gpt-oss-20b x Mem32GB + RTX3060Ti 8G の環境で少し快適に動いたメモ(LM Studio)
はじめに
gpt-oss-20b をなぜローカル環境で動かしたいのか?
個人的にClaudeに課金して開発に利用していますが、納得のいくアプリケーションが実装できるまで、何度も会話の分岐を繰り返します。気づいた時には完成していないにも関わらず課金を使い切り、後には引けない状況になっていることがあります。そのため、生成AIを利用してアプリケーション開発をしていると、正直、何も学びが無いまま、時間とお金を浪費している虚無感に襲われることがあります。
前回は、Ollama で何も調整しない状態では、快適には使えませんでした。
しかし、LM Studio - Blog - 2025-08-12 LM Studio 0.3.23 を確認していると "Force Model Expert Weights onto CPU" というオプションが追加され、簡単に設定できるようなので試してみました。
Blog抜粋翻訳:
これは、モデル全体をGPU専用メモリにオフロードするのに十分なVRAMがない場合に便利です。その場合は、高度なロード設定で「モデルエキスパートのウェイトをCPUに強制的に適用」オプションをオンにしてみてください。
試した環境
- Windows11
- CPU:i7-11700
- Memory:32GB
- GPU:NVIDIA GeForce RTX 3060 Ti 8GB
- LM Studio(0.3.23) + gpt-oss-20b
結論
ローカルで動かしていると思えば、許容できる速度で使える!
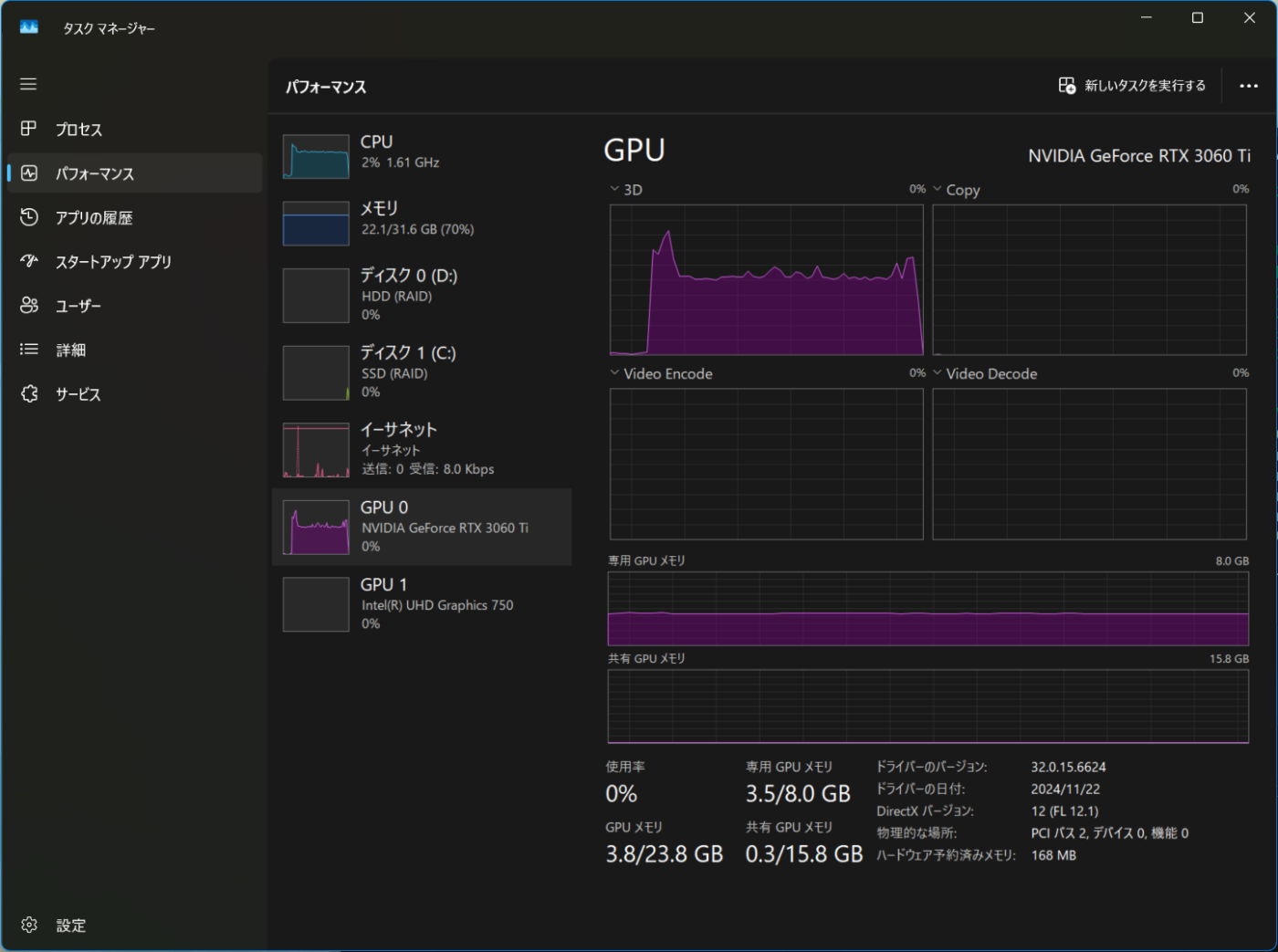
動作している状態でのパフォーマンス
LM Studio での設定
モデルを選択し、以下の項目を変更する
- Offload KV Cache to GPU Memory : ON -> OFF
- Force Model Expert Weights onto CPU : OFF -> ON

