Lambdaの基本と使用例についてまとめる
はじめに
Lambdaを最近触り始めたので、
理解を深める意味も込めて基本や使用例についてまとめてみました。
Lambdaを構築する手順にはあまり深く触れないので
ハンズオン的に使える内容ではないのでその辺はご了承ください。
Lambdaとは
まず最初にLambdaとは何なのかについてです。
LambdaはAWSが提供するサーバーレスコンピューティングサービスです。
サーバーレスと言っても実際にサーバー無しで動いている訳ではなく、
サーバーの管理をする必要が無い(管理はAWSがやってくれている) という意味です。
サーバー管理が不要なのでユーザーはコードの実装に集中することができます。
Lambdaを使用するメリット
Lambdaを使用するメリットには以下のようなものがあげられます。
・オートスケーリング
Lambdaは、リクエストの増減に応じて自動的にスケールアップ・ダウンしてくれるので、突発的なトラフィック増加にも柔軟に対応できます。
・コスト効率
Lambdaは実行された時間(100ms単位)と呼び出し回数に基づいて課金されます。使用した分だけの支払いになり、リソースが使用されない時は料金が発生しないので無駄に課金されることはありません。
・可用性
LambdaはマルチAZ構成で運用されているので可用性に優れています。
・簡単な処理をすぐに動かせる
サーバー管理が不要なので、動かしたい関数だけを実装し、セットアップすることですぐに処理を動かすことができます。
・セキュリティ面
AWSがサーバーを管理しているのでセキュリティも担保された状態でコードを実行することができます。ユーザーは自身の実装する関数にのみ責任を持つ形になります。
一般的な用途
Lambdaの一般的な用途には以下のようなものがあげられます。
・定期的に実行が必要な処理の自動化
例:1日に1回データの集計を行う
・データの変換処理
例:画像ファイルがアップロードされたときにそれを加工する
・エラーやデプロイなどの通知処理
例:AWSのサービスを利用したデプロイの成否や、サービスのエラーをslackに通知する
・サーバーレスアプリケーション
例:AWSのAPI Gatewayなどと連携してWebアプリケーションのバックエンドを実装する
Lambdaのメリットがわかりやすいよう、もう少し具体的に実用例を書いていきます。
・Webアプリケーションのバックエンド
上にも書いたように、Lambdaはウェブアプリケーションのバックエンドとして使用できます。API Gatewayと組み合わせてREST APIを提供し、Webアプリケーションからのリクエストに応じてデータベースの読み書きやビジネスロジックの処理を行います。
