Snowflake Summit 25 印象的な新機能・ブース
CARTA HOLDINGSのfluctという事業部でデータエンジニアをやっているyanyanです。
今回6/2~6/5の期間、アメリカのサンフランシスコで開催されたSnowflake Summit 25に参加してきました。そこで発表された新機能やブース出展されていたSaaS、セッションの中で個人的に気になったり使ってみたいと思ったものについてまとめていきます。
網羅的な記事についてはナウキャストさんの記事などが参考になるかと思います。ほかにもたくさんのSnowflake Summitに関する記事はzennにすでに上がっているのでぜひ読んでみてください。
今回私はBIをはじめとするデータ活用に関するセッションやブースを重点的に回ろうと決めていたため、その領域の話が多くなることはあらかじめご了承ください。
dbt on Snowflake

dbtの実行や開発、モニタリングがsnowflake上でできるようになることがplatform keynoteにて発表されました。snowflakeとdbtを合わせて使っている会社は結構いると思うので、この発表は結構盛り上がったんじゃないかなと思います。
個人的にはdbtの開発がよりやりやすくなるなというイメージは湧いています。例えば自分の場合、今まではdbtのモデルを書いたり開発用のターゲットに対するdbt buildの実行はvscodeで行い、データ加工の結果を確かめるのにはsnowsight上のworksheetでモデルの中身を見るということをやっていました。それら一連の手順が全部snowsightのworkspace上で全部行えるとなると快適さが全然違うなと感じました。また、ローカルでdbtコマンドを実行するためにpythonの実行環境を用意する必要もありました。最近はryeやuvの登場で幾分ましになりましたが、その辺もsnowflake側に任せられるならすごいよさそうです。
定期実行などもできそうですし、trailやperfomance insightsを用いてdbt buildのモニタリングもできるので、ワンチャンdbt on snowflakeで本番環境のデータ加工やれるかも?
これはとりあえず試してみたいですね。
Adaptive Compute & Adaptive Warehouse
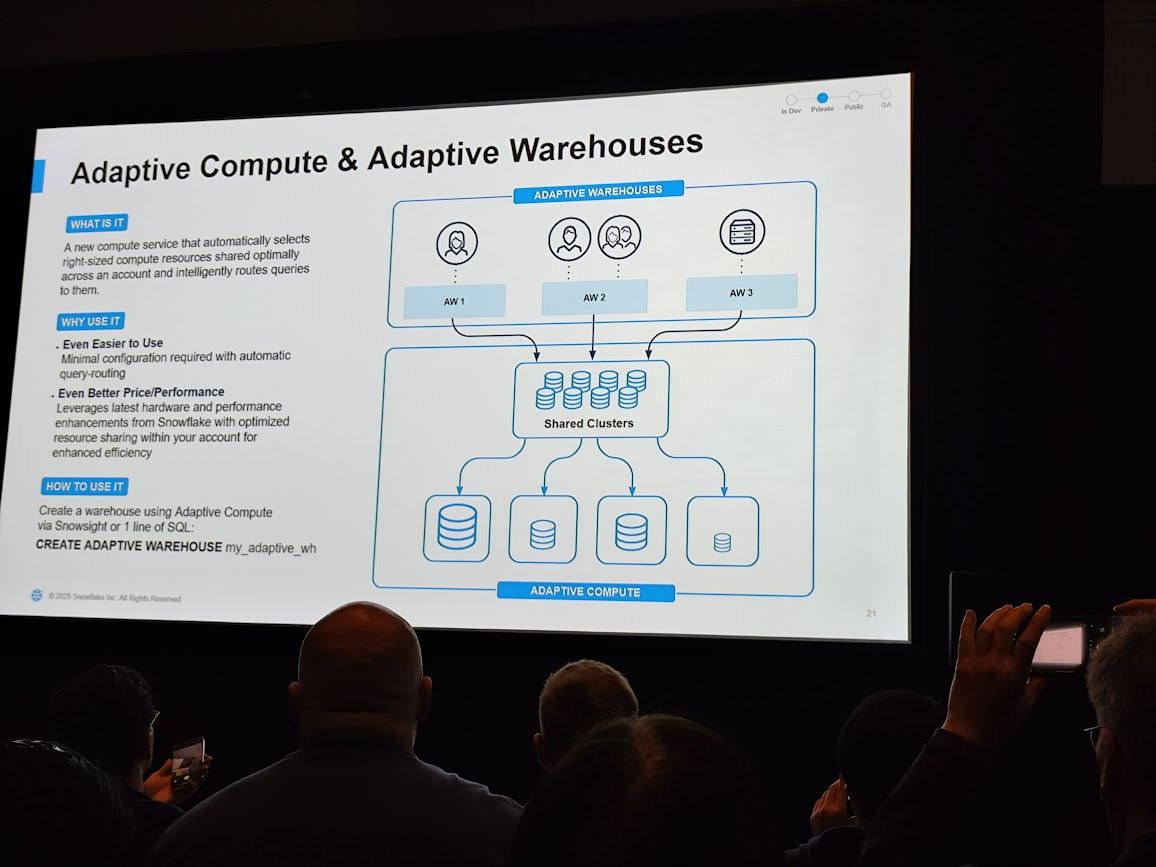
クエリに対して自動的に最適なリソースを割り当ててくれるウェアハウスが発表されました。機能の存在はplatform keynoteにて発表され、その後詳細に関するセッションがありました。platform keynoteで発表された機能に関するセッションが当日生えてくることを知らなかったのでこれは結構びっくりでした。でも同じ場で詳細に知ることができる場も用意されているのはありがたいですね。
Adaptive Warehouseを使うことによって、今までユーザー側がワークロードに応じて必要なウェアハウスサイズを指定する必要がなくなります。添付の画像のようにAdaptive Warehouseのリソース自体はポインターのような存在で、裏側にあるコンピュートリソースは共通のものという感じのようです。

