Python 3.13のFree-Threadingを試してみた
環境の準備
自らビルドする方法もあるが、pyenvでFree Threadingのビルド版があったので利用する。
pyenv 3.13.0b4tを利用する
(8/2あたりに3.13rc1がリリースされたようですが、まだpyenvは無かった。)
他にも各種linuxディストリビューション、condaでもインストール可能になるようだ
計測環境について、
MacBook Air M1, 2020
CPU arm64 8コア
メモリ 16GB
OS Sonoma 14.5
ベンチマーク
3.13のスレッド処理の高速化確認
まずは、こちらを参考にCPUバウンドの比較から行います。
ベンチマークのコードはこちらを参考にしています。

GIL(Global Interpreter Lock)ロックのため、マルチスレッドではCPUを取り合ってしまいましたが(上の図)、3.13ではGIL回避の対応が入り、マルチスレッドにおいて複数CPUを別々に使うようになります。

CPUバウンド比較
まずはCPUに負荷がかかるベンチーマークから確認してみる。
(何回か試行して一番良い結果を貼っています。数回施行した平均とかはしていません。
目安として確認いただければと思います。)
ある数が素数かどうか判定するコードでベンチマークしています。
ある数が素数かどうか判定する。1/nまでの整数で割り切れるか(スレッド利用)
# test_gil.py
from concurrent.futures import ThreadPoolExecutor
import time
import math
def get_primes(max: int) -> list[int]:
# (あえて低速な) n以下の素数一覧を返す関数
if max < 2:
raise ValueError()
primes = [2]
for n in range(3, max + 1):
is_prime = True
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
is_prime = False
break
if is_prime:
primes.append(n)
return primes
if __name__ == "__main__":
print("concurrency,time")
for concurrency in range(1, 10 + 1):
start = time.monotonic()
with ThreadPoolExecutor(max_workers=concurrency) as executor:
futures = [executor.submit(get_primes, 500000) for _ in range(concurrency)]
for f in futures:
f.result()
end = time.monotonic()
duration = end - start
print(f"{concurrency},{duration:.2f}")
python 3.12 vs 3.13t
3.12 マルチスレッド
1サンプルの計測時間
➜ py13-free-threading pyenv local 3.12.4
➜ py13-free-threading python test_gil.py
concurrency,time
1,0.76
2,1.54
3,2.30
4,3.07
5,3.84
6,4.81
7,5.44
8,6.19
9,6.91
10,7.71
7.71秒
3.12ではGILのため、CPUが1つしか使われず遅いです。
3.13t マルチスレッド
1サンプルの計測時間
➜ py13-free-threading pyenv local 3.13.0b4t
➜ py13-free-threading python test_gil.py
concurrency,time
1,0.92
2,0.93
3,0.97
4,1.02
5,1.33
6,1.51
7,1.98
8,1.99
9,2.26
10,2.39
2.39秒
マルチプロセッシング vs マルチスレッド
素数判定のマルチプロセス版
# test_gil.py
from concurrent.futures import ProcessPoolExecutor
import time
import math
def get_primes(max: int) -> list[int]:
# (あえて低速な) n以下の素数一覧を返す関数
if max < 2:
raise ValueError()
primes = [2]
for n in range(3, max + 1):
is_prime = True
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
is_prime = False
break
if is_prime:
primes.append(n)
return primes
if __name__ == "__main__":
print("concurrency,time")
for concurrency in range(1, 10 + 1):