メリット
バックエンドのスケーラビリティや可用性を気にすることなく、開発者はアプリケーションロジックに集中できます。
・データ処理と変換
Lambdaはファイルアップロードやデータストリームに反応して起動するデータ処理タスクに最適です。例えば、S3にアップロードされた画像の自動リサイズや変換、ログファイルの解析などに使用できます。
メリット
データ処理が必要なときにのみLambda関数が実行されるので、リソースの無駄がありません。
・IoTアプリケーション
IoTデバイスからのデータを処理するためにLambdaを使用できます。例えば、IoTデバイスからのセンサーデータを受け取り、処理してデータベースに保存したり、アラートを発するなどの動作を行います。
メリット
大量のデバイスからのデータを処理する必要がある場合、Lambdaはスケーラビリティとコスト効率の両方を提供します。
・クラウド自動化とオーケストレーション
LambdaはAWS環境内のリソース管理やオペレーションの自動化に使用できます。例えば、特定の条件下でEC2インスタンスを自動的に起動/停止する、または他のAWSサービスへの自動応答を行います。
メリット
インフラ管理が自動化され、運用コストと手間が削減されます。
・リアルタイムファイル処理
LambdaはS3バケットにアップロードされたファイルに対してリアルタイムで処理を行うのに適しています。例えば、アップロードされたドキュメントの内容を抽出して分析したり、トランスコード処理を行うなどです。
メリット
ファイルの処理に関連するインフラを自分で管理する必要がなく、柔軟かつ効率的に処理を行うことができます。
Lambdaを使用する際に注意すべきこと
非常に便利なLambdaですが、利用する際に注意するすべきこともいくつかあります。
・実行時間と同時実行数に制限がある
Lambdaの最大実行時間は15分なので、それ以上時間がかかる処理は実行できません。また、同時に実行できる関数の数はデフォルトでは1,000となっています。あまり気にする必要はないかもしれませんが、頭の片隅に置いておきましょう。
・再帰ループに要注意
Lambda関数で処理したデータを同じサービスに出力しようとした場合、設定ミスをしてしまうと再帰ループ(無限ループ)が発生して無限に課金されてしまう状態に陥る可能性があります。
(例えば、S3バケットへの画像保存をトリガーにその画像を処理する関数を設定したとする。その関数で処理した画像の保存先を、トリガーに設定しているバケットに設定にしてしまったなど)
