GraphQLとは何か? イメージを掴む
はじめに
今回の記事ではGraphQLについて、公式などを参考にしながら基本的なことをまとめてみました。
自分自身GraphQLのキャッチアップを始めるときに
こんなこと知っときたかったなあ、ということをまとめたので
これからGraphQLの勉強を始める方や興味のある方はよかったら読んでみてください。
大枠を掴むことをイメージして書いており、深い部分の説明を省いている箇所もあるので
その点はご了承ください。
そもそもGraphQLとは?
GraphQLはAPIのクエリ言語です。
クエリ言語というとSQLが有名ですが、SQLがデータベースに対してクエリを実行するのに対し、
GraphQLはAPIに対してクエリを実行します。
ちなみに、プログラミングにおけるクエリとは
データに対する問い合わせや要求などを一定の形式で文字に表現すること、
要は所定の形式で対象のデータにやりたいことを伝えること、と思ってもらえたら大丈夫です。
特にGraphQLのクエリはどのような形式でデータを受け取りたいか、も具体的に定義します。
なのでGraphQLは
APIに対してやりたいことや欲しいものを、こういう形式で返してほしい!と要求するための言語
というとイメージしやすいかなと思います。
RESTと比較した特徴
さて、ここでAPIに対してデータの問い合わせを行うというと
似たものとしてRESTを思い浮かべる人も多いと思います。
RESTと比較したGraphQLの大きな特徴は
エンドポイントが一つで済み、かつ柔軟なデータ操作を実現できることです。
データ取得に主眼を置いてこのことについて解説してみたいと思います。

上の画像のようにRESTの場合は複数のリソースのデータを取得しようとすると
複数のエンドポイントに対してリクエストを行う必要があります。
画像で言うとstudentsにある情報とcoursesにある情報を取得しようとした場合
~/studentsと~/coursesの両方にリクエストを行わなければならないと言うことですね。
それに対してGraphQLは、複数のリソースのデータを取得する際も
単一のエンドポイントに対してリクエストを行うだけで済みます。
studentsとcourses両方からいっぺんにデータを取得することが可能という訳です。
また、この場合studentsテーブルにid、name、ageのカラムが定義されているとして、
RESTでデータ取得を行うと全てのカラムのデータを取得することになります。
対して
GraphQLはnameが欲しいときはnameだけ、逆にidとageが欲しい場合はnameを取得しない
というように取得するデータを柔軟に選択することができます。
過不足なく、必要なデータだけを取得することができるということですね。
オーバーフェッチング(過剰な取得)やアンダーフェッチング(取得の不足)を防げると
言われていたりもするようです。
これはRESTとGraphQLのデータ操作方法が異なるためです。
RESTはオブジェクトごとに定義された複数のエンドポイントに対して
HTTPメソッドを使用してデータを操作します。
一方、GraphQLは
単一のエンドポイントを持ち、スキーマに基づいたクエリを使用することで
柔軟なデータ操作を実現しています。
スキーマとは
GraphQLのスキーマとはどういった処理を行うかを定義したドキュメントのようなものです。
(あくまで処理を定義しているだけで実際にここで処理を行なっている訳ではありません。
実際に処理を行うリゾルバーについては後述します。)
例えば以下のように書かれます。
type Student {
id: ID!
name: String!
age: Int!
}
type Query {
students: [Student!]!
student(id: ID!): Student
}
input Student {
name: String!
age: Int!
}
type Mutation {
createStudent(input: Student!): Student!
