実録!ChatGPTに正規表現エンジンを作らせたら、衝撃の結末が待っていた件について
この記事は Go Advent Calendar 2022 11日目の穴埋め記事です。
Intoroduction
巷で噂のChatGPTさんはGo言語も書ければ、コードレビューまでしてくれるらしい!
そうか、この世はもうAIの時代なんか……この1年1行も実装が進められていない自分なんかよりも、ChatGPTさんに書いてもらったほうがよっぽど人類の役に立つものを作ってくれるに違いない!
というわけで、去年作ったGo言語による正規表現エンジンをChatGPTさんに作ってもらうことにしました。
思い立ったが吉日。早速OpenAIのアカウントを作ってきました。
以下、ChatGPTさんと筆者のはじめてのやり取りを、筆者によるコメンタリーとともに全編ノーカットでお送りします。
Dialogue

正規表現エンジンを作るという発言に対して「標準ライブラリ使っとけや」という回答。
ド正論です!!
まったくもってそのとおりです。99%の人間はGo標準の正規表現ライブラリを使った方が絶対幸せになれます。
しかも、いきなり否定するのではなく「非常に面白い課題です」と好意的な返しをしてからのやんわりとした否定!ChatGPTさん、人間が出来すぎてないか?
しかし、そんなのChatGPTさんの制止を無視して、まずは要件定義をしてみましょう。

なかなかいいですね。
しかしここでも「DFAとかNFAの勉強がいるから大変だよ?やめといたら?」とやんわりと止めに入ってきました。
ここはちょっと知識をひけらかして、こちらの実力をChatGPTさんにわからせてやるとしましょう。

あ、ウン……そうだね……その情報の大半、今俺が言ったことだけれども…
気を取り直して、APIを設計に進みましょう。
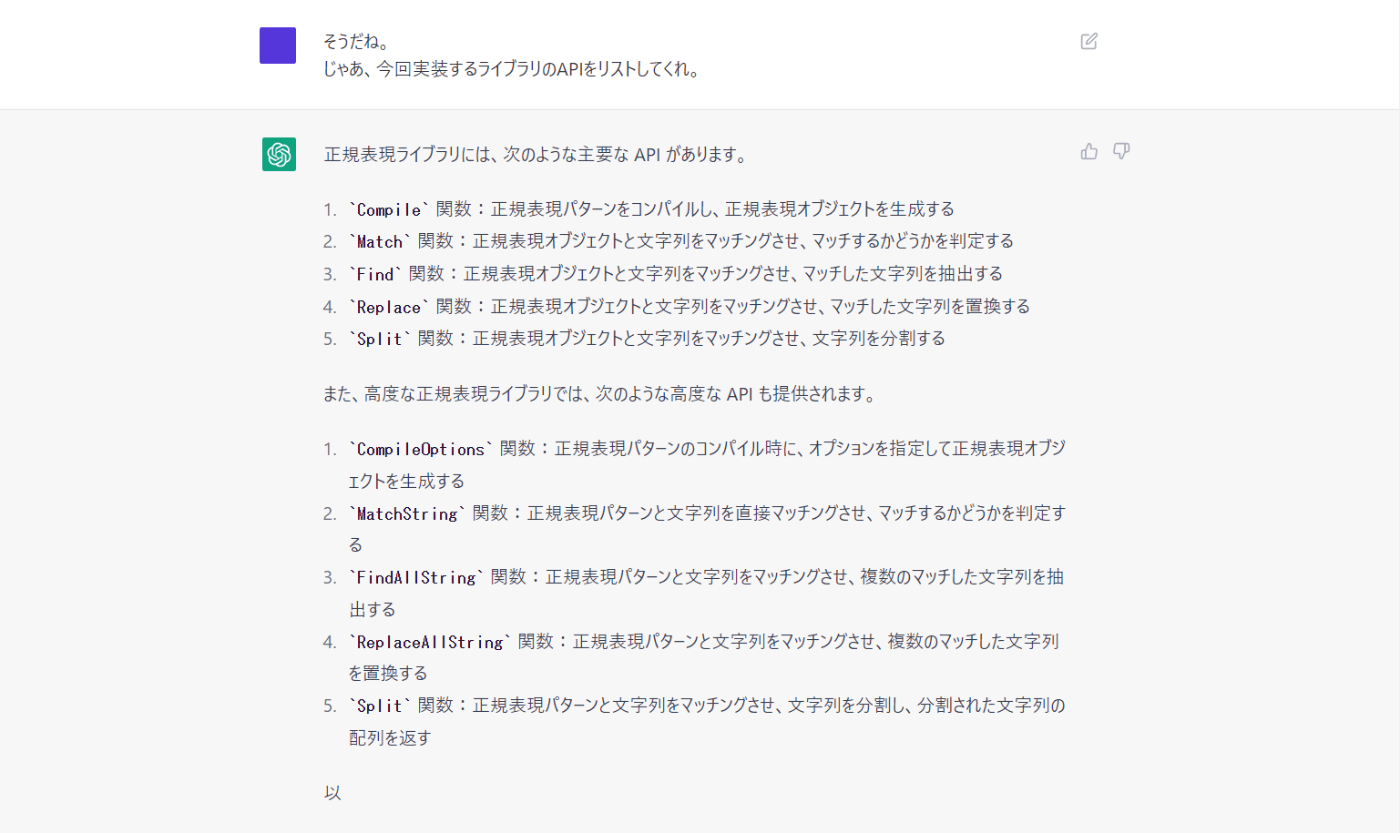
おおー、標準の正規表現APIをそのまま持ってきた感じね。
でも、APIなんだから型も書いておいてほしいな。



