🥖
半構造化データのためのRAGの概要
前提
多くの文書には、テキスト、表、画像など、様々な種類のコンテンツが混在
このような半構造化データの解析は従来のRAGにとって困難な場合が多い
- 👎テキストを分割すると表が分断され、検索時にデータが破損する可能性がある。
- 👎表を埋め込むと、意味的類似性検索が困難になる可能性がある。
- 👎画像に含まれる情報は通常失われる。
手法
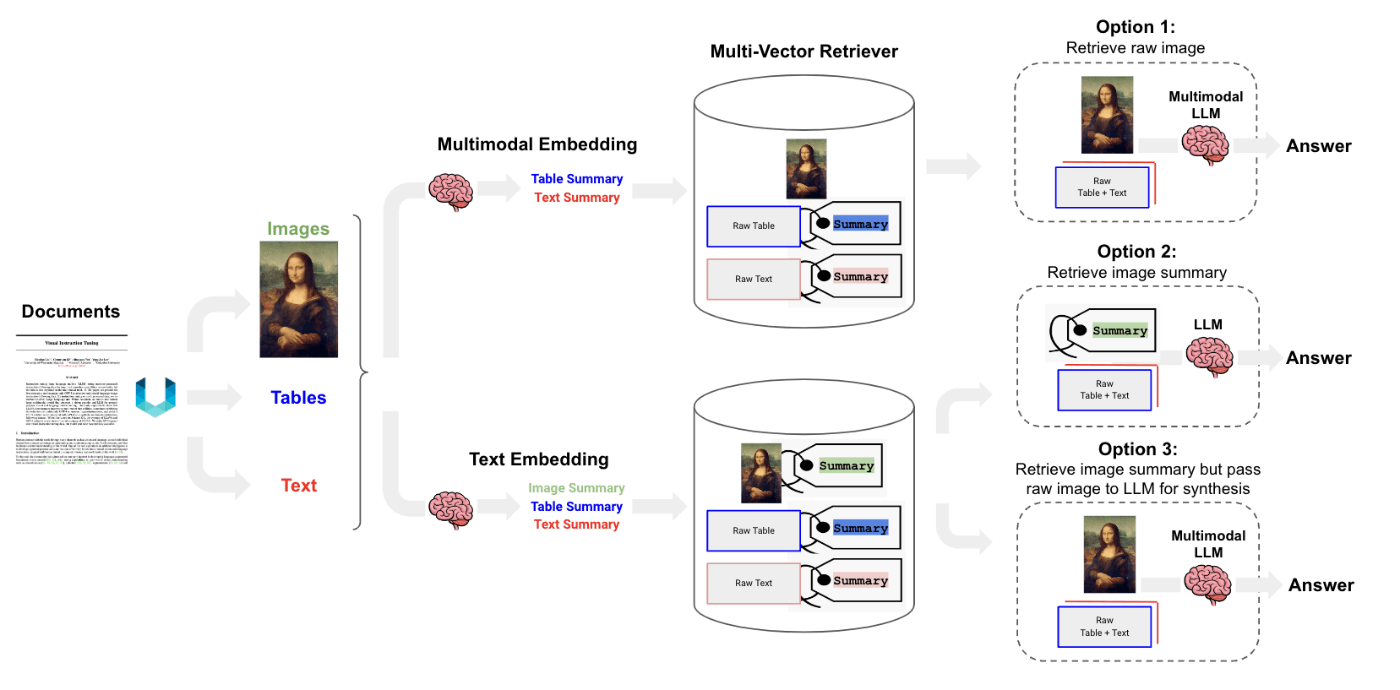
Unstructuredというlangchain,llamaindex外部のAPIを使い、ドキュメント(PDF等)から画像、テキスト、表を解析する。
multi-vector retrieverを使って、生の表、テキスト、(オプションで)画像を、検索用の要約とともに保存する。
選択肢(各選択肢が下画像のoptionに対応)
-
選択肢1:
CLIPなどのマルチモーダルモデルを使い画像とテキストを埋め込み、類似性検索を使って両方を取得。生の画像とテキストチャンクをマルチモーダルLLMに渡し、回答を生成する。 -
選択肢2:
マルチモーダルLLM(GPT4-V、LLaVA、FUYU-8bなど)を使って、画像からテキスト要約を生成し、テキストを埋め込み、取得。テキストチャンクをLLMに渡し、回答を生成。 -
選択肢3:
マルチモーダルLLM(GPT4-V、LLaVA、FUYU-8bなど)を使って、画像からテキスト要約を生成する。
生画像と画像要約を埋め込み、取得する。生画像とテキストチャンクをマルチモーダルLLMに渡し、回答を生成する。
参考
Discussion