difyをすべてローカルで動かす手順の話
difyとは
difyのメインサイトはこちらで。
なんかAIアプリがRAGでフロー形式でなんやからのツールっぽいです。
(まだ触って日が浅い)
ローカルで動かせるということなので、動かしてみました。
外に情報は出したくないけどAI使ったツールは動かしたい、とかいう欲求があればチャレンジしてみてください。
作成したシステム関連の環境
| 項目 | 内容 |
|---|---|
| CPU | i5第8世代 |
| RAM | 64G |
| OS | Windows11 |
| GPU | (#0) RTX3060 12G |
| GPU | (#1) RTX3050 6G |
RTX3050はロープロのGPUです。
i5第6世代のマシンに着けてたのですが、Windows10がサポート切れそうなので止めた関係上、GPU2枚刺しにしました。
(ディスプレイは(#1)につけて、(#0)はcudaに使うようにしています)
大前提として、NVIDIAのドライバはインストールしておいてください。
環境構築
以降のコマンドライン入力のターミナルは以下になります。
| プロンプト | 環境 |
|---|---|
| > | Windowsコマンドライン |
| $ | wsl上仮想環境一般ユーザー |
| # | wsl上仮想環境rootユーザー |
wslで仮想環境作成
> wsl --install Ubuntu-24.04
> wsl --shutdown
> wsl --export Ubuntu-24.04 ubuntu-24.04.tar
> wsl --import Dify-Ubuntu24 dify-ubuntu24 ubuntu-24.04.tar
最初の行のインストール後に一般ユーザーを作成します。
wsl import 後にデフォルトログインアカウントが設定されなくなるので、アカウントは覚えておきます。
仮想環境初期設定
以降は、作成した Dify-Ubuntu24 上で作業です。
# vi /etc/wsl.conf
[user]
default = xxx
ユーザーが切り離されているので、デフォルトでログインする一般ユーザーを指定します。
xxxの部分はUbuntuをインストールしたときに指定したユーザーを指定してください。
その後、wslを一度起動しなおします。
> wsl --terminate Dify-Ubuntu24
基礎環境更新
ここ以降は、普通にUbuntu環境と同じです。
Ubuntu実機で動かす際にはここ以降を参考にしてください。
まずは、パッケージを更新します。
$ sudo apt update
$ sudo apt upgrade -y
Dockerインストール
基本はこちらになります。
$ sudo apt-get update
$ sudo apt-get install ca-certificates curl
$ sudo install -m 0755 -d /etc/apt/keyrings
$ sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
$ sudo chmod a+r /etc/apt/keyrings/docker.asc
$ echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ sudo apt-get update
$ sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
NVIDIA Container Toolkitインストール
Docker composerのyamlをGPUで動くように書くので、NVIDIA Container Toolkitをインストールします。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit
DockerにNVIDIA Container Toolkitを認識させます。
$ sudo nvidia-ctk runtime configure --runtime=docker
$ sudo systemctl restart docker
sudo ばかりなんだからデフォルトユーザー指定しなくていいじゃん、なんて話は無しの方向で。
difyダウンロード
Gitでdifyを取得します。
$ cd ~
$ git clone https://github.com/langgenius/dify.git
ローカルモデル対応
ローカルでモデルを動かすツールを動かすようにdocker composeファイルを書き換えます。
動かすツールは、ollamaとxinferenceです。
patch用diffファイルは以下になります。
適当なファイル名つけて保存してください。
複数GPUにさせるためにGPU idを書いているので、必要なければ device_ids: の行を削除してください。
--- docker-compose.yaml 2024-11-19 12:11:02.602512200 +0900
+++ docker-compose.my.yaml 2024-11-20 05:00:01.999166000 +0900
@@ -297,6 +297,8 @@
depends_on:
- db
- redis
+ - ollama
+ - xinference
volumes:
# Mount the storage directory to the container, for storing user files.
- ./volumes/app/storage:/app/api/storage
@@ -317,6 +319,8 @@
depends_on:
- db
- redis
+ - ollama
+ - xinference
volumes:
# Mount the storage directory to the container, for storing user files.
- ./volumes/app/storage:/app/api/storage
@@ -827,6 +831,43 @@
volumes:
- ./volumes/unstructured:/app/data
+ # ollama
+ ollama:
+ image: ollama/ollama
+ container_name: ollama
+ restart: always
+ ports:
+ - ${OLLAMA_PORT:-11434}:11434
+ volumes:
+ - ./volumes/ollama:/root/.ollama
+ deploy:
+ resources:
+ reservations:
+ devices:
+ - driver: nvidia
+ capabilities: [gpu]
+ device_ids: ["0"]
+
+ # xinference
+ xinference:
+ image: xprobe/xinference:latest
+ container_name: xinference
+ restart: always
+ ports:
+ - ${XINFERENCE_PORT:-9997}:9997
+ volumes:
+ - ./volumes/xinference/xinference:/root/.xinference
+ - ./volumes/xinference/cache/huggingface:/root/.cache/huggingface
+ - ./volumes/xinference/cache/modelscope:/root/.cache/modelscope
+ deploy:
+ resources:
+ reservations:
+ devices:
+ - driver: nvidia
+ capabilities: [gpu]
+ device_ids: ["1"]
+ command: ['xinference-local', '-H', '0.0.0.0']
+
networks:
# create a network between sandbox, api and ssrf_proxy, and can not access outside.
ssrf_proxy_network:
上記パッチをdocker composeファイルに適用させ、必要なディレクトリを作成後、dockerコンテナを起動します。
$ cd dify/docker
$ cp .env.example .env
$ patch < docker-compose.my.patch
$ mkdir -p volumes/ollama volumes/xinference/xinference volumes/xinference/cache/huggingface volumes/xinference/cache/modelscope
$ sudo docker compose up -d
システムの環境構築は以上です。
動作設定
dify初期化
difyの初期設定を行います。
ブラウザでローカルページ(http://localhost/install)を開きます。

