新しくなったKindle for Macの蔵書一覧取得方法
とあることからKindleの蔵書一覧を取得したいなと思いたち、簡単にできるかと思ったら、ほとんどの記事が以前のKindleアプリでの取得方法でした。
2023年9月にKindle for Macアプリは刷新されたようで、これまでのKindleアプリは廃止されたようです。それに伴いこれまでは自動生成されたxmlファイルをパースすることで、本の情報が取得できていたのですが、それができなくなりました。
この記事では、新しいKindle for Mac版での蔵書一覧取得方法を紹介していきます。
こちらの記事を参考にしつつ、Google Colaboratoryを用いてやっていきます。
前準備
目的とするKindleのデータは次の場所にあります。
/Library/Containers/com.amazon.Lassen/Data/Library/Protected/BookData.sqlite
SQLファイルのアップロード
まずはcolab上にファイルをアップロードします。
from google.colab import files
uploaded = files.upload()
どのようなフィールドがあるのかを確認する
実行すると、下にファイル選択ボタンが出てくるので、これで先ほどのBookData.sqliteを選択してアップロードします。(数分かかります)
次にどのようなフィールドがあるか確認します。
import sqlite3
with sqlite3.connect("./BookData.sqlite") as conn:
cur = conn.cursor()
data = cur.execute("SELECT * FROM sqlite_master WHERE type='table'").fetchall()
print(data)
実行すると次のような出力が得れます。
[('table', 'ZARTICLE', 'ZARTICLE', 3, 'CREATE TABLE ZARTICLE ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZRAWINDEX INTEGER, ZRAWISUNREAD INTEGER, Z2RAWARTICLES INTEGER )'), ('table', 'ZBOOK', 'ZBOOK', 4, 'CREATE TABLE ZBOOK ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZISHIDDENBYUSER INTEGER, ZRAWAUTOSHELVE INTEGER, ZRAWBOOKSTATE INTEGER, ZRAWBOOKTYPE INTEGER, ZRAWBOOKUPGRADESNEEDED INTEGER, ZRAWCURRENTPOSITION INTEGER, ZRAWERL INTEGER, ZRAWFILESIZE INTEGER, ZRAWHASCOMPANION INTEGER, ZRAWHASFIXEDMOPHIGHLIGHTS INTEGER, ZRAWINBOOKCOVERCHECKED INTEGER, ZRAWISARCHIVABLE INTEGER, ZRAWISDICTIONARY INTEGER, ZRAWISENCRYPTED INTEGER, ZRAWISHIDDEN INTEGER, ZRAWISKEPT INTEGER, ZRAWISMULTIMEDIA INTEGER, ZRAWISPENDINGVERIFICATION INTEGER, ZRAWISSMDCREATEDDICTIONARY INTEGER, ZRAWISTRANSLATIONDICTIONARY INTEGER, ZRAWISUNREAD INTEGER, ZRAWLASTACCESSTIME INTEGER, ZRAWLASTOPENSUCCEEDED INTEGER, ZRAWLASTVIEW INTEGER, ZRAWMAXLOCATION INTEGER, ZRAWMAXPOSITION INTEGER, ZRAWNCXINFOSTORED INTEGER, ZRAWPROGRESSDOTCATEGORY INTEGER, ZRAWPUBLICATIONDATE INTEGER, ZRAWREADSTATE INTEGER, ZRAWREADSTATEORIGIN INTEGER, ZRAWREADINGMODE INTEGER, ZRAWUSERVISIBLELABELING INTEGER, ZCOMPANION INTEGER, ZALTERNATESORTTITLE VARCHAR, ZBOOKID VARCHAR, ZBUNDLEPATH VARCHAR, ZCONTENTTAGS VARCHAR, ZDICTIONARYLOCALEID