[Docker] LiteLLM + Langfuse をローカルにDockerで立ち上げる
はじめに(モチベーション)
最近、Cline等のAIを用いたエージェント型のツールが賑わっていますが、利用している内に以下の点が気になり始めました。
- AIとの通信内容の可視化
- 利用量の統計的な把握と分析
- 長期的なデータの保存と活用
これらの要件を満たすため、LiteLLMを中心としたプロキシ構成を採用し、各種AIツールからの通信を集約して情報を収集する方式を検討しました。この方式であれば、将来的なツールの移行にも柔軟に対応できます。
記事の目的
この記事では、Docker Compose(Docker Desktop)を用いて、ローカル環境にLiteLLM + Langfuse環境を構築し、AIツールからの呼び出しを長期的に保存・分析できる環境を整備する方法を解説します。
作業環境
- PC : MacBook Pro 14インチ / 2024
- 16コアCPU + 40コアGPU搭載 M4 Max
- 128 GB memory
- OS : macOS Sequoia 15.2
利用バージョン
| ツール | バージョン | 用途 | 補足 |
|---|---|---|---|
| Docker Desktop | 4.37.2 | Docker環境構築 | - |
| LiteLLM | 1.53.7 | OpenAI互換のProxyサーバー | 通信の共通化 |
| Langfuse | 3.23.0 OSS | OSSのLLM Opsツール | ロギング用途で利用 |
Langfuseのセットアップ
Langfuseとは
Langfuseは、LLMアプリケーションの開発・運用を支援するオープンソースプラットフォームです。主な機能は以下の通りです:
- 計測: LLM呼び出しのトレース、速度計測、コスト計測
- 管理: プロンプトのバージョン管理とデプロイ
- 評価: LLMを活用した評価、ユーザーフィードバックの収集
- テスト: データセットを用いたベンチマーク実施
今回は主にトレース機能を利用して、AIとの通信内容を記録・分析します。
インストール手順
公式GitHubリポジトリの手順に従ってセットアップを行います:
# Clone repository
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# Run server and database
docker compose up -d
実行結果
(main●●) ❯❯❯ docker compose up -d
[+] Running 65/5
✔ langfuse-web Pulled 41.8s
✔ postgres Pulled 64.2s
✔ clickhouse Pulled 78.1s
✔ redis Pulled 7.4s
✔ langfuse-worker Pulled 128.3s
[+] Running 7/7
✔ Network langfuse_default Created 0.0s
✔ Container clickhouse Healthy 5.9s
✔ Container minio Healthy 5.9s
✔ Container langfuse-redis-1 Healthy 3.9s
✔ Container langfuse-postgres-1 Healthy 3.9s
✔ Container langfuse-langfuse-web-1 Started 5.8s
✔ Container langfuse-langfuse-worker-1 Started
初期設定
- ブラウザで
http://localhost:3001にアクセス - Sign upからアカウントを作成

