📕
VectorDBで社内ドキュメントの意味検索:Qdrant×BGE-M3
はじめに
社内ドキュメントの“意味検索”を、できる限りローカル完結で実現するための検証メモ。
キーワード一致に依存せず、言い回しが違っても近い内容のチャンクを素早く返すために、**埋め込み(embedding)→ ベクトル近傍検索(Vector DB)**を使う。
この記事では Qdrant(VectorDB)と BGE-M3(埋め込み/疎ベクトル対応)を使い、dense / sparse / ハイブリッド + クロスリランクの挙動を最小構成で確認します。
目的
- 表現揺れに強い検索(例:「年末年始の休暇」⇔「正月の有給」「申請締切」)
- ローカルでの PoC(Docker 上の Qdrant + ローカルモデル)
環境
- macOS (Apple Silicon)
- Python 3.13(pyenv または Homebrew で導入)
- Docker 28.x(Qdrant をローカル起動)
- 仮想環境:
python -m venv .venv→source .venv/bin/activate
全体の流れ(抽出→分割→埋め込み→Upsert→検索)
- ファイル抽出:.txt / .md / .pdf からテキスト抽出(PyMuPDF で PDF も対応)
- チャンク分割:固定長スライディング + 多少の前処理(ページ番号や過剰な空白の除去)
- 埋め込み:BGE-M3 で dense(密) を生成、同モデルの sparse 出力で 疎ベクトル も生成
-
Upsert:Qdrant に named vectors として
dense/sparseの両方を保存(1ポイントに両方格納) -
検索:
- dense 検索(
using="dense") - sparse 検索(
using="sparse") - ハイブリッド(dense + sparse を RRF で融合)+任意でクロスエンコーダ再ランク
- dense 検索(
Qdrant とは
オープンソースのベクターDB。高次元ベクトル(埋め込み)を高速に近傍検索でき、HNSW をベースにした ANN(Approximate Nearest Neighbor)や、スカラー/タグによるフィルタ、分散・永続化まで面倒を見てくれる。
この検証で重要なのは、次の 3 つ:
-
Named Vectors:1つのポイントに複数のベクトルを「名前付き」で格納できる(例:
denseとsparseを同居)。 - Sparse Vectors:BM25 などの語彙ベースや、BGE-M3 の疎出力をネイティブに保持・検索できる。
- ハイブリッド検索:dense と sparse を同一コレクション内で検索し、スコアや順位を融合できる。
公式リンク
- 公式サイト: https://qdrant.tech
- Named Vectors: https://qdrant.tech/documentation/concepts/vectors/#named-vectors
- クイックスタート(Pythonクライアント): https://qdrant.tech/documentation/quick-start/
インデックスと検索モードの考え方
本記事で扱う用語を整理しておく。
dense(密ベクトル)
- 役割:意味的な近さ(表現違い・言い換え)を捉えるのが得意
- 作り方:SentenceTransformer などで埋め込み(例:BGE-M3 の dense 出力)
- 長所:概念一致に強い/多言語対応のモデルを使えば言語跨りも強い
- 短所:OOV(未知語)や固有名詞の微細一致は苦手なことがある
sparse(疎ベクトル)
- 役割:語彙レベルの一致に強い(キーワード、頻度、IDF)
- 作り方:BM25 など/BGE-M3 の sparse 出力(
lexical_weights等) - 長所:キーワード主導の精確一致に強い/長文コーパスでの高速検索
- 短所:表現の言い換えには弱いことがある
both(同一点に dense + sparse を格納)
- Qdrant の Named Vectors を使い、同じ
pointにdenseとsparseを同時保存 - ランタイムで dense / sparse / ハイブリッド(RRF など) を切替できる
- 運用面でも「最初から両方入れておく」ほうが後からの再投入を避けられる
再ランク(Rerank)
-
一次検索(dense / sparse / ハイブリッド)で上位N件を取った後、
クロスエンコーダ(例:BAAI/bge-reranker-v2-m3)でクエリ×候補チャンクのペアをスコアリングして並べ替える。 - 位置づけ:インデックスや検索スキームとは独立した 後段処理。
- 効用:上位の順序誤差を是正し、「本当に読みたい順」に近づける。
- 注意:計算コスト増(バッチ数・文字数に依存)— まずは上位20〜50件を再ランク対象にするのが現実的。
Qdrantのセットアップ
- ローカルのDocker上で動かす
Qdrantのイメージ取得
docker pull qdrant/qdrant
Qdrant起動(コンテナ作成)
docker run --name qdrant \
-p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
- --name qdrant : コンテナ名
- -p 6333:6333 : ポート開放(Pythonからアクセス可能になる)
- -v ... : ストレージをホストに保存(データ永続化)
その他のDockerコマンド
その他のコマンド
- 一覧表示
docker ps -a
- 停止
docker stop qdrant
- 再起動
docker start qdrant
- 完全に削除
docker rm qdrant
起動後、以下のURLでダッシュボードを確認できる。
Pythonからの接続準備
仮想環境の作成
- プロジェクト用ディレクトリで下記のコマンドを実行
python3 -m venv .venv
- 有効化
source .venv/bin/activate
ライブラリのインストール
- .venvを有効化してからインストールする。
- pip, setuptools, wheel をアップグレードすることで、最新のパッケージ管理機能を利用できる。
python -m pip install --upgrade pip setuptools wheel
python -m pip install -U \
"qdrant-client>=1.15.0" "pydantic>=2.7,<2.12" \
sentence-transformers FlagEmbedding scipy \
torch torchvision torchaudio \
pandas pymupdf
埋め込みモデルのダウンロード
- ローカルに保存する。
python - <<'PY'
from huggingface_hub import snapshot_download
snapshot_download("BAAI/bge-m3", local_dir="./models/bge-m3", local_dir_use_symlinks=False)
print("Downloaded to ./models/bge-m3")
PY
※ すでに ./models/bge-m3 がある場合は再ダウンロード不要。初回の実行時に数 GB のモデルを取得。
最小構成での動作確認(6パターン比較)
まずは固定の短文コーパスで、インデックス × 再ランク の 6 パターンを比較する。
比較軸
- インデックス:
dense/sparse/both(同一点に dense+sparse を格納) - 再ランク:
none/cross(BAAI/bge-reranker-v2-m3)
実行例(どれか一つずつ実行)
python test_index_and_rerank.py --index dense --rerank none
python test_index_and_rerank.py --index dense --rerank cross
python test_index_and_rerank.py --index sparse --rerank none
python test_index_and_rerank.py --index sparse --rerank cross
python test_index_and_rerank.py --index both --rerank none
python test_index_and_rerank.py --index both --rerank cross
from __future__ import annotations
from dataclasses import dataclass
from typing import List, Dict, Any, Optional
import argparse
from qdrant_client import QdrantClient
from qdrant_client.http import models as qm
from qdrant_client.http.models import SparseVector, PointStruct
from sentence_transformers import SentenceTransformer
from FlagEmbedding import BGEM3FlagModel, FlagReranker
import numpy as np
# =============================
# 設定(環境・モデル・コレクション名)
# =============================
HOST, PORT = "localhost", 6333
MODEL_DIR = "./models/bge-m3" # SentenceTransformer 互換のローカルモデル(dense用)
COLL = "test_compare"
# デモ用のコーパス(検証用の短文サンプル)
TEXTS = [
"今日は天気がいい",
"年末年始の休暇規定を確認してください",
"申請の締切日は12月15日です",
"API 標準設計ガイドの参照はこちら",
"会議は月曜日に延期になりました",
"正しいPythonの環境構築方法",
"Please check the holiday policy for New Year vacation.",
]
# 既定クエリと返却件数
QUERY = "正月の休暇と申請締切"
TOP_K = 5
# ==============================================
# ユーティリティ(RRFと正規化、sparse出力の整形)
# ==============================================
def rrf_fuse(id_lists: List[List[int]], k: int = 60) -> List[int]:
"""RRF (Reciprocal Rank Fusion) による ID 融合。
複数のランキング(例: dense と sparse)を統合するために、順位に基づく逆数でスコアを合算する。
Args:
id_lists: 各ランキング結果の ID リスト(上位順)
k: RRF の平滑化パラメータ(大きいほど上位の差が緩やか)
Returns:
統合後の ID リスト(高スコア順)
"""
score: Dict[int, float] = {}
for id_list in id_lists:
for rank, pid in enumerate(id_list, start=1):
score[pid] = score.get(pid, 0.0) + 1.0 / (k + rank)
return [pid for pid, _ in sorted(score.items(), key=lambda x: x[1], reverse=True)]
def to_qdrant_sparse_list(m3_output: Dict[str, Any]) -> List[SparseVector]:
"""BGE-M3 の sparse 出力(2形式のいずれか)を Qdrant の SparseVector に変換。
BGEM3FlagModel.encode(..., return_sparse=True) の戻り値は以下のどちらか:
- "sparse_vecs": SciPy CSR 行列(indices/data を持つ)
- "lexical_weights": { token_id(int) -> weight(float) } の辞書
どちらにせよ Qdrant の SparseVector(indices, values) の配列へ正規化する。
"""
sv_list: List[SparseVector] = []
if "sparse_vecs" in m3_output:
for sp in m3_output["sparse_vecs"]:
sv_list.append(SparseVector(indices=sp.indices.tolist(), values=sp.data.tolist()))
elif "lexical_weights" in m3_output:
for lw in m3_output["lexical_weights"]:
items = sorted((int(k), float(v)) for k, v in lw.items())
idx = [i for i, _ in items]
val = [v for _, v in items]
sv_list.append(SparseVector(indices=idx, values=val))
else:
raise ValueError("BGEM3の出力にsparse情報が見つかりません")
return sv_list
# ==============================================
# PointStruct 生成ヘルパ(互換性を意識)
# ==============================================
def _make_point_dense(id_: int, v: List[float], payload: Dict[str, Any]) -> PointStruct:
"""dense 用の PointStruct を作成(名前付きベクトル 'dense' を使用)。"""
return PointStruct(id=id_, vector={"dense": v}, payload=payload)
def _make_point_sparse_only(id_: int, sv: SparseVector, payload: Dict[str, Any]) -> PointStruct:
"""sparse のみの PointStruct を作成(名前付きベクトル 'sparse' を使用)。"""
return PointStruct(id=id_, vector={"sparse": sv}, payload=payload)
def _make_point_dense_and_sparse(id_: int, v: List[float], sv: SparseVector, payload: Dict[str, Any]) -> PointStruct:
"""dense + sparse を同一ポイントに保持する PointStruct を作成。"""
return PointStruct(id=id_, vector={"dense": v, "sparse": sv}, payload=payload)
# ==============================================
# コレクション作成(dense / sparse / 両方)
# ==============================================
def recreate_collection_dense(q: QdrantClient, dim: int) -> None:
"""dense 専用のコレクションを作り直す(既存は削除)。"""
if q.collection_exists(COLL):
q.delete_collection(COLL)
q.create_collection(
collection_name=COLL,
vectors_config={"dense": qm.VectorParams(size=dim, distance=qm.Distance.COSINE)},
)
def recreate_collection_sparse(q: QdrantClient) -> None:
"""sparse 専用のコレクションを作り直す(既存は削除)。"""
if q.collection_exists(COLL):
q.delete_collection(COLL)
q.create_collection(
collection_name=COLL,
vectors_config=None, # dense は作らない
sparse_vectors_config={"sparse": qm.SparseVectorParams()},
)
def recreate_collection_both(q: QdrantClient, dim: int) -> None:
"""dense + sparse の両方を保持できるコレクションを作り直す(既存は削除)。"""
if q.collection_exists(COLL):
q.delete_collection(COLL)
q.create_collection(
collection_name=COLL,
vectors_config={"dense": qm.VectorParams(size=dim, distance=qm.Distance.COSINE)},
sparse_vectors_config={"sparse": qm.SparseVectorParams()},
)
# ==============================================
# アップサート(dense / sparse / 両方)
# ==============================================
def upsert_dense(q: QdrantClient, dense_model: SentenceTransformer) -> None:
"""dense ベクトルのみを各テキストに付与して upsert。"""
vecs = [dense_model.encode(t, normalize_embeddings=True).tolist() for t in TEXTS]
pts = [_make_point_dense(i, v, {"text": t}) for i, (t, v) in enumerate(zip(TEXTS, vecs), start=1)]
q.upsert(COLL, points=pts)
def upsert_sparse(q: QdrantClient, m3: BGEM3FlagModel) -> None:
"""sparse ベクトルのみを各テキストに付与して upsert。"""
out = m3.encode(TEXTS, return_sparse=True)
sp_list = to_qdrant_sparse_list(out)
pts = []
for i, (t, sp) in enumerate(zip(TEXTS, sp_list), start=1):
pts.append(_make_point_sparse_only(i, sp, {"text": t}))
q.upsert(COLL, points=pts)
def upsert_both(q: QdrantClient, dense_model: SentenceTransformer, m3: BGEM3FlagModel) -> None:
"""dense + sparse を同一ポイントに持たせて upsert。ハイブリッド検索の前提。"""
vecs = [dense_model.encode(t, normalize_embeddings=True).tolist() for t in TEXTS]
out = m3.encode(TEXTS, return_sparse=True)
sp_list = to_qdrant_sparse_list(out)
pts = []
for i, (t, v, sp) in enumerate(zip(TEXTS, vecs, sp_list), start=1):
pts.append(_make_point_dense_and_sparse(i, v, sp, {"text": t}))
q.upsert(COLL, points=pts)
# ==============================================
# 検索(dense / sparse / ハイブリッド[RRF])
# ==============================================
def search_dense(q: QdrantClient, dense_model: SentenceTransformer, qtext: str, top_k: int = TOP_K):
"""dense 検索:クエリを dense に埋め込み、名前 'dense' で検索。"""
qvec = dense_model.encode(qtext, normalize_embeddings=True).tolist()
res = q.query_points(
collection_name=COLL,
query=qvec,
using="dense",
limit=top_k,
search_params=qm.SearchParams(hnsw_ef=128),
)
return res.points
def search_sparse(q: QdrantClient, m3: BGEM3FlagModel, qtext: str, top_k: int = TOP_K):
"""sparse 検索:クエリを sparse に変換し、名前 'sparse' で検索。"""
out = m3.encode([qtext], return_sparse=True)
q_sp = to_qdrant_sparse_list(out)[0]
res = q.query_points(
collection_name=COLL,
query=q_sp,
using="sparse",
limit=top_k,
)
return res.points
def search_hybrid_rrf(q: QdrantClient, dense_model: SentenceTransformer, m3: BGEM3FlagModel,
qtext: str, top_k: int = TOP_K):