start = time.monotonic()
with ProcessPoolExecutor() as executor:
futures = [executor.submit(get_primes, 500000) for _ in range(concurrency)]
for f in futures:
f.result()
end = time.monotonic()
duration = end - start
print(f"{concurrency},{duration:.2f}")
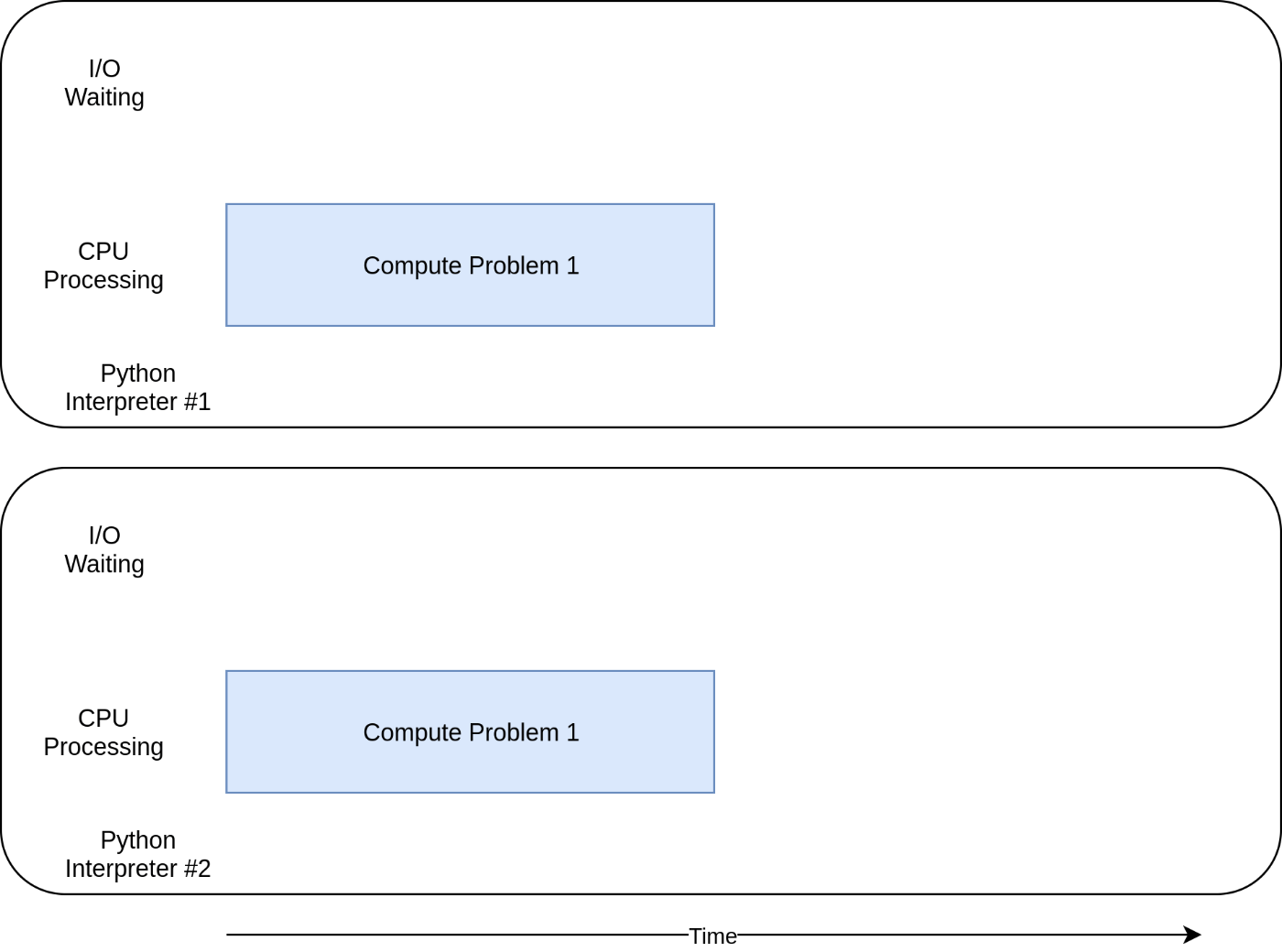
Pythonインタープリタごとにプロセスが起動して、処理される
3.12 マルチプロセス
1サンプルの計測時間
➜ py13-free-threading python test_gil-multi-proc.py
concurrency,time
1,0.99
2,0.82
3,0.84
4,0.84
5,1.02
6,1.09
7,1.20
8,1.33
9,2.06
10,2.09
2.09秒
3.13t マルチプロセス
1サンプルの計測時間
➜ py13-free-threading python test_gil-multi-proc.py
concurrency,time
1,0.98
2,1.00
3,1.03
4,1.10
5,1.30
6,1.45
7,1.64
8,1.94
9,2.74
10,2.80
2.8秒
3.12のマルチプロセスより劣化している。まだベータ版なので、正式リリースでは改善を期待したい。
I/Oバウンド比較
(全般的にこちらの図を使わせてもらっています。)
ベンチマークのコードはこちらを参考にしています。
複数のwebサイトをスクレイピングする処理
3.12 シングルスレッド
スクレイピング シングルスレッド
import urllib.request
import time
URLS = ['https://www.foxnews.com/',
'https://www.cnn.com/',
'https://www.yahoo.co.jp/',
'https://www.bbc.co.uk/',
'https://www.google.co.jp/',
'https://www.reddit.com/',
'https://prtimes.jp/',
'https://www.gizmodo.jp/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def get_detail():
# Start the load operations and mark each future with its URL
for url in URLS:
try:
data = load_url(url,60)
except Exception as exc:
print(f'{url} generated an exception: {exc}')
else:
print(f'{url} page is {len(data)} bytes')
def main():
startTime = time.time()
get_detail()
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()

1サンプルの計測時間
➜ py13-free-threading python io-wait-single-th.py
https://www.foxnews.com/ page is 691131 bytes
https://www.cnn.com/ page is 3052649 bytes
https://www.yahoo.co.jp/ page is 34216 bytes
https://www.bbc.co.uk/ page is 589274 bytes
https://www.google.co.jp/ page is 20705 bytes
https://www.reddit.com/ page is 612757 bytes
https://prtimes.jp/ page is 311236 bytes
https://www.gizmodo.jp/ page is 94070 bytes
Time:2.546834945678711[sec]
2.54秒
3.12 マルチプロセス
まず、GILの制約がないマルチプロセスを、concurrent.futuresで試します
スクレイピング マルチプロセス
import concurrent.futures
import urllib.request
import time
URLS = ['https://www.foxnews.com/',
'https://www.cnn.com/',
'https://www.yahoo.co.jp/',
'https://www.bbc.co.uk/',
'https://www.google.co.jp/',
'https://www.reddit.com/',
'https://prtimes.jp/',
'https://www.gizmodo.jp/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def get_detail():