いくつかのサービスをトリガーにした場合は再帰ループを検知してくれるようになったようですが、全てのサービスに適用されている訳では無いので注意しましょう。
・Lambda単体では使用できない
Lambdaは単体で使用することはできず、他のAWSサービスで処理のトリガーを設定する必要があります。そのため必然的にLambda以外の他サービスの知識もある程度必要になってくるので、その辺をキャッチアップする必要があります。
・ステートレス
Lambda関数は実行が終了すると破棄されるステートレスな構成のため、前回実行した際の状態を保持することはできません。
・エラー解析が難しい
処理の大部分がLambda内部に隠蔽されているため、問題が発生した時の解析が難しくなります。
Lambdaの使い方
Lambdaのプログラムを用意する方法は、実行したいプログラムを関数として実装し、
Lambdaにアップロードするだけです。
実行する関数を記述するための言語は現在(2023年12月時点)
Java、Go、PowerShell、Node.js、C#、Python、Rubyの7言語が
デフォルトでサポートされています。
しかし、Goに関しては2023年12月末をもってサポートが終了する予定です。
ただサポートがない言語は使用できないのかと言われるとそういう訳でもなく
カスタムランタイムを使用すればサポート外の言語を使用することも可能です。
ただLambdaを使用する際に注意することであげたように
Lambdaは単体では実行ができないので、実際に使用する際は
その他のAWSサービスの設定などを行うことになります。
コードの登録方法
Lambdaにコードを登録するにはいくつか方法があります。主な方法には
1、AWSのマネジメントコンソールでコードを書いて登録する。
2、手元で作ったものを手動でアップロードする。
3、手元で作ったコードをAWS CLIを利用してデプロイする。
などがあげられます。
Lambda関数の種類
Lambda関数には大きく分けて2種類あって、1つはZIP形式のLambda関数、
もう1つはコンテナ形式のLambda関数です。
ZIP形式のLambda関数は従来から使われていたもので、
基本的に関数を実装するだけで実行の準備ができるので手軽に利用することができます。
コンテナ形式のLambda関数は2020年12月から新たに導入された形式で、
ZIP形式のLambda関数よりも大きなサイズのコードを実行することができます。
ただコンテナ形式の場合、
カスタムのコンテナイメージを作り、それをAWS ECRに登録する手間があったり
コマンドラインツールを使ったビルドやデプロイが前提になるので
少し手軽さに欠ける部分があります。