"""ハイブリッド検索:dense と sparse の上位を取り出し、RRF で統合。"""
dh = search_dense(q, dense_model, qtext, top_k=top_k)
sh = search_sparse(q, m3, qtext, top_k=top_k)
dense_ids = [h.id for h in dh]
sparse_ids = [h.id for h in sh]
fused_ids = rrf_fuse([dense_ids, sparse_ids])[:top_k]
# ID を元にスコア付きヒットへ戻す(dense を優先、無ければ sparse を利用)
by_id = {h.id: h for h in dh}
for h in sh:
by_id.setdefault(h.id, h)
return [by_id[i] for i in fused_ids if i in by_id]
# ==============================================
# クロスエンコード・リランク
# ==============================================
def cross_rerank(qtext: str, hits: List[qm.ScoredPoint], max_chars: int = 1400, batch_size: int = 16):
"""クロスエンコーダ(BAAI/bge-reranker-v2-m3)での再ランク。
セマンティック類似度で取得した候補に対し、クエリとテキストの対をスコアリングして並べ替える。
"""
rr = FlagReranker("BAAI/bge-reranker-v2-m3", use_fp16=True)
pairs, keep = [], []
for h in hits:
t = (h.payload.get("text") or "")[:max_chars].replace("\n", " ")
if t.strip():
pairs.append([qtext, t])
keep.append(h)
scores = rr.compute_score(pairs, normalize=True, batch_size=batch_size)
for h, s in zip(keep, scores):
h.payload["_cross"] = float(s)
keep.sort(key=lambda x: x.payload.get("_cross", 0.0), reverse=True)
return keep
# ==============================================
# メイン(6パターン比較:index 3種 × rerank 2種)
# ==============================================
def main() -> None:
"""コマンドライン引数を受け取り、インデックス作成 → 検索 →(任意)再ランク → 出力 を実行。"""
ap = argparse.ArgumentParser(description="Dense/Sparse/Both × Cross Rerank の6パターン比較")
ap.add_argument("--index", choices=["dense", "sparse", "both"], required=True, help="作成するインデックスの種類")
ap.add_argument("--rerank", choices=["none", "cross"], default="none", help="最終段の再ランク方式(なし or クロスエンコーダ)")
ap.add_argument("--query", default=QUERY, help="検索クエリ(既定: %(default)s)")
ap.add_argument("--top_k", type=int, default=TOP_K, help="取得件数(既定: %(default)s)")
args = ap.parse_args()
q = QdrantClient(host=HOST, port=PORT)
dense_model = SentenceTransformer(MODEL_DIR)
m3 = BGEM3FlagModel("BAAI/bge-m3", use_fp16=True)
dim = dense_model.get_sentence_embedding_dimension()
# 1) コレクションを作り直して投入
if args.index == "dense":
recreate_collection_dense(q, dim)
upsert_dense(q, dense_model)
searcher = lambda: search_dense(q, dense_model, args.query, args.top_k)
title = "INDEX = DENSE, SEARCH = DENSE"
elif args.index == "sparse":
recreate_collection_sparse(q)
upsert_sparse(q, m3)
searcher = lambda: search_sparse(q, m3, args.query, args.top_k)
title = "INDEX = SPARSE, SEARCH = SPARSE"
else: # both
recreate_collection_both(q, dim)
upsert_both(q, dense_model, m3)
searcher = lambda: search_hybrid_rrf(q, dense_model, m3, args.query, args.top_k)
title = "INDEX = BOTH, SEARCH = HYBRID(RRF)"
# 2) 検索 → (任意)クロス再ランク
hits = searcher()
if args.rerank == "cross":
hits = cross_rerank(args.query, hits)
# 3) 出力
print(f"\n{title} RERANK={args.rerank.upper()}")
print(f'Query: "{args.query}"\n')
for h in hits:
base = f"score={h.score:.3f}"
if "_cross" in h.payload:
base += f" cross={h.payload['_cross']:.3f}"
print(f"{base} id={h.id} text={h.payload.get('text','')}")
if __name__ == "__main__":
main()
出力結果
python test_index_and_rerank.py --index dense --rerank none
INDEX = DENSE, SEARCH = DENSE RERANK=NONE
Query: "正月の休暇と申請締切"
score=0.727 id=2 text=年末年始の休暇規定を確認してください
score=0.664 id=7 text=Please check the holiday policy for New Year vacation.
score=0.617 id=3 text=申請の締切日は12月15日です
score=0.474 id=5 text=会議は月曜日に延期になりました
score=0.378 id=1 text=今日は天気がいい
(参考)他のパターンでの実行結果
python test_index_and_rerank.py --index dense --rerank cross
INDEX = DENSE, SEARCH = DENSE RERANK=CROSS
Query: "正月の休暇と申請締切"
score=0.617 cross=0.030 id=3 text=申請の締切日は12月15日です
score=0.727 cross=0.025 id=2 text=年末年始の休暇規定を確認してください
score=0.664 cross=0.020 id=7 text=Please check the holiday policy for New Year vacation.
score=0.474 cross=0.000 id=5 text=会議は月曜日に延期になりました
score=0.378 cross=0.000 id=1 text=今日は天気がいい
python test_index_and_rerank.py --index sparse --rerank none
INDEX = SPARSE, SEARCH = SPARSE RERANK=NONE
Query: "正月の休暇と申請締切"
score=0.097 id=3 text=申請の締切日は12月15日です
score=0.071 id=2 text=年末年始の休暇規定を確認してください
score=0.001 id=6 text=正しいPythonの環境構築方法
score=0.000 id=5 text=会議は月曜日に延期になりました
python test_index_and_rerank.py --index sparse --rerank cross
INDEX = SPARSE, SEARCH = SPARSE RERANK=CROSS
Query: "正月の休暇と申請締切"
score=0.097 cross=0.030 id=3 text=申請の締切日は12月15日です
score=0.071 cross=0.025 id=2 text=年末年始の休暇規定を確認してください
score=0.000 cross=0.000 id=5 text=会議は月曜日に延期になりました
score=0.001 cross=0.000 id=6 text=正しいPythonの環境構築方法
python test_index_and_rerank.py --index both --rerank none
INDEX = BOTH, SEARCH = HYBRID(RRF) RERANK=NONE
Query: "正月の休暇と申請締切"
score=0.727 id=2 text=年末年始の休暇規定を確認してください
score=0.617 id=3 text=申請の締切日は12月15日です
score=0.474 id=5 text=会議は月曜日に延期になりました
score=0.664 id=7 text=Please check the holiday policy for New Year vacation.
score=0.001 id=6 text=正しいPythonの環境構築方法
python test_index_and_rerank.py --index both --rerank cross
INDEX = BOTH, SEARCH = HYBRID(RRF) RERANK=CROSS
Query: "正月の休暇と申請締切"
score=0.617 cross=0.030 id=3 text=申請の締切日は12月15日です
score=0.727 cross=0.025 id=2 text=年末年始の休暇規定を確認してください
score=0.664 cross=0.020 id=7 text=Please check the holiday policy for New Year vacation.