}
この例を見ていただくと分かるように
GraphQLではスキーマを定義するときにString、Intのように型指定を行います。
これもGraphQLの特徴の一つで、静的型付けが可能なことにより
クライアントから投げられるクエリがスキーマに対して正しいかを実行前に検証できたり
データの整合性や安全性を高め、バグの発生を防いだりすることができます。
冒頭でクエリとは所定の形式で対象のデータにやりたいことを伝えることと書きましたが
スキーマは出来ることを定義しているイメージを持ってもらうとわかりやすいかと思います。
このスキーマの中で具体的な操作を定義しているのがQueryとMutationです。
Queryはデータ取得操作の定義、Mutationはデータ変更操作の定義で
それぞれクエリが実行された際にどのような操作を行い、どのような形式でデータを返すかを
定義します。
QueryとMutationが定義する操作をRESTと比較すると以下のようになります。
| REST | GraphQL |
|---|---|
| Get | Query |
| Create | Mutation |
| Update | Mutation |
| Delete | Mutation |
またGraphQLにはQuery、Mutationに加えてSubscriptionという機能も備わっています。
これはいわゆるリアルタイム通信を行うための機能で、
特定のイベントが生じるたびにクライアント側にデータ送信を行うことができます。
type Subscription {
newStudent: Student
}
先ほどの例で言うと、このようなスキーマを定義することで、
新しいStudentの情報が登録された際にクライアント側に自動的にその情報を送信
できるようになります。
これだとわかりにくいと思うので具体的な例をあげると、
チャット機能などで送信者がメッセージを送信した場合、
受信者側が何もしなくても勝手に送信者が送信したメッセージが受信者側のチャットにも
反映されるような機能をイメージしてもらえればいいかと思います。

GraphQLサーバー作成からデータ取得までの流れ
では実際にGraphQLサーバーを利用して欲しいデータを取得できるようになるまでに
どのような工程が必要か簡単に説明していきます。
今回は本のデータの登録と取得ができる簡単なサーバーを作成してみました。
1、APIサーバーを用意し、スキーマを定義する
まずはサーバーを用意します。
GraphQL開発に役立つツールやライブラリはプログラミング言語ごとに
GraphQLの公式にまとめられているのでそこから適切なものを選ぶのが良いでしょう。
今回スキーマは以下のように定義しました。
type Book {
id: ID!
title: String!
genre: String!
}
type Query {
Books: [Book!]!
Book(id: ID!): Book
}
input NewBook {
title: String!
genre: String!
}
type Mutation {
CreateBook(input: NewBook!): Book!
}
2、リゾルバーを実装する
スキーマで行うのはあくまで操作の定義だけで実際のデータ操作は行えません。
そのためGraphQLではリゾルバーという関数を使ってデータ操作を行なっていきます。
リゾルバーはスキーマで定義されたQueryやMutationが実際にどのようにしてデータを
取得、変更するかを具体的に実装します。
スキーマで何が出来るかを定義し、リゾルバーがそれをどう実現するかを実装する
という関係にあると考えるとわかりやすいと思います。
なお、リゾルバーの実装方法は使用する言語によって異なるので、
各言語仕様に則った形で実装を行うことになります。
詳細は割愛しますが、今回はGoで以下のようにリゾルバーを実装しました。
func (r *mutationResolver) CreateBook(ctx context.Context, input model.NewBook) (*model.Book, error) {
book, err := r.Srv.CreateBook(ctx, &input)
if err != nil {
return nil, err
}
return book, nil
}
func (r *queryResolver) Books(ctx context.Context) ([]*model.Book, error) {
