DIN-SQLでText-to-SQLの精度をあげよう!
TL;DR
- DIN-SQLは、「質問を単語と表の関連付け」、「難易度に分類」、「SQL生成」、「微調整」の4つのモジュールでSQL生成精度を向上させる!
- 面白いのが、これら全てのモジュールがプロンプティングで実現されていること。
- ベンチマークデータセットのSpiderとBIRDにおいて、DIN-SQLの実行精度は既存の手法を上回っている!
- モジュールを減らすと、精度は基本落ちる
- (私の感想)生成したいSQLの難易度によっては、一部のモジュールを省略してチューニングすることも有効かもしれない。
はじめに
みなさん、DBはあるけれどそれをうまくLLMを使って活用したいと思ったことはありませんか?
データベースを自然言語で操作できればめちゃくちゃ便利ですよね。
例えば、「去年の売上が100万円以上の顧客を抽出して」といった具合に、普段使っている言葉でデータベースに問い合わせができたら便利ですよね。
今回は現状のText-to-SQLの問題点と、それを解決する方法であるDIN-SQLについて解説したいと思います。
DIN-SQLは、Text-to-SQLタスクを部分問題に分解して、段階的に解決することで、LLMのSQL生成精度を改善する手法です。
自然言語からSQLへの変換は難しい
LLMでText-to-SQLを挑戦したことありますか?
LangChainでもText-to-SQLのチュートリアルはあります。実際試そうと思ったら結構簡単にできてしまいます。興味ある方は以下を読んで手を動かしてみてください
簡単にできるんですが、じゃあSQL生成の精度がいいかと言われるとなんとも言えなくなります。
LLMでSQLクエリを自動生成するのって、実はまあまあ難しいんです。例えば
- 自然言語をスキーマに対応させようとしても、正しく対応しない
- 自然言語が曖昧すぎる...
- スキーマの制約に厳密に合わなかったりする。
- LLMがスキーマの制約を甘く見てしまっているからなのかな?
- クエリが複雑になるほど生成したSQLがエラーを起こしやすい。
- なんとなく想像がつくやつやな
などなど色々と難しい点があるのです。
- なんとなく想像がつくやつやな
その中でも改善策として挙げられてるのは
- Few-shotのプロンプト
- 少数のサンプルを示すことで、LLMにタスクの実行方法を教えるプロンプト手法
- CoTのプロンプト
- 問題を段階的に分解し、各ステップの推論プロセスを明示的に示すことで、LLMの理解を深めるプロンプト手法。
などがあります。(他にもあります。)
しかし、これらの手法を用いても、まだ完全とは言えない状況です。
以下の表を見てもらいたいです。現状のLLMs vs 既存の手法で精度をSpiderというデータセットで比較した表です。

(referenced by DIN-SQL: Decomposed In-Context Learning of
Text-to-SQL with Self-Correction)
- 問題を段階的に分解し、各ステップの推論プロセスを明示的に示すことで、LLMの理解を深めるプロンプト手法。
この段階である程度Fine-tuningした既存手法の方が全然強いんですよね。
もっと言うと現状のLLMsは、特に中程度および複雑なクエリについて、既存の手法に比べて劣っているんですね。
その中でもLLMsがどんなパターンでSQL生成が失敗しているか確認してみましょう。以下をみてください。これは

SQL生成の失敗パターンで、多かった順で書くと以下です。
- スキーマリンキング(質問を単語と表の関連付け)
- JOIN
- GROUPBY
- Nested
- そもそも不正なクエリになってしまう
DIN-SQLは、これらエラーをモジュールごとに解決することでSQL生成の精度を上げていきます。
では実際にDIN-SQLの仕組みを見ていきましょう。
DIN-SQLの仕組み
DIN-SQLは以下の図のように4つのモジュールからできています。
- スキーマリンク(Schema Linking Module)
- クエリ分類と分解( Classification & Decomposition Module)
- SQL生成(SQL Generation Module)
- 自己修正(Self-correction Module)

(referenced by DIN-SQL: Decomposed In-Context Learning of
Text-to-SQL with Self-Correction)
そして面白いところは、各モジュールは何かロジックを書いているわけではなくて、全部プロンプティングで実施していることです。
気になる方はGitHubのリポジトリを見ることを推奨します。
スキーマリンク(Schema Linking Module)
簡単に言うと、自然言語の質問の中から、データベースのスキーマに関連する単語を見つけ出すことです。
例えば、こんな質問があったとします。
"Find the names and ages of customers who made a purchase over $100 last year."