APIリファレンスだけでなく、使用例まで出してくれるとは・・・素晴らしい。
こんな気が利く開発者、もし自分が雇用主だったら即採用しちゃうよね・・・
でも、 バックトラッキングNFAで実装することを提案したのは俺だけどな!
まぁ、ここは大人の対応力でスルーして、テストコードを用意しましょう。

うん、パッと見いいんだけど、マッチしない場合のテストケースも入れとかないとね。
そうじゃないと、 return true; ってだけの実装でテストが通っちゃうからね。

素晴らしい・・・リテイクに対しても素直だし、仕事も速い!
そんじゃ、とりあえずこのテストコードが通るようなミニマルなコードからはじめていきましょうか。


ん?お?なんかいきなり壮大なもの作り始めたぞ?最初はもっとしょぼい実装からはじめて、インクリメンタルに進めていく感じでも良かったのに・・・
まぁ、とりあえず見守るとしますか。(convertToDFA とか runDFA とかいう文字が見えて、なんか不穏な空気がただよってるけど…)

なんか表示がくずれた。
どうやら会話が途中で切れたために、インデントがおかしくなったらしい。
(ChatGPTのバックエンドはMarkdownを出力してるのか?🤔)
読みにくいが、ひとまず「続けて」を繰り返して、すべてコードを出力させることにしよう。
(※出力されたコード全文は こちら にあります。





