facefusionを用いてdeepfake動画を作成する
おはこんばんにちは。
最近、AIやdeepfake, ML周りを触っているYです。
今回はdeepfake動画を簡単に作成できるfacefusionというオープンソースプロジェクトの使用方法について解説していきます。
※pythonを軽く触ったことがあるという前提
1. 環境構築
今回はPCのスペック差もあるかと思いますので、クラウド上での実行を想定してセットアップを行います。(要領的にはローカルも同様)
まず、本記事ではPaperspaceというクラウドGPUサービスを使用します。
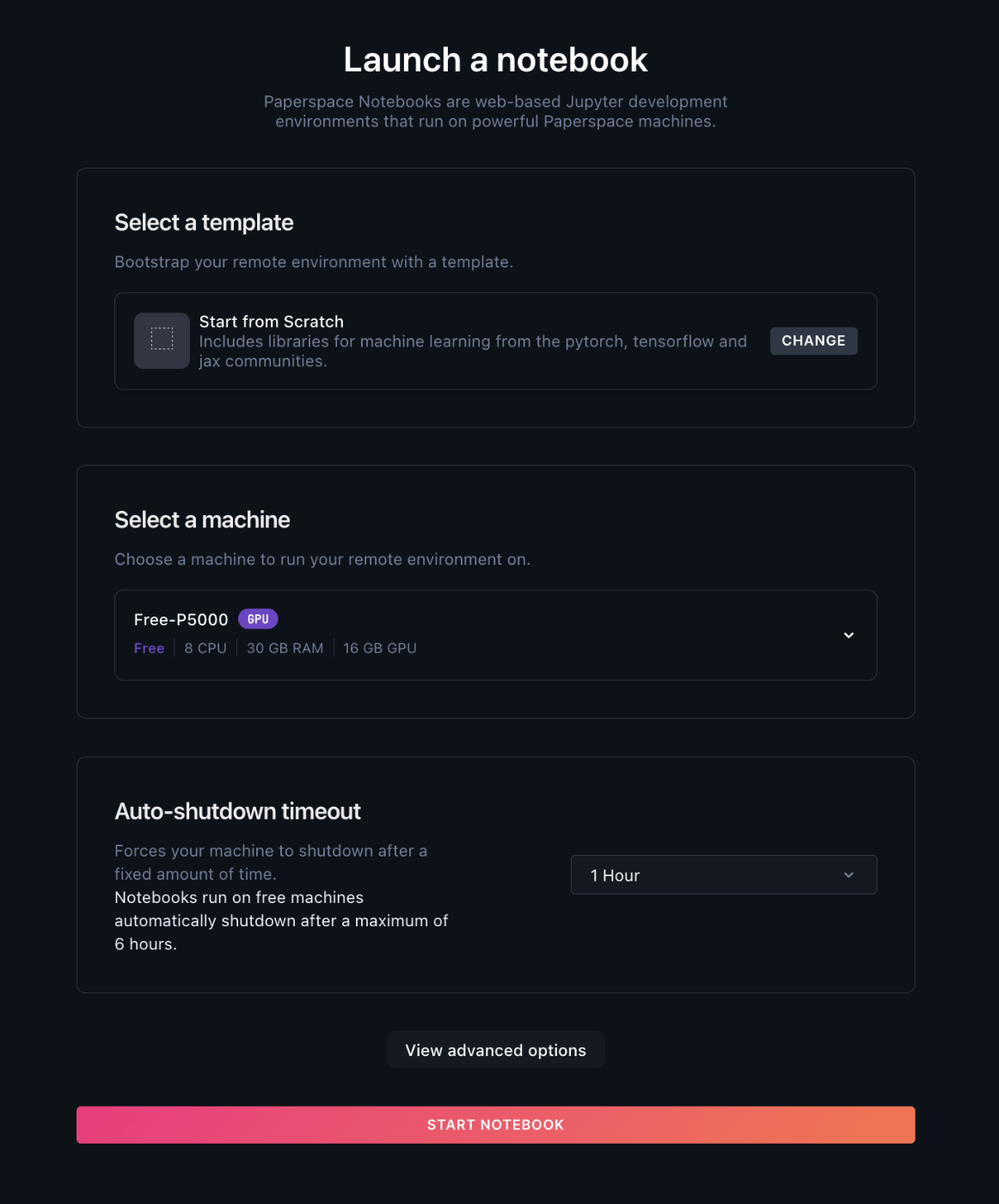
サインアップが完了しましたら、MLGradientにて新規でprojectを作成し、notebookを立ち上げましょう。
今回使用するmachineは無料枠のP5000です。
(なお、FREEプランの場合マシン自体の無料枠が見当たらなかった為、クレジットバランス内での使用を行えば大丈夫かと思われます)
そして、startしましたらターミナルを開き仮想環境を立ち上げ、facefusionをgitcloneします。
プロジェクトファイルのfacefusionに移動して必要なパッケージ類をインストールします。
requirements.txtに格納されているため、そちらを使用してください。
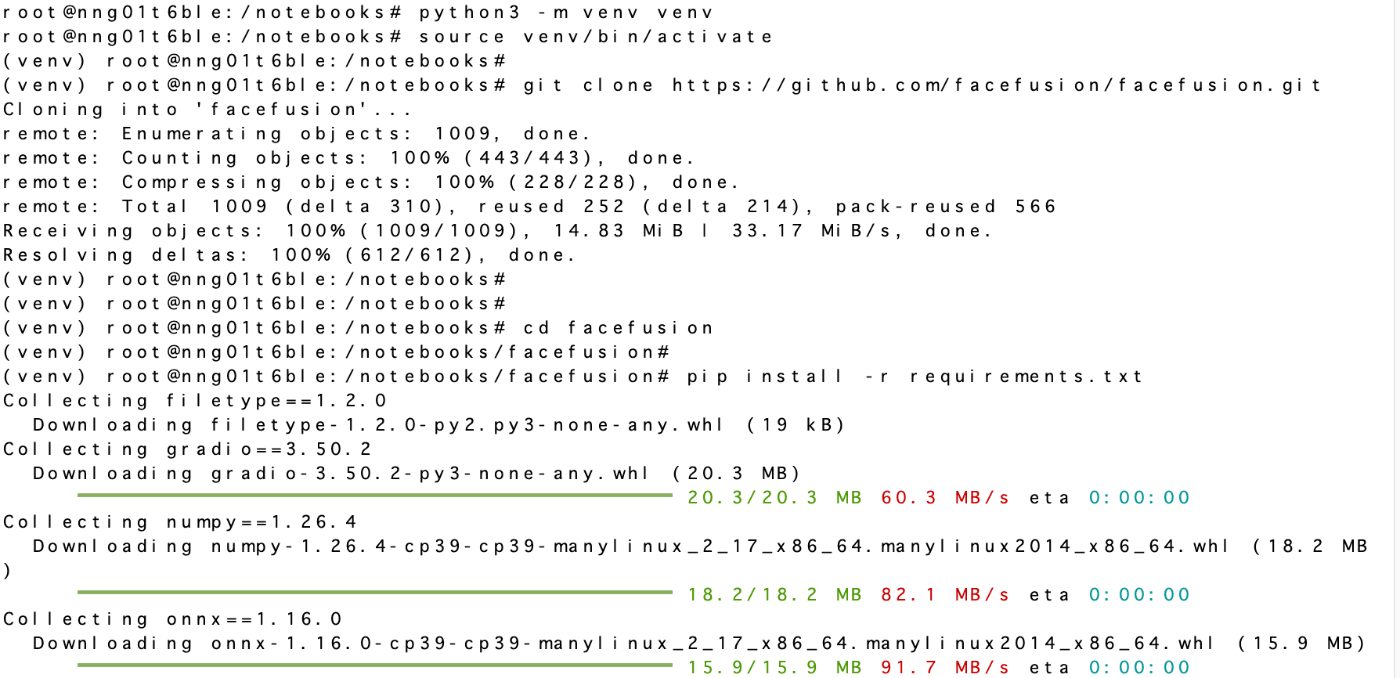
また、cudaエンコーダを使用するためのパッケージが入っていないみたいなので、下記コマンドでインストールしてください。
python install.py --onnxruntime cuda-11.8
2. 実行
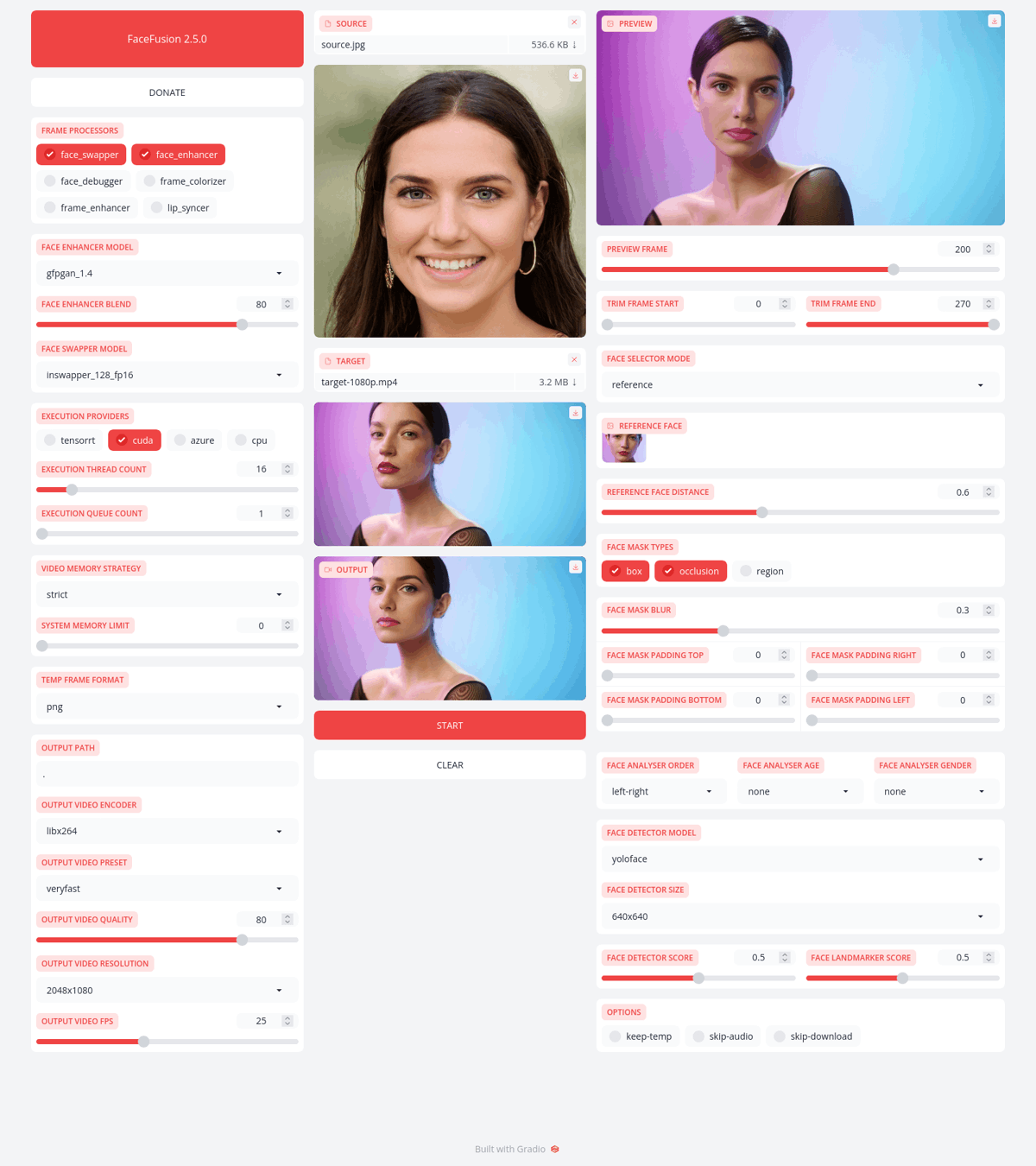
