Transformerを理解するため!今からでもAttention入門 ~ イメージ・仕組み・コードの3面で理解する ~
はじめに
どうもどうも、やまぐちです。
今回はTransformerアーキテクチャの中核をなすAttentionについて重点的に解説したいと思います。
Attentionのイメージ・仕組み・コードの三つの側面から解説することでAttentionの理解につながるかと思います。
記事全体を通して、Attentionの説明にはTransformerの文脈を交えながら解説するように心がけましたのでAttention自体の理解は進むはずです!
解説はできる限り理解しやすいイメージに落とし込んでいます。できる限り正確に解説することを心掛けていますが、もし不正確な点があればご指摘いただけると幸いです。
Transformerの中のAttention
まずはよくあるTransformerの全体図です。
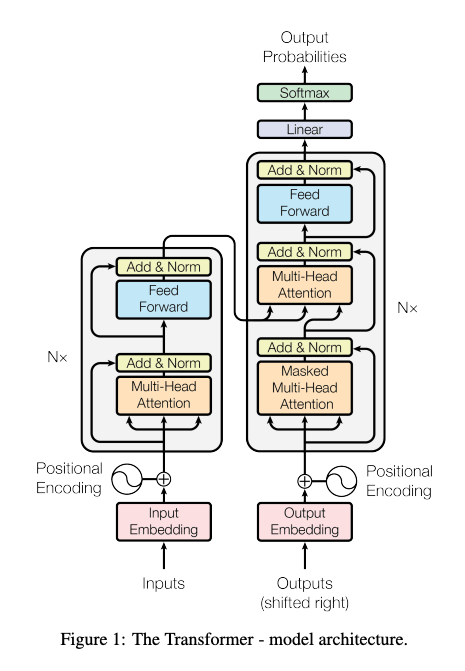
(Referenced by https://arxiv.org/pdf/1706.03762)
上記の図を見て、RNNやLSTMなどに慣れ親しんだ人なら、初めて目にするのは主に以下の2つでしょう。
- 位置エンコーディング(Positional Encoding)とは何か?
- マルチヘッドアテンション(Multi-Head Attention)とは何か?
Transformer以前の深層学習の自然言語処理モデルはRNNやLSTMなどを使用しており、これらには計算の並列化が難しいという制約がありました。
そこでTransformerはSelf-Attention機構を中心としてモデルを作成することで、この制約を克服していきました。
そう、Attentionのおかげなのです。
本記事では、Transformerの核心ともいえるマルチヘッドアテンションの仕組みを理解するために、その基礎となるAttentionの概念について詳しく解説していきます。
位置エンコーディングに関しても短くまとめていますので興味がある方はご覧ください!
位置エンコーディングとは?
Transformerモデルは、RNNのようなシーケンシャルな処理を行わないので並列処理が可能となり、訓練速度が大幅に向上します。
しかし、並列処理のため、シーケンス内のトークン(単語など)の位置や順序情報が失われる問題が生じます。
