AWS DAS試験勉強
Kinesis Data Stream
1日から365日までで保持期間を指定。
- プロビジョンドモード
- プロビジョンドされたシャードごとに時間料金がかかる。
- シャードごとにスループット制限あり(IN: 1MB/s & 1000records, OUT: 2MB/s)
- オンデマンドモード
- 過去30日間の使用に応じてオートスケール
- 時間当たりのシャード数 & in/outデータ量で課金
- VPCエンドポイントを使ってVPC内からアクセス可能
- KMSで暗号化可能
- 拡張ファンアウト
- 1つのシャードに複数のコンシューマを登録している際、制限がコンシューマごとに割り当てられる。デフォルトでは5つまでコンシューマを登録できるが、上限緩和可能。
- 2MB/sだったものが、10MB/sなどにできるため、処理待ちのレイテンシが小さくなる。一方でコストは上がる。
Kinesis Data Firehose
Redshiftへ送信する場合は、S3に一度データを配信し、RedshiftにCOPYクエリを打つ。なので、RedshiftへのIAM権限も必要。
Glue
ダイナミックフレームについて。
FindMatchesで複数のソースデータに一意のIDがなくとも、重複レコードを検出できる。機械学習を使っている。
データソースはAurora, RDS, DynamoDB Redshift, S3やEC2錠で実行されているデータベースなど。 VPNやDXで繋がっているオンプレサーバにもJDBCを利用することで、クローラ、ジョブを実行できる。
