ComfyUIでFLUX.1の各種つなぎ方サンプル
兼忘備録的な各種FLUX.1でのつなぎ方のサンプルです。
できるだけつなげ方を見やすくはしたつもりですが、見にくかったらすみません。
以下で紹介するワークフローをまとめたものは、以下になります。
基本
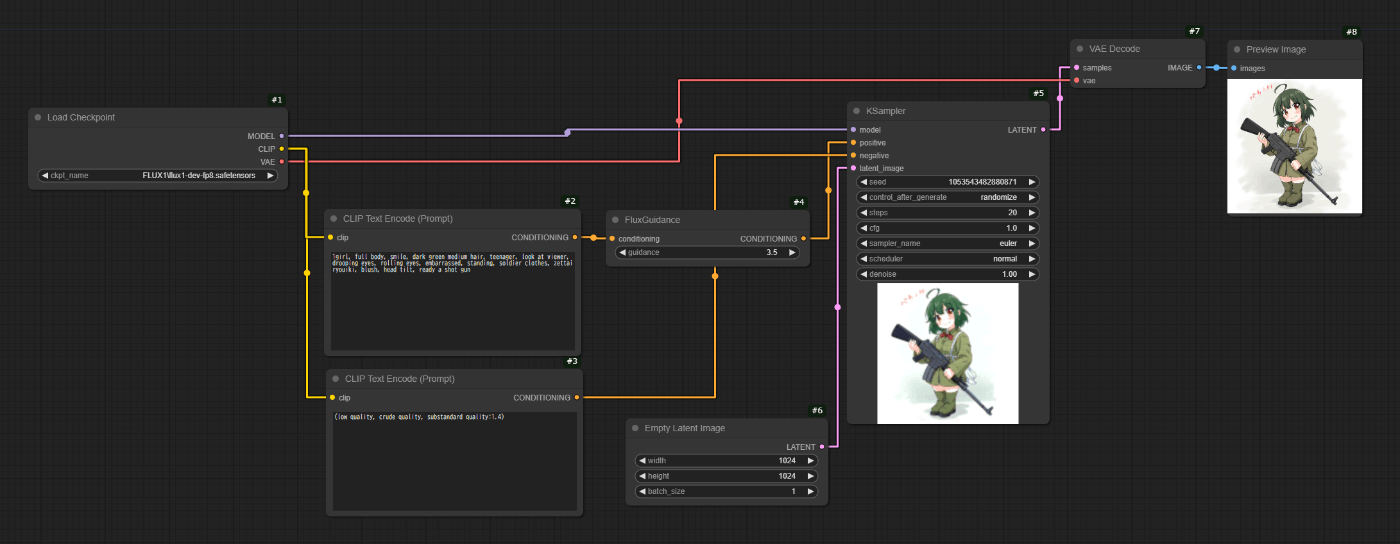
基本のつなげ方です。
何も凝ったことはしていません。
重要なのは、
- FluxGuidanceを忘れないこと
- KSamplerのcfgを1にすること
です。
CheckPointのsafesensorsはComfyUI Managerから取得できます。
マルチローダー

上記ワークフローが各種データローダーに分かれたバージョンです。
ここで気を付けるのは、ローダー系のtypeをfluxに設定しておくこと。
自分はこれ良く忘れます。
ここから以降はこのタイプのマルチローダーを使います。
いろいろ使いまわしているとこちらでないとダメなんですよねー。
DualClipのt5xxl以外は、ComfyUI Managerから取得できます。
t5xxlは下記からダウンロードしてください。
デュアルクリップエンコーダー
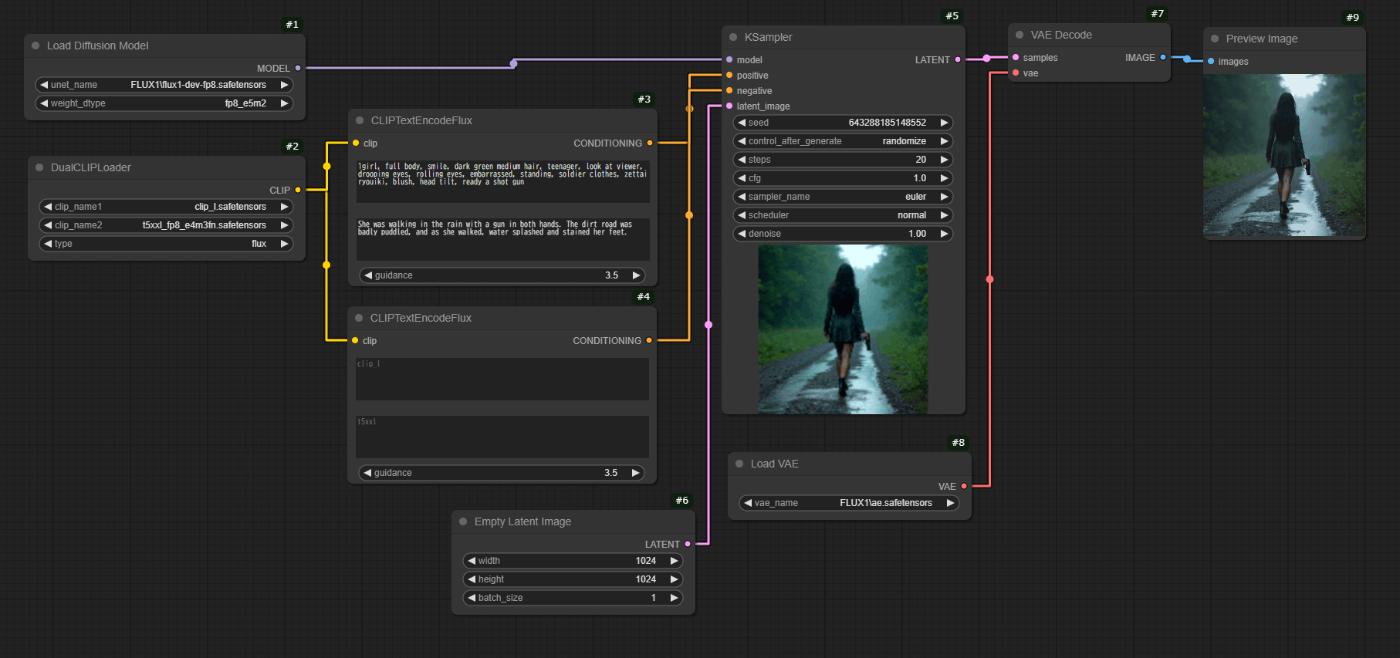