例えば自然言語処理(NLP)のタスクでは、単語やトークンの順序が非常に重要です。例えば、「私は昨日映画を見た」と「映画を見た私は昨日」は意味が異なります。このように、シーケンス内の位置情報がなければ、文脈の理解や意味の解釈が困難になります。
このような問題を位置エンコーディング(Positional Encoding)の導入で解決します。
位置情報をモデルに提供するために、位置エンコーディングが使用されます。
このエンコーディングは、入力埋め込みに対して追加され、トークンの相対的または絶対的な位置を示す情報を付加します。
具体的には、正弦波(sin)と余弦波(cos)を用いて次のように計算されます:
ここで、(pos) は位置、(i) は次元です。
これを入力埋め込みに対して足し算し、Attentionの入力として使用します。
他にも位置埋め込みという位置情報を学習させてベクトル化する方法もありますが以下の点で位置エンコーディングは有用です。
-
学習が不要: 位置エンコーディングは事前に決まった方式(正弦波と余弦波)で計算するので、追加で学習する必要がありません。このため、モデルの学習が少しシンプルになります。
-
順序情報の付加: 位置エンコーディングを使うことで、各単語やトークンがシーケンス内でどの位置にあるかの情報を簡単に付加できます。これにより、モデルはシーケンスの順序情報を理解できます。
-
長いシーケンスにも対応: 学習された位置埋め込みとは異なり、正弦波ベースの位置エンコーディングは既定の数式で位置を計算するので、訓練中に遭遇したことのない長いシーケンスにも対応することができます。
ちなみに論文中では、学習された位置埋め込みと正弦波ベースの位置エンコーディングを比較しています。
結果はほとんど同じでしたが、位置エンコーディングの方が上述の利点を持つため、位置エンコーディングが選ばれています。
使い分けがあるみたいですが、あまり私は把握していないです。
1.Attentionをイメージで理解する
AttentionではKey-Value-Queryという3つの要素を使ってコンテキストを作成します。ここでのコンテキストとは、「ある単語に着目したときに、その単語と関連が深い周辺の単語の情報」のことを指します。
Attention機構が何なのかをイメージで理解するために、4コマ漫画を描いてみました。
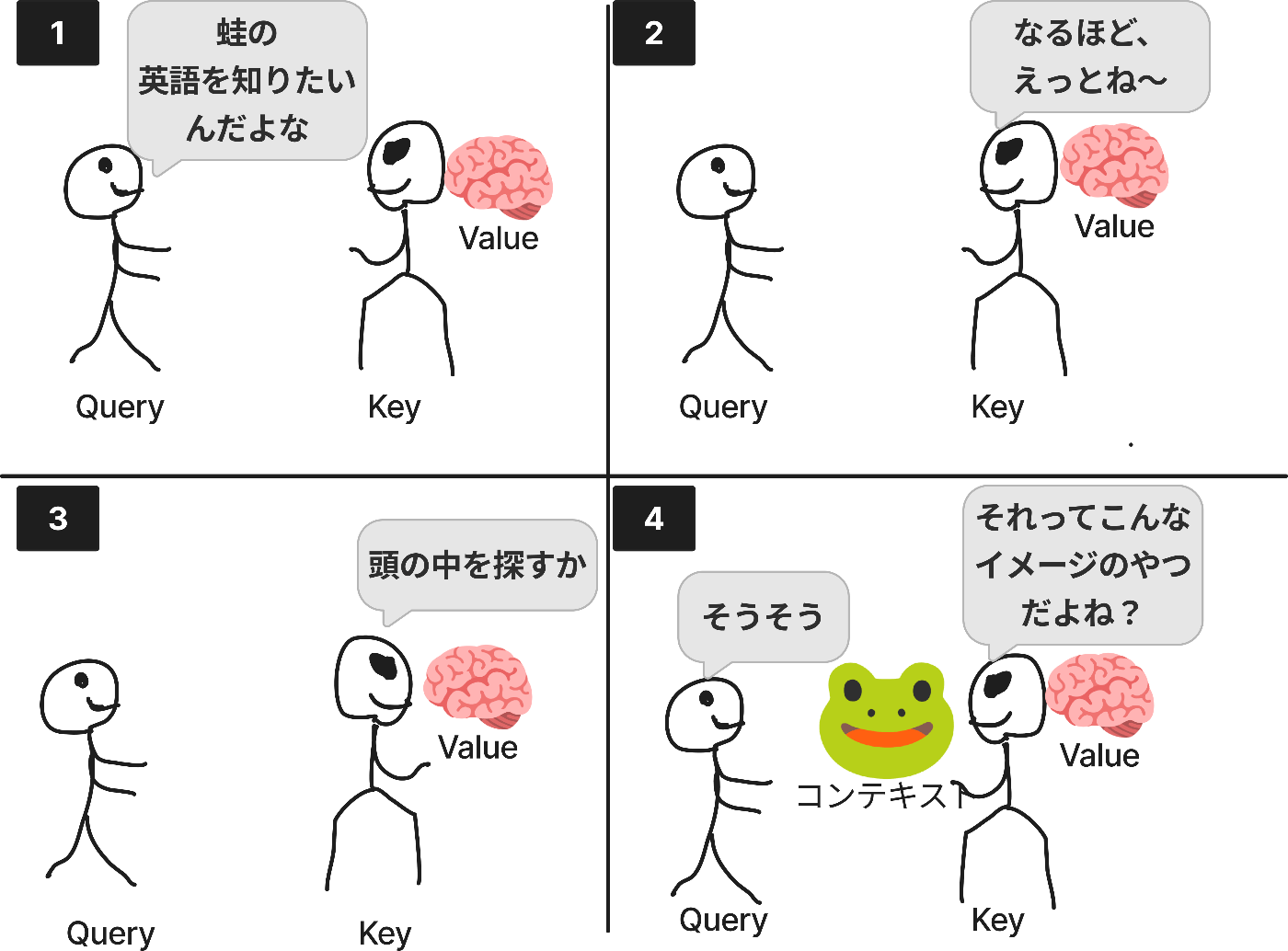
かなりアバウトな情報なので、不正確な部分もあるのですが、かなり言い得てるんじゃないでしょうか?
