PyTorch にある画像認識モデル
公式ページ
事前学習済みモデルについて
torchvision.models サブパッケージの中には画像分類、セマンティックセグメンテーション、物体認識、インスタンスセグメンテーション、動画分類、オプティカルフローといった異なるタスクのためのモデル定義が含まれています。 TorchVision パッケージでは、提供されるすべてのモデルアーキテクチャに対して、事前学習済みの重みを提供しています。事前学習済みのモデルを使う際には、キャッシュディレクトリに重みがダウンロードされます。
ライブラリに含まれる事前学習済みのモデルは、それぞれ異なるライセンスや規約があります。あなたのユースケースに対してモデルが使用可能かどうかは、あなた自身が決定する責任があります。
事前学習済みモデルの初期化
TorchVision v0.13 以降では、異なる重みをロードするための Multi-weight support API を提供しています。
from torchvision.models import resnet50, ResNet50_Weights
# 精度 76.130% の古い重み
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# 精度 80.858% の新しい重み
resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# 現在利用可能な中で最高精度(現在は IMAGENET1K_V2 のエイリアス)
# バージョンごとに変更される可能性がある
resnet50(weights=ResNet50_Weights.DEFAULT)
# String もサポートされている
resnet50(weights="IMAGENET1K_V2")
# 重みなし(ランダムに初期化)
resnet50(weights=None)
新しい API にマイグレーションするのは非常に簡単です。以下の 2種類の関数呼び出しは、それぞれ同じです。
from torchvision.models import resnet50, ResNet50_Weights
# 事前学習済みの重みを使う場合:
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
resnet50(weights="IMAGENET1K_V1")
resnet50(pretrained=True) # 現在は非推奨
resnet50(True) # 現在は非推奨
# 事前学習済みの重みを使わない場合:
resnet50(weights=None)
resnet50()
resnet50(pretrained=False) # 現在は非推奨
resnet50(False) # 現在は非推奨
pretrained パラメータは現在では非推奨であり、 v0.15 で削除される予定です。
事前学習済みのモデルの使い方
事前学習済みのモデルを使う前に、モデルは適切な前処理(正しい解像度、補間方法でのリサイズ、値の理スケーリングなど)が必要です。前処理については、与えられたモデルがどのように訓練されたかに依存するため、標準的な方法はありません。正しい前処理手法を用いることは必須であり、間違えて前処理を行うと精度の低下や正しくない結果につながります。
推論の変換に必要なすべての情報は、モデルの重みに関するドキュメントに掲載されています。単純に推論するだけであれば、TorchVision が必要な前処理の変換をそれぞれのモデルの重みに組み込んでおり、 weight.transforms という attribute からアクセスすることが可能です。
import torch
from torchvision.models import ResNet50_Weights
# 重みと変換の初期化
weights = ResNet50_Weights.DEFAULT
preprocess = weights.transforms()
img = torch.zeros((3, 320, 240), dtype=torch.int8)
# 入力画像への適用
img_transformed = preprocess(img)
print(img.size())
print(preprocess)
print(img_transformed.size())
上記のコードの実行結果は以下のようになります。 ResNet では入力画像のサイズが 224x224 となっているため、入力した 320x240 の画像が 224x224 にリサイズされていることが分かります。
変換前: torch.Size([3, 320, 240])
ImageClassification(
crop_size=[224]
resize_size=[232]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BILINEAR
)
変換後: torch.Size([3, 224, 224])
いくつかのモデルは、 Batch Normalization のように訓練時と評価時に異なるふるまいを示すモジュールを使っています。これらのモードを切り替えるには model.train() と model.eval() を適切に使用してください。
# モデルの初期化
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
# モデルを評価モードにする
model.eval()
モデルの登録方法
TorchVision v0.14 以降では、モデル名からモデルや重みを取得できる新しいモデル登録メカニズムを提供しています。ここではいくつかの例を示しています。
# 現在利用可能なモデルの一覧
all_models = list_models()
classification_models = list_models(module=torchvision.models)