パッケージインストールが完了しましたら、実際にファイルをアップロードして実行していきます。
facefusionのディレクトリ内にinput, outputのフォルダを新規作成し、deepfake加工を行う元動画ファイルとfaceswapする画像をinputフォルダ内にアップロードしてください。

今回はvitalikを元動画として使用します。
なお、画像は危機感ニキでお馴染みのジョージコーチを使いますw

そして、下記コマンドで実行を行います。
(ファイル名はそれぞれ合わせてください)
python3 run.py --source input/face.png --target input/video01.mp4 --output /notebooks/facefusion/output/swapped.mp4 --frame-processors face_swapper face_enhancer --face-enhancer-model gpen_bfr_512 --execution-providers cuda --headless
そして、実際に出力されたものがこちらになります。
3. 更なるクオリティを求めて
さらにクオリティを向上させるために、face_swapperの学習モデルを色々トライしてテストしていきます。
下記リンクの公式docにてconfigできます。
それは僕も同意見ですので、別の動画をサンプルとして使用させていただきます。
今回のテストで使用する動画はこちらです。
そして、個人的に藤咲凪さんが好みですので下記のツイート画像を使用させて頂きます。
テスト1 blendswap_256 + enhancer-blend 100
まぁ割といいですね。
ただ、目の箇所や涙袋あたりが凪さんの要素として入ってないようにも見えます。