説明させてもらうと、
- 1コマ目: 「蛙の英語を知りたいんだよな」というQueryが登場します。
- 2コマ目: QueryがKey-Valueに聴きにいきます。KeyはQueryから関連度の高いやつを見つけようとしています。
- 3コマ目: QueryとKeyの関連度を考えてKeyの頭の中のValueと突き合わせます。
- 4コマ目: その結果、🐸というイメージが出てきました。選ばれた🐸がコンテキストになります。🐸には「緑色で、目が2つあって、目が飛び出ている」などの情報が含まれています。
これはつまりは、言われたことを解釈して(QueryとKeyを突き合わせて)、自分の知っていること(Value)からイメージ(コンテキスト)を作成したのです。
Atentionでは、上記のようなことをしています。
※ 異論あれば、ご指摘ください。
2.Attentionを仕組みで理解する。
イメージがついたところで、仕組みを追っていきましょう。
Attentionの仕組みの流れは以下の図のようになっています。
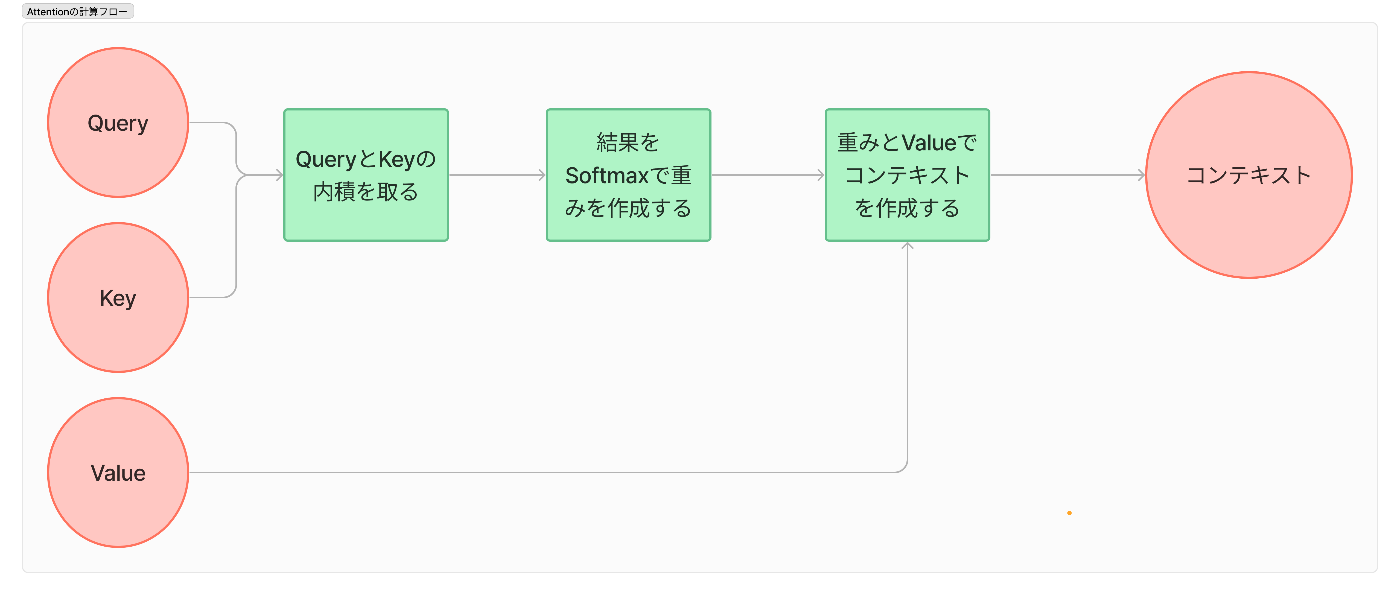
これらを「どんな行列で、どんな計算をするのか」を見ていきたいと思います。
①入力
まずは入力です。
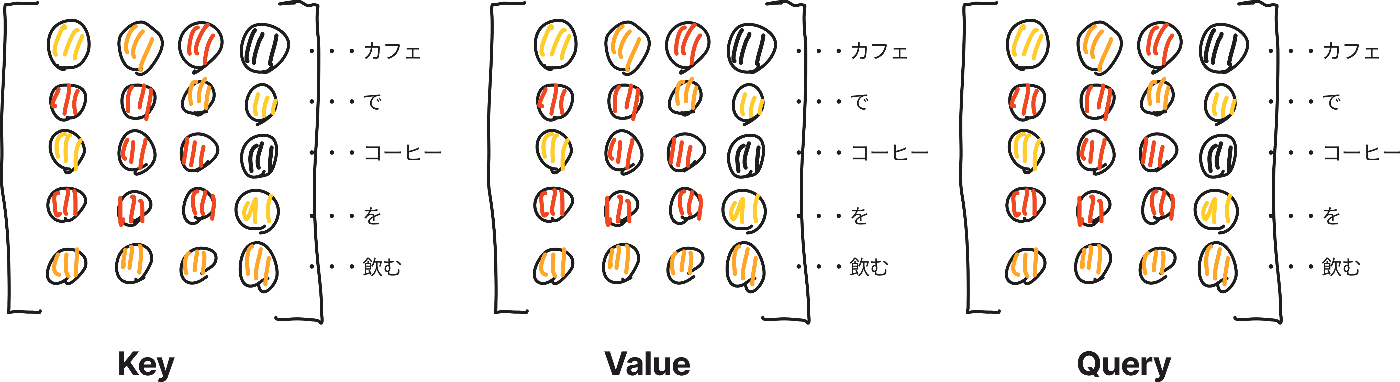
これらは前のレイヤーである入力埋め込みと位置エンコーディングの組み合わせたものを入力であるKey、Value、Queryとして使用します。
②QueryとKeyの内積
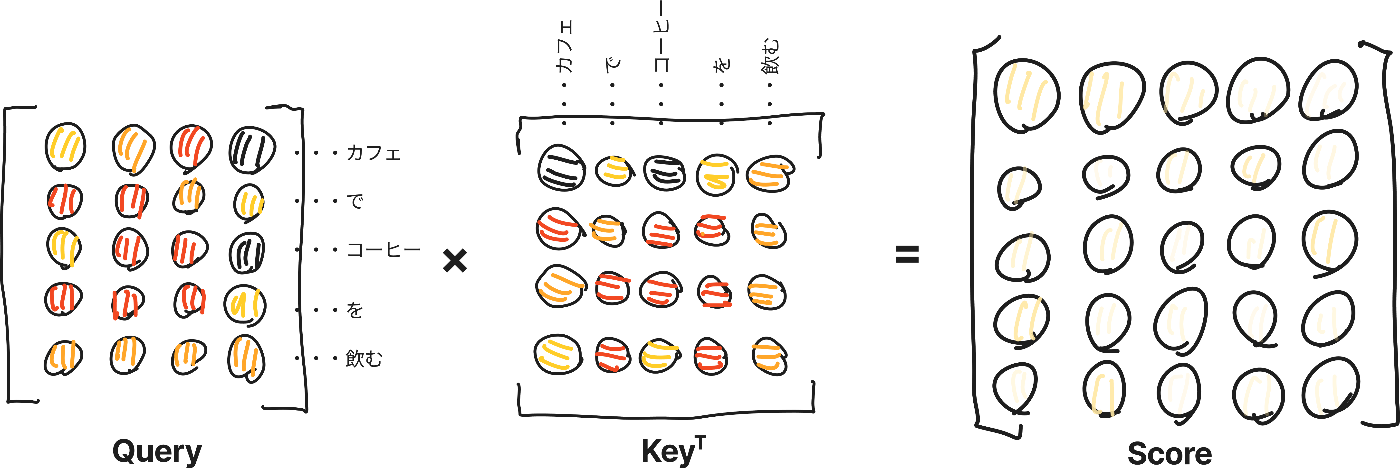
QueryとKeyの内積をとります。
