[論文紹介]VeRA: Vector-based Random Matrix Adaptation
LoRAの派生型PEFT手法であるVeRA: Vector-based Random Matrix Adaptationに関する論文を読んでみたので軽くまとめてみました。
(arxiv:https://arxiv.org/abs/2310.11454)
時間がない方向け
- LoRAの派生型PEFT
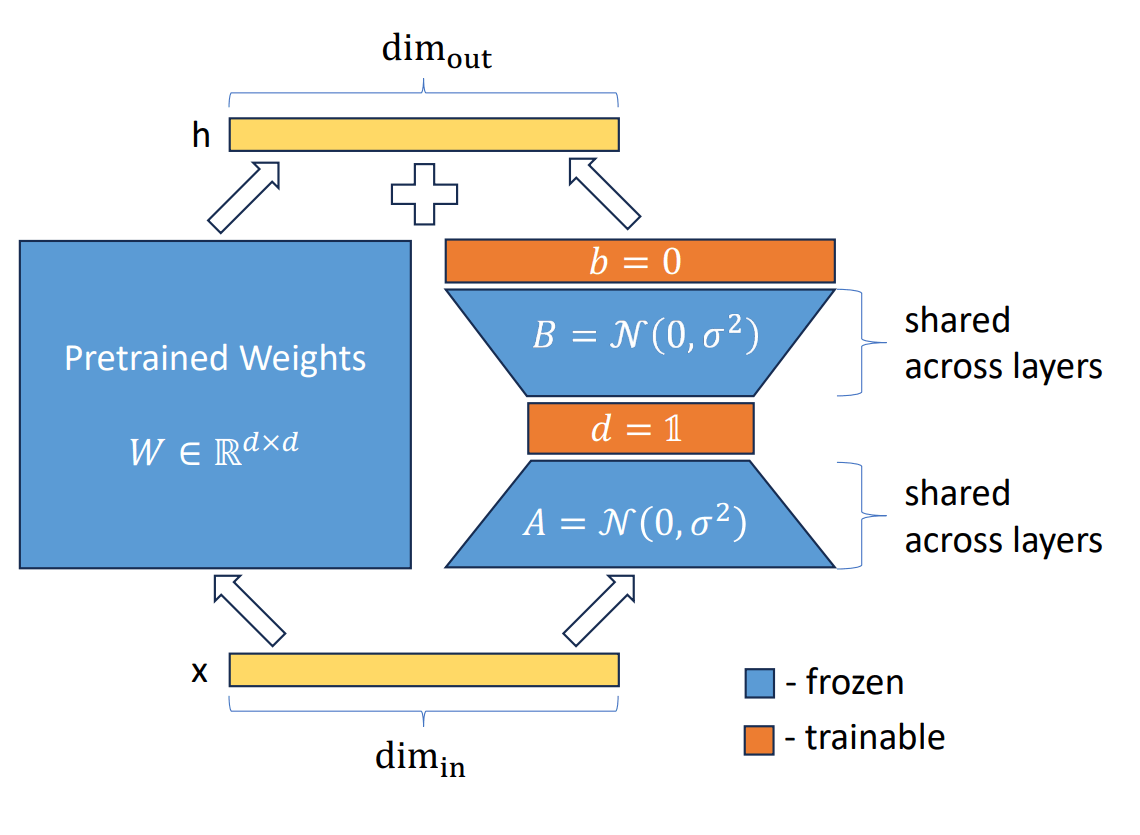
- 上図を見て分かる通り、ベースモデルの層の隣に差分行列を追加し、差分行列のみを微調整するという基本的な構図はLoRAと同じ
- LoRAと比較して学習パラメータ数を10分の1に削減かつ同等の性能を維持
要旨
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which reduces the number of trainable parameters by 10x compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, and show its application in instruction-following with just 1.4M parameters using the Llama2 7B model.