books, err := r.Srv.GetAllBooks(ctx)
if err != nil {
return nil, err
}
return books, nil
}
func (r *queryResolver) Book(ctx context.Context, id string) (*model.Book, error) {
intID, err := strconv.Atoi(id)
if err != nil {
return nil, err
}
book, err := r.Srv.GetBookByID(ctx, intID)
if err != nil {
return nil, err
}
return book, nil
}
func (r *Resolver) Mutation() internal.MutationResolver { return &mutationResolver{r} }
func (r *Resolver) Query() internal.QueryResolver { return &queryResolver{r} }
type mutationResolver struct{ *Resolver }
type queryResolver struct{ *Resolver }
3、クエリを送信する
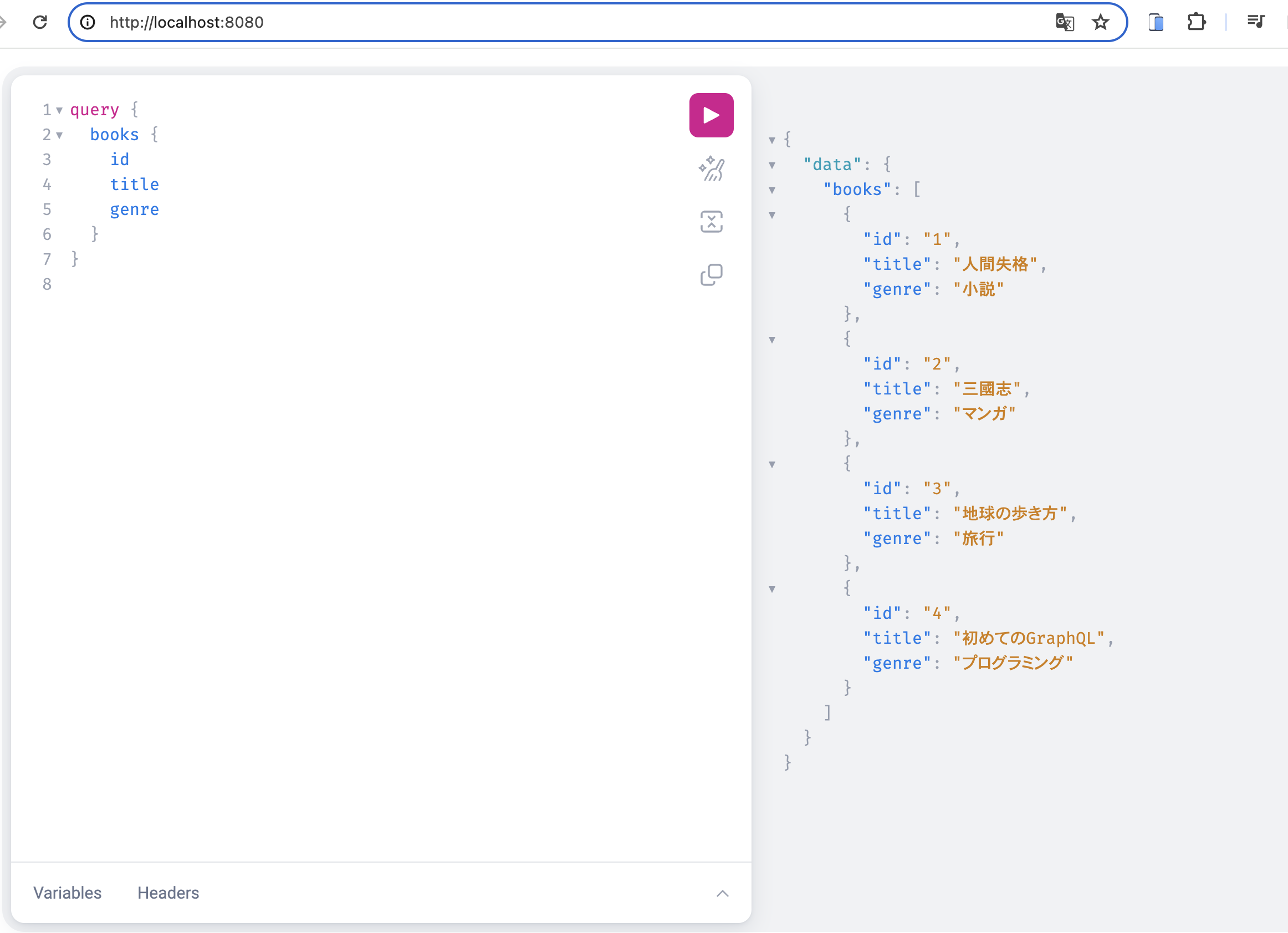
サーバーが完成すればあとは欲しい情報に合わせてクエリを作成し、実行するだけです。
# データ取得のクエリ
query {
books {
id
title
genre
}
}
# レスポンス
{
"data": {
"books": [
{
"id": "1",
"title": "人間失格",
"genre": "小説"
},
{
"id": "2",
"title": "三國志",
"genre": "マンガ"
},
{
"id": "3",
"title": "地球の歩き方",
"genre": "旅行"
}
]
}
}
タイトルのみ取得したい場合はクエリを変更すれば良いだけです
# クエリ
query {
books {
title
}
}
# レスポンス
{
"data": {
"books": [
{
"title": "人間失格"
},
{
"title": "三國志"
},
{
"title": "地球の歩き方"
}
]
}
}
今回はidをもとに特定のデータを取得できるスキーマも定義しているので
クエリの引数にidを指定することで、任意のidの情報だけを取得することもできます。
# クエリ
query {
book(id: "1") {
id
title
genre
}
}
# レスポンス
{
"data": {
"book": {
"id": "1",
"title": "人間失格",
"genre": "小説"
}
}
}
データを新たに追加する場合は以下のようなクエリを実行します。
# クエリ
mutation {
createBook(input: { title: "初めてのGraphQL", genre: "プログラミング" }) {
id
title
genre
}
}
# レスポンス
{
"data": {
"createBook": {
"id": "4",
"title": "初めてのGraphQL",
"genre": "プログラミング"
}
}
}
GraphQLで実際にクエリを投げたときにどのようなレスポンスが返ってくるかは
playground(RESTで言うPostman的なやつ)で確認することができます。
サーバーを実装するときにplayground向けのルーティングを設定することで
簡単に使用できるので、GraphQLサーバー開発を行う際には活用しましょう。
ディレクティブ
GraphQLを使用する際、クライアント側が特定の条件に基づいてデータの取得を制御したい
場合があります。
例えば、ユーザーごとに異なるデータを取得したい、
または特定の条件下でのみ特定のフィールドを取得したいといった場合です。
GraphQLではそのような動的にレスポンスを変化させたいときにディレクティブという機能を
利用することができます。
GraphQLにはデフォルトでディレクティブが3つ組み込まれています。
| @include | 指定された条件がtrueの場合にクエリ結果を取得します。 |
| @skip | 指定された条件がtrueの場合にクエリ結果を除外します。 |