ここはイメージで言うと、Queryに対してKeyの内積をとることでQueryとKeyの類似度がわかります。つまりQueryがどのKeyに対して反応するかが確認できます。検索みたいなもんですね。
ここではQueryとKeyの内積を取ると類似度が出力されます。これをScoreとします。
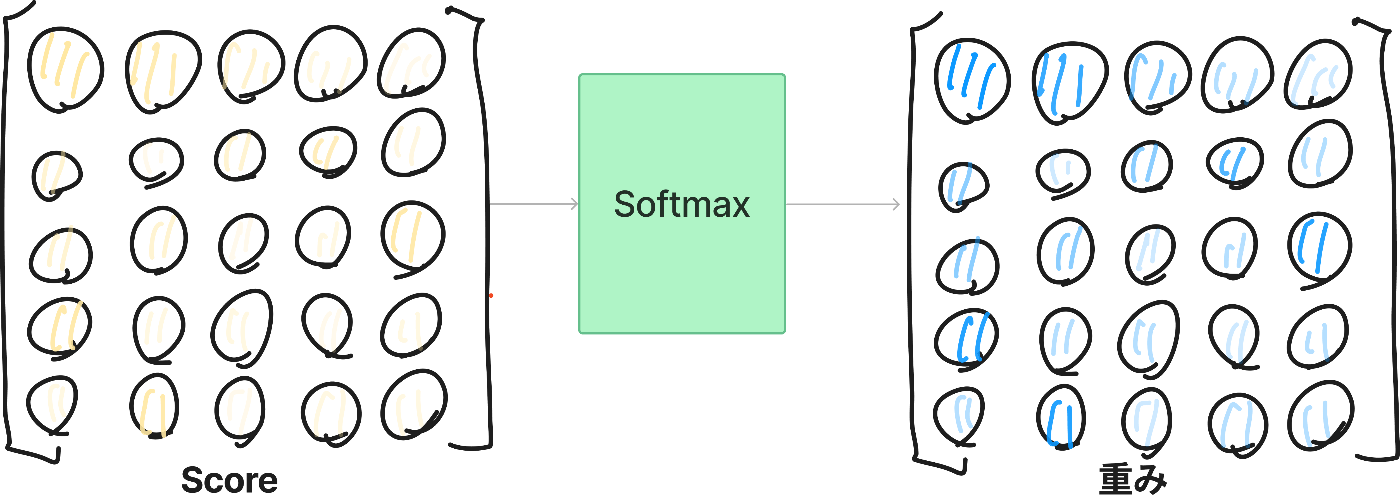
③Softmaxで確率で重みづけ行列を作成する
出てきた出力であるスコアは類似度ごとの重み付けとして使用したいので、Softmaxを通すことで重み付けの行列に変換しましょう。
④重みづけ行列とValueでコンテキストを作成する
最後に出てきたスコアから、どの程度どのトークンのベクトルをどれぐらいの割合で含めるかが明確になります。
出力される値であるコンテキストには、入力したい内容のイメージ・意味が入っているのでしたね。
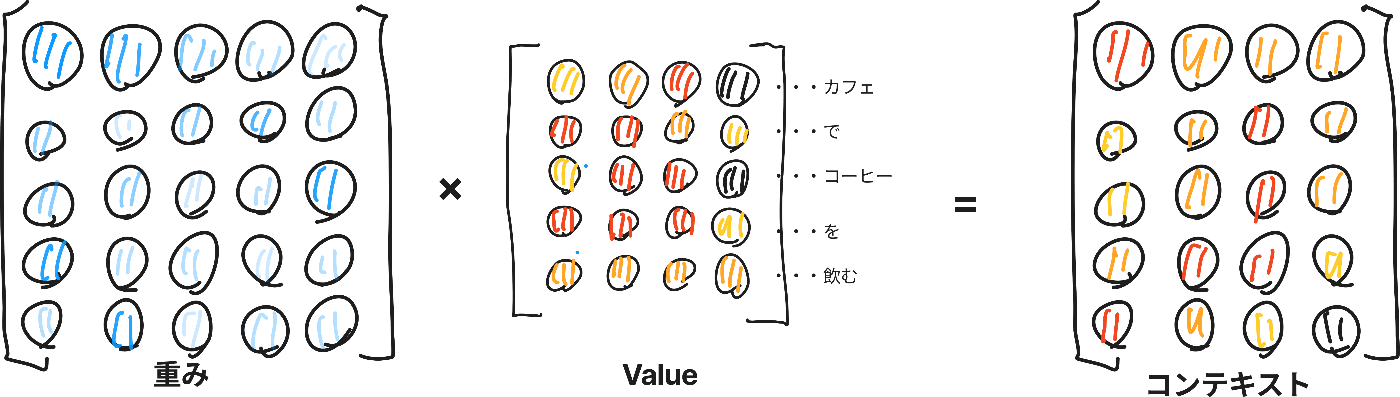
①~④までをまとめると、「QueryとKeyの内積から得られる類似度をSoftmaxで重みに変換し、Valueに掛けることで、入力文における各トークン間の関連性を反映した埋め込み表現」が得られます。これは、コンテキストを考慮した埋め込み表現であることを示しています。
実際に仕組みを追っていくだけでも4コマ漫画が納得感のあるイメージだったとご理解いただけると思います。
(おまけ1)Multi-Head Attention
実際にAttentionそのものが使われているのではなく、MultiHeadAttentionという形で使用されます。
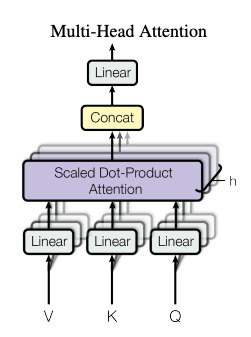
(Referenced by https://arxiv.org/pdf/1706.03762)
