【論文紹介】A Survey on RAG Meeting LLMs(RAG調査)
- 論文はこちらに参考してください
1. はじめにと背景
データマイニングにおける検索技術の重要性とその応用
検索技術はデータマイニングにおける最も基本的な技術の一つであり、入力クエリを理解して外部データソースから関連情報を抽出することを目的としています。検索エンジン、質問応答システム、推薦システムなど、さまざまな分野で広く利用されています。例えば、検索エンジン(Google、Bing、Baiduなど)は、業界において検索技術の最も成功した応用の一例であり、ユーザーのクエリに最も関連性の高いウェブページや文書をフィルタリングし、検索してくれることで、ユーザーが必要な情報を効率的に見つける手助けをしています。また、検索モデルは外部データベースを効果的に管理することで、さまざまな知識集約型のタスクにおいて真実でタイムリーな外部知識を提供し、重要な役割を果たします。AI生成コンテンツ(AIGC)の時代が到来するにつれ、検索技術は先進的な生成モデルに統合され、生成されるテキストの品質を大幅に向上させています。
Retrieval-Augmented Generation (RAG) の役割
Retrieval-Augmented Generation (RAG) は、検索モデルと言語モデルを組み合わせる技術であり、検索によって生成テキストの品質を向上させることを目的としています。RAGはまず、検索エンジンから外部データベース内の関連する文書を検索し、それを元のクエリと組み合わせて文脈として活用し、生成プロセスを強化します。RAG技術はさまざまな生成タスク、特にオープンドメインの質問応答(OpenQA)などの知識集約型タスクで優れた成果を示しており、検索コンポーネントの調整だけで多様なタスクに効率的に適用できることから、通常追加のトレーニングが不要です。RAGは知識集約型タスクにおいて卓越した成果を示すだけでなく、一般的な言語タスクや下流アプリケーションにおいても大きな可能性を見せています。

RAG イメージ図
RA-LLMsのアーキテクチャ、トレーニング戦略と応用分野
近年、特に大型言語モデル(LLMs)において、基礎的な事前学習モデルが様々なタスクで優れた成果を上げています。LLMsの成功は、その先進的なアーキテクチャと大量のトレーニングコーパスでの事前学習に起因しています。しかし、LLMsには、特定分野の知識の不足や「幻覚」の生成問題、モデルの更新に必要な膨大な計算リソースといった固有の制約があります。これらの問題を解決するために、RAGの利用を通じてLLMsの能力を強化し、特に最新で信頼性のある知識が求められるタスクにおいてその価値が証明されています。RA-LLMsは、外部データベースから関連知識を検索し、それを生成プロセスに統合することで、「幻覚」の生成問題を効果的に抑制し、生成内容の品質を向上させています。
RA-LLMsの制限と将来的な研究方向
RA-LLMsは生成テキストの品質向上において優れた成果を示していますが、依然としていくつかの制限があります。例えば、さまざまな分野のニーズに応えるために外部知識を効率的に検索し統合する方法や、モデル更新に必要な計算リソースを削減する方法などの課題が存在します。また、RA-LLMsが特定分野のタスクを処理する際に、検索と生成プロセスのさらなる最適化が求められ、生成内容の正確性と関連性を確保する必要があります。将来的な研究は、RA-LLMsのアーキテクチャとトレーニング戦略を最適化し、これらの課題に対応するとともに、より多くの実際の応用シナリオにおける潜在的な可能性を探る方向性が考えられます。
2. 主要技術と方法
検索コンポーネント設計の分析
検索コンポーネントは検索拡張生成モデル(RAG)において重要な役割を果たしており、クエリと外部知識ソースの文書間の距離を測定することで関連情報を提供します。検索方法は主にスパース検索とディープ検索の二種類に分類されます。