モデルへの設定
利用した感想
- javaアプリケーションを実装したが、レスポンスを全て出力するまでの体感は良くない
- 4分程度待たされるが、正確なソースコードが出力、実際に修正無く動作確認ができている
- チャット履歴フォルダ : C:\Users\ユーザ名.lmstudio\conversations
- ログの stats 情報サマリを確認
| tokens/s | FirstToken | totalTime | promptTokens | predictedTokens | totalTokens |
|---|---|---|---|---|---|
| 11.7/s | 1.6s | 3.7s | 68 | 43 | 111 |
| 8.3/s | 1.6s | 201.4s | 765 | 1,667 | 2,432 |
| 7.9/s | 1.7s | 222.0s | 1459 | 1,765 | 3,224 |
※列名は表示幅に収まるように部分省略
※numGpuLayers=-1 のため省略
環境構築メモ
LM Studio は初めて利用するのですが、インストール後の操作は非常に分かりやすく、すぐに構築することができました。
LM Studio のダウンロードとインストール
- https://lmstudio.ai/ から Windows版のダウンロード(現在:0.3.23)
- LM-Studio-0.3.23-3-x64.exe を実行するとインストールが開始

インストール開始
インストール先を選択

インストール完了
LM Studio 初回起動

Power User を選択

モデルダウンロード画面は skip (ここで Download しても問題はないが)

チャット画面が表示
モデルのダウンロードと設定
- 虫眼鏡アイコンを押下し "model Search" の検索に "gpt-oss" を選択し "OpenAI's gpt-oss 20B" を "Download" する