(去年100ドル以上の購入をした顧客の名前と年齢を探してください。)
この質問を読んで、"names"(名前)や"ages"(年齢)がcustomers(顧客)テーブルのカラムと紐づけることです。
これをするとLLMは質問のどの部分がデータベースのどの要素に対応しているのかを理解できるようになります。
ただ、スキーマリンキングは完璧ではありません。同じ名前のカラムが複数のテーブルにある場合や、質問文の表現があいまいな場合は、正しく対応付けできないことがあります。そのため、DIN-SQLではスキーマリンキングの結果を確率的に扱い、後段のモジュールで調整を行っています。
プロンプト
プロンプトで、以下を盛り込んでスキーマリンクを実行してます。
- instruction
- Find the schema_links for generating SQL queries for each question based on the database schema
- スキーマ
- 大量の実行例
- Few-shot プロンプトだねえ
コードを読むとわかりますが、実行例などはコードで作成してますね
https://github.com/MohammadrezaPourreza/Few-shot-NL2SQL-with-prompting/blob/main/DIN-SQL.py
- Few-shot プロンプトだねえ
# Find the schema_links for generating SQL queries for each question based on the database schema
and Foreign keys.
Table city, columns = [*,City_ID,Official_Name,Status,Area_km_2,Population,Census_Ranking]
Table competition_record, columns = [*,Competition_ID,Farm_ID,Rank]
Table farm, columns = [*,Farm_ID,Year,Total_Horses,Working_Horses,
Total_Cattle,Oxen,Bulls,Cows,Pigs,Sheep_and_Goats]
Table farm_competition, columns = [*,Competition_ID,Year,Theme,Host_city_ID,Hosts]
Foreign_keys = [farm_competition.Host_city_ID = city.City_ID,competition_record.Farm_ID =
farm.Farm_ID,competition_record.Competition_ID = farm_competition.Competition_ID]
Q: "Show the status of the city that has hosted the greatest number of competitions."
A: Let’s think step by step. In the question "Show the status of the city that has hosted the greatest
number of competitions.", we are asked:
"the status of the city" so we need column = [city.Status]
"greatest number of competitions" so we need column = [farm_competition.*]
Based on the columns and tables, we need these Foreign_keys = [farm_competition.Host_city_ID =
city.City_ID].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are = []. So the
Schema_links are:
Schema_links: [city.Status,farm_competition.Host_city_ID = city.City_ID,farm_competition.*]
Table department, columns = [*,Department_ID,Name,Creation,Ranking,Budget_in_Billions,Num_Employees]
Table head, columns = [*,head_ID,name,born_state,age]
Table management, columns = [*,department_ID,head_ID,temporary_acting]
Foreign_keys = [management.head_ID = head.head_ID,management.department_ID = department.Department_ID]
Q: "How many heads of the departments are older than 56 ?"
A: Let’s think step by step. In the question "How many heads of the departments are older than 56 ?",
we are asked:
"How many heads of the departments" so we need column = [head.*]
"older" so we need column = [head.age]
Based on the columns and tables, we need these Foreign_keys = [].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are = [56]. So the
Schema_links are:
Schema_links: [head.*,head.age,56]
Table department, columns = [*,Department_ID,Name,Creation,Ranking,Budget_in_Billions,Num_Employees]
Table head, columns = [*,head_ID,name,born_state,age]
Table management, columns = [*,department_ID,head_ID,temporary_acting]
Foreign_keys = [management.head_ID = head.head_ID,management.department_ID = department.Department_ID]
Q: "what are the distinct creation years of the departments managed by a secretary born in state
’Alabama’?"