Adaptive Warehouseが発表されたときに気がかりだったことは、想定以上のコンピュートリソースが使われ課金死してしまうことでした。しかし、添付の画像のように1時間あたりの消費クレジットの上限を設定できるようです。

また、Target Statement Sizeというオプションもあり、ウェアハウスサイズを動的に割り当てる際に基準となるサイズをユーザー側で設定できるようです。
こういったガードレールやヒントのような設定が用意されているので、既存のワークロードでAdaptive Warehouseを利用する際に今までのパフォーマンスやコスト感を維持しながら試すことができそうですね。
SnowPipeの新しい課金体系

snowpipeの課金体系が、ファイル数ベースからingestされた容量ベースに変更されました。今までログをs3などのオブジェクトストレージに置いてsnowpipeでロードする際、ある程度ログを1ファイルにまとめてから吐き出すようにしてファイル数を抑える工夫をしていました。ログをまとめるということは、ログが発生してからsnowflakeにロードされるまでのタイムラグが増えるわけです。そのため求められるリアルタイム性との兼ね合いを考える必要があったり、そもそも調整するの大変だなーと思っていました。今回の変更でそういったことを考える必要が減ったのでsnowpipeの使いやすさが向上しましたね。一方で個人的によくわからなかったのはコストの効果です。上で添付した画像では~50% Better Economicsと書いてあって安くなる旨が書いてありますが、安くなるかどうかはデータとそれぞれの単価次第なので場合によっては高くなる場合もあるのでは?ということを考えています。まあこれは新しい課金体系の単価がわかれば試算できるので、座して情報を待つことにしています。
Semantic Views

Semantic Viewsという新しいスキーマレベルオブジェクトが発表されました。すでに公式のドキュメントも読むことができます。
これは概念的にはdbtのsemantic layerと同じだと認識していて、ビジネスにおける指標や項目の定義、エンティティ同士の関係性をオブジェクトとして定義しておきます。
Semantic Viewsがもたらす効果は以下のことがあると考えています。
- セマンティックモデルの可搬性が高まる
- snowflakeというデータの基盤側で定義されていれば、どのBIツールでも(対応していればの話ではありますが)しゅっとセマンティックモデルを利用することができる
- 指標の導出方法やエンティティの関係性をデータ基盤側で一度定義して使いまわせるので、共通化しやすい
- 例えばClick Through Rate (クリック数 / 広告表示回数) のような複数の指標から計算される指標も、Semantic views上で定義してしまえばその定義を様々な場所で使いまわすことができます
- snowflake上にあるAI Agent機能が使い物になっていく
- 後述するSnowflake Intelligenceもそうなのですが、Semantic Viewsを整えることでAI Agentのアウトプットがより良いものになっていくはずです

omniというBIツールを開発しているチームのセッションで上記のようなスライドがありました。AI Agentを使ってデータを出したりインサイトを得るというワークフローの価値を高めるためには、AI Agentが参照するSemantic Modelを改善していくというステップが必要です。
Semantic Viewsはpreviewではありますがすでに使えるはずなので、触ってみて詳細をアウトプットしたいと思っています。
Snowflake Intelligence