クローラを実行する際、データ内容を評価するために分類子を利用する。ファイル内容がjson, parquet, xml, csvなどなどを識別する。カスタム分類子を作成する事で、分類内容を増やすことができる。クローラにカスタム分類しを追加すると、最初にカスタム分類子を呼び出す。 certainty=1.0の場合、その分類子を選択する。1.0以外の場合は次の分類子を評価する。どの分類子にもマッチしない場合は最も値の高い分類子を選択する。ただし全てが0.0未満の場合はUNKNOWNとなる。
EMR
EMRのBlack Belt動画
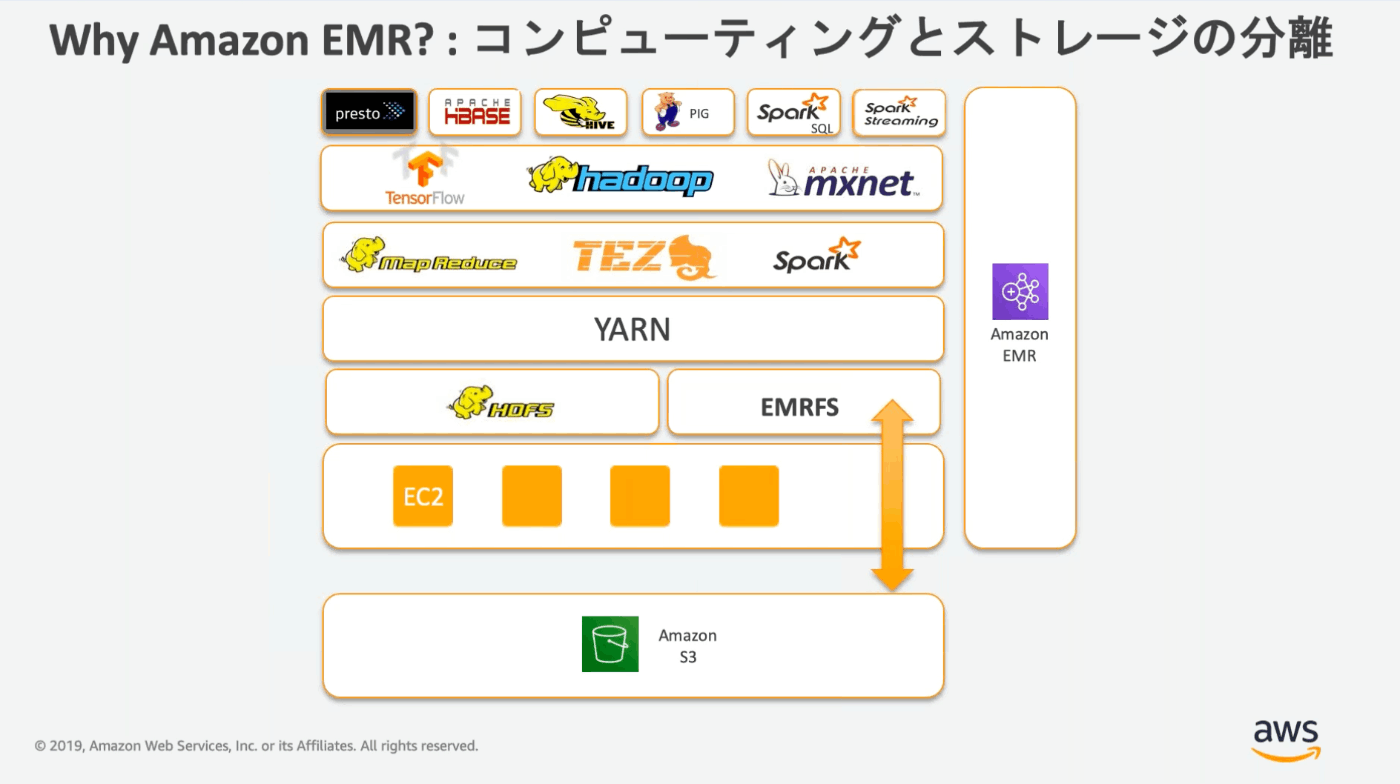
EMRFSはHDFSと同じような使用感でS3ストレージを実行できる。
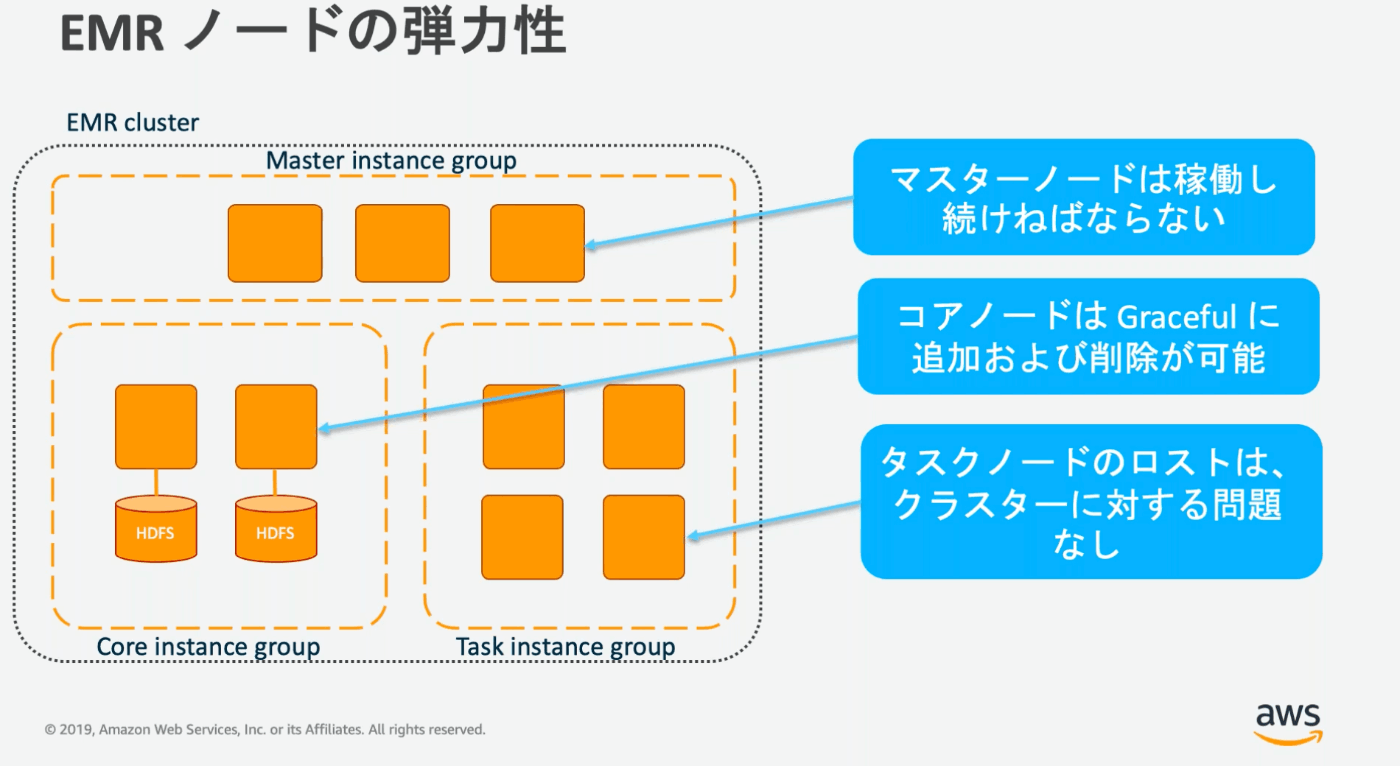
マスターノードはクラスター全体の管理を行う。ジョブなどもマスターインスタンスが受け付けて、コアノード・タスクノードで処理を行う。クラスターが存在する間は常に稼働していなければならない。また、HA構成として、マルチマスターが可能。
コアノードはEBSを利用してHDFSを構成する。
タスクノードはEMRFSを利用するので、ストレージが不要。スポットインスタンスとの相性が良い。
1つのサブネット内で実行される(単一AZのみ)。
インスタンスグループかインスタンスフリートか
インスタンスグループ
インスタンスグループごとに1つのインスタンス購入オプションおよびインスタンスタイプを指定する。

マスターインスタンスグループ、コアインスタンスグループ、タスクインスタンスグループに分かれる。タスクインスタンスグループのみ、複数グループを持つことができる。
インスタンスフリート