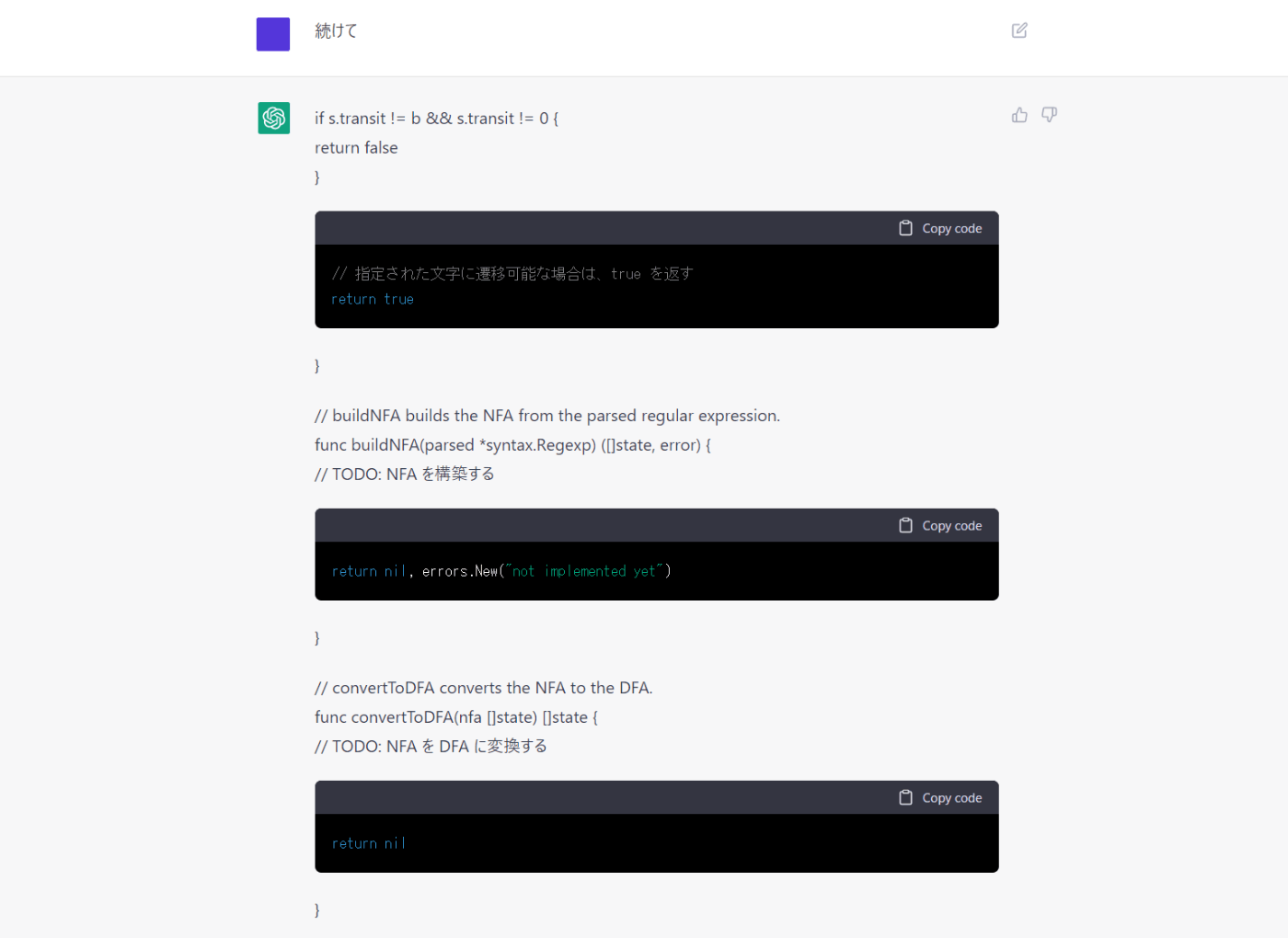
ん!?TODO…だ…と……!?