LoRAは、大規模な言語モデルをファインチューニングする際に学習するパラメータ数を削減する一般的な手法であるが、さらに大規模なモデルに拡張する場合や、ユーザ毎やタスク毎に適応したモデルを多数展開する場合には、ストレージに関する深刻な問題に直面する。本研究では、LoRAと比較して学習可能なパラメータ数を10分の1に削減し、かつ同等の性能を維持するVector-based Random Matrix Adaptation (VeRA)を提案する。これは、全層で共有される1組の低ランク行列を使用し、代わりに小さなスケーリングベクトルを学習することで達成される。我々は、GLUEとE2Eベンチマークでその有効性を実証し、Llama2 7Bモデルを用いて、わずか1.4Mパラメータでのinstruction-followingへの応用を示す。
手法
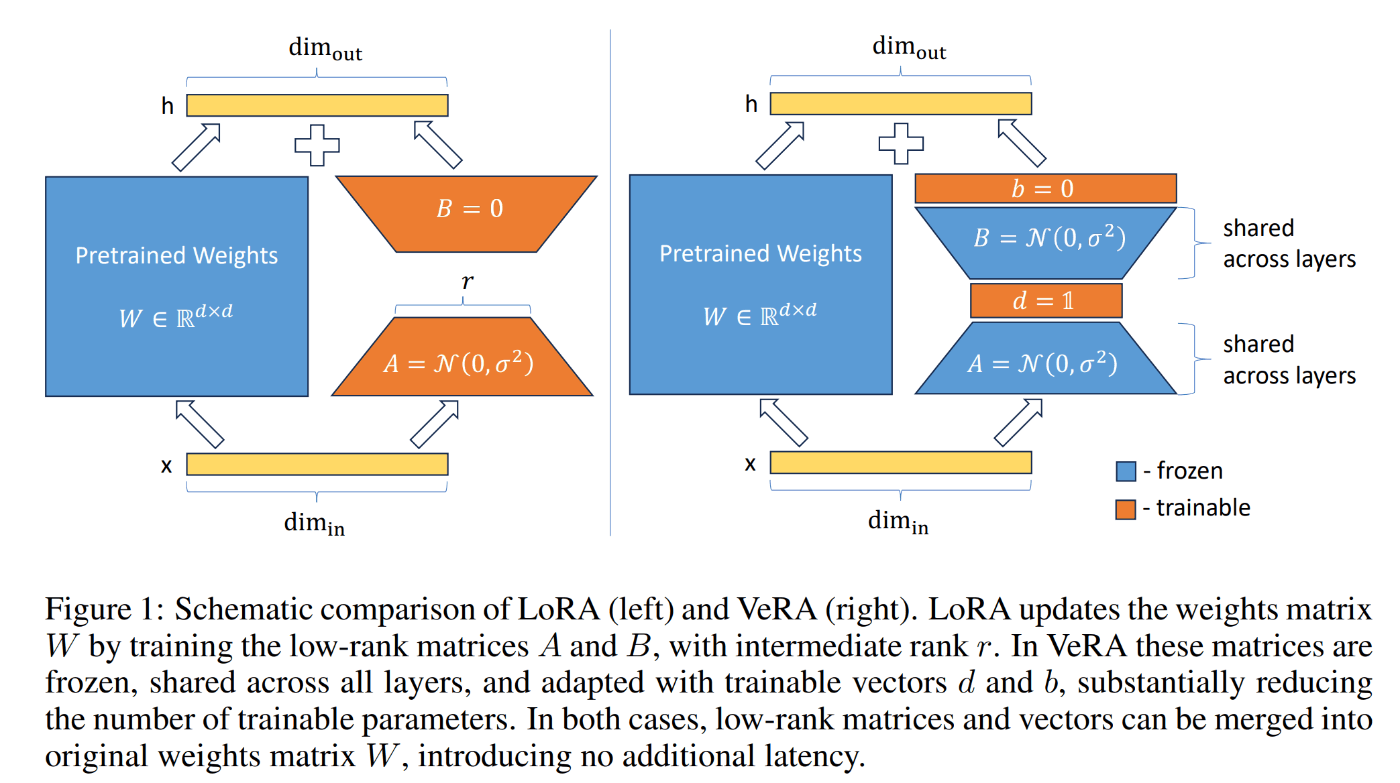
左図がLoRA、右図がVeRA
(復習)LoRAの場合
他のパラメータは固定した上で
を満たすような低ランク行列A,Bのみを学習
VeRAの場合
他のパラメータは固定した上で
を満たすようなベクトル
このアプローチでは、
このアプローチでは、
下表はRoBERTabase,RoBERTalarge,GPT-3各モデルに対し既存手法であるLoRAと本研究の手法であるVeRAを適用した際の理論上のパラメータ数及びその必要メモリ数
