ローカル環境にLangfuseとJupyterLabをDockerでサクッと構築してLLMのオブザーバビリティを試す
はじめに
AIエージェントやLLMアプリケーションが複雑化するにつれて、「LLMの内部的な挙動を追跡し、デバッグや継続的な改善に繋げる」ための観測基盤が不可欠になっています。LLMアプリケーションは、プロンプトと出力だけを見ていても、なぜその出力に至ったのかを理解するのが難しい場合が多いためです。
この記事では、LLMの挙動を追跡・可視化するツールの一つである「Langfuse」を、ローカル環境にDockerで構築し、データサイエンティストや機械学習エンジニアにとって馴染み深いJupyterLabから利用するための手順を解説します。
また、実際にJupyterLab上でGoogle ADK(Agent Development kit)で作ったAIエージェントをLangfuseでトレーシングしてみます。
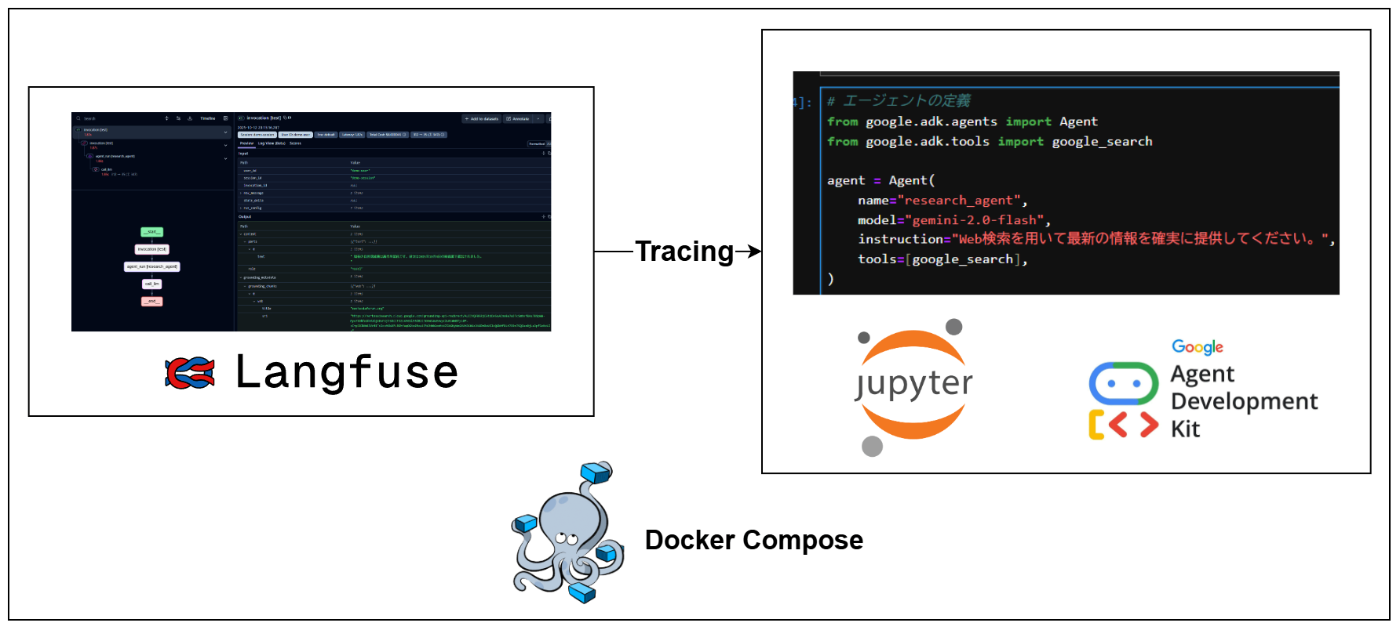
最終的な構成
なぜこの構成を選ぶのか?