え!これで終わり!?一番大事なとこが実装されてないじゃん!
というわけで、すかさずクレームをつけます。

TODO: ASTのノードから、NFAのステートを作成する
じゃねーしwww

いつまでも肝心な部分の実装をしようとしないChatGPTくんに、いいかげんしびれを切らしたので、ガチクレームをつけようとしたところ、 なんとここでカタまりました!
メッセージを送ろうとしてEnterを押せども画面は変わらず、ChatGPTくんからの返事もありません。。。
もしかして・・・コイツ、バックレやがった!!!!
前言撤回です。もし自分が雇用主だったら、 プロジェクトが佳境に入ったところでバックレる開発者なんて絶対に雇いません。
Review
さて、それではバックレやがった新人AI開発者のコードでもレビューしていくとしましょう。
コピペではないのか?
まっさきに疑ったのは、このコードがどこかの誰かコードのコピペなのではないか、ということです。
つまり、GitHub Copilot で問題視されていること と同様の問題があるのではないかということです。
結論から言うと、 既存のコードのコピペである証拠は見つかりませんでした。
半日かけてGitHubやGoogle検索で似たようなコードがないか探したのですが、そのようなコードを見つけることは出来ませんでした。
ただし、今回見つけられなかっただけの可能性もあります。
まぁ、ChatGPTが日本語の質問に対してちゃんと日本語の文法でそれっぽい回答をしていることを考えれば、Goの文法でそれっぽい回答をするなんて大した問題ではないのかもしれません。(日本語の文法のほうが、よっぽど難しいでしょうから)
ライブラリを使った簡単なロジックなら書ける
では、まずは Compile 関数から見ていくとしますか:
// Compile compiles a regular expression pattern into a regular expression object.
func Compile(pattern string) (*Regexp, error) {
// 正規表現パターンをパースする
parsed, err := syntax.Parse(pattern, syntax.Perl)
if err != nil {
return nil, err
}
// NFA を構築する
nfa, err := buildNFA(parsed)
if err != nil {
return nil, err
}
// NFA を DFA に変換する
dfa := convertToDFA(nfa)
// Regexp オブジェクトを作成して返す
return &Regexp{
states: dfa,
}, nil
}
とても丁寧にコメントがつけられていて、好感が持てますね!
しかし、標準ライブラリの syntax.Parse でASTが取得できるだなんてマニアックなこと、なんで知ってるの?普通の人は使う必要のないAPIだよね?
でも、 なんでいきなりDFAに変換してんの? バックトラッキング型NFAでいくんじゃなかったのかな?ChatGPTくんは 3分前のことは忘れちゃう仕様なのかな?
次に Split 関数:
// Split splits the input string by the regular expression and returns the splitted string array.
func (re *Regexp) Split(b []byte, limit int) [][]byte {
// 入力文字列のインデックスを初期化する
re.inputIdx = 0
// マッチした文字列を初期化する
re.matched = ""
// マッチした部分文字列の位置を初期化する
re.matchedIdx = -1
// 分割された文字列の配列
var result [][]byte
// DFA のステートの集合
states := make([]int, len(re.states))
for i := range states {
states[i] = i
}
// 入力文字列を分割する
for re.inputIdx < len(b) {
// DFA を実行し、マッチするかどうかを判定する
if !re.runDFA(b, states) {
// マッチしない場合は、残りの文字列を分割された文字列の配列に追加する
result = append(result, b[re.inputIdx:])
break
}
// 分割された文字列を分割された文字列の配列に追加する
result = append(result, b[re.inputIdx:re.matchedIdx])
// 入力文字列のインデックスを更新する
re.inputIdx = re.matchedIdx + len(re.matched)
// 分割された文字列の数が制限値に達した場合は、残りの文字列を分割された文字列の配列に追加する
if limit > 0 && len(result) == limit-1 {
result = append(result, b[re.inputIdx:])
break
}
}
return result
}
runDFA 関数を使って、「まぁ、そんな感じで実装するよね」というコードを出力しています。
恐らく、自分が書いてもこんな感じで書くでしょうね。
でもね…… なんで runDFA に初期ステートとして全ステートを渡してるのか意味わかんない…
難しいロジックは理解していない
では、今回の実装のキモである runDFA を見てみましょう。
// runDFA runs the DFA and returns whether the input string matches the regular expression or not.
func (re *Regexp) runDFA(b []byte, states []int) bool {
for {
// 現在のステートの集合から、次に遷移できるステートの集合を求める
nextStates := re.getNextStates(states, b[re.inputIdx])
// 次に遷移できるステートがない場合は、終了する
if len(nextStates) == 0 {
return false
}
// 次に遷移できるステートから、マッチするかどうかを判定する
if re.isMatchState(nextStates) {
// マッチした場合は、マッチした文字列とマッチした部分文字列の位置を更新する
re.matched = string(b[re.inputIdx : re.inputIdx+1])
re.matchedIdx = re.inputIdx
// 入力文字列のインデックスを更新する