# モデルの初期化
m1 = get_model("mobilenet_v3_large", weights=None)
m2 = get_model("quantized_mobilenet_v3_large", weights="DEFAULT")
# 重みの取得
weights = get_weight("MobileNet_V3_Large_QuantizedWeights.DEFAULT")
assert weights == MobileNet_V3_Large_QuantizedWeights.DEFAULT
weights_enum = get_model_weights("quantized_mobilenet_v3_large")
assert weights_enum == MobileNet_V3_Large_QuantizedWeights
weights_enum2 = get_model_weights(torchvision.models.quantization.mobilenet_v3_large)
assert weights_enum == weights_enum2
それぞれのタスクに適した事前学習済みのモデルを探すには、以下のようなコードを実行します。
import torchvision
from torchvision.models import list_models
all_models = list_models()
classification_models = list_models(module=torchvision.models)
segmentation_models = list_models(module=torchvision.models.segmentation)
detection_models = list_models(module=torchvision.models.detection)
optical_flow_modesl = list_models(module=torchvision.models.optical_flow)
video_models = list_models(module=torchvision.models.video)
quantized_models = list_models(module=torchvision.models.quantization)
画像分類
TorchVision では、以下の画像分類モデルが利用可能です。
- AlexNet
- ConvNeXt
- DenseNet
- EfficientNet
- EfficientNetV2
- GoogLeNet
- Inception V3
- MaxVit
- MNASNet
- MobileNet V2
- MobileNet V3
- RegNet
- ResNet
- ResNeXt
- ShuffleNet V2
- SqueezeNet
- SwinTransformer
- VGG
- VisionTransformer
- Wide ResNet
事前学習済みモデルの分類クラスについての情報は weights.meta["categories"] を見てください。
import requests
from torchvision.io import read_image
from torchvision.models import resnet50, ResNet50_Weights
file_name = "orange.jpg"
url = f"https://github.com/opencv/opencv/blob/master/samples/data/{file_name}?raw=true"
response = requests.get(url)
blob = response.content
with open(file_name, "wb") as f:
f.write(blob)
img = read_image(file_name)
# Step 1: モデルの初期化(最高精度の重み)
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
model.eval()
# Step 2: 推論用の前処置変換の初期化
preprocess = weights.transforms()
# Step 3: 前処理変換の適用
batch = preprocess(img).unsqueeze(0)
# Step 4: モデルによる推論と予測されたカテゴリの表示
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
ここでは、以下のような画像を入力としています。

コードを実行すると以下のような出力が得られ、正しく推論できていることが分かります。
orange: 22.1%
AlexNet
概要
AlexNet [Krizhevsky 2012] は、 2012 年に Geoffrey Hinton 研究室の Alex Krinzhevsky と Ilya Sutskever らによって提案された、画像分類のための畳み込みニューラルネットワークアーキテクチャです。
CVMLエキスパートガイド によると、 AlexNet の特徴として次の4点を挙げています。
- 特徴 1 : ReLU の導入
- 特徴 2 : 過学習の削減
- 特徴 3 : 重なりあり最大値プーリング Overlapped max pooling
- 特徴 4 : 複数 GPU を使用した学習
モデル構成
コード
from torchsummary import summary
from torchvision.models import AlexNet, AlexNet_Weights
weights = AlexNet_Weights.DEFAULT
preprocess = weights.transforms()
print("Preprocess:")
print(preprocess)
