[論文紹介]Self-RAG: Learning to Retrieve, Generate, and Critique through S
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
arxiv:https://arxiv.org/abs/2310.11511
超簡単なまとめ
自らの出力を批評することで出力を制御するようなSelf-RAGというフレームワークを使って生成品質の向上が認められた
各種情報
- 提出日:2023年10月17日
- 提出者及び所属:Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi(University of Washington, Allen Institute for AI, IBM Research AI)
要旨翻訳
LLMは、その卓越した能力にもかかわらず、内包するパラメトリック知識のみに依存するため、しばしば事実と異なる応答を生成する。RAGは、関連知識の検索によってLMを補強するアドホックなアプローチであり、このような問題を減少させる。しかし、検索が必要であるか、関連性があるかどうかに関わらず、検索された文章を無差別に入力することは、LMの汎用性を低下させ、役に立たない生成につながる可能性がある。我々は、検索と内省を通じてLMの品質と事実性を向上させる、Self-RAGと呼ばれる新しいフレームワークを導入する。このフレームワークは、必要に応じて文章を検索し、リフレクショントークンと呼ばれる特別なトークンを用いて、内省する。リフレクショントークンを生成することで、LMは推論段階で制御可能となり、多様なタスク要求に合わせた振る舞いが可能となる。実験によると、Self-RAG(7Bと13Bのパラメータ)は、様々なタスクにおいて、最新のLLMや検索補強モデルを大幅に上回る。特に、Open-domain QA、推論、事実検証タスクにおいて、Self-RAGはChatGPTや検索補強型Llama2-chatを凌駕し、これらのモデルと比較して、長文生成の正確性と引用精度の有意な向上を示す。
モチベーション
- 👎LLMは、驚異的な生成能力を持つが、パラメトリックな知識にのみ依存するため、事実に反する生成をしばしば行う。
- 👎RAGは、LLMの入力に関連する知識を検索して追加することで、この問題を減らすが、検索が必要かどうかや文書が関連しているかどうかに関係なく、一定数の文書を検索して生成に組み込むため、LLMの多様性や生成品質を低下させる可能性がある。また、生成された出力が検索された文書と一致しているかどうかを明示的に学習したり、検索された文書を引用したりすることができない。
強み
- 👍検索が必要かどうかを動的に判断し、検索された文書の関連性や生成品質を細かく評価することで、RAGの欠点を克服する。
- 👍任意のLLMに適用でき、生成品質や事実性を向上させるだけでなく、生成の多様性や創造性を損なわない。
- 👍リフレクショントークンを用いて、生成に対する制約や制御を柔軟に調整できる。例えば、事実性や引用精度を重視する場合は、検索頻度を高めたり、文書の支持度を高めたりすることができる。
手法
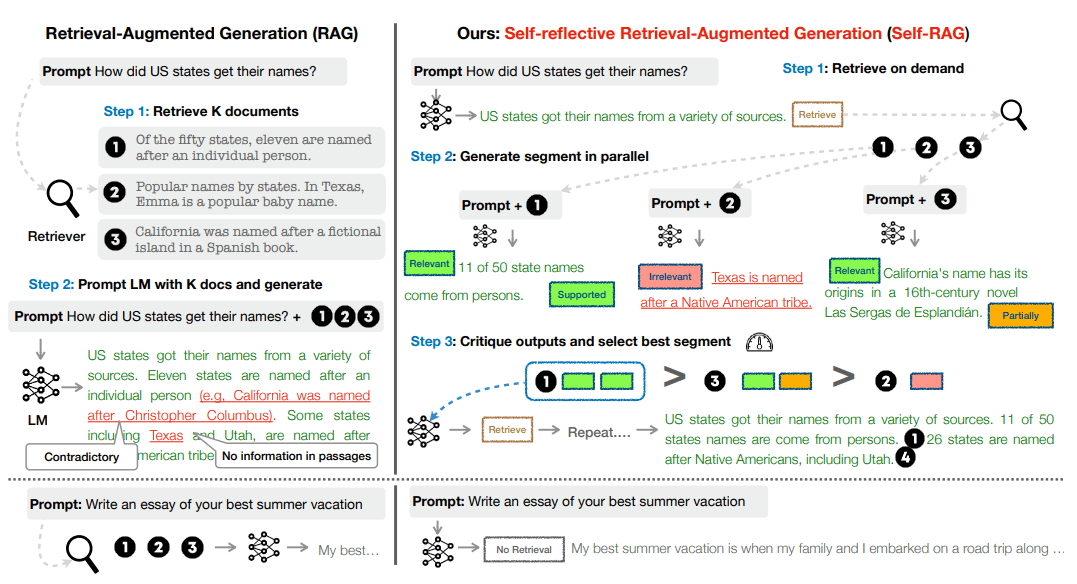
SELF-RAGは、検索モデルR、批評モデルC、生成モデルMの3つのコンポーネントから構成される。
検索モデルRは、入力に基づいて関連する文書を検索する。