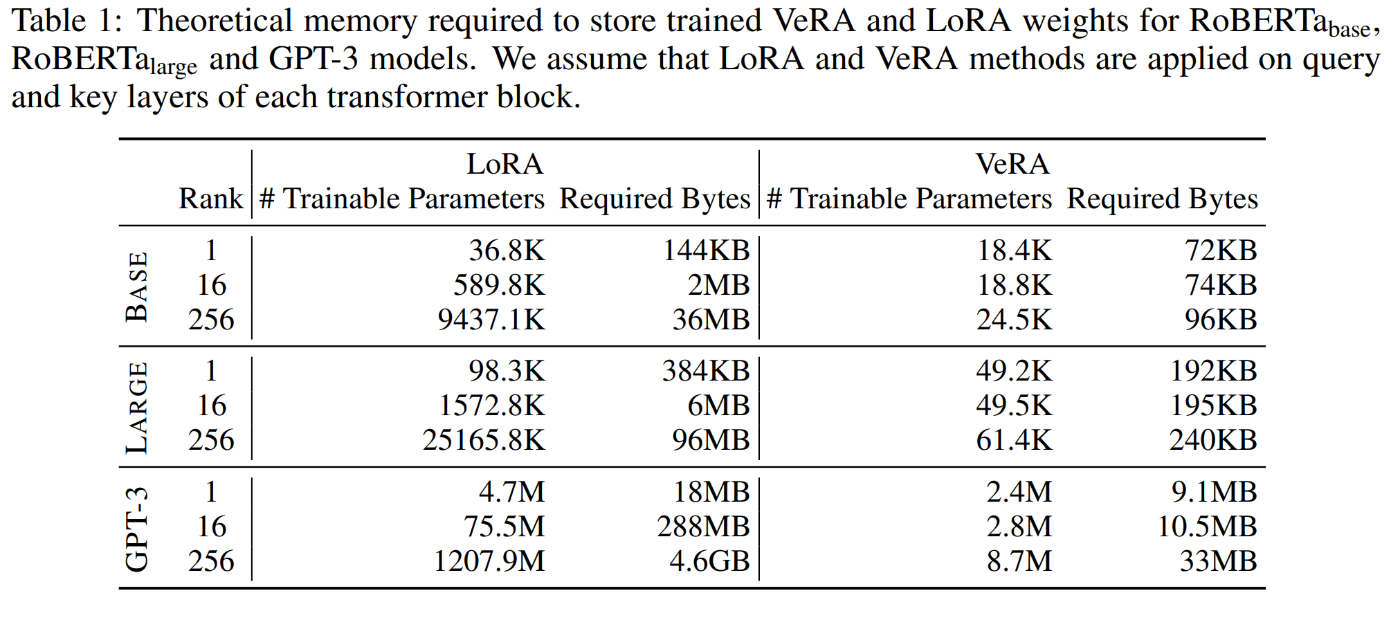
具体的には、最低ランク(すなわち
このパラメータ効率はGPT-3のような大きいモデルでは顕著になる。
VeRAの主な利点は、学習されたウェイト調整を保存するためのメモリフットプリントが最小であること。ランダム凍結行列(
どうやってA,B,b,d初期化しようか
- VeRAでは、行列AとBに対してKaiming initialize(He et al, 2015)を採用する。行列の次元に基づいて値をスケーリングすることで、AとBの行列積がすべてのランクで一貫した分散を維持することを保証し、各ランクの学習率を調整する必要性を排除する。
- スケーリング・ベクトル: スケーリング・ベクトル
b d d A B d
実験
VeRAによるファインチューニングを評価するために一連の実験を行う。
- RoBERTabase及びRoBERTalargeに各ベースライン手法(ベースライン一覧は後述)を適用した際のGLUEおよびE2Eベンチマークの比較
- 1つのタスクを選択し、両手法のランクを変化させ、性能がどのように変化するかを調べる。最後に、ablation studyにより、本手法の各要素の重要性を明らかにする
- Llama2 7Bモデルのinstruction tuning(省略)
ベースライン
- Full finetuning