A: Let’s think step by step. In the question "what are the distinct creation years of the departments
managed by a secretary born in state ’Alabama’?", we are asked:
"distinct creation years of the departments" so we need column = [department.Creation]
"departments managed by" so we need column = [management.department_ID]
"born in" so we need column = [head.born_state]
Based on the columns and tables, we need these Foreign_keys = [department.Department_ID =
management.department_ID,management.head_ID = head.head_ID].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are = [’Alabama’].
So the Schema_links are:
Schema_links: [department.Creation,department.Department_ID = management.department_ID,
head.head_ID = management.head_ID,head.born_state,’Alabama’]
Table Addresses, columns = [*,address_id,line_1,line_2,city,zip_postcode,state_province_county,country]
Table Candidate_Assessments, columns = [*,candidate_id,qualification,assessment_date,asessment_outcome_code]
...続きはhttps://arxiv.org/pdf/2304.11015.pdfで
クエリ分類と分解( Classification & Decomposition Module)
クエリを3つのクラスに分類します。
- Easyクラス:
- 単一のテーブルで回答できる簡単なクエリなので中間ステップのないシンプルなfew-shotのプロンプトで十分!
- Non-nested Complexクラス:
- エラー分析でわかってることですが、2つのテーブルをJOINするための正しい列と外部キーを見つけることがLLMにとって難しい可能性がある。
- なので自然言語→中間表現(NatSQL)→SQL と順々に変換していく
- Nested Complexクラス:
- サブクエリやネストを含む複雑な質問
プロンプト
プロンプトで、以下を盛り込んでクエリの分類を実行してます。
- instruction
- For the given question, classify it as EASY, NON-NESTED, or NESTED based on nested queries and JOIN. if need nested queries: predict NESTED
elif need JOIN and don’t need nested queries: predict NON-NESTED
elif don’t need JOIN and don’t need nested queries: predict EASY
- For the given question, classify it as EASY, NON-NESTED, or NESTED based on nested queries and JOIN. if need nested queries: predict NESTED
- どのテーブルのどのカラムに外部キーついてるか
- 大量の実行例
- Few-shot プロンプトだねえ
# For the given question, classify it as EASY, NON-NESTED, or NESTED based on nested queries
and JOIN.
if need nested queries: predict NESTED
elif need JOIN and don’t need nested queries: predict NON-NESTED
elif don’t need JOIN and don’t need nested queries: predict EASY
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Foreign_keys = [course.dept_name = department.dept_name,instructor.dept_name = department.dept_name,section.building = classroom.building,section.room_number = classroom.room_number,
section.course_id = course.course_id,teaches.ID = instructor.ID,teaches.course_id = section.course_id,teaches.sec_id = section.sec_id,teaches.semester = section.semester,
teaches.year = section.year,student.dept_name = department.dept_name,takes.ID = student.ID,takes.course_id = section.course_id,takes.sec_id = section.sec_id,takes.semester =
section.semester,takes.year = section.year,advisor.s_ID = student.ID,
advisor.i_ID = instructor.ID,prereq.prereq_id = course.course_id,prereq.course_id =
course.course_id]
Q: "Find the buildings which have rooms with capacity more than 50."
schema_links: [classroom.building,classroom.capacity,50]
A: Let’s think step by step. The SQL query for the question "Find the buildings which have rooms
with capacity more than 50." needs these tables = [classroom], so we don’t need JOIN.
Plus, it doesn’t require nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we
need the answer to the questions = [""].
So, we don’t need JOIN and don’t need nested queries, then the the SQL query can be classified as
"EASY".