- 必要情報を入力してアカウントを作成

- Organizationを作成

- Projectを作成

- Settings > API Keysから新規APIキーを作成


- 表示された秘密鍵と公開鍵を保存

LiteLLMのセットアップ
LiteLLMとは
LiteLLMは、OpenAI互換のAPIフォーマットを提供するOSSライブラリ兼Proxyサーバーです。これにより、OpenAI/Anthropic/Gemini/Ollama等の様々なAIサービスへの統一的なアクセスが可能になります。
インストール手順
1. Docker-Compose.yamlの準備
LiteLLMのソースコードに同梱されているdocker-compose.ymlを修正します。
このあとconfig.yamlを用意するため、そのマウント設定を有効にしています。
diff --git a/docker-compose.yml b/docker-compose.yml
index 1508bd375c..af514a5ab7 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -8,10 +8,10 @@ services:
image: ghcr.io/berriai/litellm:main-stable
#########################################
## Uncomment these lines to start proxy with a config.yaml file ##
- # volumes:
- # - ./config.yaml:/app/config.yaml <<- this is missing in the docker-compose file currently
- # command:
- # - "--config=/app/config.yaml"
+ volumes:
+ - ./config.yaml:/app/config.yaml
+ command:
+ - "--config=/app/config.yaml"
##############################################
ports:
- "4000:4000" # Map the container port to the host, change the host port if necessary
2. 設定ファイルの準備
次に利用するAIサーバーの設定を記述するconfig.yamlと.envファイルを準備します。
config.yaml
config.yamlの書き方としてはmodel_listとして
- LiteLLMにアクセスする際に使用するモデルネームを
model_nameとして好きな名前で設定 - 対応する実際のAPIサーバーのモデル名を
{Provider名}/{モデル名}の形式で記述 - アクセスに必要なAPI Key は環境変数からとるように指定
のように記述します。
model_list:
- model_name: my-gpt-4o-mini
litellm_params:
model: openai/gpt-4o-mini
api_key: "os.environ/OPEN_AI_API_KEY"
利用できるProvider名の一覧は、公式ドキュメントのこちらを参照してください。
以下に私が記述したconfig.yamlを示しておきます。
config.yaml
model_list:
- model_name: gpt-4o-mini
litellm_params:
model: openai/gpt-4o-mini
api_key: "os.environ/OPEN_AI_API_KEY"
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: "os.environ/OPEN_AI_API_KEY"
- model_name: o1
litellm_params:
model: openai/o1
api_key: "os.environ/OPEN_AI_API_KEY"
- model_name: o1-mini
litellm_params:
model: openai/o1-mini
api_key: "os.environ/OPEN_AI_API_KEY"
- model_name: o3-mini
litellm_params:
model: openai/o3-mini
api_key: "os.environ/OPEN_AI_API_KEY"
- model_name: claude-3-5-sonnet
litellm_params:
model: anthropic/claude-3-5-sonnet-20241022
api_key: "os.environ/ANTHROPIC_API_KEY"
- model_name: claude-3-5-haiku
litellm_params:
model: anthropic/claude-3-5-haiku-20241022
api_key: "os.environ/ANTHROPIC_API_KEY"
- model_name: gemini-1.5-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: "os.environ/GEMINI_API_KEY"