- Bitfit :バイアスベクトルの微調整のみを行い、他のパラメータはすべて固定とする
- アダプターチューニング :今回はAdapterH,AdapterP,AdapterDの3つのバリエーションで比較
- LoRA
GLUE評価
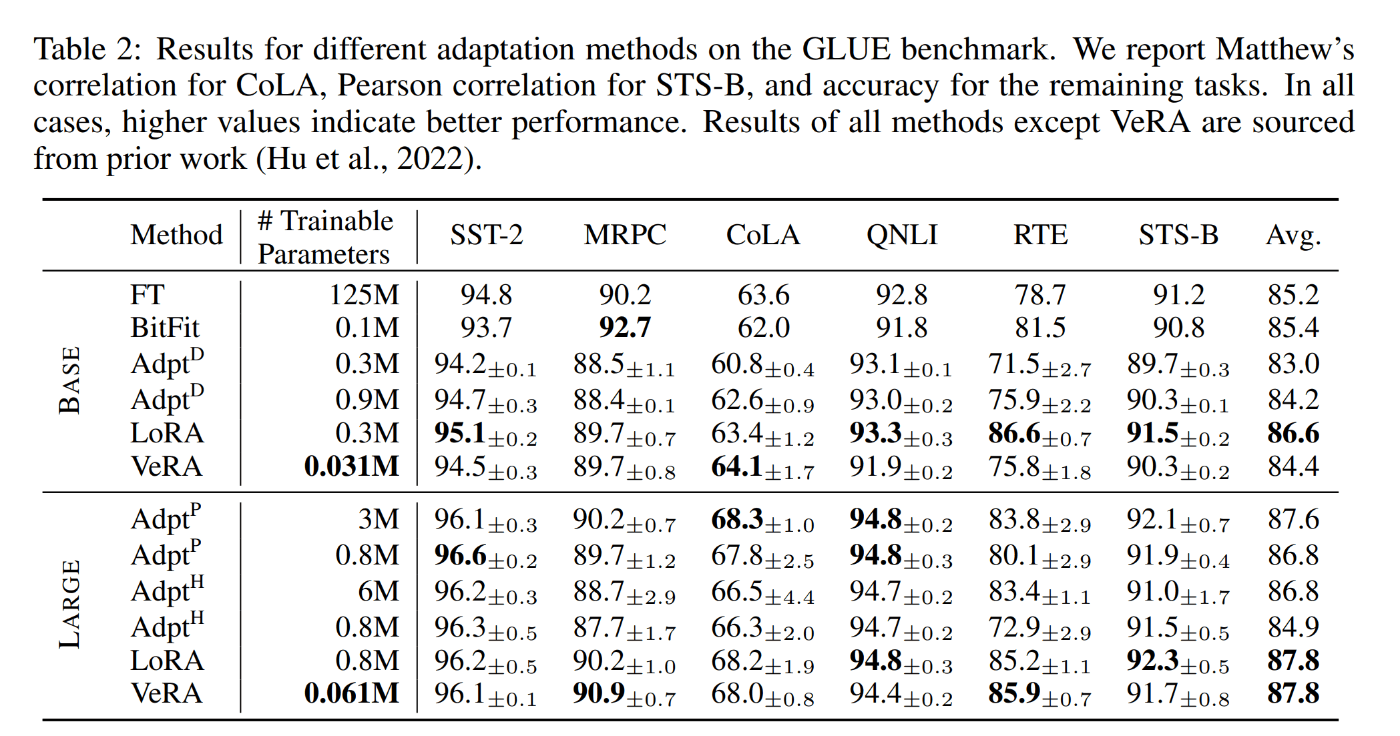
VeRAは両方のモデルにおいて LoRA と同等の性能を示し、しかも桁違いに少ないパラメータでこれらの結果を達成していることがわかる。RoBERTabaseの性能が若干低下したのは、実験で使用した配列長が短くなったためである。相対的には性能向上しているものと考えられる。
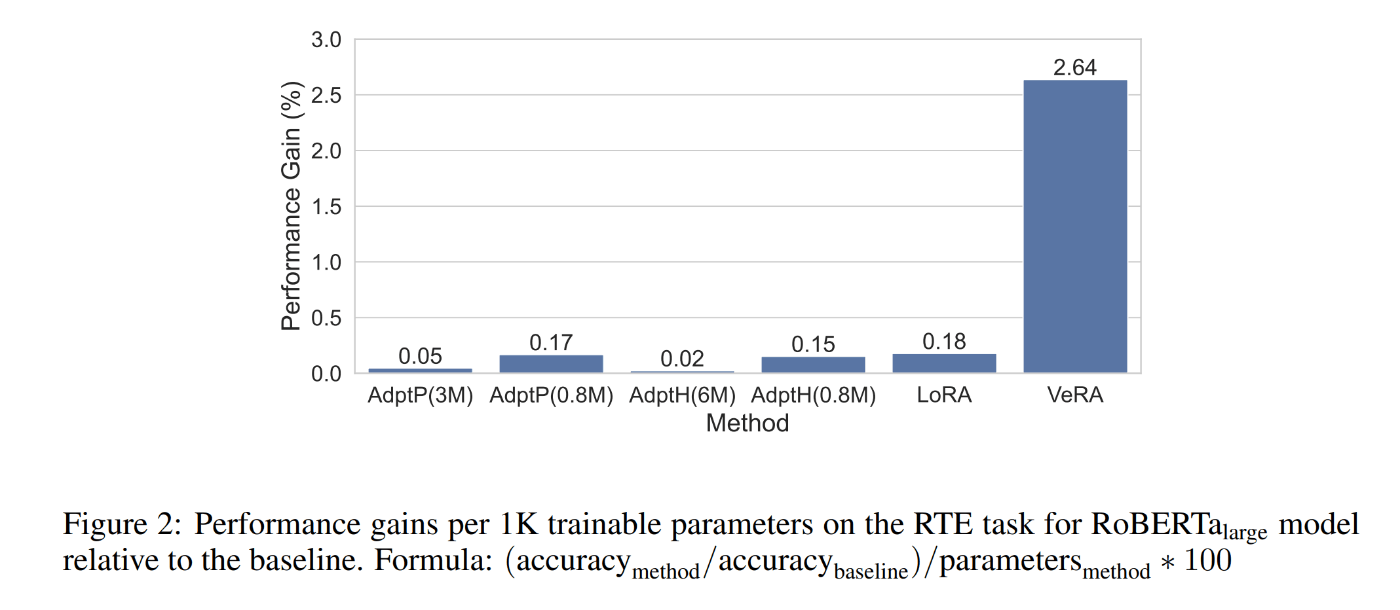
上図は、各手法の効率を、学習可能なパラメータ 1K 個あたりの性能向上という観点から定量化したものである。重点的に比較するために、RTE タスクと RoBERTalarge モデルを選択した。ベースラインを確立するために、分類ヘッドのみを訓練し、残りのモデルは凍結する補助実験を行う。このベースラインは、VeRAと同じハイパーパラメータを用いて構築される。次に、ベースラインに対して、導入された追加訓練可能パラメータによって正規化された、各方法に起因する性能利得を評価する。その結果、VeRAが1K個の訓練可能パラメータあたりで最も高い性能をもたらすことが明らかになった。
E2E評価