批評モデルCは、検索された文書や生成された出力の品質を評価するためのリフレクショントークンを生成する。リフレクショントークンには、検索トークンと批評トークンの2種類がある。検索トークンは、検索が必要かどうかを判断するためのものであり、yes, no, continueの3つの値をとる。批評トークンには、文書の関連性(ISREL)、出力の支持度(ISSUP)、出力の有用性(ISUSE)の3つのタイプがあり、それぞれ複数の値をとる。

x,y,dはそれぞれ入力、出力、関連パッセージ
生成モデルMは、入力と検索された文書に基づいて出力を生成するとともに、リフレクショントークンを自身で生成することができる。生成モデルMは、リフレクショントークンを含む拡張された語彙から次のトークンを予測するように学習される。
学習時には、まず批評モデルCを、GPT-4によって生成されたリフレクショントークンを含む教師データで教師あり学習する。次に、批評モデルCと検索モデルRを用いて、元の入力-出力ペアにリフレクショントークンと検索された文書を挿入して、生成モデルMの教師データを作成する。最後に、生成モデルMを、リフレクショントークンを含む教師データで学習する。
推論時には、生成モデルMは、入力に基づいて検索トークンを生成し、必要に応じて検索モデルRを呼び出す。検索された文書に対して、生成モデルMは、関連性、支持度、有用性の各批評トークンを生成し、それらの確率を用いて出力候補をランク付けする。リフレクショントークンの重みは、推論時に調整することができる。
実験
- 実験設定
Llama2 7Bと13BをMとして使用し、Llama2 7BをCとして使用する。Rには、Contriever-MS MARCO (Izacard et al., 2022a)を使用し、各入力に対して最大10個の文書を検索する。

表中のタスクを知らない人向け
以下bing AIの出力
PopQAは、ポピュラーな知識に関するオープンドメインの質問応答タスクです。Mallen et al. (2023)によって作成されたデータセットで、月間のWikipediaページビューが100未満のレアなエンティティに関する1,399のクエリが含まれています。
TQAは、トリビアに関するオープンドメインの質問応答タスクです。Joshi et al. (2017)によって作成されたTriviaQA-unfilteredというデータセットで、11,313のテストクエリが含まれています。
Pubは、公衆衛生に関する事実検証タスクです。Zhang et al. (2023)によって作成されたPubHealthというデータセットで、医学的な主張の真偽を判定する必要があります。
ARCは、科学的な試験から作成された多肢選択式の推論タスクです。Clark et al. (2018)によって作成されたARC-Challengeというデータセットで、難易度の高い科学的な質問に答える必要があります。
Bioは、伝記の生成タスクです。Min et al. (2023)によって作成されたデータセットで、有名人の名前からその人物の伝記を生成する必要があります。
ASQAは、長文の質問応答タスクです。Gao et al. (2023)によって作成されたALCE-ASQAというデータセットで、長文の質問に対して長文の回答を生成し、回答に含まれる事実に対して引用を提供する必要があります。
SELF-RAG 7Bは、SELF-RAG 13Bを上回ることがある。これは、SELF-RAGが小さいほど、正確な根拠を持つが短い出力を生成する傾向があるためである。Llama2-FT7Bは、SELF-RAGと同じ命令-出力ペアで学習され、検索や内省を行わず、テスト時のみ検索を行うベースラインLMであるが、SELF-RAGに遅れをとっている。この結果は、SELF-RAGの能力が訓練データのみによるものではないことを示し、SELF-RAGフレームワークの有効性を実証している。
Discussion