Label: "EASY"
Q: "What are the names of all instructors who advise students in the math depart sorted by
total credits of the student."
schema_links: [advisor.i_id = instructor.id,advisor.s_id = student.id,instructor.name, student.dept_name,student.tot_cred,math]
A: Let’s think step by step. The SQL query for the question "What are the names of all instructors
who advise students in the math depart sorted by total credits of the student." needs these tables =
[advisor,instructor,student], so we need JOIN.
Plus, it doesn’t need nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we
need the answer to the questions = [""].
So, we need JOIN and don’t need nested queries, then the the SQL query can be classified as
"NON-NESTED".
Label: "NON-NESTED"
Q: "How many courses that do not have prerequisite?"
schema_links: [course.*,course.course_id = prereq.course_id]
A: Let’s think step by step. The SQL query for the question "How many courses that do not have
prerequisite?" needs these tables = [course,prereq], so we need JOIN.
Plus, it requires nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we need
the answer to the questions = ["Which courses have prerequisite?"].
So, we need JOIN and need nested queries, then the the SQL query can be classified as "NESTED".
Label: "NESTED"
...続きはhttps://arxiv.org/pdf/2304.11015.pdfで
SQL生成(SQL Generation Module)
Classification & Decomposition Moduleで分類したクエリごとに処理を生成処理を実行していく。
- Easyクラス:
- 単一のテーブルで回答できる簡単なクエリですね。必要なテーブルとカラムを選んで、条件があればWHERE句に入れるだけで終わり
プロンプト
- instruction
- Use the the schema links to generate the SQL queries for each of the questions.
- どのテーブルのどのカラムに外部キーついてるか
- 大量の実行例
- Few-shot プロンプトだねえ
#Use the the schema links to generate the SQL queries for each of the questions.
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Q: "Find the buildings which have rooms with capacity more than 50."
Schema_links: [classroom.building,classroom.capacity,50]
SQL: SELECT DISTINCT building FROM classroom WHERE capacity > 50
Q: "Find the room number of the rooms which can sit 50 to 100 students and their buildings."
Schema_links: [classroom.building,classroom.room_number,classroom.capacity,50,100]
SQL: SELECT building , room_number FROM classroom WHERE capacity BETWEEN 50 AND
100
Q: "Give the name of the student in the History department with the most credits."
Schema_links: [student.name,student.dept_name,student.tot_cred,History]
SQL: SELECT name FROM student WHERE dept_name = ’History’ ORDER BY tot_cred DESC
LIMIT 1
Q: "Find the total budgets of the Marketing or Finance department."
Schema_links: [department.budget,department.dept_name,Marketing,Finance]
SQL: SELECT sum(budget) FROM department WHERE dept_name = ’Marketing’ OR dept_name =
’Finance’
Q: "Find the department name of the instructor whose name contains ’Soisalon’."
Schema_links: [instructor.dept_name,instructor.name,Soisalon]
SQL: SELECT dept_name FROM instructor WHERE name LIKE ’%Soisalon%’
Q: "What is the name of the department with the most credits?"
Schema_links: [course.dept_name,course.credits]
SQL: SELECT dept_name FROM course GROUP BY dept_name ORDER BY sum(credits) DESC
LIMIT 1
Q: "How many instructors teach a course in the Spring of 2010?"
Schema_links: [teaches.ID,teaches.semester,teaches.YEAR,Spring,2010]
SQL: SELECT COUNT (DISTINCT ID) FROM teaches WHERE semester = ’Spring’ AND YEAR
= 2010
...続きはhttps://arxiv.org/pdf/2304.11015.pdfで
- Non-nested Complexクラス:
- 複数のテーブルをJOINする必要があるので、LLMは適切なJOIN条件を考えながら、テーブルを結合していきます。
プロンプト
- instruction
- Use the the schema links and Intermediate_representation to generate the SQL queries for each of the questions.
