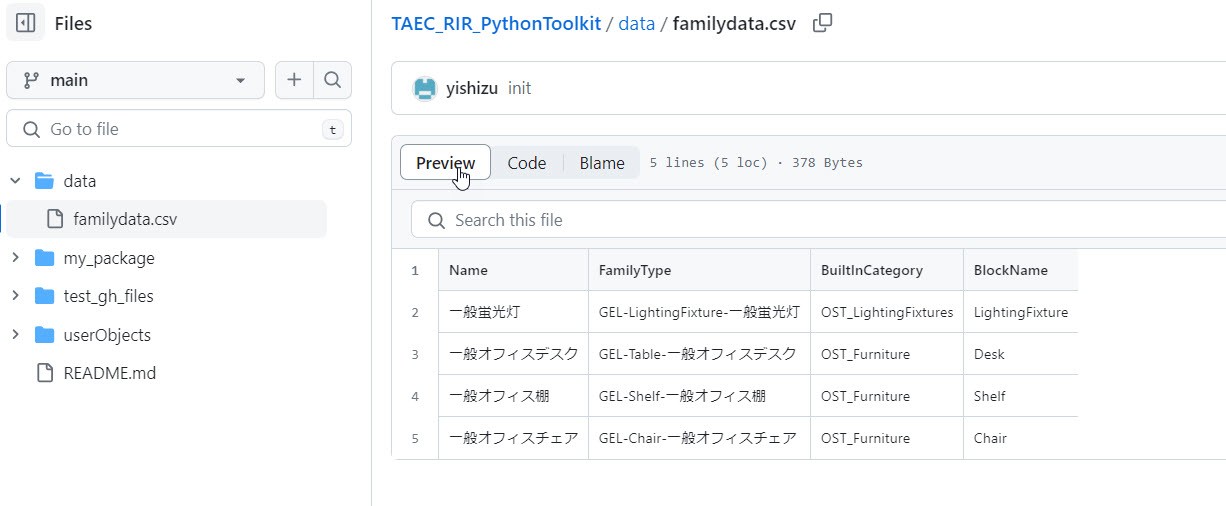
本日のデータはこちらになります。
Data Processor
例えば、社内の標準ファミリのRhinoのBlockとRevitのFamilyの関係をcsvに保存しておく。
このデータを用いて、RhinoからRevitへ簡単にファミリを生成するための仕込みのコードを用意する。
# -*- coding: utf-8 -*-
import csv
import os
import codecs
def find_row_by_name(target_name, name_key,target_column = None ):
current_dir = os.path.dirname(__file__)
two_levels_up = os.path.abspath(os.path.join(current_dir, '..', '..'))
csv_path = os.path.join(two_levels_up, 'data','familydata.csv')
data = []
with codecs.open(csv_path, 'r', 'utf-8', 'ignore') as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
if row[name_key] == target_name:
if target_column:
# 特定の列のみを追加
data.append(row[target_column])
else:
# 全ての列を追加
data.append(row)
return data
print(find_row_by_name('Desk','BlockName'))

内部で持っておいたデータをDictionaryで持っておくことができるようになりました。
これは、色々な使い方が考えられますが、RhinoとRevitへどうデータを連携するかという情報を社内で統一して持っておくことができます。
Revit FamilyInstance Creation
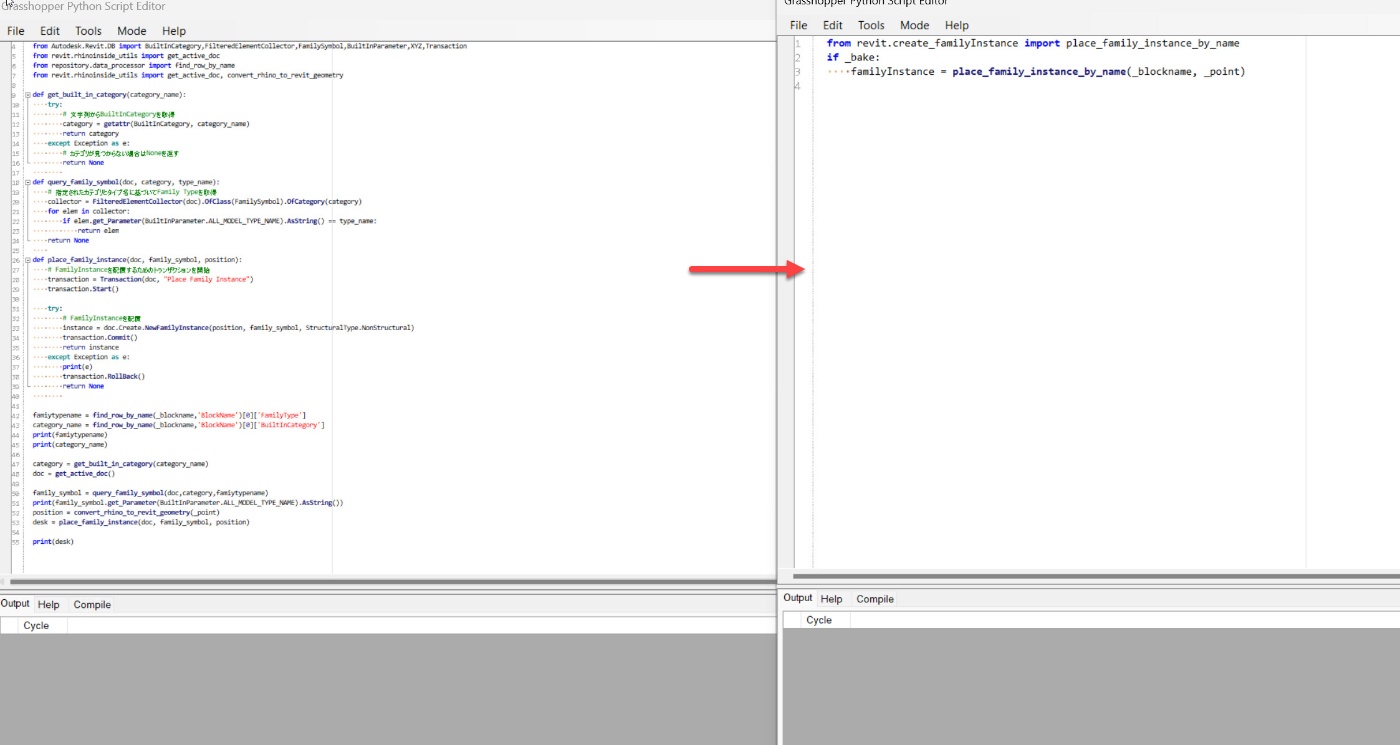
このように、Revit系の関数をライブラリ化することで、GH内のコードはスッキリとまとめて奥古閑可能です。Revitのバージョンが変更されても、ライブラリ内の関数を変更すれば、すべてのコンポーネントで使っていた関数がアップデートされます!