re.inputIdx++
// マッチした場合は、true を返す
return true
}
// 現在のステートの集合を更新する
states = nextStates
// 入力文字列のインデックスを更新する
re.inputIdx++
}
}
states というのが現在いる(可能性のある)ステートの集合で、次の入力文字を1文字とって現在のステート集合からその文字で遷移できるステート集合を getNextStates で計算する、ということを繰り返していくわけですね。
愚直にDFAを実装している感じです。
そして getNextStates では:
// getNextStates returns the next states which can be transitioned from the given states by the given byte.
func (re *Regexp) getNextStates(states []int, b byte) []int {
// 次に遷移できるステートの集合
var nextStates []int
// 現在のステートの集合から、次に遷移できるステートの集合を求める
for _, state := range states {
if state < 0 || state >= len(re.states) {
// 無効なステートの場合は、処理をスキップする
continue
}
// 現在のステートが指定された文字に遷移可能かどうかを判定する
if re.states[state].canTransit(b) {
// 遷移可能な場合は、次に遷移できるステートの集合に追加する
nextStates = append(nextStates, re.states[state].next)
}
}
return nextStates
}
ステートそれぞれについて、遷移可能 (canTransit) だったら、次のステート next を append する。うん、正しそう・・・正しそう?んん??
next って何?ひとつのステートに対して次のステートが1つしかないの!?
というわけで、 state 構造体の定義を見てみましょう。
// state represents a state of the NFA.
type state struct {
// 次に遷移するステート
next int
// 指定された文字に遷移するかどうか
transit byte
// マッチするかどうか
match bool
}
どうやら次のステートは1つしか持てないらしい。。。
これじゃ分岐(|)を表現できないから一直線のマッチングしかできなくない?っていうか、もうオートマトンじゃなくない?オートマトンっていうのは、ある状態から任意の数の遷移先が存在できるもんなんですよ・・・
結論: ChatGPTさんはDFAすら実装できませんでした
ついでに指摘しておくと、マッチ対象が1文字しか指定できないのもいただけない。
DFA(オートマトン)の実装としてはきわめて教科書的なんだけど、正規表現エンジンをこの設計で進めると、遠からず詰みます。なぜなら文字クラスがあるから。
たとえば誰もがよく使うであろう [\n] という文字クラスは改行以外のあらゆる文字にマッチする。これをマッチ対象を1文字で表す設計で無理やり表現しようとすると、a, b, c, d, ... , 0, 1, 2, 3, ... と改行以外の文字をすべて遷移する文字として列挙していけば良い。
ASCIIコードの範囲だったら255文字列挙するっていう力技がないわけでもないんだけど、時代はUnicode。Unicodeでこれを無理やりやると、2^32-1 = 40億以上の文字を列挙しなければいけないことになる。メモリ的に無理ゲーですよね。
なので、マッチ対象は文字の"範囲"を扱えるようにしておくのが定石です。(詳しくは unicode.RangeTable あたりを参照)
苦しくなったらTODO
ChatGPTのクセとして、難しそうなところは関数に切り出して抽象化していくというクセがありそうですね。これは可読性という意味でも、非常に良い習慣だと思います。
一方で、難易度が一定以上になると 「TODO」とかいう都合のいいワードだけ書き残して、肝心な部分を丸っと未実装にするクセがある ようです:
// buildNFA builds the NFA from the parsed regular expression.
func buildNFA(parsed *syntax.Regexp) ([]state, error) {
// TODO: NFA を構築する
return nil, errors.New("not implemented yet")
}
あとさ、さも平然と公式APIなふうな顔して errors.New("not implemented yet") を返さないで、 正直に panic したと言いなさい と教わらなかったのかな?
そして最後は、いよいよ手に負えなくなったらバックレる 。
まじか~…こんなに 人間味にあふれるAI を期待してたわけじゃなかったわ・・・
Lessons
今回の調査で得られた教訓です。
1.ChatGPTは嘘をつく(ことがある)
まず、ChatGPTはそれっぽい回答をするだけであって、平気な顔で(顔があるのか?)嘘をつくということ。
上記の runDFA を見てわかる通り、DFAと言いながらこれはDFAになっていません。
つまり、「嘘を嘘と見抜ける人でないと(ChatGPTを扱うのは)難しい」というわけですね。(なんだか昔ひろゆき氏が言ってたことみたいですね!)
今回ChatGPTに実際にプログラムを書かせてみて思ったのは、ChatGPTの嘘が見抜けない、つまり"本当はプログラムのことがわかっていない人たち" が相当数あぶり出されることになるのでは?ということです。
これは、Web2.0で個人が気軽に情報発信できるようになったことで、インターネットが「バカ発見機」として機能するようになったのと似ています。
2.ChatGPTはプログラマの仕事を奪う?
この答えは人によって分かれそうです。
今回の記事を腹を抱えて笑って読んでたアナタ。アナタの仕事は(まだ当分は)AIに奪われることはないでしょう。ChatGPTは簡単なアルゴリズムの実装もまだまともにできません。
しかも、最初に決めた要件定義すら数分で忘れる始末です。まだまだ改善が求められます。
今回の記事を「俺もこんなコードばっかり書いてるわ…」と思って読んでたアナタ。アナタの仕事はおそらくAIにアウトソース可能です。おめでとうございます。
特に、ライブラリを使ってボイラープレート的なコードを書くことは得意そうですし、仕事も速いです。
なお、今回ChatGPTの成果物はこちらにアップしてあります↓
じっくりレビューしたい方はこちらをどうぞ。
Discussion