- どのテーブルのどのカラムに外部キーついてるか
- 大量の実行例
- Few-shot プロンプトだねえ
# Use the the schema links and Intermediate_representation to generate the SQL queries for each of
the questions.
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Foreign_keys = [course.dept_name = department.dept_name,instructor.dept_name = department.dept_name,section.building = classroom.building,
section.room_number = classroom.room_number,section.course_id = course.course_id,teaches.ID =
instructor.ID,teaches.course_id = section.course_id,
teaches.sec_id = section.sec_id,teaches.semester = section.semester,teaches.year = section.year,
student.dept_name = department.dept_name,takes.ID = student.ID,takes.course_id = section.course_id,takes.sec_id = section.sec_id,takes.semester = section.semester,
takes.year = section.year,advisor.s_ID = student.ID,advisor.i_ID = instructor.ID,prereq.prereq_id =
course.course_id,prereq.course_id = course.course_id]
Q: "Find the total budgets of the Marketing or Finance department."
Schema_links: [department.budget,department.dept_name,Marketing,Finance]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables
= [].
First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: select sum(department.budget) from department where department.dept_name = "Marketing" or department.dept_name = "Finance"
SQL: SELECT sum(budget) FROM department WHERE dept_name = ’Marketing’ OR dept_name =
’Finance’
Q: "Find the name and building of the department with the highest budget."
Schema_links: [department.budget,department.dept_name,department.building]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables
= [].
First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: select department.dept_name , department.building from department
order by department.budget desc limit 1
SQL: SELECT dept_name , building FROM department ORDER BY budget DESC LIMIT 1
Q: "What is the name and building of the departments whose budget is more than the average budget?"
Schema_links: [department.budget,department.dept_name,department.building]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables
= [].
First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: select department.dept_name , department.building from department
where @.@ > avg ( department.budget )
SQL: SELECT dept_name , building FROM department WHERE budget > (SELECT avg(budget)
FROM department)
Q: "Find the total number of students and total number of instructors for each department."
Schema_links: [department.dept_name = student.dept_name,student.id,department.dept_name =
instructor.dept_name,instructor.id]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables
= [department,student,instructor].
First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: "select count( distinct student.ID) , count( distinct instructor.ID) ,
department.dept_name from department group by instructor.dept_name
SQL: SELECT count(DISTINCT T2.id) , count(DISTINCT T3.id) , T3.dept_name FROM
department AS T1 JOIN student AS T2 ON T1.dept_name = T2.dept_name JOIN instructor AS T3
ON T1.dept_name = T3.dept_name GROUP BY T3.dept_name
...続きはhttps://arxiv.org/pdf/2304.11015.pdfで
- Nested Complexクラス:
- サブクエリごとにSQLをCoTプロンプトで解決しながらも、基本はNon-nested Complexクラスと同じ方法でSQL生成します。
プロンプト
- instruction
- Use the intermediate representation and the schema links to generate the SQL queries for each of the questions.
- どのテーブルのどのカラムに外部キーついてるか
- 大量の実行例
- Few-shot プロンプトだねえ
#Use the intermediate representation and the schema links to generate the SQL queries for each of the questions.
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Foreign_keys = [course.dept_name = department.dept_name,instructor.dept_name = department.dept_name,section.building = classroom.building,section.room_number = classroom.room_number,
section.course_id = course.course_id,teaches.ID = instructor.ID,teaches.course_id = section.course_id,teaches.sec_id = section.sec_id,teaches.semester = section.semester,teaches.year =
section.year,student.dept_name = department.dept_name,takes.ID = student.ID,takes.course_id =
section.course_id,
takes.sec_id = section.sec_id,takes.semester = section.semester,takes.year = section.year,advisor.s_ID
= student.ID,advisor.i_ID = instructor.ID,prereq.prereq_id = course.course_id,prereq.course_id =
course.course_id]
Q: "Find the title of courses that have two prerequisites?"