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions
https://arxiv.org/pdf/1706.03762 P.5
元論文のAttention Is All You Needでは、複数のAttentionHeadを使うことで、入力の異なる側面や表現部分空間の情報を同時に考慮できるようになるようです。
(おまけ2)Masked Multi-Head Attention
実際の図にはMasked Multi-Head Attentionとして出てきますが、ここでは簡単のためにMasked Attentionとして説明します。
Transformerのデコーダーにおいて出てくるAttentionです。
デコーダーでは時刻tから次の時刻t+1の出力をする。なので出力は時刻t以前の入力にのみ依存するべきで、それ以降の情報を見てはいけません。見せてしまっては、意味がないからです。
なのでMasked Attentionはスコアの段階で未来に出てくるトークン部分をマスクしてしまって使わないようにしよう!というためのメカニズムです。結構簡単でイメージは以下です。
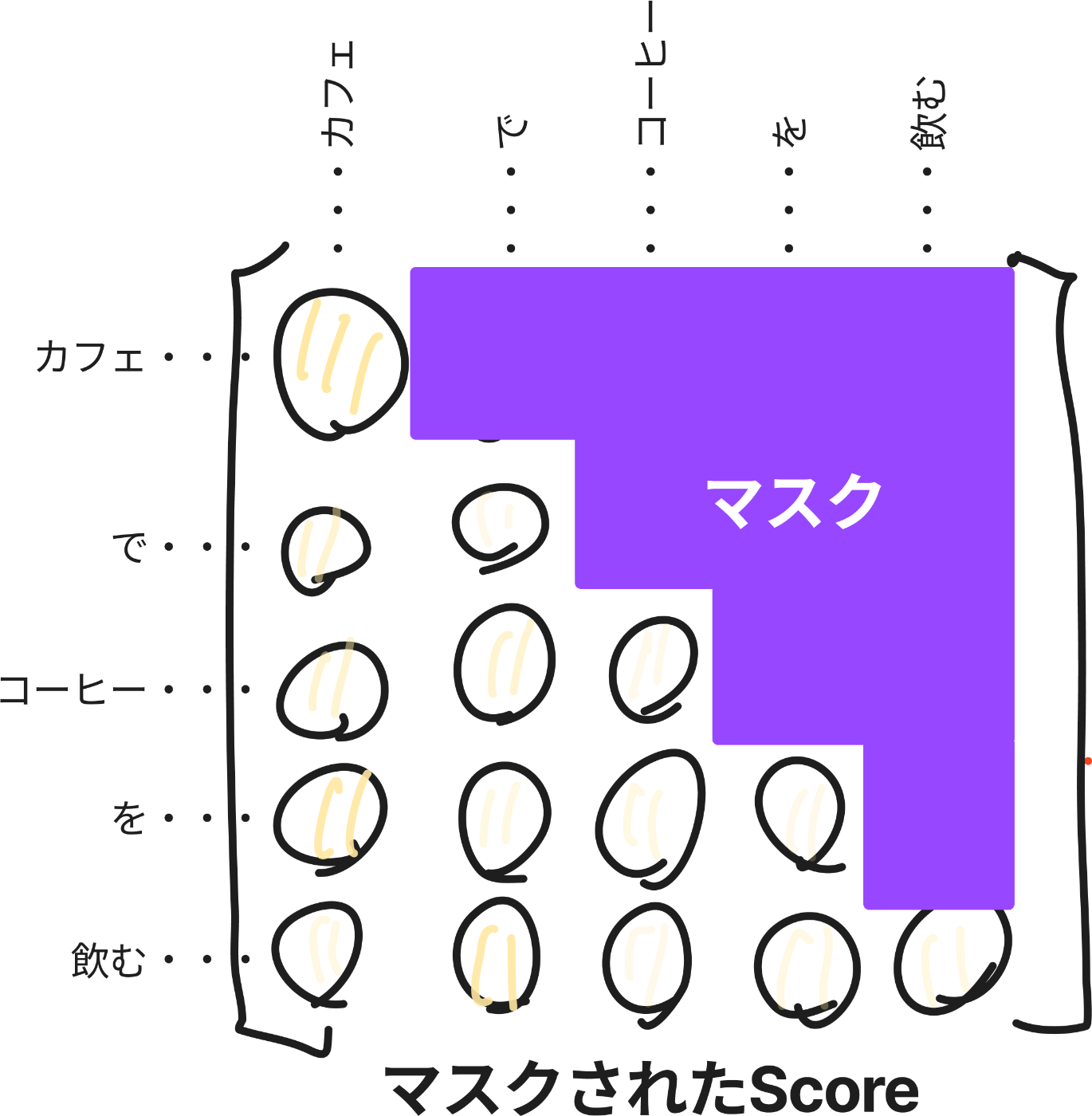
実装では、−∞にマスクすることでSoftmax関数からの出力が0することで未来の内容が見えないようにします。
3.Attentionをコードで理解する。
最後にコードを見ながら、より詳しくAttentionを理解してみましょう。
ここでのコードは機械学習エンジニアのためのTransformers 最先端の自然言語処理ライブラリによるモデル開発の第3章のコードを一部改変したものです。
計算ロジックの作成