score=0.474 cross=0.000 id=5 text=会議は月曜日に延期になりました
score=0.001 cross=0.000 id=6 text=正しいPythonの環境構築方法
ハマりどころ
-
vector 次元不一致: 「expected dim: 384, got 1024」等 → コレクション作成時の
sizeと実際の埋め込み次元が不一致。コレクションを作り直す。 -
sparse を upsert できない: qdrant-client の古い型では
sparse_vectorsが未対応。qdrant-client>=1.15.0+pydantic>=2.7,<2.12を推奨。 -
ディスク不足(HF モデル取得時):
No space left on device→ モデル保存先の空き容量を増やすか、local_dirを外部ディスクに変更。 -
Docker の永続化忘れ: コンテナを消すとデータも消える。
-v $(pwd)/qdrant_storage:/qdrant/storageを必ず指定。
社内ドキュメント検索の実装
実装ファイル構成
project/
├─ models/
│ └─ bge-m3/ # ローカル保存した埋め込みモデル(HF からDL)
├─ docs/ # 取り込み対象の社内文書(.txt/.md/.pdf)
├─ services/
│ └─ search_engine.py # 検索サービス(dense/sparse/hybrid + cross-rerank)
├─ infrastructure/
│ ├─ embed.py # dense埋め込み(SentenceTransformer)
│ ├─ extract.py # テキスト抽出&チャンク分割
│ └─ qdrant_store.py # Qdrantラッパ(dense/sparse/hybrid RRF)
└─ scripts/
├─ upsert_docs.py # 取り込み(常に dense+sparse を同一点にUpsert)
└─ search_cli.py # 検索CLI
-
infrastructure/embed.py:埋め込み(BGE-M3 の dense)を生成 -
infrastructure/extract.py:テキスト抽出(.txt / .md / .pdf)とチャンク分割 -
infrastructure/qdrant_store.py:Qdrant の作成・upsert・検索(named vectors:dense/sparse、ハイブリッドRRF) -
services/search_engine.py:検索(--mode dense|sparse|hybrid、--rerank crossなど) -
scripts/upsert_docs.py:ローカルのドキュメントを抽出→分割→dense+sparse を同一点に upsert -
scripts/search_cli.py:検索CLI
方針:常に
denseとsparseを同じポイントに格納しておき、実行時に検索方式を切り替える。
(再投入を避けたい・運用簡易化のため)
実装のポイント
-
Named Vectors:コレクション作成時に
denseとsparseを定義。1ポイントに両方保存。 -
Upsert:
PointStruct(..., vector={"dense": d, "sparse": s})で投入。 -
検索:
- dense →
query_points(..., using="dense") - sparse →
query_points(..., using="sparse") - hybrid → dense と sparse を別々に検索し RRF で順位融合
- dense →
-
再ランク(任意):上位 N 件を
BAAI/bge-reranker-v2-m3でクロスエンコーダ再ランク。 -
重複除去:
--unique_per_pathを既定 ON。パス正規化で同一ファイルの重複を抑止。
使い方(CLI)
1) インデックス作成(ローカルドキュメントを登録)
# コレクション 'docs' を作り直し、dense+sparse を同一点に upsert
python -m scripts.upsert_docs --root ./docs --collection docs --recreate
主な引数:
-
--root: 取り込み対象フォルダ(.txt/.md/.pdf) -
--collection: Qdrant のコレクション名 -
--recreate: 既存コレクションを削除して作り直す
※ 初回はモデル(BGE-M3)を数GBダウンロード。
2) 検索
# dense 検索
python -m scripts.search_cli --q "API 設計" --mode dense --top_k 10
# sparse 検索(語彙一致重視)
python -m scripts.search_cli --q "API 設計" --mode sparse --top_k 10
# ハイブリッド(RRF) + クロス再ランク
python -m scripts.search_cli --q "API 設計" --mode hybrid --rerank cross --top_k 10
便利オプション:
-
--type .pdf: ファイル種別でフィルタ -
--unique_per_path: 同一ファイルからは 1 件のみ(既定 ON) -
--prefer_path_contains api guide ipa: パスに含む語で優先(スコアにブースト)
embed.py
- 役割:BGE-M3(SentenceTransformer互換)で dense埋め込み を生成。
- 正規化:normalize_embeddings=True でコサイン類似度前提の長さ正規化。
- バッチ処理:encode_batch(..., batch_size=32) はメモリと速度の妥協点。GPU/VRAMに合わせて調整。
embed.py
from sentence_transformers import SentenceTransformer
class Embedder:
def __init__(self, model_dir: str = "./models/bge-m3"):
self.model = SentenceTransformer(model_dir)
self._dim = self.model.get_sentence_embedding_dimension()
@property
def dim(self) -> int:
return self._dim
def encode(self, text: str, is_query: bool = False) -> list[float]:
return self.model.encode(text, normalize_embeddings=True).tolist()
def encode_batch(self, texts: list[str], is_query: bool = False) -> list[list[float]]:
vecs = self.model.encode(texts, normalize_embeddings=True, batch_size=32)
return [v.tolist() for v in vecs]
extract.py
- テキスト抽出:.txt/.md/.pdf を単一パスで扱う。PDFは PyMuPDF でページ毎に抽出。
- クリーニング:ページ番号や連続空白など最低限のノイズ除去。
- チャンク分割:固定長スライディング(size=1000, overlap=200)。
- チャンクは 意味境界非考慮のシンプル方式。精度を上げたいなら文/段落ベースの「スマート分割」へ差し替えを検討。
extract.py
from pathlib import Path
import fitz # PyMuPDF
import re
def load_text(path: Path) -> str:
s = path.suffix.lower()
if s == ".txt":
return path.read_text(encoding="utf-8", errors="ignore")
if s == ".pdf":
doc = fitz.open(path)
parts = []
for page in doc:
t = page.get_text("text")
# ---- ノイズ掃除 ----
t = re.sub(r"\.{4,}", " ", t) # 「……」や「................」を空白に
t = re.sub(r"(?m)^\s*\d{1,3}\s*$", "", t) # ページ番号だけの行を削除
t = re.sub(r"[ \t]{2,}", " ", t) # 連続スペースを1つに
parts.append(t)
return "\n".join(parts)
if s in {".md", ".markdown"}:
return path.read_text(encoding="utf-8", errors="ignore")
return ""
def chunk(text: str, size=1000, overlap=200) -> list[str]:
out, i, L = [], 0, len(text)
while i < L:
seg = text[i:i+size]
if seg.strip():
out.append(seg)
i += max(1, size - overlap)
return out
qdrant_store.py
- コレクション設計:Named Vectors を使用し、1ポイントに dense と sparse を同居。
- recreate() は常に dense + sparse を作成。
- Upsert:upsert() は 両方のベクトル必須({"dense": d, "sparse": s})。
- 検索API:query_points(..., using="dense|sparse") を優先。古い環境では search() に自動フォールバック可。
- ハイブリッド:search_hybrid_rrf() で dense/sparse の上位を RRF融合(k=60は緩やか設定、要調整)。
- 注意:クライアント/サーバのバージョン差で「sparse未対応」になることがあるので、qdrant-client>=1.15 推奨。
qdrant_store.py
from __future__ import annotations
from typing import Dict, List, Optional
from qdrant_client import QdrantClient
from qdrant_client.http import models as qm
from qdrant_client.http.models import SparseVector, PointStruct
class QdrantStore:
"""
Qdrant ラッパー(dense / sparse / hybrid 検索対応)
仕様:
- コレクションは常に dense('dense') と sparse('sparse') の両方を作成
- upsert() は必ず両方(dense + sparse)を登録
- search_* はそれぞれのベクトル名を明示(新API query_points を優先・旧 search をフォールバック)
"""
def __init__(self, host: str = "localhost", port: int = 6333):
self.q = QdrantClient(host=host, port=port)
# -----------------------------
# Collection create / recreate
# -----------------------------
def recreate(self, collection: str, dim: int) -> None:
"""
名前付きベクトル 'dense' と疎ベクトル 'sparse' の両方を持つコレクションを作り直す。
"""
if self.q.collection_exists(collection):
self.q.delete_collection(collection)
self.q.create_collection(
collection_name=collection,
vectors_config={
"dense": qm.VectorParams(size=dim, distance=qm.Distance.COSINE)
},
sparse_vectors_config={
"sparse": qm.SparseVectorParams()
},
)
# ---------------
# Upsert (both)
# ---------------
def upsert(
self,
collection: str,
ids: List[str],
payloads: List[dict],
*,
dense_vecs: List[List[float]],
sparse_vecs: List[SparseVector],
) -> None:
_check_same_len(ids, payloads, dense_vecs, sparse_vecs)
points: List[PointStruct] = []
for pid, d, s, p in zip(ids, dense_vecs, sparse_vecs, payloads):
points.append(PointStruct(id=pid, vector={"dense": d, "sparse": s}, payload=p))
self.q.upsert(collection_name=collection, points=points)
# -----------------
# Search utilities
# -----------------
@staticmethod
def _to_filter(filters: Optional[Dict]) -> Optional[qm.Filter]:
if not filters:
return None
must = [
qm.FieldCondition(key=k, match=qm.MatchValue(value=v))
for k, v in filters.items()
]
return qm.Filter(must=must)
def search_dense(
self,
collection: str,
query_vector: List[float],
top_k: int = 5,
filters: Optional[Dict] = None,
) -> List[dict]:
qfilter = self._to_filter(filters)
res = self.q.query_points(
collection_name=collection,
query=query_vector,
using="dense",
limit=top_k,
query_filter=qfilter,
search_params=qm.SearchParams(hnsw_ef=128),
)
hits = res.points
return [{"score": h.score, **(h.payload or {})} for h in hits]
def search_sparse(
self,
collection: str,
query_sparse: SparseVector,
top_k: int = 5,
filters: Optional[Dict] = None,
) -> List[dict]:
qfilter = self._to_filter(filters)
res = self.q.query_points(
collection_name=collection,
query=query_sparse,
using="sparse",
limit=top_k,
query_filter=qfilter,
)
hits = res.points
return [{"score": h.score, **(h.payload or {})} for h in hits]
def search_hybrid_rrf(
self,
collection: str,
query_vector: List[float],
query_sparse: SparseVector,
top_k: int = 5,
filters: Optional[Dict] = None,
rrf_k: int = 60,
) -> List[dict]:
"""
dense と sparse を RRF (Reciprocal Rank Fusion) で融合。
"""
d_hits = self.search_dense(collection, query_vector, top_k=top_k, filters=filters)
s_hits = self.search_sparse(collection, query_sparse, top_k=top_k, filters=filters)
# 表示キー(path + chunk + snippet 先頭)
def _key(h: dict) -> str:
return f"{h.get('path','')}|{h.get('chunk','')}|{(h.get('snippet') or h.get('text',''))[:80]}"
fused: Dict[str, dict] = {}
for rank, h in enumerate(d_hits, start=1):
k = _key(h)
fused.setdefault(k, {**h, "_rrf": 0.0})
fused[k]["_rrf"] += 1.0 / (rrf_k + rank)
for rank, h in enumerate(s_hits, start=1):
k = _key(h)
fused.setdefault(k, {**h, "_rrf": 0.0})
fused[k]["_rrf"] += 1.0 / (rrf_k + rank)
out = sorted(fused.values(), key=lambda x: x["_rrf"], reverse=True)[:top_k]
for h in out:
h["score"] = h.pop("_rrf")
return out
# -----------------
# helpers
# -----------------
def _check_same_len(ids, payloads, dense_vecs, sparse_vecs) -> None:
n = len(ids)
if not (len(payloads) == len(dense_vecs) == len(sparse_vecs) == n):
raise ValueError(
f"length mismatch: ids={len(ids)}, payloads={len(payloads)}, "
f"dense_vecs={len(dense_vecs)}, sparse_vecs={len(sparse_vecs)}"
)
search_engine.py
- 重複除去:パス正規化して「同一ファイル内の重複チャンク」を1件に集約。
- 再ランク:rerank="cross" 指定時、BAAI/bge-reranker-v2-m3 で上位のみクロスエンコード再スコアリング。
search_engine.py
from __future__ import annotations
from typing import List, Dict, Optional, Tuple
from pathlib import Path
from qdrant_client.http.models import SparseVector
from infrastructure.embed import Embedder
from infrastructure.qdrant_store import QdrantStore
from FlagEmbedding import BGEM3FlagModel, FlagReranker
def _to_qdrant_sparse_list(m3_output) -> List[SparseVector]:
"""BGEM3 の sparse 出力を Qdrant の SparseVector へ正規化"""
sv_list: List[SparseVector] = []
if "sparse_vecs" in m3_output:
for sp in m3_output["sparse_vecs"]:
sv_list.append(SparseVector(indices=sp.indices.tolist(), values=sp.data.tolist()))
elif "lexical_weights" in m3_output:
for lw in m3_output["lexical_weights"]:
items = sorted((int(k), float(v)) for k, v in lw.items())
idx = [i for i, _ in items]
val = [v for _, v in items]
sv_list.append(SparseVector(indices=idx, values=val))
else:
raise ValueError("No sparse vectors found in BGEM3 output")
return sv_list
def _normalize_path(p: Optional[str]) -> str:
"""パス文字列を正規化(大文字小文字/セパレータ/./など)"""
if not p:
return ""
try:
return Path(p).as_posix().lower()
except Exception:
return str(p).lower()
def _path_key(hit: Dict) -> str:
"""重複判定用キー(path が無い場合は stem を使って近似的にまとめる)"""
p = _normalize_path(hit.get("path"))
if p:
return p
stem = ""
try:
raw = hit.get("path") or ""
stem = Path(str(raw)).stem.lower()
except Exception:
pass
return f"__nop__::{stem}"
def _score_tuple_for_pick(hit: Dict) -> Tuple[float, float]:
"""重複時に“どちらを残すか”の比較キー(cross を最優先、次に類似度スコア)"""
c = hit.get("_cross", None)
s = hit.get("score", 0.0)
return ((c if c is not None else float("-inf")), s)
def _sort_key_final(hit: Dict) -> Tuple[float, float]:
"""最終の並び順(cross があれば第一指標、無ければ極小値にしてスコアで並べる)"""
c = hit.get("_cross", None)
s = hit.get("score", 0.0)
return (c if c is not None else -1e9, s)
class SearchEngine:
"""
検索の共通クラス。
- Embedder / QdrantStore は必須
- BGEM3 / Reranker は必要な時だけ渡せばOK(Noneでも動くモードは動く)
使い方:
eng = SearchEngine(store, emb, m3=..., reranker=...)
