機械学習の推論WebAPIの実装をテンプレート化して使い回せるようした
概要
機械学習を利用したウェブサービスを開発していると、WebAPIとして外部から利用できる形で機械学習の推論を実行可能にしたいということがよくあると思います。私も幾度となくそうした実装をする中で使いまわし定番のコードを用意しているので、知識の棚卸しや改めて新しい技術を学ぶという意味でも、久しぶりに構造や技術スタックを刷新したものを今回作成しました。
そこで本記事は、テンプレート化した機械学習のWebAPI実装の構成と、そこから実際に機械学習の推論を行うWebAPIを作る過程を書いてみようと思います。
テンプレートプロジェクト
今回作ったテンプレートプロジェクトはyagays/fastapi-ml-templateです。
利用しているパッケージ/ツール
利用している技術スタックとしては以下のようになっています。
- Web API
- 開発
実行環境はローカルでの動作に加えて、DockerおよびDocker Compose両方で動くようにしています。
全体的におおよそモダンな技術選定になっているのではないかと思います。ウェブフレームワーク選定に関しては、特にこだわりがなければFastAPIを軸に、PydanticやUvicornなどの相性の良いパッケージと合わせて開発するのが良いと思っています。開発時のツールに関しては色々と趣味が出るところですので、お好きなものを利用すればいいと思います。
ディレクトリ/ファイル構成
レポジトリ内の構成は以下の通りです。
.
├── Dockerfile
├── README.md
├── app
│ ├── api
│ │ ├── api.py # 機械学習の推論のエンドポイント
│ │ └── heartbeat.py # WebAPIの外部監視用のエンドポイント
│ ├── core
│ │ ├── config.py # WebAPI全体の設定
│ │ └── event_handler.py # WebAPI起動/終了時に実行する処理
│ ├── main.py # WebAPI本体
│ ├── models
│ │ └── predict.py # WebAPIの入力/出力のモデル
│ └── services
│ └── model.py # 機械学習の推論の実装
├── docker-compose.yml
├── poetry.lock
├── pyproject.toml
├── run.sh # WebAPIの起動
├── tests
│ ├── conftest.py # テスト共通のfixtureの実装
│ └── test_api.py # WebAPIのテスト
└── tox.ini
細かくディレクトリを切るのは個人的にあまり好きではないので、今後APIや推論モデルの実装が増えていくことも考えて拡張性も担保しつつ、シンプルめに押さえています。
なお本実装は、FastAPI作者が公開しているテンプレート等を参考にしています。ちなみに、tiangolo/full-stack-fastapi-postgresqlは、フロントエンドにVue、バックエンドにFastAPI、DBにPostgreSQLを使った定番ウェブアプリの構成を雛形としてまとめたものであり、ウェブアプリ構築の方法や利用する技術スタックなどコンパクトに実装されているので、Pythonを使ったウェブアプリに興味ある人は一読をお勧めします。
- https://github.com/tiangolo/full-stack-fastapi-postgresql
- https://github.com/eightBEC/fastapi-ml-skeleton
機械学習の推論を実装してみる
それでは実際にこのテンプレートプロジェクトを利用して、機械学習の推論をWebAPI化してみましょう。今回は自然言語処理タスクとして、spaCyとGiNZAを使った日本語文書の固有表現抽出を実装してみます。入出力のインターフェイスとしては以下の通りです。
- 入力: テキスト
- 出力: 抽出した固有表現抽出の情報および入力テキスト
今回実装したものは、以下のレポジトリに置いてあります。
それではテンプレートプロジェクトからの変更点を個々に見ていきましょう。
推論部分の実装
まずは機械学習の推論部分の実装です。app/services/model.pyにSpacyGinzaNERModelクラスとして実装します。同ファイルに定義したBaseMLModelを継承する形で、推論はpredict()メソッドに詰め込みます。
class SpacyGinzaNERModel(BaseMLModel):
def __init__(self, ginza_model_name: str = "ja_ginza") -> None:
self.nlp = spacy.load(ginza_model_name)
def predict(self, input_text: str) -> List[Entity]:
doc = self.nlp(input_text)
return [Entity(text=e.text, start_char=e.start_char, end_char=e.end_char, label=e.label_) for e in doc.ents]
抽出した固有表現のクラスの実装
推論部分の返り値にEntityというクラスを利用しており、app/models/predict.pyの中で定義しています。これは抽出した固有表現を表す基本単位のオブジェクトで、WebAPIの出力部分にそのまま利用しますので、PydanticのBaseModelを利用して実装しています。
class Entity(BaseModel):
text: str
start_char: int
end_char: int
label: str
機械学習モデルを起動時に読み込む実装
機械学習のモデルはFastAPIの起動時に自動で読み込まれて利用可能なようにします。app/core/event_handler.pyで、先ほど実装した機械学習クラスのインスタンスを作成し、FastAPI()のapp.state内に入れておきます。
def _startup_model(app: FastAPI, ginza_model_name: str) -> None:
model_instance = SpacyGinzaNERModel(ginza_model_name)
app.state.model = model_instance
def start_app_handler(app: FastAPI, ginza_model_name: str) -> Callable:
def startup() -> None:
_startup_model(app, ginza_model_name)
return startup
また、設定ファイルからGiNZAのモデルファイル名を指定できるようしておきたいため、引数に取れるようにしています。これはapp/main.pyのhandlerの指定時に以下のような形でapp/core/config.pyに指定したsettingsの設定値を読み込むようにしています。
app.add_event_handler("startup", start_app_handler(app, settings.GINZA_MODEL_NAME))
その他
主な変更点は以上で終了です。他に必要な点で言えば、依存パッケージをpoetryでインストールしたり、プロジェクト名の変更したり、Dockerで動くようにしたりする程度ですので、ここでは割愛します。
実装した推論WebAPIの実行
それでは最後に、今回作成した固有表現抽出の推論WebAPIを実行してみます。ここではhttpieを使ってCLIから叩きます。
# Dockerを利用してコンテナ内でWebAPIを起動
$ docker build -f Dockerfile -t spacy-ginza-ner-webapi .