今回の記事では従来型のZIP形式のLambda関数について書いていきます。
Lambdaの作成
Lambdaの作成画面を見ながら、各設定について解説していきたいと思います。
Lambdaを作成するにはAWSマネジメントコンソールからLambdaと検索し、
関数の作成ボタンを押すことで設定画面に遷移できます。
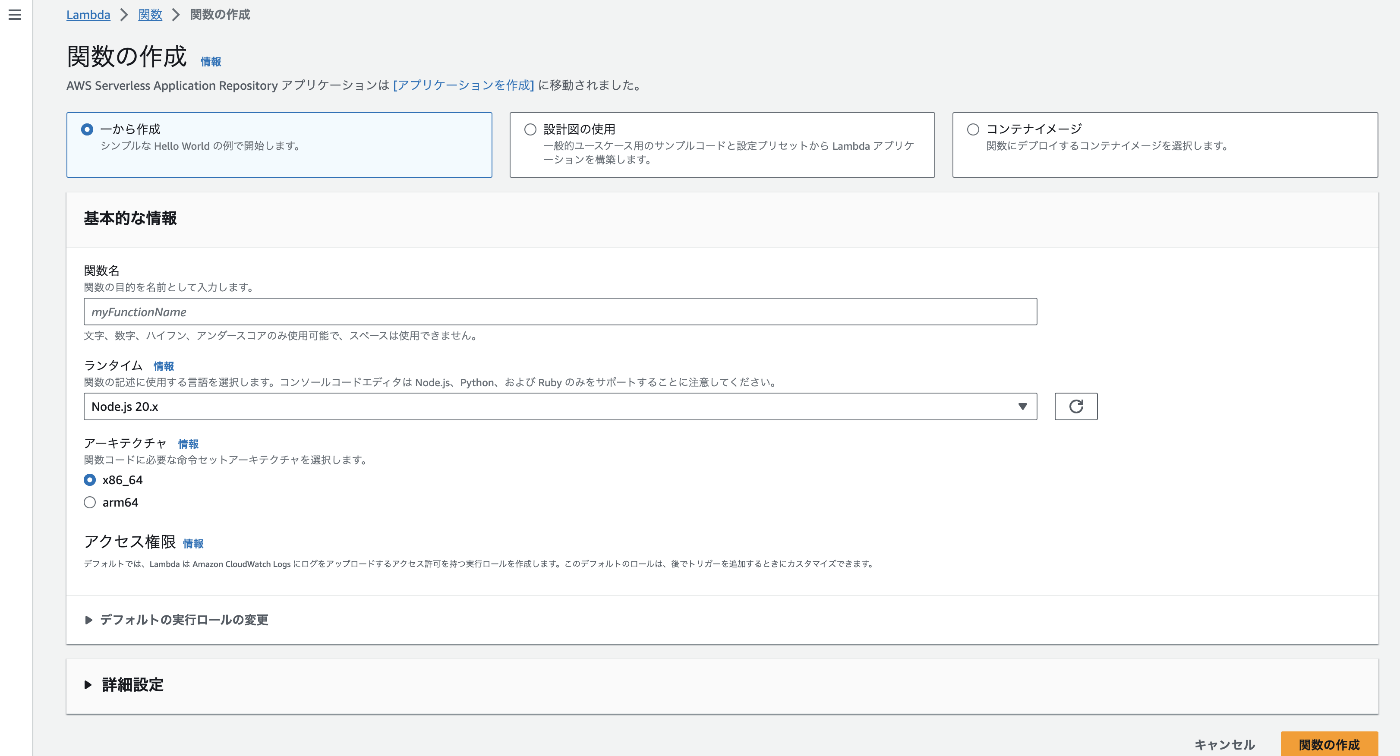
こちらの画面について解説していきます。
・作成方法
まず作成方法について、
1から作成・設計図の使用・コンテナイメージのどれかから選択できます。
1から作成は文字通り自分で設定を行なって1から関数を作成したい場合に使用します。
設計図の使用は様々なパターンを想定したサンプルをもとに関数を作成することができます。
自分が作りたいものの条件を満たすものがあればこれを使うと便利でしょう。
コンテナイメージは、コンテナイメージをECRに登録して関数を作成する場合に使用しますが
今回はここの説明は割愛します。
・関数名
関数名は関数を識別するための名前です。わかりやすい名前をつけるようにしましょう。
・ランタイム
続いてランタイムです。
Lambdaにおけるランタイムとは、Lambda関数を実行するためのプログラミング言語の環境のことです。Lambdaには、先ほどLambdaの使い方に書いたデフォルトで用意されている言語の
特定のバージョンのランタイムが用意されています。
ランタイムによってAWSがコードが実行される際に必要な言語固有の実行環境を提供、管理してくれているため開発者はサーバーの管理を行う必要がなくなるのです。
また、カスタムランタイムを使用することで公式にサポートされていないプログラミング言語や、特定のバージョンを使用することも可能になり、より柔軟にLambdaを使用することが可能になります。
・アーキテクチャ
続いてアーキテクチャです。
これはLambdaを実行する環境の基礎のようなもので、命令セットアーキテクチャと呼ばれています。2種類あるのでどちらを選べばいいのかというところですが、ここは特別な理由がなければarm64の方を選択しましょう。理由としてはarm64の方がx86_64に比べて2割ほど安く、またパフォーマンスも優れているからです。x86_64に依存したLambda関数を利用する場合以外はarm64を選択するようにしましょう。
続いてアクセス権限と詳細設定についてです。
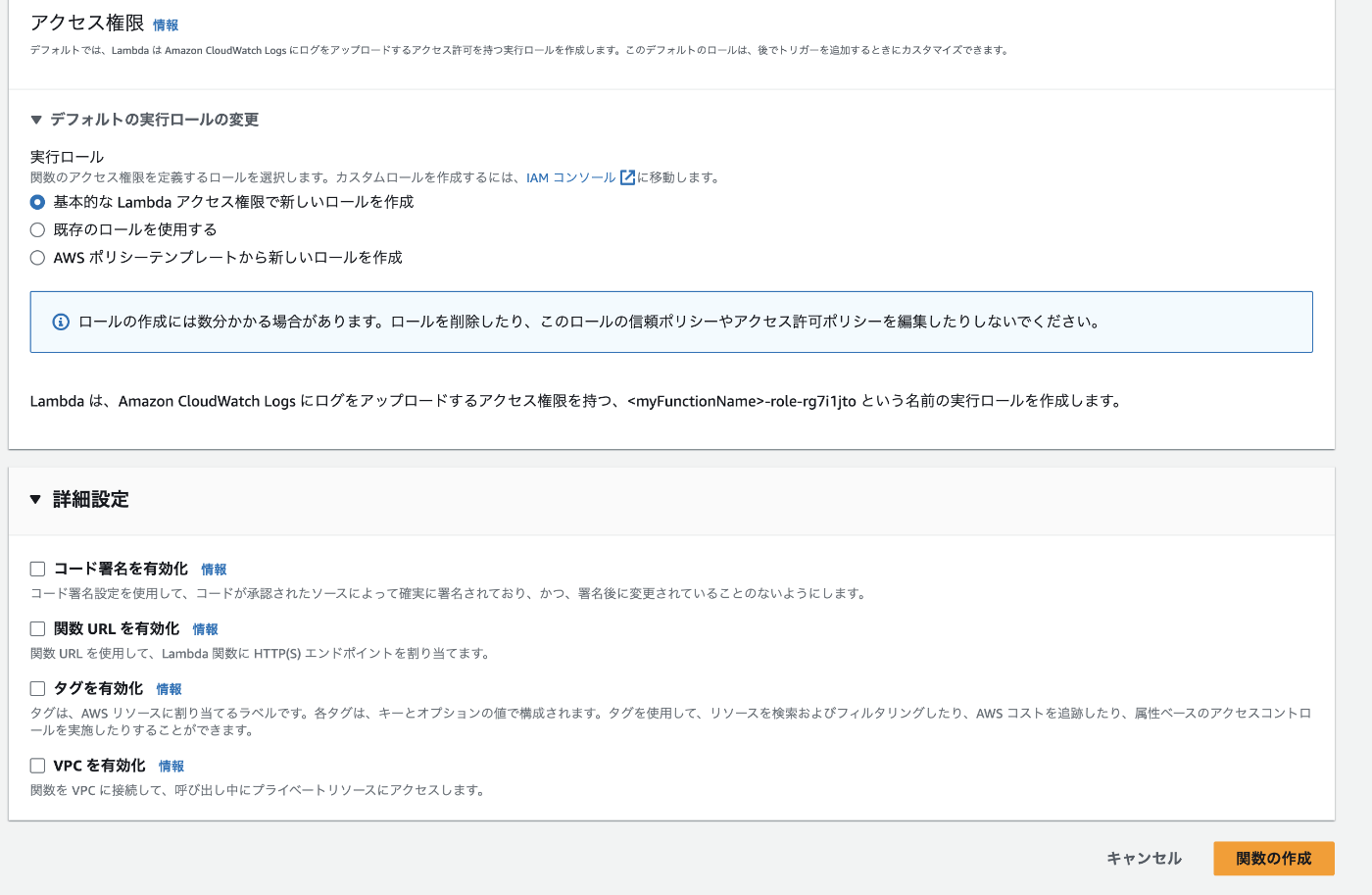
・アクセス権限
まずアクセス権限についてです。
AWSにはロールという機能があります。要は権限管理のようなものですね。