今回採用する構成には、LLMアプリケーション開発の初期段階において、特に有効なメリットがあります。
-
ローカル環境で迅速に検証
業務ではセキュリティポリシーなどの理由で、外部のSaaSを気軽に試すのが難しい場合があります。セルフホスト可能なLangfuseをローカル環境に構築することで、ツールの有用性を迅速に、かつ安全に評価できます。 -
Dockerでクリーンな開発環境を維持
Dockerを利用することで、ホストマシンの環境を汚さずに済みます。依存ライブラリのバージョン競合といった環境起因のトラブルを避け、クリーンで再現性の高い実験環境を維持できます。 -
JupyterLabによるインタラクティブな試行錯誤
JupyterLabは、コードをセル単位で実行し、結果を即座に確認できるため、本格的なアプリケーションを構築する前の試行錯誤や実験に最適です。Langfuseがどのような情報を取得できるのかを、インタラクティブに確認しながら開発を進められます。 -
セルフホスト版で全コア機能を無料で試用
Langfuseのセルフホスト版は、SaaSの無料プランでは制限されている可能性のある機能も含め、全てのコア機能を無料で利用できます。将来的な有償プラン導入を見据えた評価にも適しています。
前提条件
- Docker Desktopがインストールされており、
docker composeコマンドが利用できること。 -
gitコマンドが利用できること。 - Google GeminiのAPIキーを取得済みであること。
環境構築手順
1. Langfuseのリポジトリをクローン
まず、公式のdocker-compose.ymlが含まれるLangfuseのGitリポジトリをクローンします。
git clone https://github.com/langfuse/langfuse.git
cd langfuse
2. docker-compose.ymlにJupyterLabサービスを追加
次に、docker-compose.ymlファイルを編集し、JupyterLabのサービス定義を追記します。これにより、Langfuseの各コンポーネント(サーバー、Web UI、データベース等)と同じDockerネットワーク内でJupyterLabが起動し、コンテナ間で相互に通信できるようになります。
docker-compose.ymlファイルを開き、services:セクションに以下のlangfuse-labの定義を追加してください。
services:
# ... 既存のlangfuse-server, langfuse-web, db, redis, minio, create-minio-bucketの定義 ...
langfuse-lab:
image: jupyter/scipy-notebook:latest
ports:
- "8888:8888"
volumes:
- ./notebooks:/home/jovyan/work