Schema_links: [course.title,course.course_id = prereq.course_id]
A: Let’s think step by step. "Find the title of courses that have two prerequisites?" can be solved
by knowing the answer to the following sub-question "What are the titles for courses with two
prerequisites?".
The SQL query for the sub-question "What are the titles for courses with two prerequisites?" is
SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id
GROUP BY T2.course_id HAVING count(*) = 2
So, the answer to the question "Find the title of courses that have two prerequisites?" is =
Intermediate_representation: select course.title from course where count ( prereq.* ) = 2 group by
prereq.course_id
SQL: SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id
GROUP BY T2.course_id HAVING count(*) = 2
...続きはhttps://arxiv.org/pdf/2304.11015.pdfで
自己修正(Self-correction Module)
最後に生成したSQLを校正する。
たとえば、「カラムが抜けてないか」とか「いらないカラムが入ってないか」とか「GROUPBYがない」とかの細かい部分を修正します。
これはZero-shotで十分らしいです。
精度は?
Spider(ベンチマークデータセット)での精度評価
Spiderは、テキスト to SQL のタスクにおいて広く使われているベンチマークデータセットです。200以上のデータベースにまたがる10,000以上の質問と、それに対応する複雑なSQLクエリが含まれています。質問は、簡単なものから非常に複雑なものまで、幅広い難易度をカバーしています。
Spiderでの精度評価は以下です。

(referenced by DIN-SQL: Decomposed In-Context Learning of
Text-to-SQL with Self-Correction)
DIN-SQL+GPT-4がEX(実行精度)で従来の手法(RED-SQL 3B + NatSQL)を上回りましたが、EM(完全一致精度))では従来手法の方が優れていました。
ではEMとEXのどっちを見ればいいのでしょうか?
EM(完全一致精度)とEX(実行精度)の違い
EMとEXの違いは以下です。
| 指標 | 説明 |
|---|---|
| EX(実行精度) | 生成されたSQLクエリの実行結果が正解のSQLクエリの実行結果と一致するかどうか |
| EM(完全一致精度) | 生成されたSQLクエリが正解のSQLクエリと文字列レベルで完全に一致するかどうか |
| 結論から言うとEXの方を見ておいた方がいいです。 |
一見すると、EMの方が厳密で、SQLクエリの正確さを直接評価しているように思えます。しかし、実際にはEXの方が、より実用的な指標だと思います。
- 同じ結果を返すSQLクエリは複数ある
例えば、以下の2つのSQLクエリは、結果的に同じテーブルを返します。
SELECT * FROM users WHERE age > 20;
SELECT * FROM users WHERE age >= 21;
EMでは、これらのクエリは別物として扱われます。つまり、正解がage > 20であった場合、age >= 21はたとえ結果が同じでも不正解となってしまうのです。
一方、EXでは、これらのクエリは同一視されます。実行結果が同じであれば、クエリの表記が多少異なっていても正解と判定されるわけです。
- 実用上は、SQLクエリの実行結果こそが重要
テキスト to SQL の究極的な目的は、ユーザの質問に正しく答えることです。そのためには、生成されたSQLクエリが文字列として正解と一致しているかどうかよりも、そのSQLクエリを実行した結果が正しいかどうかの方が重要ですね。
BIRD(ベンチマークデータセット)での精度評価
BIRDは、実世界のさまざまなドメインから収集された大規模なデータベースを含むデータセットらしいです。
BIRDの精度がいい方がより、現実での応用に使えそうとのことで、実際に精度評価の確認はEX(実行精度)とVES(実行効率)を使います。

(referenced by DIN-SQL: Decomposed In-Context Learning of
Text-to-SQL with Self-Correction)
DIN-SQL (GPT-4使用) はテストセットでEX(実行精度)は一番高くて、VES(実行効率)はGPT-4よりちょっと劣るけど2位と他の手法と比べるとかなり高いですね。
モジュールどれか抜いたりしてもいいの?