「2. Attentionを仕組みで理解する。」で解説した内容をそのまま関数にします。
同時にバッチ計算できるような処理が入っているので少しみづらいですが、基本は解説した通りです。
import torch
from math import sqrt
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)
Attention層の作成
あとは実際にAttention層がどのようになるのか見ておきましょう。ついでにMulti-Head Attentionも記載しています。
from torch import nn
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, query, key, value):
attn_outputs = scaled_dot_product_attention(
self.q(query), self.k(key), self.v(value))
return attn_outputs
class MultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
embed_dim = hidden_size //隠れ層のサイズ
num_heads = num_attention_heads // アテンションヘッドの数
head_dim = embed_dim // アテンションヘッドの数
self.heads = nn.ModuleList([AttentionHead(embed_dim, head_dim) for _ in range(num_heads)] )
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value):
x = torch.cat([h(query, key, value) for h in self.heads], dim=-1)
x = self.output_linear(x)
return x
イメージを掴んで、仕組みを掴んだらかなりAttentionのコードが読みやすくなって、コードを読むことでさらに腹落ちできたのではないでしょうか?
最後に
Transformerで出てくるAttentionを理解するための記事を書いてみたのですがどうでしたか?
本当はTransformerの全体を解説する記事にしたかったのですが、大変だったのでAttentionだけに絞ってみました。
本当に今更ですが、せっかくなのでどこかでTransformer全体の解説も書いてみたいと思っています。
Xやってるのでぜひフォローお願いします。
@hudebakonosoto
参考文献
-
ゼロから作るDeep Learning ❷ 自然言語処理編 斎藤 康毅 著
- Attentionに関してはこれで理解しました
- https://www.oreilly.co.jp/books/9784873118369/
-
機械学習エンジニアのためのTransformers 最先端の自然言語処理ライブラリによるモデル開発 Lewis Tunstall、Leandro von Werra、Thomas Wolf 著、中山 光樹 訳
- Attentionのコードはこちらから転記
- https://www.oreilly.co.jp/books/9784873119953/
-
Attention Is All You Need
Discussion