| @deprecated | フィールドや列挙値が非推奨であることを示します。あくまで非推奨であることを伝えるだけなので実際の動作には影響を与えません(@deprecatedが付与されたフィールドや値を含むクエリはその対象を取得できてしまいます)。 |
例えば、以下のようなクエリを作成することができます。
# @includeの使用例
query GetUser($includeEmail: Boolean!) {
user(id: "1") {
name
# $includeEmail変数の値がtrue場合にのみデータを取得する
email @include(if: $includeEmail)
}
}
このクエリはユーザー情報を取得する際にメールアドレスが登録されている場合はそれも取得し、
登録されていない場合は取得しない、というクエリです。
こうすることで無駄な空データを取得することによるパフォーマンスの低下や
クライアント側で空データを処理するコストを軽減することができます。
@deprecatedの使い所についてですが、
これはプロダクトの成長に伴い使われなくなっていく値やフィールドを
段階的に削除することを計画している場合などに有用です。
例えば以下のように何かしらの理由で新しいフィールドにデータを移行したり、
別のテーブルで値を管理するようになったりした場合などにそれを示すことができます。
@deprecatedの後ろにreason引数でコメントを入れることで、
非推奨になった理由や代わりに何を使えばいいかを示すこともできます。
type User {
id: ID!
username: String!
# emailの代わりにcontactEmailを使うようになったのでそちらを使用してくださいと言う意味
email: String @deprecated(reason: "Use `contactEmail` instead.")
contactEmail: String
}
標準のディレクティブは3つだけですが、
独自のカスタムディレクティブを定義することもできます。
認証の有無を検証するディレクティブを作成してデータへのアクセス制御を行う場合や、
データのフォーマットを検証するバリデーションを定義する(メールアドレスの形式チェックや電話番号に数字以外が含まれていないかのチェックなど)場合に利用されることがあります。
ディレクティブがクエリに含まれるかスキーマに定義されるかの違いですが、
@includeと@skipはクエリに含まれ、
@deprecatedやカスタムディレクティブはスキーマ定義の際に利用されます。
@includeと@skipはクライアント側で取得するデータを制御する際に使用するものであり、
@deprecatedはサーバー側がクライアントに伝えたい情報を書くもの、
カスタムディレクティブは
基本的にサーバー側がデータ操作を制御するために定義して使用するものなので
そこを意識するとディレクティブの使い方がイメージしやすくなると思います。
一般的に言われるGraphQLのメリット・デメリット
一般的にGraphQLには以下のようなメリット、デメリットがあると言われています。
メリット
・欲しいデータだけを過不足なく取得できる
必要なデータをクエリによって明確に指定して取得できるため過不足なく欲しいデータを取得することができます。RESTの場合エンドポイントごとにレスポンスが決まっているので不要なデータの取得や、逆に欲しいデータが単一のリクエストで取得できないなどの問題がありますが、GraphQLはそれを解決しています。
・効率的にデータが取得できるのでパフォーマンスが向上する
GraphQLはRESTのようにデータ取得のために複数のエンドポイントにリクエストを行う必要がなく、単一のエンドポイントからデータをまとめて取得できるためパフォーマンスが向上します。これにより低速のネットワークやモバイルデバイスでも高速なデータ通信が可能になります。
・スキーマベースの型安全性やデータ構造のチェック
静的型付けなので型の整合エラーを防ぐことができ、安全性と開発効率を向上させることができます。また、クエリからどういう構造のデータが取得できるかも分かるのでクライアント側でデータを正しく扱っているかをチェックできます。
・APIの変更が容易でバージョン管理が基本的に不要
RESTでは新しいデータが必要になると、新しいバージョンやエンドポイントを作成する必要があります。それと比較してGraphQLはスキーマの追加や再利用をしやすくAPIの変更を簡単に行うことができ、基本的にバージョン管理を行う必要がなくなります。(場合によっては古いフィールドを非推奨として管理するなどの対応は必要)