テスト2 simswap_256 + enhancer-blend 100
はい。
プラシーボ効果が効いてるのか、そう思えば変化してます。
次に移ります。
テスト3 inswapper_128_fp16 + enhancer-blend 100 + real_esrgan_x4_fp16
お、いい感じ。
目の感じが上手いこと取れてるように思えます。
そして、frame_enhancerのmodelを標準の上位互換であるx4_fp16に変更しました。
全体比較
blendswapとsimswapの違いは特に無いですが、inswapperがやはり強いですね。
元動画とinswapperの比較画像からも違いがわかるかと思います。

4. 最後
以上がfacefusionを用いたdeepfake動画の作成方法でした。
割と簡単に作成でき、通常のパッケージ化されたアプリやソフトでするよりも、無料でこの自由度が実現されているのは感激です。。
また、本記事ではクラウドサービス上での構築と実行を行いましたが、ローカル環境ですとWebUI上で操作ができるみたいなので、高性能なGPUをお持ちでしたらそちらで行ったほうが良いかもしれません。
では、お疲れ様でしたー。
Discussion
現在でも上記の方法で動いていますか?
"python install.py --onnxruntime cuda-11.8"
を実行するとエラーが起き inquirer のインストールを促され、インストール後は
"Conda is not activated"
という文言で停止します。
現状、" --execution-providers cuda" を " --execution-providers cpu" に変更して実行できてはいます。
PaperspaceのGPUはA4000、VENV環境下です。