VARCHAR, ZDICTIONARYSHORTTITLE VARCHAR, ZDICTIONARYSOURCELANG VARCHAR, ZDISPLAYTITLE VARCHAR, ZGROUPID VARCHAR, ZLANGUAGE VARCHAR, ZLONGCURRENTPOSITION VARCHAR, ZLONGMAXPOSITION VARCHAR, ZMIMETYPE VARCHAR, ZPARENTASIN VARCHAR, ZPATH VARCHAR, ZPERASINGUID VARCHAR, ZRAWPUBLISHER VARCHAR, ZSHELF VARCHAR, ZSORTTITLE VARCHAR, ZWATERMARK VARCHAR, ZALTERNATESORTAUTHOR BLOB, ZDISPLAYAUTHOR BLOB, ZEXTENDEDMETADATA BLOB, ZORIGINS BLOB, ZSORTAUTHOR BLOB, ZSYNCMETADATAATTRIBUTES BLOB, ZRAWTITLEDETAILSJSON BLOB )'), ('table', 'ZBOOKEXT', 'ZBOOKEXT', 5, 'CREATE TABLE ZBOOKEXT ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZBOOKID VARCHAR, ZDOWNLOADORIGIN VARCHAR )'), ('table', 'ZBOOKUPDATE', 'ZBOOKUPDATE', 6, 'CREATE TABLE ZBOOKUPDATE ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZPLUGINRETRIES INTEGER, ZRAWUPDATESTATE INTEGER, ZENDTIME TIMESTAMP, ZLASTUPDATEATTEMPT TIMESTAMP, ZSTARTTIME TIMESTAMP, ZBOOKID VARCHAR, ZUPDATEID VARCHAR, ZUPDATEREQUESTID VARCHAR )'), ('table', 'ZCOLLECTIONITEM', 'ZCOLLECTIONITEM', 7, 'CREATE TABLE ZCOLLECTIONITEM ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZSYNCHINT INTEGER, ZBOOK INTEGER, ZCOLLECTION INTEGER, ZRAWORDER FLOAT, ZCOLLECTIONID VARCHAR, ZITEMID VARCHAR )'), ('table', 'ZCOLLECTIONV2', 'ZCOLLECTIONV2', 8, 'CREATE TABLE ZCOLLECTIONV2 ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZRAWLASTACCESSTIME INTEGER, ZSYNCHINT INTEGER, ZALTERNATESORTNAME VARCHAR, ZCOLLECTIONID VARCHAR, ZCONTENTTYPE VARCHAR, ZLANGUAGE VARCHAR, ZNAME VARCHAR, ZPHONETICNAME VARCHAR, ZSORTNAME VARCHAR )'), ('table', 'ZGROUP', 'ZGROUP', 9, 'CREATE TABLE ZGROUP ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZLASTACCESSTIME INTEGER, ZLASTACCESSTIMEFORDOWNLOAD INTEGER, ZRAWPUBLICATIONDATE INTEGER, ZTOTALSIZE INTEGER, ZSERIESCOVERIMAGE INTEGER, ZGROUPID VARCHAR, ZALTERNATESORTAUTHOR VARCHAR, ZALTERNATESORTTITLE VARCHAR, ZCOLLECTIONORDERTYPE VARCHAR, ZCOVERBOOKID VARCHAR, ZDETAILPAGEASIN VARCHAR, ZDISPLAYAUTHOR VARCHAR, ZDISPLAYNAME VARCHAR, ZSERIESTYPE VARCHAR, ZSORTAUTHOR VARCHAR, ZSORTTITLE VARCHAR, ZRAWSERIESCOLLECTIONTYPES BLOB )'), ('table', 'ZGROUPITEM', 'ZGROUPITEM', 10, 'CREATE