スパース検索とディープ検索
スパース検索は通常、TF-IDFやBM25などの単語マッチングに基づいており、これらの手法はインバーテッドインデックスや原始データ入力に依存しています。例えば、BM25は生成器への入力を強化するために段落レベルでの検索によく使用されます。しかし、スパース検索の主要な制限は、トレーニング不要であるため、検索性能がデータベースやクエリの品質に強く依存する点です。また、固定された単語マッチング手法は類似性に基づいた検索のみをサポートし、多様性など他の可能な検索基準には対応できません。
一方、ディープ検索ではクエリと文書を連続ベクトル空間に埋め込み、通常は意味的な類似性に基づいています。ディープ検索は通常トレーニング可能であるため、適応性においてより大きな柔軟性と潜在能力を持っています。ディープ検索の主要なコンポーネントは埋め込みモデルであり、現行のRAGモデルではこの設計が異なります。簡単な設計としては、生成モデルの一部を検索器の埋め込み層として直接使用し、検索と生成プロセスの整合を強化する方法があります。BERT構造の双流エンコーダ(bi-encoder)は、クエリと文書のエンコードに使用される一般的な設計の一つであり、Dense Passage Retriever (DPR)のように、大規模な専用事前学習が知識集約タスクでのRAGモデルのパフォーマンスをさらに向上させます。
生成器設計の考察
生成器の設計は下流タスクに依存し、主にホワイトボックス生成器とブラックボックス生成器に分かれます。
ホワイトボックス生成器
ホワイトボックス生成器のパラメータはアクセス可能であり、モデルの最適化が可能です。代表的なホワイトボックス生成器にはEncoder-Decoder構造とDecoder構造のみが含まれます。Encoder-Decoderモデル(T5やBARTなど)は、異なるパラメータセットで入力とターゲットを独立して処理し、交差アテンションコンポーネントを介して入力とターゲットを接続します。対照的に、Decoderのみのモデルは、入力とターゲットを接続してから処理を行い、ネットワーク伝播中に両部分の表現が並行して構築されます。これらの生成器は検索データと組み合わせることで生成の正確性と関連性を高めており、RAGやRe2GはBARTを使用し、FIDやEMDR2はT5を利用しています。
ブラックボックス生成器
ブラックボックス生成器の内部構造やパラメータはアクセス不可能であり、典型的な例としてGPTシリーズやCodexがあります。これらの生成器はクエリを入力し、応答を受け取るのみで、内部構造の変更やパラメータの更新ができません。ブラックボックスRA-LLMsは検索と強化プロセスに注力しており、生成器の性能向上のために入力(LLM文脈ではプロンプトとして呼ばれる)を強化することで対応しています。例えば、Rubinらは、プロンプト検索器をトレーニングし、言語モデル自身がデータに注釈を付けたサンプルを提供して文脈学習を強化する方法を提案しました。
トレーニング戦略の議論
トレーニングの必要性に応じて、既存のRAG方法はトレーニング不要な方法とトレーニングに基づく方法に分類できます。
トレーニング不要な方法
トレーニング不要な方法は、推論時に直接検索した知識を利用し、それをプロンプトに挿入するため、計算効率が高いです。しかし、この方法の課題は、検索器と生成器のコンポーネントが下流タスクに最適化されていないため、検索知識の利用が次善にとどまる可能性があることです。
独立トレーニング、順序トレーニングと結合トレーニング
トレーニングに基づく方法は、検索器と生成器を微調整することで外部知識を最大限に活用します。独立トレーニング方法はRAGプロセス内の各コンポーネントを独立してトレーニングします。順序トレーニング方法は、あるモジュールをトレーニングし、そのパラメータを固定してから別のパーツを調整するプロセスを採用します。結合トレーニング方法は、検索器と生成器を同時にトレーニングすることで、パフォーマンスを最大化します。