E2Eについては、Hu et al.(2022)の実験セットアップに従い、GPT-2 mediumモデルをファインチューニングする。LoRAについては、Huら(2022)で提供された実装とハイパーパラメータのセットを使用し、VeRAについては、ランクと学習率を変更し、その両方を調整する。使用したハイパーパラメータの表は下記トグルへ。

上表はE2Eベンチマークにおける異なる適応手法の結果。アスタリスク(*)が付いた手法の結果は、先行研究からの引用である。VeRAは、LoRAと比較して、学習可能なパラメータが3倍以上少な異にも関わらず他の手法よりも優れている。
使用したハイパーパラメータ

ablation study
手法の各要素の影響を調べるために、MRPC と RTE タスクに焦点を当て、RoBERTalargeモデルを使用して、これまでの実験で使用したハイパーパラメータを用いてablation studyを行う。
1 つは

上表に示すように、どちらかのスケーリングベクトルを省略すると、パフォーマンスが低下する。 only dは、only b 構成よりもわずかに優れたパフォーマンスを発揮する。 このパフォーマンスの違いは、
A,B初期化方法による性能の変化を見る。

どちらのKaiming初期化も一様な範囲の初期化よりも優れていることがわかる

実験では、dInit を
Discussion
誤字脱字・誤り、単純に分かりづらい等、指摘して頂けると幸いです。