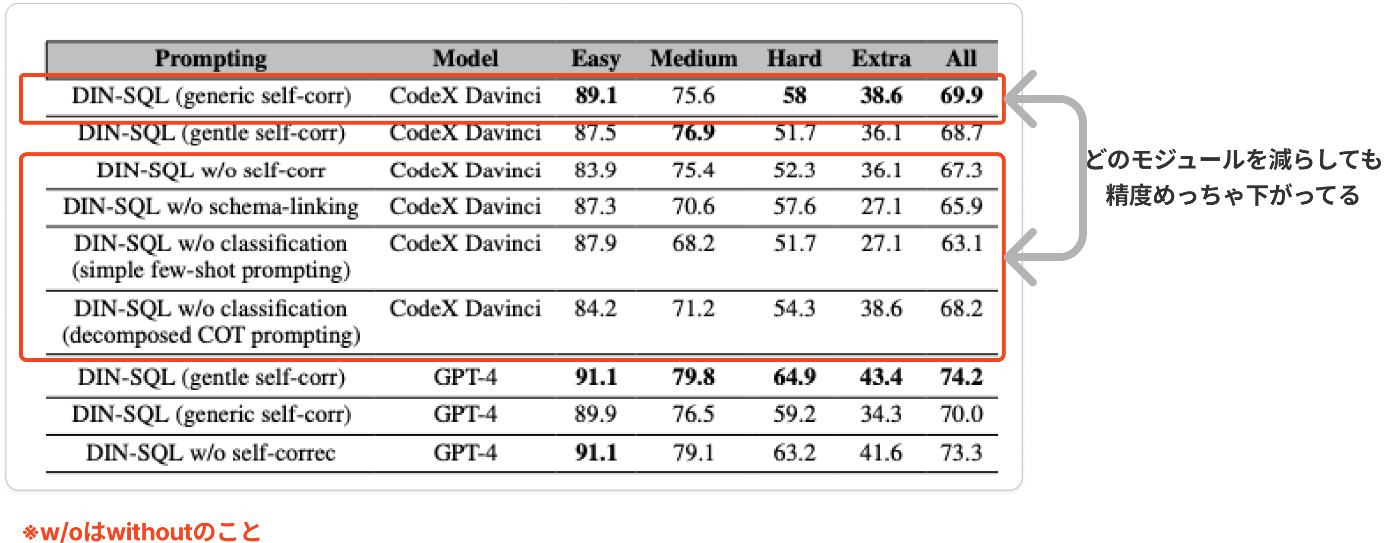
(referenced by DIN-SQL: Decomposed In-Context Learning of
Text-to-SQL with Self-Correction)
DIN-SQLの論文では、スキーマリンキング、クエリ分類、自己修正の各モジュールを取り除いた場合のパフォーマンスが報告されています。
その結果、どのモジュールを取り除いた場合でも、全体的な性能(実行精度)が低下するようです。
ただ、この表を見ると、現実のタスクの難易度ごとを考慮しながらモジュールを抜いたりしてもいいかもしれません。
例えば、簡単なタスクにはself correlationが効くから入れるけどスキーマリンキングは入れなくてもいいかもしれないです。
実行効率を上げたい場合は、モジュールを入れたり抜いたりしてチューニングすることは試してもいいですね!
最後に
自然言語からSQLへの変換を高い精度で行いたい場合、DIN-SQLは検討してもいい手法だと私は思いました。
ただし、プロジェクトに割ける時間や労力に応じて、アプローチを選択する必要があります。
簡単なタスクであればFew-shotプロンプトのみで十分な精度が得られるかもしれませんし、一方で複雑なタスクに取り組む場合は、DIN-SQLの各モジュールをタスクに合わせてチューニングして精度と実行効率をプロジェクトにフィットするか試すのも有効かもしれません。
プロジェクトの要件とリソースを考慮しながら、最適なアプローチを選択していくことが重要ですね!(自戒)
Xやってるのでぜひフォローお願いします。
@hudebakonosoto
Discussion