model = AlexNet()
print("Model summary:")
summary(model, input_size=(3, 224, 224))
出力結果
Preprocess:
ImageClassification(
crop_size=[224]
resize_size=[256]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BILINEAR
)
Model summary:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 55, 55] 23,296
ReLU-2 [-1, 64, 55, 55] 0
MaxPool2d-3 [-1, 64, 27, 27] 0
Conv2d-4 [-1, 192, 27, 27] 307,392
ReLU-5 [-1, 192, 27, 27] 0
MaxPool2d-6 [-1, 192, 13, 13] 0
Conv2d-7 [-1, 384, 13, 13] 663,936
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 [-1, 256, 13, 13] 884,992
ReLU-10 [-1, 256, 13, 13] 0
Conv2d-11 [-1, 256, 13, 13] 590,080
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 [-1, 256, 6, 6] 0
AdaptiveAvgPool2d-14 [-1, 256, 6, 6] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 1000] 4,097,000
================================================================
Total params: 61,100,840
Trainable params: 61,100,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 8.38
Params size (MB): 233.08
Estimated Total Size (MB): 242.03
----------------------------------------------------------------
参考
ResNet
概要
ResNet [He 2016] (residual neural network: 残差ニューラルネットワーク) は、 2016 年に、 He らにより提案された CNN アーキテクチャであり、残差ブロックを多数つなげることにより、高精度の深い CNN を学習可能にしました。
残差ニューラルネットワークの文脈では、残差を用いないネットワークのことをしばしば plain network と呼ぶことがあるようです。
モデル構造
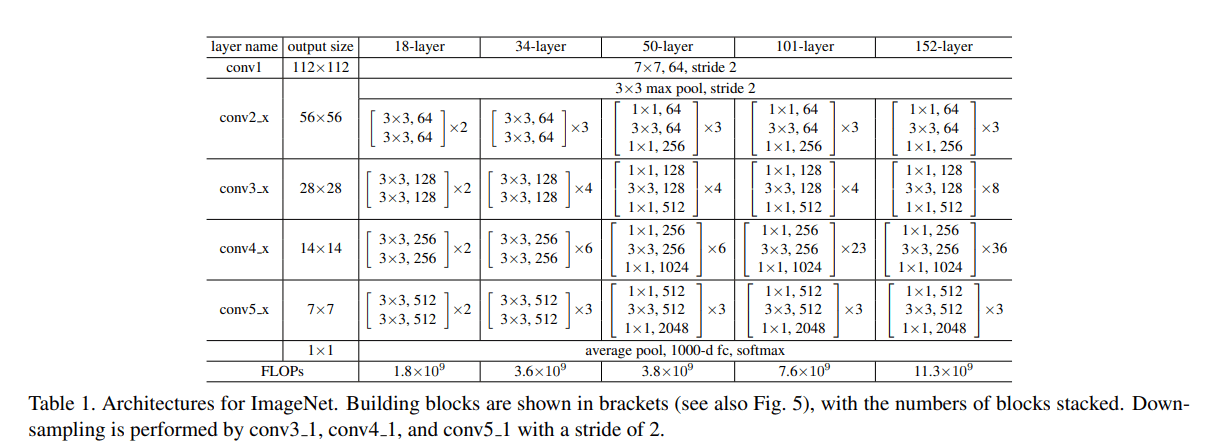
PyTorch では、 ResNet の層の数ごとに、 ResNet-18, 34, 50, 101, 152 という異なるモデルが提供されていますが、以下では一番層の数が少ない ResNet-18 のモデル構造を示しています
コード
from torchsummary import summary
from torchvision.models import resnet18, ResNet18_Weights
weights = ResNet18_Weights.DEFAULT
preprocess = weights.transforms()
print("Preprocess:")
print(preprocess)
model = resnet18()
print("Model summary:")
summary(model, input_size=(3, 224, 224))
出力結果
Preprocess:
ImageClassification(
crop_size=[224]
resize_size=[256]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BILINEAR
)
Model summary:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
以下に示した論文に記載されている構成と同じようになっていることが確認できます。まず、論文で言うところの conv1 layer は、 PyTorch では Conv2d 、 BatchNorm2d 、 ReLU の層から成っており、この層で channel が 3 から 64 になり、サイズが半分になっていることが分かります。次に論文の conv2_x layer 以降を見てみると、 PyTorch では、まず MaxPool2d のプーリング層に入力された後、 Conv2d → BatchNorm2d → ReLU → Conv2d → BatchNorm2d → ReLU → BasicBlock という層に繰り返し渡されます。最後の BasicBlock は ResNet における残差ブロックを実現するための nn.Module であり、公式ドキュメントで PyTorch の内部実装を確認することができます。
モデル検証のための特徴抽出
torchvision.models.feature_extraction パッケージは特徴抽出に関するユーティリティが含まれており、学習済みのモデルを利用して中間層の変換にアクセスすることが可能です。これは、コンピュータビジョンのあらゆる応用に有益であり、いかにいくつかの例を示します。
- 特徴マップの可視化
- 顔認識や文字認識などの画像記述子を算出することによる特徴抽出
- 特定タスクに焦点を当てた end-to-end 学習のために選択した特徴を下位ネットワークへ渡す(例: Feature Pyramid Networkに特徴量の階層を渡す)