マスター、コア、タスクノードにそれぞれ1つのフリートを設定する。フリートには最大5種のインスタンスタイプおよび購入オプションを設定できる。
ジョブの実行

EMR Step APIか、Hadoopアプリケーションのネイティブなインターフェースからジョブを送信できる。
インスタンスの軌道
インスタンスの起動時にスクリプトを実行可能。内容はインスタンスのタイプ(マスター、コア、タスク)などによって変更できる。
AMIにはカスタムAMIを利用することができる。
アクセス許可
EC2のIAMロールにより、S3へアクセスできる。
Hadoopサービス群
Apache Pig
JDBCをサポートしていない。EMRFS, HDFSのオブジェクトにのみ実行可能?
構造化、半構造化データに対して処理が可能。
EMR Notebooks
Gitリポジトリを関連づけてバージョニング等ができる。
ハンズオン
Lake Formation
【AWS Black Belt Online Seminar】AWS Lake Formation
テーブル = S3に保存されているデータの場所
データベース = テーブルの集合
データカタログ
データカタログ=データベースとテーブルに対するメタデータ。
Apache Hiveメタストア互換。Glueデータカタログと統合されている。

テーブル情報、テーブルプロパティ、テーブルスキーマ、テーブルパーティションが保存されている。
Glueクローラによって自動推論が可能。
メタデータに対して検索を行うことができる。ただし権限があるデータカタログのみ検索可能。
テーブルプロパティやカラムプロパティに独自のプロパティを設定可能。
利用者がセルフサービスで検索できるので素晴らしい!
