ニュースについて
生成AIで起こるSAP技術文書変革:Amazon BedrockでSAP Notesのナレッジ生成を加速
本日のAWSニュース
生成AIを活用したナレッジベース文書の効率化の話。
ウェブブラウザ向けに最適化されたページはモバイルユーザーには負荷が高い
→Amazon Bedrockを使用して、SAP NotesとKBAのAI生成要約の機能を持つアプリを開発しよう!
開発に際して下記のような問題点が発覚。
①600万ものSAP Notesの要約
②技術的制度の確保が重要
③新規および既存のノートの両方に対する要約更新を管理するための効率的なシステムの開発も必要
→RAGを利用して膨大な知識ベースを効率的にベクトル化・検索・要約し、サポートの精度(ソースとなる記事を表示)と答えにたどり着くスピードを向上させた!これはSAPのモバイル利用の革命や~~~
みたいな話
知識として情報はベクトル化されて学習につかわれるよ~んみたいな事を学んでいたけど
実際にはこういう風に使われるのだなあと思いました。
でもこれ結構データ化が進んでいないとこならどこの会社においても役に立ちそうですよね。
例えば膨大な文書とかもOCR化したデータをベクトルデータ化すれば紙文書もデータのナレッジにできるよねえ~などと思いましたが素人が思いつく事ならどこもやってるか。。。
bedrockは生成された解答を自然な言語にするみたいな部分でも使用されていてなるほどなあと。
bedrockは合体させるRAGの中身次第でどうとでもなるビックリドッキリメカなんだねえと

気になって見に行ったらもう最初からRAGと連携させて実装できるらしい。すごい(小並)

これオッケーなとこならウェブもソースにできるんですね
適当に好きなゲームのウェブページをソースに自分が欲しい情報を出してくれるエージェントとかを試しに作ってみるのも面白いかもしれない…
なるべく近いうちにトライしてみることとする。
こちらは昨日と同じようなソリューションで、Amazon Bedrock のKnowledge Bases 機能のRAGを使用して、膨大な情報から曖昧検索できるようにしましたよという話と、スキルや成長を猫の成長で可視化する遊び心の見えるソリューションを作成することで情報探索時間を24000→4000時間まで削減と
ざっと八割削減しましたよという話
やはりBedrock Knowledge Bases 機能のRAG これはかなり激熱な気がします。
こちらは少しシンプルだがbedrockを使用した対話型サービスの説明。
自身が作成しようと思っていた構成にかなり近しいので参考にしようと思って紹介。
ちょっと趣向を変えてAWS以外のサイトから、、、
意図的にリソースの限られたところにAIを配置して、どう行動するのかを観察するという
なかなか面白い実験。途中では極限状況にAIを2体(?)配置して、どういう行動を取るか観察というなかなかえぐいこともやっている。
結論、LLMが我々の書いたテキストから生存志向のパターンを学習していることを意味しており
これは安全性と信頼性に関する新たな課題を提起しているとのこと。
AI自体が自身の生存が脅かされると認識した場合、AIの都合のいいように解答を出力してしまう…みたいなことが起きたりする可能性があるってことかな?
道具として扱っていたつもりが、いつの間にか人間側がAIの指示通りに生きるだけの道具になっていた…なんてディストピアな未来がちょっぴり想像できたりできなかったりして、便利だけど怖いなあと思った(こなみ)
Amazon Bedrockを活用したAWS サポート問い合わせ内容の自動集約ソリューションの実装
さらっと読んだだけだと内容がよくわかんないし構成図も意味わからないので何度か読み返したが
要はたくさんのAWSアカウントで問い合わせを投げてるから問い合わせ内容がみんなで共有しにくい
ナレッジベースを作ろうにも手作業が多く発生して手間がかかりすぎる、、、
しかも問い合わせは二年経過すると消えてしまう、、、、
①問題解決をトリガーにeventbridgeでlamdaを起動
②解決した時の会話データを取り込んでbedrockに食わせて要約
③出力結果をDynamoDBに保存
④結果はservicenowから開けてみんなハッピー
ということでAWSのお手本みたいなデータの流れでナレッジの作成と共有にあたっての手間や問題点をまるっと解決しましたよという話でした(かなり端折っているので興味があれば記事をご覧ください)
新しい汎用 Amazon EC2 M8a インスタンスが利用可能になりました
というわけでオレゴンで早速確認
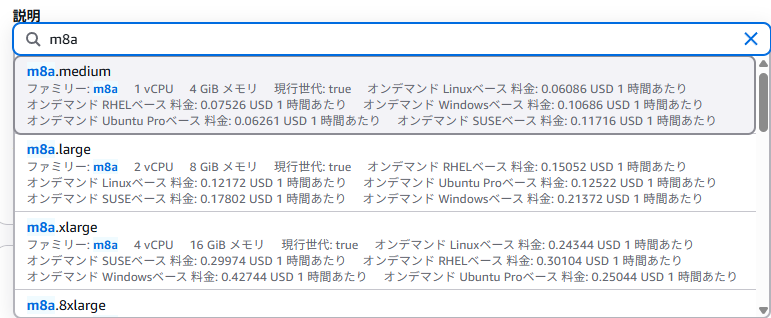
シンプルにスペックが高いんですが、SAP認定を受けてるので高パフォーマンスを求めるorSAPのソリューションで必要とされる感じ
新しいコンピューティング最適化 Amazon EC2 C8i および C8i-flex インスタンスのご紹介

こっちはCなんでコンピューティング特化EC2の新型のようですね…
機械学習とかが捗るのかもしれない
こういった基本のサービスも日進月歩で良いものが実装されているんですなあ
最近よく見る企業での生成AIを使用した業務効率化みたいな事例ではこいつらを見る機会が増えそうなのでそういった点にも注目しながら見ていく。