Torchvision では、 create_feature_extractor() 関数を用いてこれらの目的を達成します。大まかには、次のステップで実行します。
- モデルをシンボリックにトレーシングし、入力がどのように変換されるかをグラフで表現する
- ユーザの選択したグラフノードをアウトプットとして設定する
- すべての冗長なノードを削除する
- グラフの結果から Python コードを生成し、 グラフ自体と一緒に PyTorch モジュールとしてまとめられる
symbolic tracing についての詳細な説明は torch.fx のドキュメントを参照してください。
ノードの名前について
どのノードが出力ノードにとくてい
例
import torch
from torchvision.models import resnet50
from torchvision.models.feature_extraction import get_graph_node_names
from torchvision.models.feature_extraction import create_feature_extractor
from torchvision.models.detection.mask_rcnn import MaskRCNN
from torchvision.models.detection.backbone_utils import LastLevelMaxPool
from torchvision.ops.feature_pyramid_network import FeaturePyramidNetwork
# 特徴抽出器の設計を助けるためにまず resnet50 の利用可能なノードを出力してみます
m = resnet50()
train_nodes, eval_nodes = get_graph_node_names(resnet50())
# 実行時(訓練時と検証時のそれぞれ)におけるすべてのグラフノード名が返されます
# この例では `train_nodes` と `eval_nodes` は同じ結果になります
# しかし、もしモデルが訓練モードに依存する制御フローを含む場合は、異なる結果となります。
# 抽出したいノードを特定するために、メインの層の最後のノードを選択可能です。
return_nodes = {
# node_name: user-specified key for output dict
'layer1.2.relu_2': 'layer1',
'layer2.3.relu_2': 'layer2',
'layer3.5.relu_2': 'layer3',
'layer4.2.relu_2': 'layer4',
}
# しかし `create_feature_extractor` は `layer1` のように短縮されたノード名も指定可能です。
# (ヒント: 層に複数の出力がある場合には注意が必要です。最後に実行された操作が
# 必ずしも希望する出力に対応するとは保証されていませんので、
# 入力モデルのコードを見て確認する必要があります)
return_nodes = {
'layer1': 'layer1',
'layer2': 'layer2',
'layer3': 'layer3',
'layer4': 'layer4',
}
# このように特徴抽出器を作成します。これにより、
# 以下のような辞書オブジェクトが返される forward メソッドを持ったモジュールが返されます
# {
# 'layer1': output of layer 1,
# 'layer2': output of layer 2,
# 'layer3': output of layer 3,
# 'layer4': output of layer 4,
# }
create_feature_extractor(m, return_nodes=return_nodes)
# それでは resnet50 with MaskRCNN をラップしてみましょう
# MaskRCNN は attached FPN を用いたバックボーンが必要です
class Resnet50WithFPN(torch.nn.Module):
def __init__(self):
super(Resnet50WithFPN, self).__init__()
# resnet50 バックボーンを取得する
m = resnet50()
# 4 つのメインレイヤーを抽出する
# 注意: MaskRCNN は特定の名前と return nodes のマッピングが必要です
self.body = create_feature_extractor(
m, return_nodes={f'layer{k}': str(v)
for v, k in enumerate([1, 2, 3, 4])})
# FPN用のチャンネル数を取得するために、仮で実行
inp = torch.randn(2, 3, 224, 224)
with torch.no_grad():
out = self.body(inp)
in_channels_list = [o.shape[1] for o in out.values()]
# FPN を構築する
self.out_channels = 256
self.fpn = FeaturePyramidNetwork(
in_channels_list, out_channels=self.out_channels,
extra_blocks=LastLevelMaxPool())
def forward(self, x):
x = self.body(x)
x = self.fpn(x)
return x
# ここからモデルを構築することが可能です!
model = MaskRCNN(Resnet50WithFPN(), num_classes=91).eval()