- model_name: gemini-1.5-flash-8b
litellm_params:
model: gemini/gemini-1.5-flash-8b
api_key: "os.environ/GEMINI_API_KEY"
- model_name: gemini-1.5-flash
litellm_params:
model: gemini/gemini-1.5-flash
api_key: "os.environ/GEMINI_API_KEY"
- model_name: gemini-2.0-flash-exp
litellm_params:
model: gemini/gemini-2.0-flash-exp
api_key: "os.environ/GEMINI_API_KEY"
- model_name: phi4:latest
litellm_params:
model: ollama_chat/phi4:latest
api_base: "os.environ/OLLAMA_HOST"
litellm_settings:
drop_params: True
success_callback: ["langfuse"]
redact_user_api_key_info: true
.env ファイル
.envファイルには各種AIのAPI Key や、LangfuseのKeyを記述します。
LANGFUSE_SECRET_KEY/LANGFUSE_PUBLIC_KEYの箇所にLangfuseの設定で保存した秘密鍵と公開鍵を記述します。
LiteLLMのMasterKey、SaltKeyは公式の例をそのまま書いていますが、必要に応じて書き換えてください。
また通信先のHost情報としてLangfuse, Ollama のアドレスも記述します。
こちらは同一PC上に構築した物を利用するため、Docker のホスト通信用のアドレスでアクセスをします。
export LITELLM_MASTER_KEY="sk-1234"
export LITELLM_SALT_KEY="sk-1234"
export LANGFUSE_PUBLIC_KEY="pk-{LangFuseのPublic Key}"
export LANGFUSE_SECRET_KEY="sk-{LangFuseのSecret Key}"
export LANGFUSE_HOST="http://host.docker.internal:3001"
export OLLAMA_HOST="http://host.docker.internal:11434"
export OPEN_AI_API_KEY="sk-{Open AI のAPI Key}"
export GEMINI_API_KEY="{Google AI Studio のAPI Key}"
export ANTHROPIC_API_KEY="sk-{Anthropic のAPI Key}"
3. ビルドと起動
docker compose up -d
動作確認
curlコマンドを使用して、LiteLLMを介したAIモデルへのアクセスをテストします:
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "claude-3-5-sonnet",
"messages": [
{
"role": "user",
"content": "100までの素数"
}
]
}
実行結果
以下の通信結果が返ってきます。
実際に質問に対する回答が返ってきている事がわかります。
{"id":"chatcmpl-ea1887b3-ffc0-4d78-a74f-1a3e33eaaa1f","created":1738656931,"model":"claude-3-5-sonnet-20241022","object":"chat.completion","system_fingerprint":null,"choices":[{"finish_reason":"stop","index":0,"message":{"content":"100までの素数を順番に示します:\n\n2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97\n\n合計25個の素数があります。\n\n参考:\n- 最小の素数は2\n- 2は唯一の偶数の素数\n- 100までの素数は25個","role":"assistant","tool_calls":null,"function_call":null}}],"usage":{"completion_tokens":141,"prompt_tokens":13,"total_tokens":154,"completion_tokens_details":null,"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0},"cache_creation_input_tokens":0,"cache_read_input_tokens":0}}%
トレース確認
同様にLangfuse側でもトレース出来ている事を確認します。
Langfuseにログインしてプロジェクトを開くと、ダッシュボードにトレース数やコスト等の情報が表示されるようになっています。
-
ダッシュボードを表示