ollamaモデル読み込み
ollamaはLLM用モデルツールです。
コマンドラインからapiを使用してモデルを読み込ませます。
対応している基本モデルはこちら、全モデルはこちら。
$ curl http://localhost:11434/api/pull -d '{"model":"gemma2"}'
{"status":"success"} が出たら、念のためモデルが認識されているか確認します。
ここで表示されるモデル情報は後でdifyの設定をするときに使用します。
$ curl http://localhost:11434/v1/models
xinferenceモデル読み込み
xinferenceもLLM用モデルツールなのですが、対応を謳っているモデルがen zhに偏りがちです。
そこで、xinferenceにはrerank用モデルを読み込ませて使用します。
こちらはブラウザでの設定なので、ローカル(http://localhost:9997/)を読み込んで、rerankから

jina-rerankerを選び、

自分の場合はGPU id(GPU Idxと書いてあるところ)に「1」を入力して、左下のロケットのボタンを押します。
すると、モデルが読み込まれます。
(本当はbge-reranker-v2-gemma読み込みたいんですが、GPUのメモリが足りなくて…😭)
difyに基本モデルを設定
difyの左上のメニューから「設定」を選び、

モデルプロバイダーからollamaの下あたりにカーソルを合わせてボタンを出し、

ボタンを押してモデルを追加します。
モデル設定画面では、
| 設定箇所 | 設定 |
|---|---|
| Model Type | LLM |
| Model Name | gemma2:latest |
| Base URL | http://ollama:11434 |
と設定します。
Model Name の欄には上記ollamaでモデルを認識しているか確認したコマンドで id として出力されている文字列を設定し、左下の青い「保存」ボタンを押します。

設定後、モデルプロバイダー一覧の一番上に設定したモデルが表示されているので、「モデルの表示」にカーソルを合わせてください。
そこがボタンになるので押し、次のモデルを設定します。

ここの右上の「モデルを追加」を押し、「Text Embedding」を設定します。
設定する項目は上記と同じです。

次はollamaと同じように、Xorbits Inferenceからxinferenceの設定をします。

xinferenceの画面の Running Models で表示されているIDとNameを

| 設定箇所 | 設定 |
|---|---|
| Model Type | Rerank |
| Model Name | 上記のName欄 |
| Server url | http://xinference:9997 |
| Model uid | 上記のID欄 |
IDは Model uid の欄に、Nameは Model Name の欄に設定します。
Server urlは http://xinference:9997 を設定します。