Lambdaを利用する際は他のAWSのサービスと連携する場合がほとんどであり、
Lambdaから他のAWSサービスへアクセスする権限を設定する必要があるケースが多いです。
このロール(権限)をLambda関数に付与することで他サービスと連携が取れるようになります。
このロールの設定を間違えてしまうと関数が上手く動作しなくなってしまうので注意しましょう。
ロールの設定自体はAWSのIAMというサービスで行います。具体的な設定方法は省きますが、
ロールは種類が多く、どれを選ぶべきかわからないからといって強い権限のロールを付与してしまうとセキュリティ上良くないので、必要最低限のロールを付与するように心がけましょう。(これはLambdaに限らずAWSのサービス全般に言えることです。)
・詳細設定
次は詳細設定について簡単にまとめていきます。
コード署名の有効化
コード署名の有効化は関数のコードに署名を行い、それを検証することで署名が行われていないコードがデプロイされた際に、それをログに残したり、デプロイをブロックできるようにします。これによりコードが適切な手順でデプロイされたものかどうかを検証することができます。
関数URLの有効化
関数URLを有効化することでインターネットから直接関数を呼び出せるようになります。この機能を使うことでアプリケーション内の一部のロジックを担ったり、小規模なWebアプリケーションのバックエンドを簡単に構築したりすることができます。
タグ
関数に目印をつけるようなイメージです。例えば環境ごと(開発環境、本番環境など)にタグ分けするなどしてリソースを整理しやすくしてくれます。
VPCの有効化
VPCを有効化することで自分で作成したVPCの中にLambdaを配置することができるようになります。これによりLambda関数をプライベートネットワーク内で実行できるようになり、VPC内のリソースへのアクセスが可能になります。
これらの設定を行うことでLambda関数を作成することができます。
全ての設定が必須という訳ではないので必要に応じて設定を行うようにしましょう。
ただこれだけだとまだ動作はしません。
ここで作成した関数に自分が動かしたいコードをアップロードすることで
Lambda関数が動作するようになります。
コードをアップロードするには、コードをzipファイル化し、手動でアップロードする方法や
Serverless Frameworkを利用する方法などがあげられます。
手動でアップロードする方法