$ docker run -p 9000:9000 --rm --name spacy-ginza-ner-webapi -t -i spacy-ginza-ner-webapi
$ http POST http://127.0.0.1:9000/api/v1/predict \
input_text="2018年の夏にフランスに行った。ジベルニー村のジャン・クロード・モネの家で池に浮かぶ睡蓮を見た。"
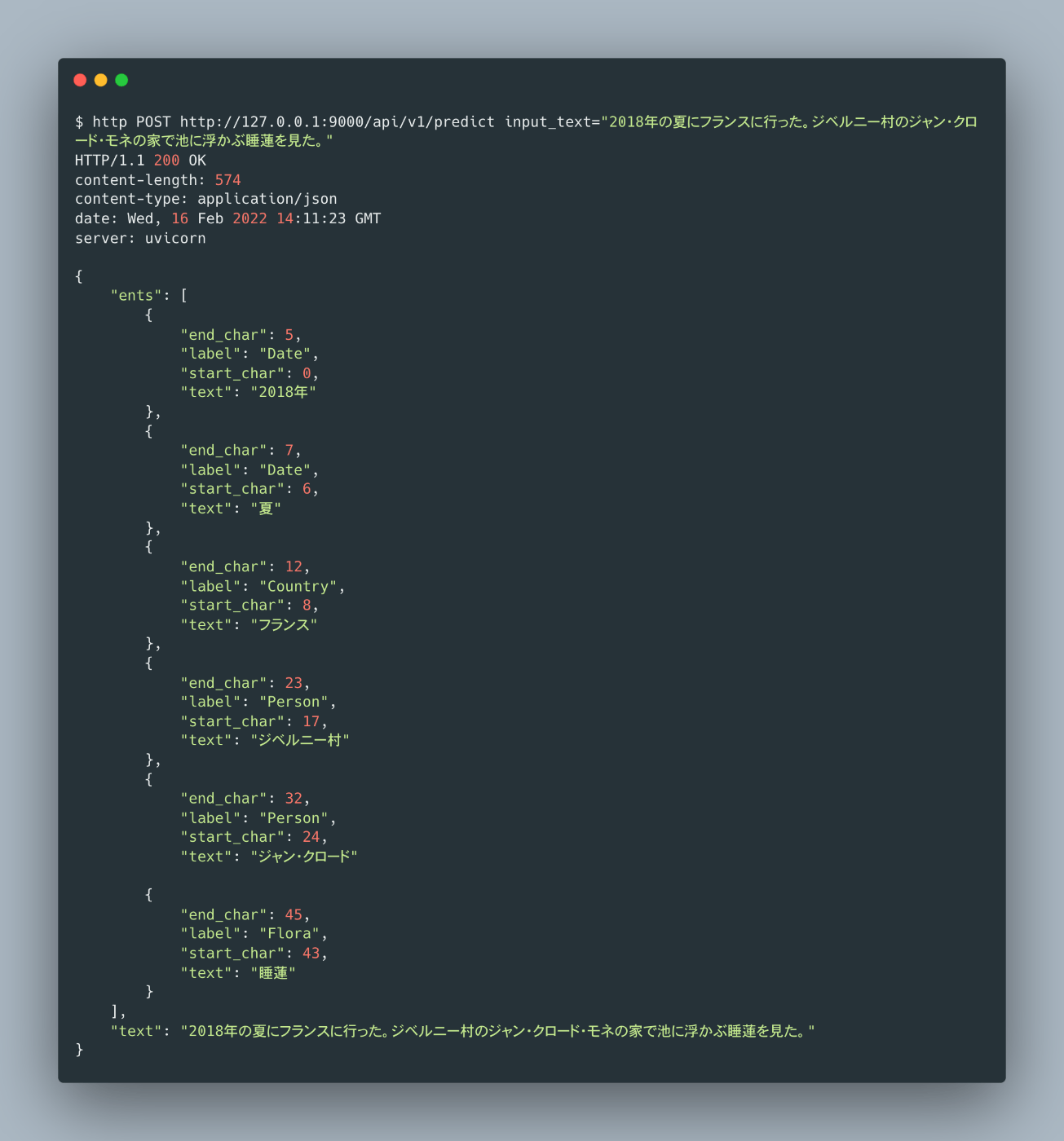
無事に結果が返ってきました!これで最小限で動く形で固有表現抽出の推論WebAPIが実装できました。
さて、ここからプロダクションレベルで動くWebAPIに仕立てていくには、何かしらのサービス上にデプロイしたり、リクエスト負荷に耐えられるための最適化や細かなパラメータ調整などが必要になってきます。ただ、今回のようにコンテナ化まで辿り着くことができれば、あとは社内SREチームやバックエンドに詳しい人と協調することができるでしょう。
まとめ
この記事では、機械学習の推論をWebAPIに実装する上での、プロジェクトテンプレートを作成し、実際のタスクで使う一連の流れを紹介しました。
今回は自分が利用するテンプレート刷新が主な目的であったため、このプロジェクトテンプレートは実装の一例というくらいに捉えてもらえればと思います。実際ログ周りはサボっていますし、実際にプロダクションで利用する際には色々と足りない点が出てくるでしょう。このあたりは、私自身も仕事で利用しながら徐々にアップデートしていければと思います。
Discussion