-
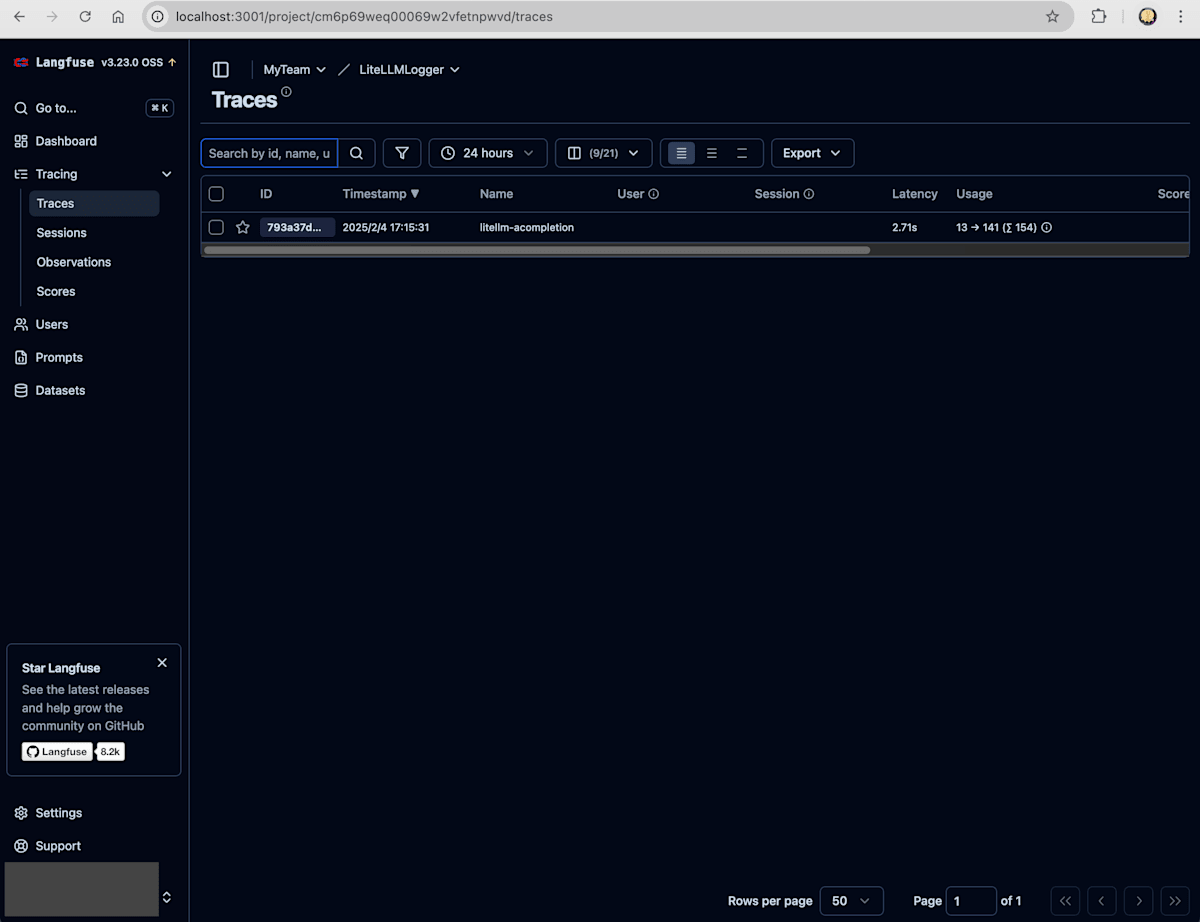
Tracesを開いて通信履歴を確認
-
トレース詳細で通信内容を確認

-
Observationsで詳細な統計情報を確認

Tracesではlitellm-acompletionという名前のトレース結果が追加されていることがわかります。そのトレース詳細では100までの素数という質問と、それに対するAIからの回答情報が記録されている事もわかります。これで実際にLiteLLMに対して要求したAI呼び出しが記録されている事を確認できました。
また、Observations の項目を開いてみると、通信の際に利用した実際のAIモデルの名前、呼び出しのレイテンシー、呼び出しコストといった情報も取得出来ている事がわかります。
結合チェック
最後に目的だったAIツール呼び出しの確認としてClineの呼び出しを確認します。
Clineが何かについては、いくらでも記事があるかと思いますので、ここでは詳しくは触れません。Editor上で動作するコード生成などを補助するAIアシスタントの一種です。利用するAIについては外部のプロバイダーを指定して好きなAIを使う事が出来る為、今回は設定を変更してLiteLLMを利用するようにします。
セットアップ
以下、Clineの設定画面です。これでLiteLLMと通信するようになります。
- API Provider :
OpenAI Compatibleを指定 - Base URL : 先ほどのLiteLLMのURL
http://0.0.0.0:4000を指定 - API Key :
.envのところで指定したLITELLM_MASTER_KEYの値を指定 - Model ID : LiteLLMのモデルリストに記載したモデル名を指定

呼び出しテスト
せっかくなので、この記事自体の推敲をClineに要求して記事を更新してもらいます。

計測結果
記事の修正結果はさておき、通信内容を確認します。
Tracesを確認すると、先ほどの1回の要求で3件もトレースが増えている事がわかります。

そのうちの一つを開いてみるとシステムプロントとして長文のメッセージが送られている事が確認できます。

スクロールし、ユーザープロンプトの部分を確認したところ、実際に記事のMarkdownファイルも送信されている事がわかります。

これで当初の目論見通り、AIツールからの呼び出し内容を可視化する事に成功しました。
まとめ
駆け足でしたが、今回は通信内容を取得するため、APIのProxyサーバーとロギング環境のセットアップを実施し、実際にツールからの通信を可視化しました。
これ自体は何か面白味のある内容ではないかと思いますが、日々新しく優秀なモデルが増えるAI界隈で面白可笑しくAIと遊ぶには、こういった足回りの整備もたまには必要かなと思いトライしました。最近はDockerで構築可能なOSSのツールが大量にあって、構築が本当に容易で素晴らしいですね。
Discussion