設定すると、上部のモデル一覧が下記のようになります。
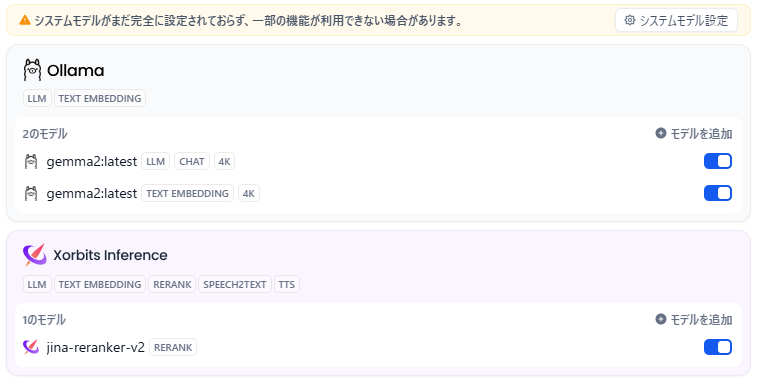
右上の「×」ボタンを押していったん設定画面を閉じ、ブラウザの更新を行って、再度設定画面を開きます。
そして、今設定したモデルが基本的に使用されるように設定されているか確認しましょう。
上の「システムモデル設定」のボタンを押します。

推論モデルと埋め込みモデルとRerankモデルが設定されていれば、問題ありません。
「保存」ボタンで保存しておきます。
ここら辺の設定で特に注意することは、 ブラウザで開くURLとdifyに設定するURLが違う ことです。
AIとチャットをしてみる
簡単なチャットボットを作ります。
difyのメインページ、 http://localhost/apps を表示し、「全て」→「最初から作成」を押し、
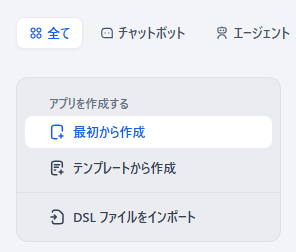
続く画面で「チャットボット」「チャットフロー」を選んで適当な名前を付け、「作成する」ボタンを押します。

フロー画面が出るので、「LLM」ノードに「Chat」のモデルが設定されていることを確認し、上部「プレビュー」ボタンを押します。
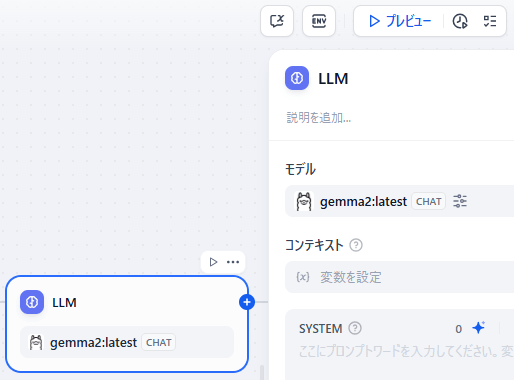
すると、右側がチャットボットの画面になるので、話してみましょう。

あとは右上「公開する」ボタンで今作ったチャットボットを(もちろんローカルになりますが)公開することができます。
以上です
以上で設定と簡単なアプリの作り方でした。
長くなってしまいましたが、設定が済んでしまえば簡単に動かすことができることはわかっていただけたと思います。
(むしろこっからのほうが長いよね)
Docker Desktopとwsl
そうそう。
なぜwslで動かして、Docker Desktop使わないのか、と。
まあそういう話もありますが、dify→ollamaやdify→xinferenceのルックアップが遅すぎるのでwsl使うほうがまし、という結論に至ったのでした。
上記 difyダウンロード 以降の設定でDocker Desktopでも問題なく動くことは確認してあります。
(先にDocker Desktopで作って絶望したのです)
Docker compose OVERRIDE ! (2024/11/22追記)
docker composeファイルってoverrideできるんですね!
さっき知りました!
Discussion