コードを手動でアップロードする場合はAWSコンソール上で操作を行います。Lambdaの画面から作成した関数を選択して詳細画面に遷移し、以下の画像のコードソース欄の右端にあるアップロード元というボタンを押して操作を進めることでコードをアップロードすることができます。コードをアップロードすることで初めてLambdaが動作するようになります。
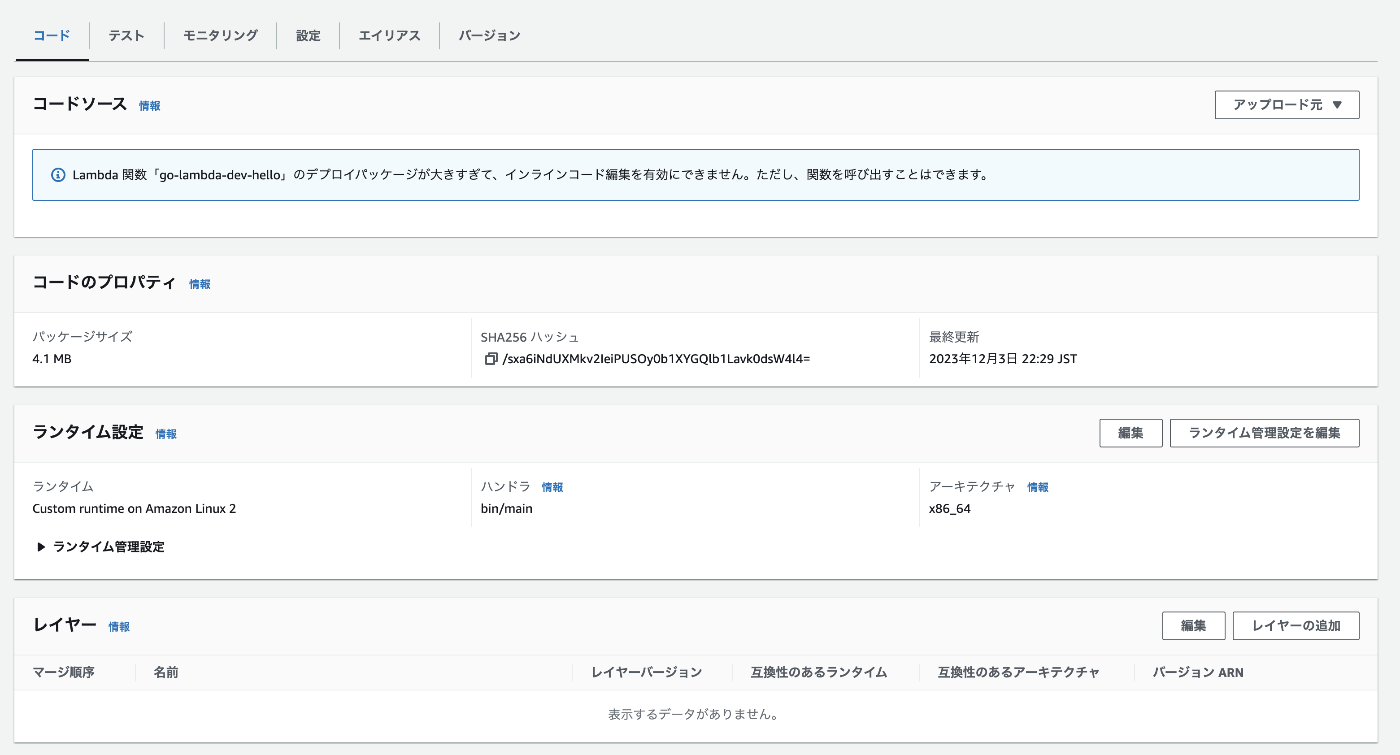
設定後のLambda関数が正常に動作するかどうかテストすることも可能です。関数の詳細画面からテストタブに移動し、テストボタンを押すことでテスト結果が画面に出力されます。
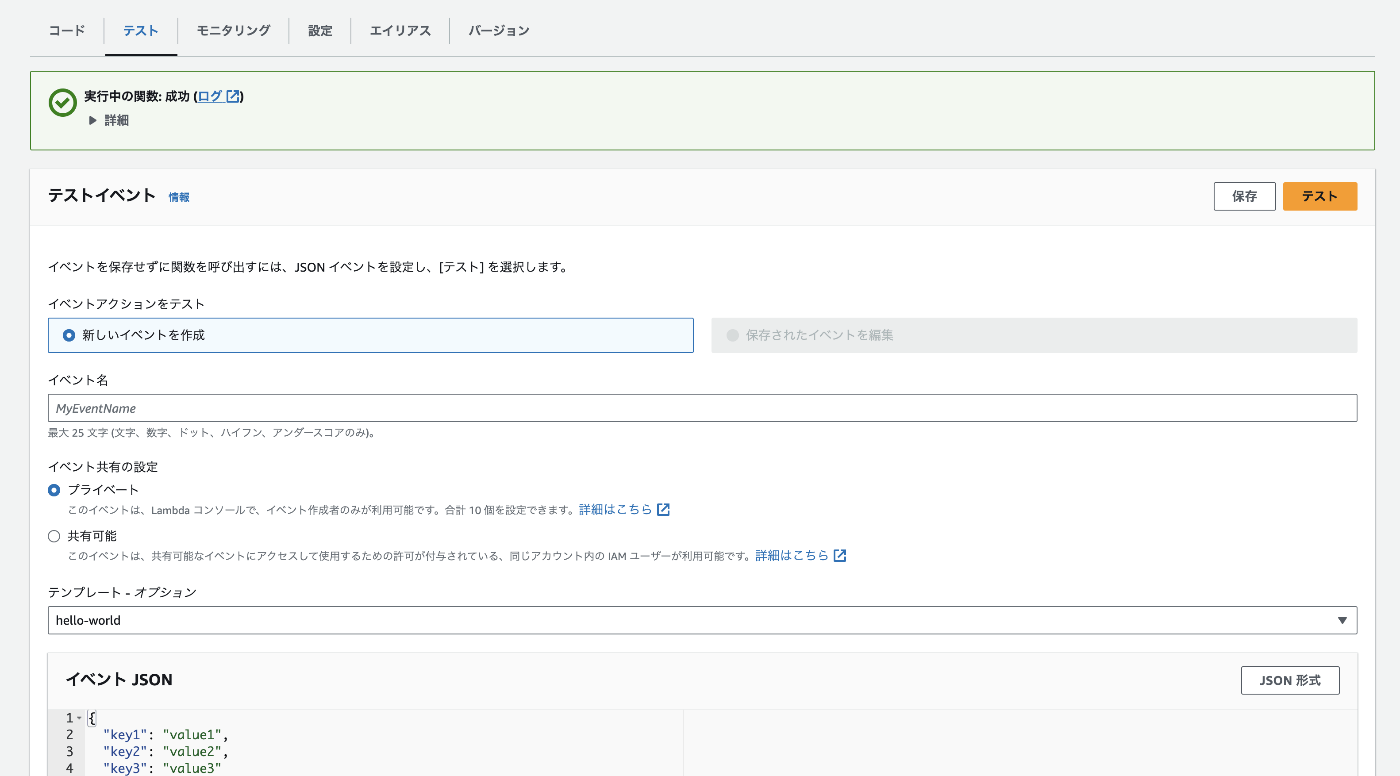
このテストですが、色々なパターンが用意されていて、関数に設定したコードの内容によってそれを使い分ける形になります。
LambdaはAWSの他のサービスと連携させて使用することがほとんどなので、連携するサービスから送られてくる値を想定してテストを行う必要があります。 その値を自分で用意するのは手間なので、AWSがテストケースを用意してくれているのです。これによりLambda関数を簡単にテストすることができるようになっています。

Serverless Framework
Serverless FrameworkはLambda関数のコードやトリガー、連携するAWSのリソースを管理することができるNode.js製のツールです。
先ほどAWSのマネジメントコンソールからLambda関数を作成し、コードをアップロードする方法を説明しましたが、Serverless Frameworkを使用する場合はコンソールで関数の作成を行う必要もなくなります。(Serverless Frameworkで関数の設定も同時に行えるため)。デプロイが成功すれば、Lambdaの関数の画面に、自動的に作成された関数の情報が反映されるようになっています。
Serverless Frameworkなどの管理ツールを使用することで、関数をコードベースで管理することもできるようになり、手作業で関数を作成する時と比べて設定状況を把握しやすくなります。(コードを見ればどのような設定で関数が作成されているかすぐわかるため)
特にチームで開発する場合などは、後から他の人が見ても設定状況を把握しやすいためServerless Frameworkなどの管理ツールを使用することが望ましいでしょう。
ちなみにServerless FrameworkはサードパーティのツールでAWSが公式でサポートしている訳ではありません。Lambdaの管理ツールには他に以下のようなものが存在します。
AWS公式のツール
SAM、CDK、Amplify
サードパーティツール
Terraform、CloudFormationなど