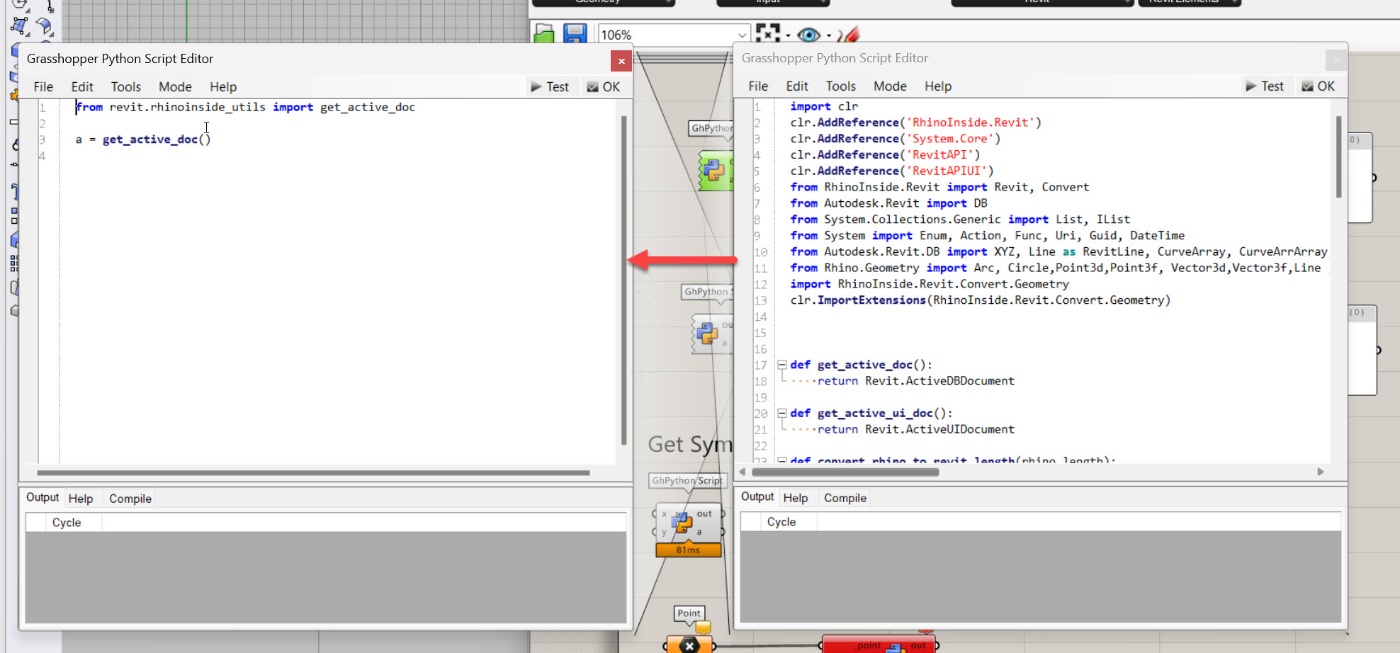
さきほどのCSVからDictionaryでデータを取得できるようにしておいてから、ライブラリの関数からFamilyInstanceを生成する様子です。
いかがでしょうか?
色々な使い道がありそうです!
Pythonのライブラリ化の感想
RevitAPIやRhinoInside.RevitAPI、RhinoCommonが関わらないところは、先にテストできるので割と便利だなと感じました。GHPython内に書くとCopilotの助けがないので、書くのが大変です。
ただし、RevitAPIやRhinoInside.RevitAPI、RhinoCommonが関わるところは、毎回Revitを立ち上げてテストする必要があるので、まずはGHPython内に動くコードを書いて、それをコピペしてからライブラリ化に綺麗にまとめていくということが必要で時間がかかります。
なので一度きりしか使わないようなGHコードのためにこの作業をするのは、あまり効果的ではないと思います。ただし、長期で使うようなコードだったり、現場が海外でGHファイルの使い手とGHファイルの作り手が離れているような場合などは、コミュニケーションコストは下がるので、使い方次第では効果が出るような気がします。
参考
Discussion