hits = eng.search(
collection="docs",
query="API 設計",
mode="hybrid", # "dense" / "sparse" / "hybrid"
top_k=10,
filters={"type": ".pdf"}, # 任意
unique_per_path=True,
prefer_path_contains=["api","guide","ipa"], # 任意
rerank="cross", # "none" / "cross"
)
"""
def __init__(
self,
store: QdrantStore,
embedder: Embedder,
m3: Optional["BGEM3FlagModel"] = None,
reranker: Optional["FlagReranker"] = None,
):
self.store = store
self.emb = embedder
self.m3 = m3
self.reranker = reranker
# ---- 基本検索 ----
def _search_dense(self, collection: str, query: str, top_k: int, filters: Optional[Dict]) -> List[Dict]:
qvec = self.emb.encode(query, is_query=True)
return self.store.search_dense(collection, qvec, top_k, filters)
def _search_sparse(self, collection: str, query: str, top_k: int, filters: Optional[Dict]) -> List[Dict]:
assert self.m3 is not None, "BGEM3 is required for sparse search"
out = self.m3.encode([query], return_sparse=True)
q_sp = _to_qdrant_sparse_list(out)[0]
return self.store.search_sparse(collection, q_sp, top_k, filters)
def _search_hybrid_rrf(self, collection: str, query: str, top_k: int, filters: Optional[Dict]) -> List[Dict]:
assert self.m3 is not None, "BGEM3 is required for hybrid search"
qvec = self.emb.encode(query, is_query=True)
out = self.m3.encode([query], return_sparse=True)
q_sp = _to_qdrant_sparse_list(out)[0]
return self.store.search_hybrid_rrf(collection, qvec, q_sp, top_k, filters)
# ---- 重複除去 / パス優先 ----
def _dedup_by_path(self, hits: List[Dict], top_k: int) -> List[Dict]:
best_by_path: Dict[str, Dict] = {}
for h in hits:
k = _path_key(h)
cur = best_by_path.get(k)
if cur is None or _score_tuple_for_pick(h) > _score_tuple_for_pick(cur):
best_by_path[k] = h
return sorted(best_by_path.values(), key=_sort_key_final, reverse=True)[:top_k]
def _boost_by_path_keywords(self, hits: List[Dict], keywords: List[str]) -> List[Dict]:
if not keywords:
return hits
def pref_score(h):
path = (h.get("path") or "").lower()
return sum(1 for kw in keywords if kw.lower() in path)
return sorted(hits, key=lambda h: (pref_score(h), h.get("score", 0.0)), reverse=True)
# ---- クロスエンコーダ再ランク ----
def _cross_rerank(self, query: str, hits: List[Dict], max_chars: int = 1400, batch_size: int = 16) -> List[Dict]:
assert self.reranker is not None, "Reranker is not provided"
pairs, keep_idx = [], []
for i, h in enumerate(hits):
text = (h.get("snippet") or h.get("text") or "").replace("\n", " ")
if text.strip():
pairs.append([query, text[:max_chars]])
keep_idx.append(i)
if not pairs:
return hits
scores = self.reranker.compute_score(pairs, normalize=True, batch_size=batch_size)
for i, s in zip(keep_idx, scores):
hits[i]["_cross"] = float(s)
return sorted(hits, key=lambda x: x.get("_cross", 0.0), reverse=True)
# ---- 外部公開: 1本の search 関数 ----
def search(
self,
collection: str,
query: str,
mode: str = "dense", # "dense" | "sparse" | "hybrid"
top_k: int = 10,
filters: Optional[Dict] = None,
unique_per_path: bool = True,
prefer_path_contains: Optional[List[str]] = None,
rerank: str = "none", # "none" | "cross"
) -> List[Dict]:
# 1) 初段検索
if mode == "dense":
hits = self._search_dense(collection, query, top_k, filters)
elif mode == "sparse":
hits = self._search_sparse(collection, query, top_k, filters)
else: # hybrid (RRF)
hits = self._search_hybrid_rrf(collection, query, top_k, filters)
# 2) 重複除去
if unique_per_path:
hits = self._dedup_by_path(hits, top_k)
else:
hits = hits[:top_k]
# 3) パス優先ブースト
hits = self._boost_by_path_keywords(hits, prefer_path_contains or [])
# 4) クロスエンコーダ再ランク(任意)
if rerank == "cross" and self.reranker is not None:
hits = self._cross_rerank(query, hits)
return hits
upsert_doc.py
- 抽出 → 分割 → dense+sparse生成 → 同一点にUpsert。
- バッチ投入:--batch でメモリ使用量を制御。
- スニペット:payload.snippet に先頭数百文字を保存(UI/ログでの可読性向上)。
- 再作成:--recreate で毎回コレクションを作り直す。
upsert_doc.py
import uuid
import argparse
from pathlib import Path
from infrastructure.embed import Embedder
from infrastructure.qdrant_store import QdrantStore
from qdrant_client.http.models import SparseVector
import re
try:
from FlagEmbedding import BGEM3FlagModel
_HAS_FLAG = True
except Exception:
_HAS_FLAG = False
from infrastructure.extract import load_text, chunk
def _to_qdrant_sparse_list(m3_output):
"""Normalize FlagEmbedding(BGE-M3) sparse output to a list of Qdrant SparseVector.
Supports both 'sparse_vecs' (csr_matrices) and 'lexical_weights' (dict[int->float]).
"""
sv_list = []
if "sparse_vecs" in m3_output:
for sp in m3_output["sparse_vecs"]:
sv_list.append(SparseVector(indices=sp.indices.tolist(), values=sp.data.tolist()))
elif "lexical_weights" in m3_output:
for lw in m3_output["lexical_weights"]:
items = sorted((int(k), float(v)) for k, v in lw.items())
idx = [i for i, _ in items]
val = [v for _, v in items]
sv_list.append(SparseVector(indices=idx, values=val))
else:
raise ValueError("No sparse vectors found in BGEM3 output")
return sv_list
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--root", default="./docs", help="文書フォルダ(.txt/.pdf/.md)")
ap.add_argument("--collection", default="docs", help="Qdrantコレクション名")
ap.add_argument("--batch", type=int, default=256)
ap.add_argument("--recreate", action="store_true", help="コレクションを毎回作り直す")
args = ap.parse_args()
root = Path(args.root)
assert root.exists(), f"{root} がありません。"
emb = Embedder() # bge-m3 専用(./models/bge-m3)
store = QdrantStore()
m3 = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) if _HAS_FLAG else None