command: start-notebook.sh
# ... networksやvolumesの定義はそのまま ...
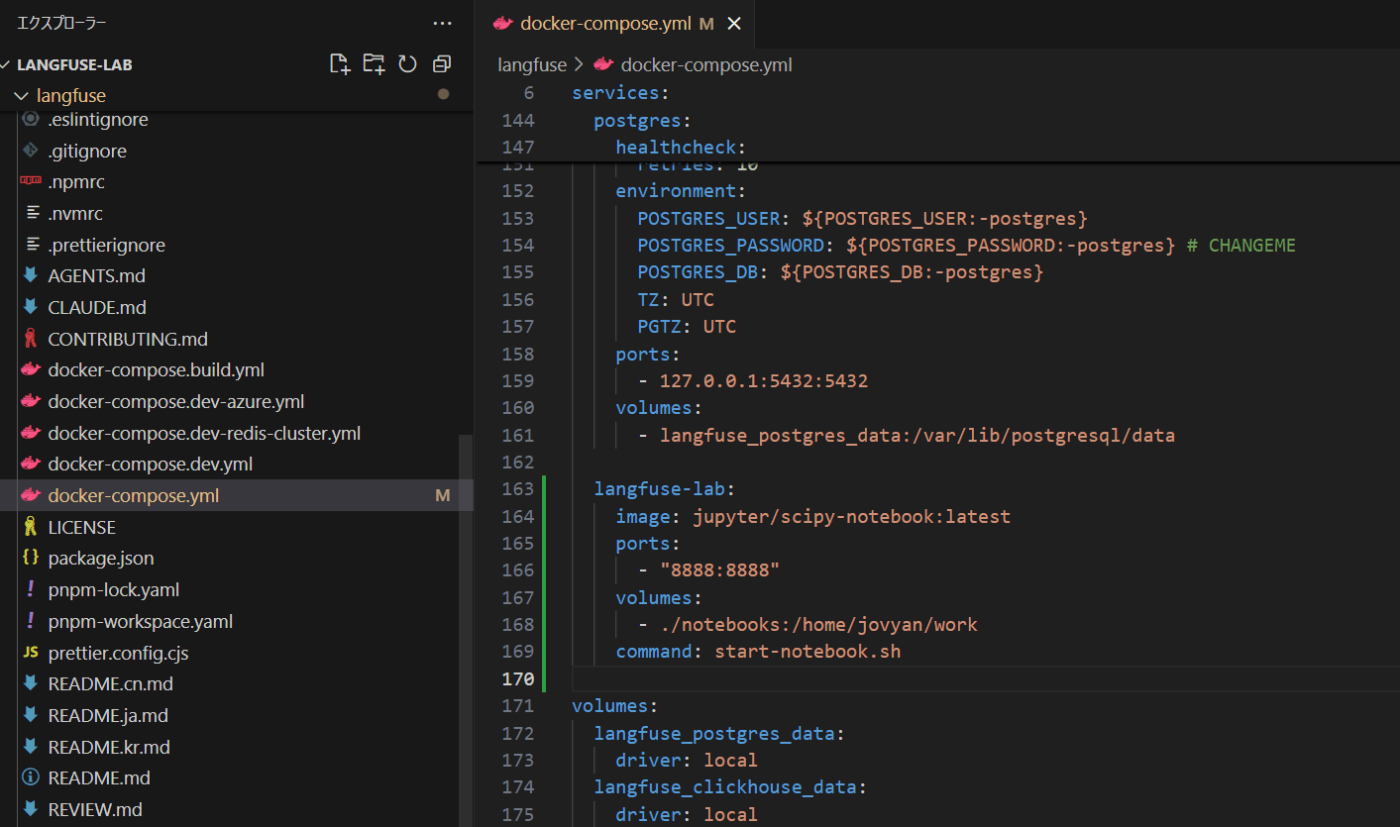
docker-compose.ymlの書き換え部分
また、JupyterLabの作業ディレクトリをホストマシンと共有するために、notebooksディレクトリを作成します。これにより、コンテナ内で作成したノートブックファイルがホストマシン上にも保存され、コンテナを停止しても作業内容が失われません。
mkdir notebooks
3. Dockerコンテナを起動
docker-compose.ymlを保存したら、以下のコマンドでLangfuseとJupyterLabの全てのコンテナを起動します。
docker compose up -d
初回起動時は、Dockerイメージのダウンロードに時間がかかる場合があります。
各サービスへのアクセスと初期設定
Langfuse UI
ブラウザで http://localhost:3000 にアクセスすると、LangfuseのUIが表示されます。初回アクセス時はアカウントを作成する必要があるので、Sign upをクリックします。
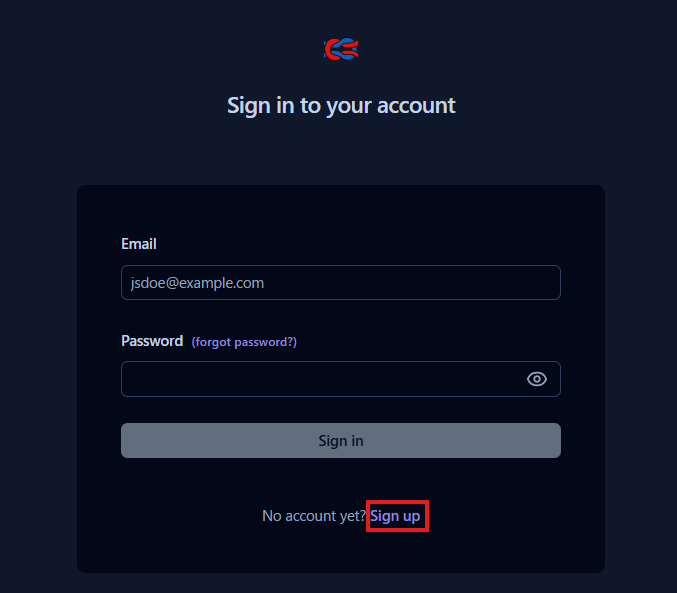
Langfuseのログイン画面
ローカル環境での検証目的なので、任意のユーザー名とパスワードでアカウントを作成してください。

Langfuseのサインアップ画面
サインアップ後、Organization(組織)とProjectの作成を求められます。こちらも今回はテスト用なので、任意の名前で作成して問題ありません。
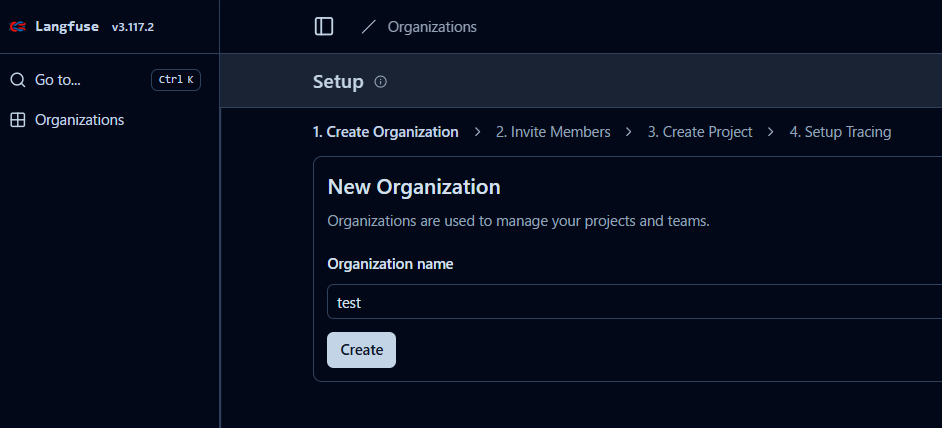
Organization作成画面

Project作成画面
プロジェクト作成後、APIキー(Secret KeyとPublic Key)が発行されます。これらのキーは、後ほどJupyter Lab上のコードからLangfuseにデータを送信するために必要となるため、控えておいてください。

APIキー作成画面
Jupyter Lab
Jupyter LabにアクセスするためのURLは、コンテナのログに出力されます。以下のコマンドでログを確認してください。
docker logs langfuse-langfuse-lab-1
ログの中に、トークン付きのURL(http://127.0.0.1:8888/lab?token=...)が出力されているので、それをコピーしてブラウザで開きます。

docker logsで確認できるログ
無事にJupyter Labにアクセスできたら、目に優しいダークモードに変更します。(お好みで)

目に優しいダークモードに変更
Google ADK (Agent Development Kit) との連携検証