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ProcessPoolExecutor() as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print(f'{url} generated an exception: {exc}')
else:
print(f'{url} page is {len(data)} bytes')
def main():
startTime = time.time()
get_detail()
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()

IOごとにプロセスを立てて、IOの応答をそれぞれ待つ仕組み
IO待ち程度でプロセスを起動するのはコストパフォーマンスは悪そう
1サンプルの計測時間
➜ py13-free-threading python io-wait-multi-proc.py
https://prtimes.jp/ page is 311307 bytes
https://www.yahoo.co.jp/ page is 34216 bytes
https://www.bbc.co.uk/ page is 589436 bytes
https://www.google.co.jp/ page is 20627 bytes
https://www.foxnews.com/ page is 691458 bytes
https://www.gizmodo.jp/ page is 93725 bytes
https://www.cnn.com/ page is 3052649 bytes
https://www.reddit.com/ page is 615509 bytes
Time:1.6700940132141113[sec]
1.67秒
3.12 マルチスレッド
GILの制約があるマルチスレッドですが、I / Oは制約が解除されます
スクレイピング マルチスレッド
import concurrent.futures
import urllib.request
import time
URLS = ['https://www.foxnews.com/',
'https://www.cnn.com/',
'https://www.yahoo.co.jp/',
'https://www.bbc.co.uk/',
'https://www.google.co.jp/',
'https://www.reddit.com/',
'https://prtimes.jp/',
'https://www.gizmodo.jp/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def get_detail():
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=6) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print(f'{url} generated an exception: {exc}')
else:
print(f'{url} page is {len(data)} bytes')
def main():
startTime = time.time()
get_detail()
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()

IOごとにスレッドを立てて、IOの応答をそれぞれ待つ仕組み
プロセスよりは省エネ
1サンプルの計測時間
➜ py13-free-threading python io-wait-multi-th.py
https://www.google.co.jp/ page is 20588 bytes
https://www.foxnews.com/ page is 696088 bytes
https://www.yahoo.co.jp/ page is 34461 bytes
https://prtimes.jp/ page is 310413 bytes
https://www.gizmodo.jp/ page is 93026 bytes
https://www.bbc.co.uk/ page is 589943 bytes
https://www.cnn.com/ page is 3056556 bytes
https://www.reddit.com/ page is 619785 bytes
Time:0.7033240795135498[sec]
0.7秒
3.13t マルチスレッド
1サンプルの計測時間
➜ py13-free-threading python io-wait-multi-th.py
https://www.yahoo.co.jp/ page is 34461 bytes
https://www.foxnews.com/ page is 696088 bytes
https://www.google.co.jp/ page is 20688 bytes