if args.recreate:
# コレクションは常に dense + sparse を作成
store.recreate(args.collection, emb.dim, with_sparse=True)
print(
f"[info] recreated collection '{args.collection}' "
f"(dim={emb.dim}, vectors=[dense], sparse=[sparse])"
)
exts = {".txt", ".pdf", ".md", ".markdown"}
ids, payloads, texts = [], [], []
n = 0
for p in root.rglob("*"):
if not p.is_file() or p.suffix.lower() not in exts:
continue
content = load_text(p).strip()
if not content:
continue
for i, seg in enumerate(chunk(content)):
stable_key = f"{p}#{i}"
ids.append(str(uuid.uuid5(uuid.NAMESPACE_URL, stable_key)))
payloads.append({
"path": str(p),
"chunk": i,
"type": p.suffix.lower(),
"snippet": seg.replace("\n"," ")[:240],
})
texts.append(seg)
n += 1
if len(texts) >= args.batch:
dense_vecs = emb.encode_batch(texts)
if m3 is not None:
out = m3.encode(texts, return_sparse=True)
sparse_vecs = _to_qdrant_sparse_list(out)
store.upsert(args.collection, ids, payloads, dense_vecs=dense_vecs, sparse_vecs=sparse_vecs)
else:
# Fallback: dense only if FlagEmbedding is not installed
store.upsert(args.collection, ids, payloads, dense_vecs=dense_vecs)
ids.clear(); payloads.clear(); texts.clear()
if texts:
dense_vecs = emb.encode_batch(texts)
if m3 is not None:
out = m3.encode(texts, return_sparse=True)
sparse_vecs = _to_qdrant_sparse_list(out)
store.upsert(args.collection, ids, payloads, dense_vecs=dense_vecs, sparse_vecs=sparse_vecs)
else:
store.upsert(args.collection, ids, payloads, dense_vecs=dense_vecs)
print(f"Indexed {n} chunks into '{args.collection}' (dim={emb.dim}, upsert={'dense+sparse' if m3 is not None else 'dense-only'})")
if __name__ == "__main__":
main()
search_cli.py
- 共通サービス呼び出し:SearchEngine を使い、--mode と --rerank を切替。
- 出力:score と cross(あれば)を併記、path/chunk/type と短い本文を表示。
search_cli.py
import argparse
from typing import List, Dict, Optional
from infrastructure.embed import Embedder
from infrastructure.qdrant_store import QdrantStore
from services.search_engine import SearchEngine
COLL = "docs"
def main():
ap = argparse.ArgumentParser(description="Vector search CLI (bge-m3 + Qdrant)")
ap.add_argument("--q", required=True, help="検索クエリ")
ap.add_argument("--top_k", type=int, default=10, help="取得件数(初段)")
ap.add_argument("--type", help="ファイル種別フィルタ(例: .pdf / .md / .txt)")
ap.add_argument("--unique_per_path", action="store_true", default=True,
help="同一ファイルからは1件だけ表示")
ap.add_argument("--prefer_path_contains", nargs="*",
help="パスに含まれていたら優先する語(例: --prefer_path_contains api guide ipa)")
ap.add_argument("--mode", choices=["dense", "sparse", "hybrid"], default="dense",
help="検索方式:dense / sparse / hybrid(RRF)")
ap.add_argument("--rerank", choices=["none", "cross"], default="none",
help="最終段の再ランク:なし / クロスエンコーダ")
args = ap.parse_args()
# インフラ生成
store = QdrantStore()
emb = Embedder()
# 必要に応じて BGEM3 / Reranker を遅延ロード(SearchEngine 内で使われる)
try:
from FlagEmbedding import BGEM3FlagModel, FlagReranker
m3 = BGEM3FlagModel("BAAI/bge-m3", use_fp16=True) if args.mode in ("sparse","hybrid") or args.rerank=="cross" else None
rr = FlagReranker("BAAI/bge-reranker-v2-m3", use_fp16=True) if args.rerank=="cross" else None
except Exception:
m3 = None
rr = None
engine = SearchEngine(store=store, embedder=emb, m3=m3, reranker=rr)
# フィルタ生成
filters: Optional[Dict] = {"type": args.type.lower()} if args.type else None
# 検索実行(共通ロジック)
hits = engine.search(
collection=COLL,
query=args.q,
mode=args.mode,
top_k=args.top_k,
filters=filters,
unique_per_path=args.unique_per_path,
prefer_path_contains=args.prefer_path_contains,
rerank=args.rerank,
)
# 結果表示
mode_label = {"dense":"DENSE", "sparse":"SPARSE", "hybrid":"HYBRID(RRF)"}[args.mode]
print(f'Query: "{args.q}" | MODE={mode_label} RERANK={args.rerank.upper()}')
if args.type:
print(f'Filter: type={args.type}')
for h in hits:
path = h.get("path", "")
chunk = h.get("chunk", "")
ftype = h.get("type", "")
snippet = (h.get("snippet") or h.get("text") or "")[:160].replace("\n", " ")
line = f"score={h.get("score", 0.0):.3f}"
if "_cross" in h:
line += f" cross={h['_cross']:.3f}"
print(f"\n{line} {path} (chunk {chunk}, {ftype})")
print(f" └ {snippet}")
if __name__ == "__main__":
main()
動作確認
-
テストデータとして、Markdownファイルと、IPA等で公開されているPDFをいくつか配置。

-
upsert_doc.pyを実行(ダッシュボードで確認すると、コレクションが作成されている)


検索結果
- PowerShellでExcelファイル操作の自動化についてのMarkdown記事が第一候補として抽出されており、期待通りの結果になっている。
Query: "簡単なツールを作ってファイル操作を自動化したい" | MODE=DENSE RERANK=CROSS
score=0.574 cross=0.011 docs/ps_excel_a0685efa3cc1ea.md (chunk 3, .md)
└ 式で保存) $pdfFilePath = "C:\path\to\file.pdf" $xlTypePDF = 0 # 0:PDF, 1:XPS $wb.ExportAsFixedFormat($xlTypePDF, $pdfFilePath) ``` https://learn.microsoft.com/ja-
score=0.536 cross=0.003 docs/maui_mvvm_b9685efa3cc1eb.md (chunk 3, .md)
└ 実装すると冗長になるところを自動生成してくれるライブラリ。 NuGetでインストールする。  https://learn.microsoft.com/ja-jp/dotnet/communitytoolkit/mvvm/ ## MainPageVie
score=0.555 cross=0.001 docs/ps_gui_b9685efa3cc1ea.md (chunk 1, .md)
└ ードを標準ツールでEXE化。1,2より処理速度に期待できる。ユーザーはダブルクリックで簡単に実行可能。| |4|C#をPowerShellでインプロセス実行|C#のコードをPowerShellのプロセス内で実行。1,2より処理速度に期待できる。処理の一部だけC#化することも可能。| --- ## 最小コード例 #
score=0.535 cross=0.000 docs/kihontokyoutsuu_2025.pdf (chunk 19, .pdf)
└ 権限を最小化する 不要なアカウントを作成せず、作成したアカウ ントに過剰な管理者権限や更新権限を与えない。 ・管理者権限の運用体制を整える 内部不正防止のため、IT を利用しない対策も 行う。例えば、運用担当者を制限することや利用 記録を残すこと、クロスチェックをすること等、運 用方法で対策することも有効である。
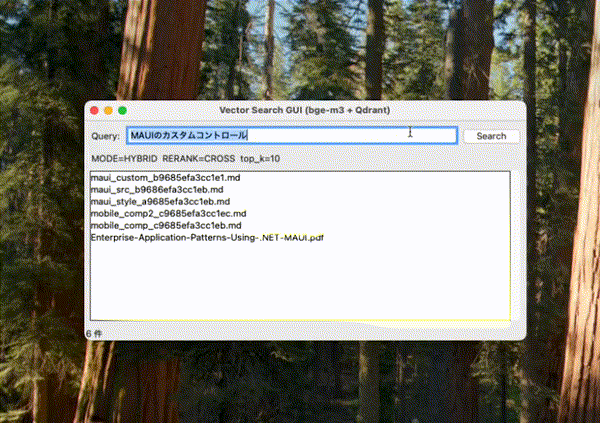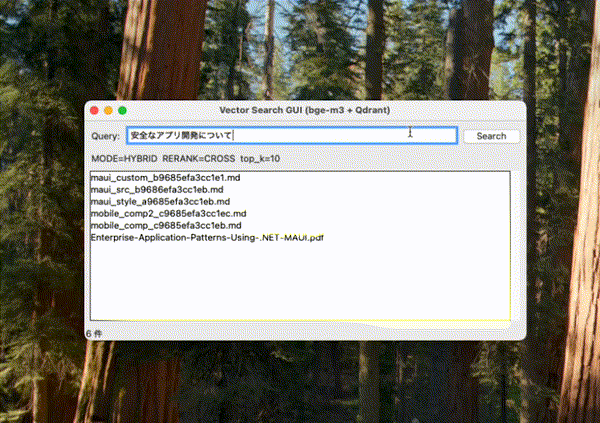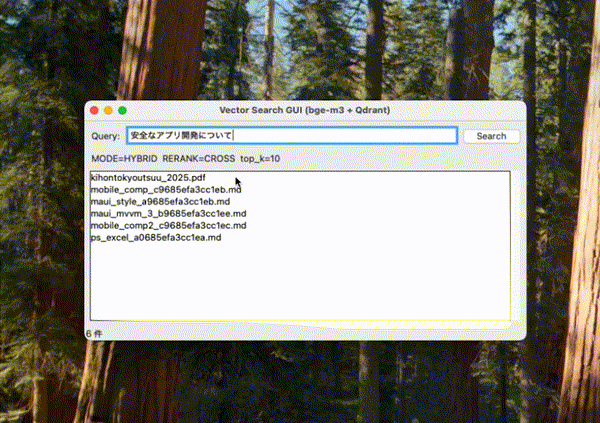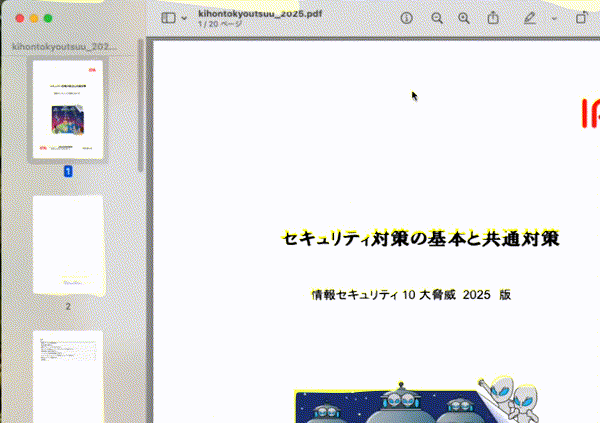