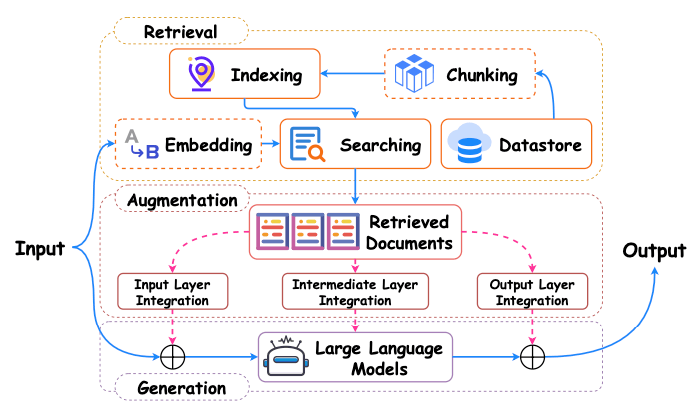
システム構成
3. 自然言語処理の応用
質問応答システムにおける応用
質問応答システム(QA Systems)は、ユーザーに正確な回答を提供することを目的としています。しかし、大量のデータでトレーニングしても、これらのシステムは最新の情報や特定の分野の知識が不足することがあります。この問題を解決するために、RA-LLMs(検索拡張大規模言語モデル)の統合が重要な役割を果たしており、検索と関連情報の合成能力を強化することで、質問応答システムの回答精度を大幅に向上させています。
具体的には、RA-LLMsは検索コンポーネントを介して膨大な知識ベースにアクセスし、連続的で文脈関連のある回答を提供します。例えば、REALMモデルは、知識検索器を事前学習、微調整、推論の各フェーズに統合し、大規模なコーパスから情報を検索することで回答の正確性を向上させました。同様に、Fusion in-Decoderモデルは、サポートドキュメントから段落を検索し、質問と融合することで回答を生成し、精度を向上させています。Borgeaudらの研究も、回答の品質が検索結果に大きく依存することを示しています。
チャットボットにおける応用
チャットボット(ChatBot)は、ユーザーと自然で連続的な対話を行うことを目的としています。質問応答システムとは異なり、チャットボットはユーザーとの連続性と豊富な対話を重視します。これらの能力を強化するため、最近の手法ではRA-LLMsを統合し、関連する外部知識をチャットボットに強化することで、より魅力的で文脈豊かなユーザーインタラクションを促進しています。
事実検証における応用
事実検証(Fact Verification)は、情報の正確性と信頼性を検証する重要なタスクです。信頼できる証拠に対するニーズが高まる中で、RA-LLMsは事実検証能力を強化するために使用されています。Lewisらは、RA-LLMsを外部知識の検索を通じて強化することで、事実検証を含む知識集約型タスク全般に優れた成果を示しました。Atlasモデルは、少数サンプル学習においてRA-LLMsの事実検証における性能を評価しました。
最近では、Self-RAGモデルが自己反映メカニズムを導入することで大きな進展を遂げています。具体的には、Self-RAGは検索した情報が有用かどうかを反映し、その信頼性を評価することで、検証の精度を大幅に向上させています。この自己反映メカニズムは、モデルの性能向上に寄与するだけでなく、検索と検証プロセスのさらなる最適化の新たな方向性も示唆しています。
4. 特定分野における応用
科学と金融分野におけるRA-LLMsの応用
特定分野における応用において、検索拡張大規模言語モデル(RA-LLMs)は巨大な潜在力と広範な応用の可能性を示しています。科学と金融といった高度にデータと情報に依存する分野は、RA-LLMs技術の重要な実験場となっています。
分子とタンパク質研究における役割
科学分野では、RA-LLMsは分子とタンパク質研究において強力な能力を発揮しています。分子研究において、RA-LLMsは分子の特性を認識し、新しい分子の予測を行うことで、薬物発見のプロセスを大幅に促進しています。例えば、LiらとWangらは、データベース検索に基づくフレームワークを提案し、分子の生成を指導しています。Liuらは、大規模データセットからテキスト知識を検索することで、分子の属性を予測する多モーダル分子構造-テキストモデルを導入しました。
また、タンパク質研究においても、RA-LLMsは重要な役割を果たしています。RSAモデルは、ターゲットタンパク質の配列構造や機能に類似した配列を検索することで、タンパク質の表現を強化しています。Lozanoらは、発表済みのレビュー記事を検索する臨床質問応答システムを提案し、RA-LLMsがバイオメディカル分野における応用潜在力をさらに示しています。