ブループリント
データソースからデータレイクにデータを取り込むテンプレート。データベース用とログファイル用がある。バルクロード、増分ロードが行える。
中身はGlueのトリガー、ワークフロー、クローラー、ジョブで構成される。

ワークフローはブループリントから作成されたリソース。実態はGlueワークフロー。
アクセス許可
データロケーションのアクセス許可
データロケーション=データが保存されるS3パス。登録されたS3のある場所にデータベース、テーブルを作成するために、プリンシパルにその場所に対するアクセス許可を与える。
ブループリントを使う場合は、ブループリントをもとに作成されたワークフローのIAMロールを指定する。
データカタログのアクセス許可
データベースとテーブルを作成、編集、削除する権限。
データアクセス許可
テーブルの下になるデータを読み書きする権限。プリンシパルにテーブルに対する許可を与える。
ここで、権限の種類、カラムの指定が行える。
暗黙的なアクセス許可
作成者のオーナー権限みたいなイメージ。
データベース作成者はデータベース内のすべてのテーブルに対する権限を持つ。
デーブル作成者はテーブルに対するすべての権限を持つ。別のプリンシパルにアクセス許可を与えることもできる。
データレイクユーザは権限を持つデータベースまたはテーブルを一覧表示できる。
データレイク管理者(Lake Formation内の管理者ユーザ。not IAMパーミッション)はすべての権限を持つ。


- (ユーザA)データレイク(S3)のデータ処理をしたい!
- (AWSサービス)Lake Formationさん、ユーザAがデータレイクにアクセスしたいらしいんだけど
- (Lake Formation)ユーザAは権限持ってるからええで。この一時クレデンシャル使ってくれや。
- (AWSサービス)ほな処理しまっか。
OpenSearch
専用マスターノード
インスタンスタイプとノード数を選択。ストレージサイズは指定できない。
クラスターの管理を行い、データは保持しない。
セキュリティ
作成時にVPC内か外どちらに設置するか選択する。後からは変更できない。パブリックからアクセスしたくなった場合はプロキシを置いたり、VPN、DXを経由する必要がある。
VPC内においた場合はセキュリティグループを設定する。
VPCの移動はできないが、サブネットの変更はできる。
JVMMemoryPressureエラー
シャード数を減らす、古いインデックスは削除する、キャッシュを削除することでメモリ負荷をさげられる。
Redshift
COPYコマンド
COPYコマンドでデータをロードする際はIAMロールを指定する。
アクセス許可
行レベル・列レベルでアクセス制御が可能。
列の場合はGRANT/REVOKE。
行の場合はCREATE RLS POLICY, ATTACH RLS POLICY。
監査ログ
Redshiftへの接続ログ・ユーザログ(データベースユーザに対する変更)・クエリログはS3, CW Logsに送信可能。
Redshift APIへのリクエストはCloud Trailで保存。
Athena
bzip2, GZIP, LZO, Snappyなど様々なデータ圧縮形式に対応している。bzip2, BZIPが推奨? (bzip2って分割できるんだ。。。)
フェデレーテッドクエリ(Lambdaをコネクタとして使用)を使って、RDSやJDBC、DynamoDB、CW Logsなど様々なデータソースにクエリを実行できる。
現状、行レベル・列レベルの制限をかけるにはLake Formationを使用するしかない。
データ使用量の制限はクエリごと、ワークグループごとそれぞれで設定できる。
ワークグループでは指定期間のうちにワークグループ全体で実行されたクエリの総データ読み込み量。ただしワークグループの制限は、制限というよりもアラート。CW Alarmを発火するだけ。
QuickSight
行および列レベルの閲覧制限ができる。
行レベルのセキュリティ(RLS)
QuickSightユーザ/グループごとに制限を行う場合は、ユーザ/グループベースのルールを適用する。
独自のアプリケーションにダッシュボードを埋め込む場合は、タグベースのルールを利用する。
列レベルのセキュリティ(CLS)
SPICEデータの更新
EEだとSPICEデータの定期更新が可能。データソースがDB系の場合、増分のみの更新もできる。
エディションの比較
SAML認証はどちらでも可能。
EEだとAD連携、組み込みダッシュボード、VPCアクセス、行レベルセキュリティ、SPICEデータの定期更新、保管データの暗号化、機械学習インサイトなどが利用できる。
SageMaker
Amazon SageMaker Ground Truth
機械学習用データセットを作成する。ラベリングの補助ができる。