今回はServerless Frameworkに絞って解説していきます。
serverless.yml
Serverless Frameworkを使用する際に一番重要なファイルがserverless.ymlファイルです。
いわゆる関数の設定ファイルですね。
以下に簡単なserverless.ymlファイルの例を書いてみました。
# Serverlessアプリケーションの名前を設定
service: hello
# プロバイダーの定義
provider:
# プロバイダーはAWSを使用する
name: aws
# ランタイムはNode.jsのバージョン18.xを使用
runtime: nodejs18.x
# 東京リージョンに関数をデプロイ
region: ap-northeast-1
# ロールの設定。この例では、AWSのLogs、CloudWatch、S3に対する全アクションを許可。
iam:
role:
statements:
- Effect: Allow
Action:
- logs:*
- cloudwatch:*
- s3:*
Resource:
- '*'
# デプロイされるLambda関数の設定
functions:
# 関数名
hello:
# sample.jsというファイルのhello関数をデプロイする。
handler: sample.hello
このような設定ファイルを書いて、デプロイしたいコードを適切な箇所に配置してコマンドを実行することでLambda関数をデプロイすることができるようになります。
本来であればServerless FrameworkのインストールやAWS CLIの設定も必要になりますが
今回はその説明は割愛します。
その辺の設定については以下の記事などが参考になると思います。
Serverless Frameworkにはプロバイダーが設定できたように、AWS以外のAzure、GCP等のクラウドサービスを利用する際にも活用することができます。コード管理が容易になり、デプロイもコマンド一つで行うことができるので、ぜひ使いこなせるようになっていきたいですね。
最後に
今回はAWS Lambdaについて、基本的な内容や使用例について解説していきました。Lambdaには様々な用途があり、使いこなせるとできることの幅も広がっていきます。Lambdaに加えてAWSのその他のサービスやネットワークの知識もしっかり身につけて、その幅をどんどん広げていきたいですね。そのうちある程度知識レベルが上がってきたタイミングでまた改めてLambdaについてまとめてみたいと思います。
最後までご覧いただき、ありがとうございました。
参考にしたサイトなどまとめ
Discussion