ついにsnowflakeもAI Agent機能を作ってきました。

ユーザーはAI Agentを通じて自然言語でデータへのアクセス、可視化、インサイトの獲得ができるようになります。Googleのgeminiのようなことがsnowflakeにある自分たちのデータ基盤上でできるということだと私は思っていて、かなり革命的だという印象です。今までSQLを書いたりダッシュボードを自力で構築できないユーザーが何かデータを見たいと思ったら、データエンジニアがクエリを書いたりする必要がありました。しかし、自然言語でアクセスできるインターフェースが用意されたことによってデータを出す、可視化をするという業務からデータエンジニアが解放されることが期待できます。
一方で手放しにSnowflake Intelligenceが圧倒的な効果を発揮するとも思っていなくて、先述のSemantic Viewsを駆使したAI Agentが価値のあるアウトプットを出せるような土台作りが必要です。ただこの土台づくりはレバが効く領域なはずなのでやりがいがありますね。
Snowflake Intelligence自体は近日public preview開始ということなので待ち遠しいです。公式がブログも書いているのでぜひ読んでみてください。
ブース出展していたBIたち
BIツールを開発している企業のブース出展がいくつもあったので、回れたものについて軽く紹介をしていきます。
Sigma

今回のSummitで最もTierの高いスポンサーだったSigma。ブースもめっちゃ大きかったです。

Sigmaはスプレッドシートライクな使い勝手でビジネスユーザーでも使いやすいらしいです。デモを見せてもらいましたが、セルに色を付けられたりとかはスプシっぽさを感じましたw
個人的によさそうだなと思ったのは未来のシミュレーションが割と簡単にできそうなことで、コストや売り上げの変動率をセルに入力することで利益の推移をシミュレーションして可視化するというデモを主っとやってもらいました。他のBIができるかというのはわかりませんが、経営層とかはそういった未来の予測をしたくなることがあると思うのでニーズは一定あると思います。
ThoughtSpot
ThoughtSpotは写真を撮り忘れたので公式のリンクを置いておきます。
ThoughtSpotのデモで見せてもらったのは、SpotterというAIに自然言語で問い合わせができる検索窓がインターフェースの入り口となっていてそこでAIが出力した可視化を用いてダッシュボードを構築していくというものでした。ダッシュボード構築の入り口も自然言語でやれるのはビジネスユーザーへの展開もやりやすそうだなと感じました。
LightDash
LightDashも写真取れてなかった...
最近日本ではやり始めているLightDashもブースがありました。ブースで日本使ってくれてる人多いよね!みたいな話を開発の人がしておりました。
LightDashはセマンティックモデルやLightDash上で扱うデータセットの定義をコード管理できたり、ダッシュボードの利用状況の管理しやすさ、データの連携先の豊富さあたりが強みかなと思っています。まためずらしくユーザー数課金じゃないのも魅力的で、弊社では今お試しをしている最中です。
国内でのMeetUpイベントが開かれるかも?しれないので今後も利用は広がっていきそうですね。
Omni

OmniもAIを利用したデータ探索が可能で、SQLがかけなくても見たいデータを見れるという部分は魅力的でした。Omniの強みは、Omni側で試行錯誤した結果をdbtのモデルやsemantic modelとしてwrite backできることっぽいです。
初めて海外カンファレンスに参加してみて
行ってよかった、来年も行きたいと自信をもって言えます。それくらい刺激をたくさん受けた濃密な時間でした。snowflakeは日本のコミュニティも活発で、summit期間中にいろんな方としゃべることができたことも良い経験となりました。
来年はさらに多くの知見を持ち帰れるように英語の勉強であったりsnowflakeの知識を増やして臨みたいと思います!!
Discussion