https://www.bbc.co.uk/ page is 589943 bytes
https://www.gizmodo.jp/ page is 91913 bytes
https://www.reddit.com/ page is 619737 bytes
https://prtimes.jp/ page is 310415 bytes
https://www.cnn.com/ page is 3056556 bytes
Time:0.8138542175292969[sec]
0.81秒
asyncioの場合
スクレイピング asyncio
import time
import asyncio
import aiohttp
URLS = ['https://www.foxnews.com/',
'https://www.cnn.com/',
'https://www.yahoo.co.jp/',
'https://www.bbc.co.uk/',
'https://www.google.co.jp/',
'https://www.reddit.com/',
'https://prtimes.jp/',
'https://www.gizmodo.jp/']
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(len(await response.text()), url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
def main():
startTime = time.time()
# get_detail()
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(download_all_sites(URLS))
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()

非同期のIOに対してシングルスレッドで捌く仕組み
一番コストパフォーマンスは良さそう
1サンプルの計測時間
➜ py13-free-threading python io-wait-asyncio.py
Read 279979 from https://prtimes.jp/
Read 589932 from https://www.bbc.co.uk/
Read 86917 from https://www.gizmodo.jp/
Read 696007 from https://www.foxnews.com/
Read 32560 from https://www.yahoo.co.jp/
Read 3038386 from https://www.cnn.com/
Read 20566 from https://www.google.co.jp/
Read 616941 from https://www.reddit.com/
Time:0.6377310752868652[sec]
➜ py13-free-threading python --version
Python 3.13.0b4
0.63秒
数値計算ライブラリをサポート状況
以下に、それぞれライブラリでのサポート状況のissueがあったのでピックアップしてみた
- numpy
No, there is no plan to do that, the first version of NumPy to support Python 3.13 will either be a 2.0.x version or NumPy 2.1 and the first version to support the free-threaded build will be NumPy 2.1.
- pandas
- scikit-learn
まとめ
GIL回避によって高速化がで期待出来るケースは限られるかもしれない。
期待出来るケース
CPUバウンドではGIL回避により、マルチスレッドが正しく並列処理できるようになった。マルチプロセスよりもメモリ効率が良くなる可能性がある。しかし、速度的にはマルチプロセスと同等か少し速い程度かもしれない。マルチスレッドなライブラリは限られる。
マルチスレッドの分析webフレームワークstreamlitにおいて、CPUに負荷をかける処理では十分な期待が持てる。
期待できないケース
一般的なwebフレームワーク(django、fastapi(starlette)、flask)、分析webフレームワークdash(flask)では、ASGI(asyncio対応)/WSGIのマルチプロセスが標準になっている。マルチスレッド対応は効果が薄そうだ。
IOバウンドではマルチスレッドの効果は元々、IO制約の解除により出せていたが、さらに微増の高速化の期待が出来る。ただし、IOバウンドでは他に非同期処理のasyncioでも十分良い性能が出せることが分かっているため、マルチスレッドの期待は薄い。
CPUバウンドな数値計算処理は、外部のライブラリに任せていることが多い。その中でCやRustの内部処理実装に任せている箇所は速いが、そうではない箇所のボトルネックで、スレッドセーフなマルチスレッドが使えれば効果が出そうだが、そのような箇所はあるのだろうか疑問に思う。
Discussion