- フォルダアイコンを押下すると "gpt-oss" がダウンロード済みであることが確認できる
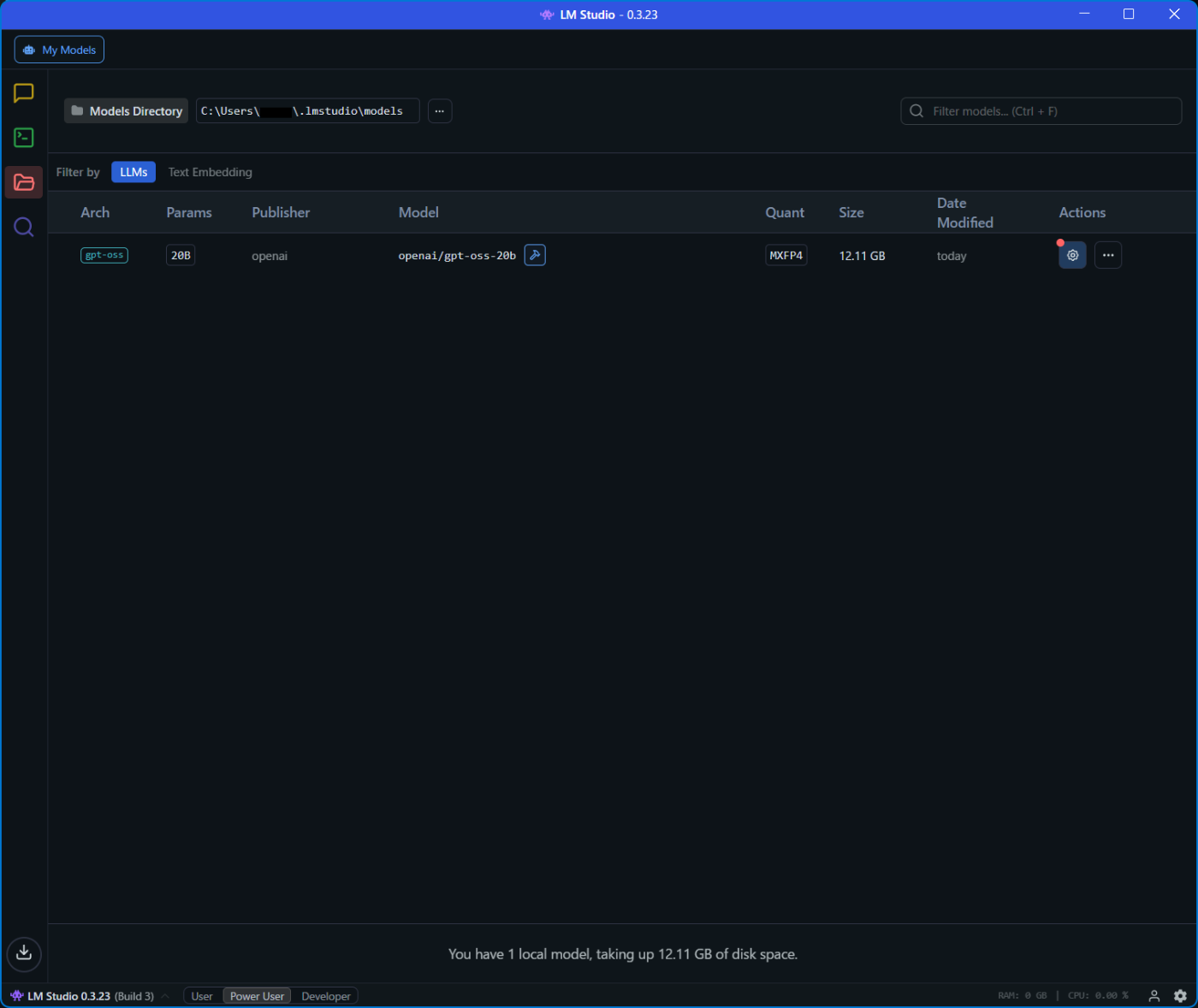
- "gpt-oss" モデルの Actions の歯車アイコンを押下すると設定画面が表示されるので設定を変更する(特にOKとかは無い)
- Offload KV Cache to GPU Memory : ON -> OFF
- Force Model Expert Weights onto CPU : OFF -> ON
チャットの開始
- チャットアイコンを押下し "Select a model to load" からダウンロードしたモデル "gpt-oss" を選択する
- "gpt-oss" のロードが開始される

Select a model to load からモデル選択
モデルロード中

チャット可能

設定を変更せずに起動した場合はエラーが発生
まとめ
使える?レベル感で生成AIが動作してくれるようになりました。このスペックで使えるのは素晴らしいことです。120bも試してみましたが、そこまで甘くは無かったです。
目的はアプリケーション開発への適用なので、今後は VSCode と統合して使えるようにし、ローカルで完結した開発環境を構築していこうと思います。
今回、設定を色々試している間に、システムリソースを使い切り、PC の画面が真っ暗/真っ白になったり、フリーズして操作不能になったり、勝手に強制終了する状況が続きました。自動的にリソースリミットのガードがかかるようにして欲しいですね。
Discussion