金融感情分析と知識抽出
金融分野において、RA-LLMsは意思決定プロセスを強化することで、金融分析の精度を大幅に向上させています。金融感情分析では、Zhangらがニュースプラットフォーム(BloombergやReuters)やソーシャルメディアプラットフォーム(TwitterやReddit)から金融情報を検索し、それを元のクエリと組み合わせることで感情分析の精度を向上させています。また、金融質問応答システムも金融分析の重要なタスクです。LinはRA-LLMsを活用したPDFパーサーを提案し、金融レポートから関連知識を検索しています。Yepesらは段落ではなく構造に基づく文書分割方法を提案し、RA-LLMs出力の品質をさらに向上させました。
特定分野におけるRA-LLMs応用のメリットと課題の評価
特定分野におけるRA-LLMsの応用は多くのメリットを示していますが、いくつかの課題にも直面しています。まず、RA-LLMsは外部データソースの統合により、モデルの精度と実用性を大幅に向上させますが、これは特に金融や医療といったセンシティブな分野において、データのプライバシーとセキュリティの問題を引き起こす可能性があります。次に、非構造化データ(例えばPDF形式の金融レポート)を効率的に処理し解析する方法は、未解決の重要な課題です。
また、RA-LLMsの分野別応用には、特定のタスクに対して最適化が必要です。例えば、分子とタンパク質研究においては、複雑なバイオメディカルデータの理解と処理能力をさらに向上させる必要があります。一方、金融分野では、市場の急速な変化と膨大なリアルタイムデータに対応する方法もRA-LLMsが克服すべき課題です。
5. 下流タスクにおける応用
レコメンデーションシステムにおける応用
レコメンデーションシステムは、ユーザーの嗜好をモデル化し、パーソナライズされた推薦を提供する重要な役割を果たしています。近年、RA-LLMs(検索拡張大型言語モデル)は、パーソナライズされ文脈関連のある推薦を提供する上での巨大な潜在力を示しています。RA-LLMsは、検索と生成プロセスを組み合わせることで、複数のデータソースから関連情報を抽出し、推薦システムのパフォーマンスを強化します。例えば、Di Palmaは、映画や書籍のデータセットの知識を活用して推薦効果を向上させるシンプルな検索拡張推薦モデルを提案しました。Luらは、レビューから情報を検索し、推薦システム内の項目情報を豊かにすることでさらに進化させました。CoRALは、強化学習を使用してデータセットから協調情報を検索し、それを意味情報と整合させ、より正確な推薦を提供しています。
ソフトウェアエンジニアリングにおける応用
RA-LLMsは、コード生成、プログラム修復、コード要約などのタスクにおけるソフトウェアエンジニアリングでの応用にも広く注目されています。検索拡張生成パラダイムは、コード生成とプログラム修復に利用されており、Parvezらは、コードライブラリから高ランクのコードや要約を検索し、それを入力と組み合わせてコード生成や要約の効果を強化する方法を提案しました。
表データ処理とText-to-SQL意味解析
RA-LLMsは、表データ処理とText-to-SQL意味解析分野においても顕著な潜在力を示しています。表データ処理において、RA-LLMsは関連表情報を検索し、対応する解析結果を生成することで、データ処理の効率と正確性を向上させます。Text-to-SQL意味解析タスクにおいて、RA-LLMsは自然言語のクエリを理解し、対応するSQLクエリを生成することで、ユーザーがデータベースから必要な情報をより簡単に取得できるようにします。
6. 今後の課題と研究の方向性
信頼性のあるRA-LLMsの開発