おまけ(簡易GUI)
Tkinterで簡易なGUIをつけると以下のようになる。
コード(参考)
search_gui.py
import threading
from typing import List, Dict, Optional
import tkinter as tk
from tkinter import ttk
import os
import queue
FIRST_RUN_HINT_SECS = 30
from infrastructure.embed import Embedder
from infrastructure.qdrant_store import QdrantStore
from services.search_engine import SearchEngine
COLL = "docs"
DEFAULT_TOP_K = 10
DEFAULT_MODE = "hybrid" # "dense" | "sparse" | "hybrid"
DEFAULT_RERANK = "cross" # "none" | "cross"
DEFAULT_UNIQUE_PER_PATH = True
DEFAULT_TYPE_FILTER: Optional[str] = None
class SearchGUI:
def __init__(self, root: tk.Tk):
self.root = root
self.root.title("Vector Search GUI (bge-m3 + Qdrant)")
self.root.geometry("900x600")
self._busy = False
self._spinner_job = None
self._queue = queue.Queue()
self._last_hits = []
store = QdrantStore()
emb = Embedder()
try:
from FlagEmbedding import BGEM3FlagModel, FlagReranker
m3 = BGEM3FlagModel("BAAI/bge-m3", use_fp16=True) if DEFAULT_MODE in ("sparse","hybrid") or DEFAULT_RERANK=="cross" else None
rr = FlagReranker("BAAI/bge-reranker-v2-m3", use_fp16=True) if DEFAULT_RERANK=="cross" else None
except Exception:
m3 = None
rr = None
self.engine = SearchEngine(store=store, embedder=emb, m3=m3, reranker=rr)
self._build_widgets()
self._poll_queue()
def _build_widgets(self) -> None:
top = ttk.Frame(self.root, padding=8)
top.pack(fill=tk.X)
ttk.Label(top, text="Query:").pack(side=tk.LEFT)
self.entry = ttk.Entry(top)
self.entry.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=(6, 6))
self.entry.bind("<Return>", self.on_return)
self.search_btn = ttk.Button(top, text="Search", command=self.run_search)
self.search_btn.pack(side=tk.LEFT)
self.info_var = tk.StringVar(value=f"MODE={DEFAULT_MODE.upper()} RERANK={DEFAULT_RERANK.upper()} top_k={DEFAULT_TOP_K}")
info = ttk.Label(self.root, textvariable=self.info_var)
info.pack(fill=tk.X, padx=8)
mid = ttk.Frame(self.root, padding=8)
mid.pack(fill=tk.BOTH, expand=True)
self.results = tk.Listbox(mid)
self.results.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.results.bind("<Double-1>", self.on_double_click)
sb = ttk.Scrollbar(mid, orient=tk.VERTICAL, command=self.results.yview)
sb.pack(side=tk.RIGHT, fill=tk.Y)
self.results.configure(yscrollcommand=sb.set)
self.status_var = tk.StringVar(value="Ready")
status = ttk.Label(self.root, textvariable=self.status_var, anchor="w")
status.pack(fill=tk.X)
def _start_spinner(self):
if not self._busy:
return
current = self.status_var.get()
dots = ["Searching", "Searching.", "Searching..", "Searching..."]
try:
idx = dots.index(current)
except ValueError:
idx = -1
next_idx = (idx + 1) % len(dots)
self.status_var.set(dots[next_idx])
self._spinner_job = self.root.after(300, self._start_spinner)
def _stop_spinner(self):
if self._spinner_job is not None:
self.root.after_cancel(self._spinner_job)
self._spinner_job = None
def on_return(self, event=None):
self.run_search()
def run_search(self) -> None:
query = self.entry.get().strip()
if not query:
self.status_var.set("クエリを入力してください")
return
self._busy = True
self._start_spinner()
self.search_btn.config(state=tk.DISABLED)
self.results.delete(0, tk.END)
def first_run_hint():
if self._busy and self.status_var.get().startswith("Searching"):
self.status_var.set("初回モデルのダウンロード中の場合、数分かかることがあります")
self.root.after(FIRST_RUN_HINT_SECS * 1000, first_run_hint)
def _task():
hits: List[Dict] = []
lines: List[str] = []
try:
print("[DEBUG] _task start. query=", query)
filters: Optional[Dict] = {"type": DEFAULT_TYPE_FILTER.lower()} if DEFAULT_TYPE_FILTER else None
hits = self.engine.search(
collection=COLL,
query=query,
mode=DEFAULT_MODE,
top_k=DEFAULT_TOP_K,
filters=filters,
unique_per_path=DEFAULT_UNIQUE_PER_PATH,
prefer_path_contains=None,
rerank=DEFAULT_RERANK,
)
print(f"[DEBUG] search finished. got {len(hits)} hits")
for h in hits:
path = h.get("path", "")
basename = os.path.basename(path)
lines.append(basename)
except Exception as e:
error_line = f"Error: {e}"
print(f"[DEBUG] Exception in search task: {e}")
lines = [error_line]
hits = []
finally:
self._queue.put((hits, lines))
threading.Thread(target=_task, daemon=True).start()
def _poll_queue(self):
try:
hits, lines = self._queue.get_nowait()
except queue.Empty:
pass
else:
try:
print("[DEBUG] entering _poll_queue, lines=", lines)
self.results.delete(0, tk.END)
for ln in lines:
self.results.insert(tk.END, ln)
if hits:
self.status_var.set(f"{len(hits)} 件")
else:
if lines and lines[0].startswith("Error:"):
self.status_var.set(lines[0])
else:
self.status_var.set("0 件")
self._last_hits = hits
except Exception as e:
print(f"[DEBUG] Exception in _poll_queue: {e}")
self.status_var.set(f"UI Error: {e}")
finally:
self._busy = False
self._stop_spinner()
self.search_btn.config(state=tk.NORMAL)
self.root.after(100, self._poll_queue)
def on_double_click(self, event):
selection = self.results.curselection()
if not selection:
return
index = selection[0]
if index >= len(self._last_hits):
return
hit = self._last_hits[index]
path = hit.get("path")
if path and os.name == "posix":
# macOS open command
os.system(f"open '{path}'")
def main():
root = tk.Tk()
def log_exception(exc, val, tb):
import traceback
print(f"[Tkinter Exception] {exc.__name__}: {val}")
traceback.print_tb(tb)
root.report_callback_exception = log_exception
SearchGUI(root)
root.mainloop()
if __name__ == "__main__":
main()
Discussion