デメリット
・セキュリティに関する問題
GraphQLのクエリは柔軟性が高いがゆえ、不正なクエリの実行による攻撃を受ける可能性があります。例えば過度にネストの深いクエリを作成し、サーバーに負荷をかけたり、サーバー側のアクセス制御の抜け目を狙うような巧妙なクエリを作成し、サーバー側が意図しないデータを取得したりすることがあげられます。
そのためクエリの深さや複雑さの制御、適切な認証や厳格なアクセス制御などを設定する必要があります。
・取得するデータ量が多い場合のパフォーマンスの問題
柔軟性を適切に使用すればメリットでもあげたようにパフォーマンスの向上に繋がる反面、データを過剰に取得してしまうとパフォーマンスが悪化する可能性もあります。特に大量のデータが要求された場合はサーバーの負荷が高くなります。
また、クライアントが意図せずに大量のデータを要求する「N+1問題」が発生する可能性もあり、適切なデータ取得方法やクエリの最適化を行う必要があります。
GraphQLのN+1問題の解決にはDataLoaderが使われることが多いですが、込み入った話になるので今回は割愛します。興味のある方は以下の記事などを読んでみてください。
・キャッシュが扱いにくい
GraphQLではクエリを自在に扱える一方で、キャッシュの利用が難しいという課題が存在します。RESTであれば特定の情報が固有のエンドポイントを持っており、異なるクライアントからのリクエストでも常に同じ形式のレスポンスが返るためキャッシュして再利用することが簡単です。しかし、GraphQLはクライアントが動的にクエリを作成し、必要なデータだけを要求するためクライアントごとに返却する情報が異なり、キャッシュを共有するのが難しくなります。
どんなときにGraphQL導入が検討されるか
GraphQLの導入がどんな場面で検討されているかまとめてみました。
導入を検討するパターン
・フロントエンド駆動の開発
フロントエンド側(特にモバイルやWebアプリケーション)で、必要なデータの構造が頻繁に変わる場合、GraphQLはクライアント側で具体的に必要なデータを指定できるため、フロントエンド駆動の開発に適しています。
・クエリの柔軟性が必要な場合
クライアント側からのデータ要求が複雑であり、RESTのような固定されたレスポンスが扱いづらい場合、GraphQLの高い柔軟性を活かすことができます。
・パフォーマンスを向上させたい場合
RESTでは、クライアントが必要としないデータも含めたレスポンスを受け取ることがあります。GraphQLを使用すると、必要なデータのみを取得できるため、ネットワーク使用量の削減やパフォーマンスの向上が期待できます。
・リアルタイムデータの利用
チャットアプリなど、リアルタイムのデータ更新が必要な場合、GraphQLのサブスクリプションを利用することで効率的なリアルタイムデータ通信を行うことができます。
導入を見送ったほうがいいパターン
・シンプルなAPIで十分な場合
もしAPIの要件が非常にシンプルで、固定されたデータ構造で十分な場合、あえて柔軟性の高いGraphQLの導入を行う必要はないかもしれません。
・キャッシュの利用が重要な場合
GraphQLはキャッシュを利用しにくいため、キャッシュが重要なアプリケーションではRESTの方が適している場合があります。
・既存のRESTで十分に機能している場合
既に問題なく十分に機能しているRESTを、GraphQLへ移行する必要ないかもしれません。
まとめるとGraphQLは、
クライアント側からの複雑なリクエストに対応する場合利用を検討してもいいと思いますが、
シンプルなAPIニーズやキャッシュの利用が重要な場合には、RESTの方が適している場合がある
といったイメージです。
とは言うものの使うのにお金がかかるわけでも無いので
個人で簡単なアプリを作る場合でもRESTとの違いを体感するのに使ってみるのはおすすめです。
私は初めてGraphQLを使用したときにこちらの動画を参考にしました。
ちょっと触ってみたいと言う人はよかったら見てみてください。
まとめ
今回はGraphQLについて簡単にまとめてみました。
私自身まだGraphQLを使い始めて間も無いので、
間違いなどあれば教えていただけると幸いです🙇♂️
gRPCについても勉強していきたいので、
そのうちREST、GraphQL、gRPCそれぞれの特徴についてもまとめていきたいと思います。
最後までお読みいただき、ありがとうございました。
参考にしたサイトなどまとめ
Discussion