信頼性のあるRA-LLMs(検索拡張大規模言語モデル)の開発において、システムの堅牢性、公平性、説明可能性、およびプライバシー保護が非常に重要です。堅牢性は、RA-LLMsが悪意ある、または意図しない干渉に耐え、さまざまな状況下で信頼できる意思決定を行う能力を意味します。公平性は、モデルが意思決定の過程でいかなる形式の差別も回避し、すべてのユーザーが公正に扱われることを意味します。説明可能性は、RA-LLMsの内部動作メカニズムを全面的に理解し、モデルの予測結果を透明かつ説明可能にすることを要求します。プライバシー保護は、データウェアハウスに保存されている個人情報の安全性を確保し、データ漏洩を防止することです。
AI分野では、これらの方向で研究者がいくつかの進展を遂げています。例えば、堅牢性に関しては、対抗トレーニングと防御メカニズムを通じてモデルの安定性を強化する研究が進んでいます。公平性については、マルチモーダルデータや多言語処理の導入がモデルのバイアスを軽減するのに役立っています。説明可能性に関しては、説明可能なAI(XAI)技術の発展により、複雑なモデルの意思決定プロセスがより透明になっています。プライバシー保護の面では、フェデレーションラーニングと差分プライバシー技術がデータセキュリティのための有効な解決策を提供しています。
多言語RA-LLMsの潜在力
多言語RA-LLMsは、多言語の知識を統合することで、モデルの理解力と生成能力を大幅に向上させる可能性があります。グローバル化が進む中で、AIシステムは異なる言語での情報を理解し、やり取りできる能力が求められています。多言語知識の検索と生成を導入することで、モデルはさまざまな言語リソースの情報をアクセスし、総合することができ、より詳細かつ包括的な理解と生成が可能となります。
例えば、ユーザーは豊富な英語と中国語のコーパスを利用して知識検索を行い、モデルの下流タスクにおけるパフォーマンスを向上させることができます。これは、異なる文化間の交流と知識共有に寄与するだけでなく、言語の障壁を取り除き、異なる地域の人々に利便性を提供します。特に小言語を使用するユーザーにとって、多言語RA-LLMsは幅広い知識資源を提供し、さまざまなアプリケーションシナリオでのパフォーマンス向上に寄与します。
マルチモーダルRA-LLMsの将来性
マルチモーダルRA-LLMsは、複数のデータモーダル(画像、ビデオ、音声など)を統合することで、モデルの文脈理解と生成能力を強化します。単一モーダルの検索拡張生成と比較して、マルチモーダルRA-LLMsはより豊富な文脈情報を活用でき、ユーザーのニーズをより包括的に理解し、正確で詳細かつ高品質な生成結果を提供します。
例えば、画像やビデオは貴重な視覚的手がかりを提供し、テキスト情報を補完することで、より正確な言語生成を実現します。このマルチモーダル統合の能力により、RA-LLMsは医療、薬物発見、分子分析などの分野において広範な応用の可能性を秘めています。複数のモーダルを効果的に統合することで、RA-LLMsは世界をより包括的に理解し、より正確で洞察に富んだ出力を生成することが可能です。
外部知識ベースの品質向上
外部知識ベースの品質は、RA-LLMsの出力の正確性と信頼性にとって極めて重要です。現行システムで一般的に利用されている知識ベース(Wikipediaなど)は、多くの記事を含む一方で、記事の信頼性と正確性にはばらつきがあります。低品質や不正確な情報は、モデルの生成プロセスを誤導し、パフォーマンスに悪影響を与える可能性があります。
したがって、外部知識ベースの品質を向上させ、低品質や信頼性の低い情報をフィルタリングすることは、RA-LLMsシステムの出力の正確性と信頼性を高める鍵となります。知識ベースの品質を強化することで、RA-LLMsシステムはより正確で信頼性の高い出力を生成し、さまざまな実際の応用においてより効果的に機能します。
Discussion