上記マルチローダーで、複数読み込んでいるCLIPに対して、それぞれプロンプトを入力できるようにしたタイプです。
CLIPを複数読み込んでそれぞれに条件を入力することで美しい絵作りが可能になるようです。
参考にしたのは下記の議論。
clip_lに対しては、単語をコンマで区切ったタイプのプロンプトを、t5xxlに対しては文章のプロンプトを、それぞれ与えるのが良いようです。
自分はclip_lで服装などのポイントポイントに関するものを、t5xxlには全体の風景や構図などを入力しています。
canny
こいつはメモリ喰います。
遅くなります。
お気をつけて。
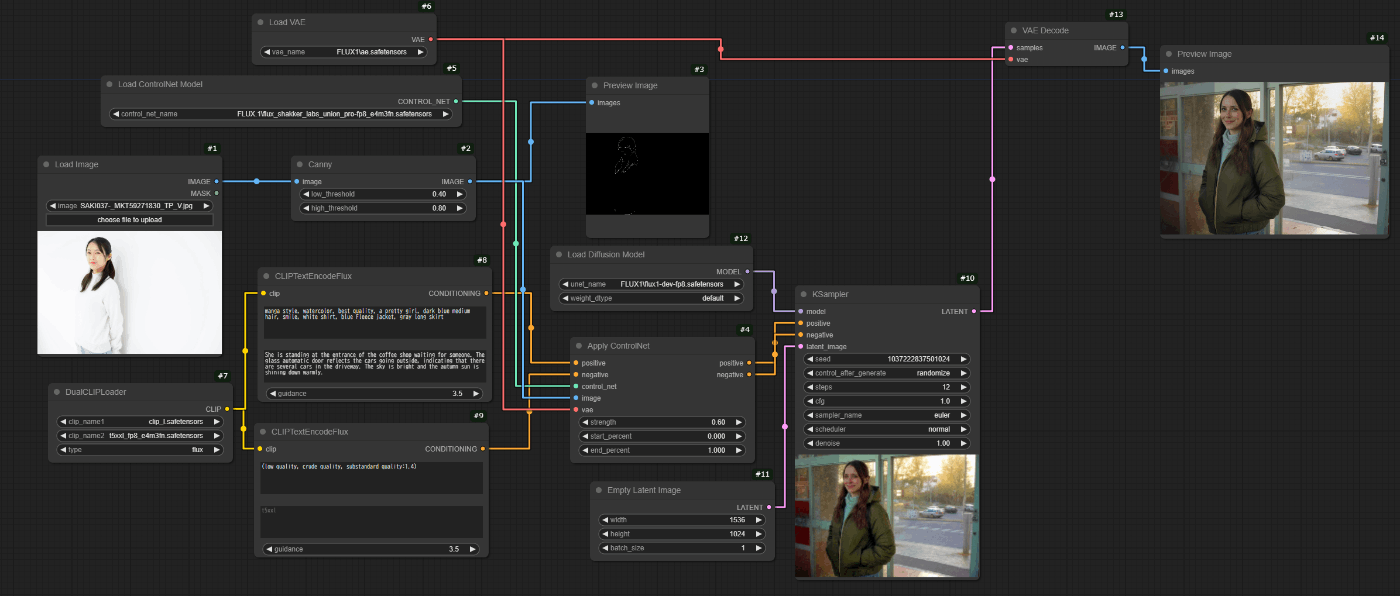
FLUX.1対応のControlNetで読み込めるモデルが出ているので、ComfyUI標準のノードだけでもここまでできます。
XLabs AIとか頑張って試したんですけどねぇ…。
そこまでクオリティを求めなければ、KSamplerのstepsが12でも十分な画像を出力してくれます。
さすがFLUX.1。
絵の方向性を見るためだけならば、6~7くらいでもわかりますね。
それであれば少ない時間でもなんとかなりそうな…。
(Stable Diffusionに比べれば全然長いですけどねー)
Discussion