TABLE ZGROUPITEM ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZBOOK INTEGER, ZPARENTCONTAINER INTEGER, Z7_PARENTCONTAINER INTEGER, ZPOSITION INTEGER, ZITEMID VARCHAR, ZPOSITIONLABEL VARCHAR, ZRAWITEMCOLLECTIONTYPE VARCHAR )'), ('table', 'ZSERIESAUTHOR', 'ZSERIESAUTHOR', 11, 'CREATE TABLE ZSERIESAUTHOR ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZSERIES INTEGER, Z_FOK_SERIES INTEGER, ZAUTHORNAME VARCHAR, ZAUTHORPRONUNCIATION VARCHAR )'), ('table', 'ZSERIESIMAGE', 'ZSERIESIMAGE', 12, 'CREATE TABLE ZSERIESIMAGE ( Z_PK INTEGER PRIMARY KEY, Z_ENT INTEGER, Z_OPT INTEGER, ZSERIES INTEGER, ZEXTENSION VARCHAR, ZIMAGEID VARCHAR )'), ('table', 'Z_PRIMARYKEY', 'Z_PRIMARYKEY', 40, 'CREATE TABLE Z_PRIMARYKEY (Z_ENT INTEGER PRIMARY KEY, Z_NAME VARCHAR, Z_SUPER INTEGER, Z_MAX INTEGER)'), ('table', 'Z_METADATA', 'Z_METADATA', 41, 'CREATE TABLE Z_METADATA (Z_VERSION INTEGER PRIMARY KEY, Z_UUID VARCHAR(255), Z_PLIST BLOB)'), ('table', 'Z_MODELCACHE', 'Z_MODELCACHE', 42, 'CREATE TABLE Z_MODELCACHE (Z_CONTENT BLOB)')]
思ったより多かった・・・
SQLデータベースの中身を確認する
ちょっと方針変えて、SQLデータの中身を見たいと思います。
VSCodeの拡張でSQLiteというパッケージがあるので、これを使って中身を見ます。
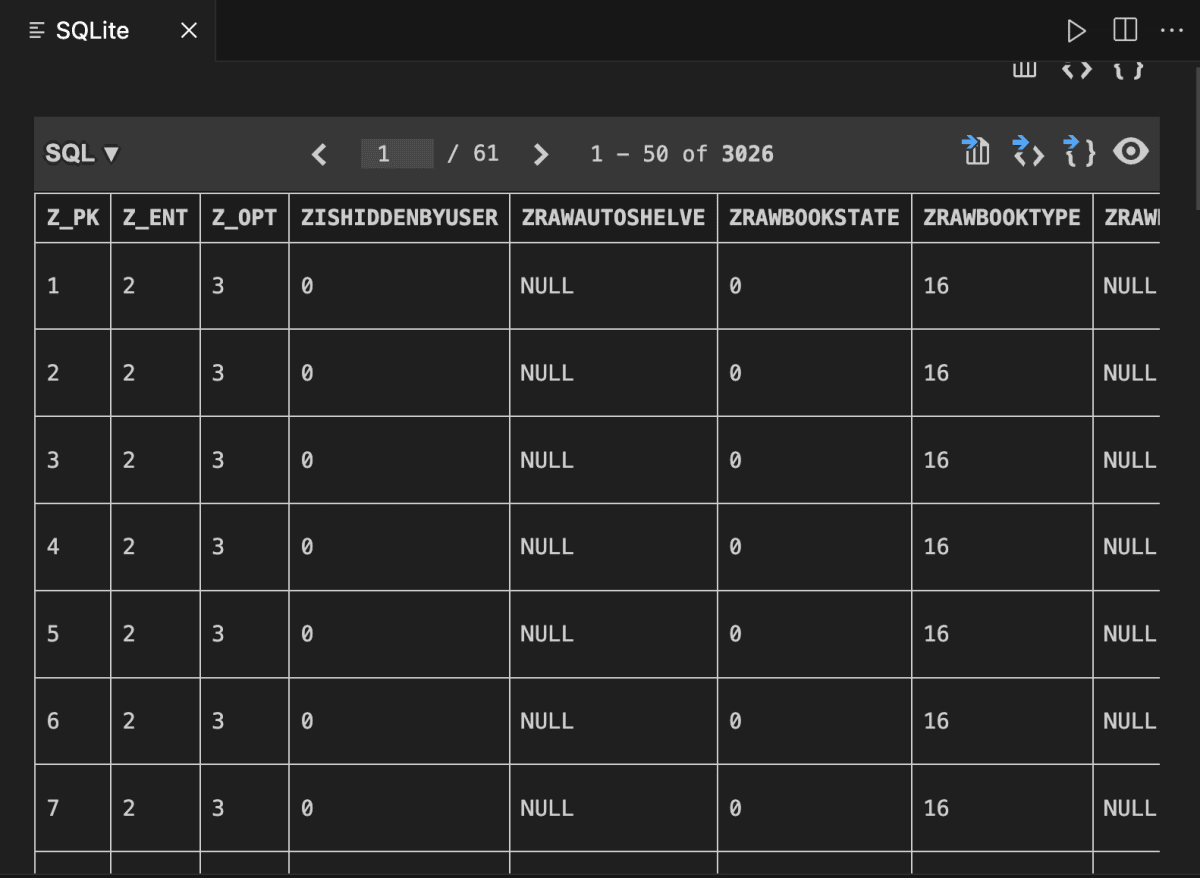
メニューのエクスプローラー選択し、下部にあるSQLITE EXPLORERから該当のSQLデータを選択すると、テーブル、フィールドが表示されますので、みたいテーブルをマウスオンして、右側の再生ボタンみたいな三角ボタンを押すと、次のようにデータベースの中身を見ることが出来ます。
ここから自分の使いたいフィールドを選んでいきます。自分はタイトルだけで良かったので、ZDISPLAYTITLEを取得できればいいとなりました。
CSVファイルを出力する
それでは、このタイトルを読み込んでCSVファイルに出力したいと思います。
import pandas as pd
with sqlite3.connect("./BookData.sqlite") as conn:
example_sql = "SELECT ZDISPLAYTITLE FROM ZBOOK"
df = pd.read_sql(sql=example_sql, con=conn)
df.columns = ['Title']
df.sort_values(by=['Title'], inplace=True)
df.to_csv('./local_data.csv')
実行すると、colab上にlocal_data.csvファイルが作成されていると思います。
dfつまり、dataframeをもとにcsvが作成されているので、このdataframeを簡単に確認します。
df = pd.read_csv('local_data.csv', sep=',')
df.shape[0]
これで列の数が取得できます。つまり蔵書数です。
dataframeの先頭5つを確認します。
df.head()
自分はこんな感じの出力になりました。

先頭のcolumnが定義されてないのと、Titleがソートされてないので、それを修正します。
df.columns = ['ID', 'Title']
df.sort_values(by=['Title'], inplace=True)
df.head()
こんな感じでIDをというcolumn名を付与し、タイトルがソートされているのを確認できました。

おわり
気軽にフォローしてください!!
参考させていただいた記事
Discussion