環境が整ったので、実際にLLMアプリケーションを動かし、その挙動をLangfuseでトレースしてみます。Langfuseは公式ドキュメントにも記載がある通り、LangChain/LangGraphやOpenAI AgentsやStrands Agentsなど、多くの主要なフレームワークとの連携に対応しています。
今回はその中から、GoogleのAIエージェント開発用フレームワークであるGoogle ADKとの連携を試します。
1. 必要なライブラリのインストール
まず、新しいノートブックを作成し、以下のコマンドを実行して必要なライブラリをインストールします。
!pip install langfuse google-adk openinference-instrumentation-google-adk
ライブラリをインストールしたら、変更を反映させるために一度Jupyter Labのカーネルを再起動してください。

カーネルを再スタート
2. LangfuseとGoogle ADKのセットアップ
次に、LangfuseとGoogle Geminiを利用するための認証情報を環境変数に設定します。
import os
# LangfuseのAPIキーを設定
# 先ほどLangfuse UIから取得したキーに置き換えてください
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..." # 取得したSecret Key
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..." # 取得したPublic Key
# Langfuseホストの設定
# Jupyter LabコンテナからLangfuseのWebコンテナへ通信するため、
# Docker Composeのサービス名 'langfuse-web' を指定します
os.environ["LANGFUSE_HOST"] = "http://langfuse-web:3000"
# Google Gemini APIキーの設定
# 自身のAPIキーに置き換えてください
os.environ["GOOGLE_API_KEY"] = "YOUR_GOOGLE_API_KEY"
設定が完了したら、Langfuseクライアントを初期化し、認証が成功するか確認します。
from langfuse import get_client
langfuse = get_client()
# 接続を検証
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
Langfuse client is authenticated and ready!と表示されれば、接続成功です。
続いて、Google ADKの動作をLangfuseがトレースできるように設定します。
from openinference.instrumentation.google_adk import GoogleADKInstrumentor
GoogleADKInstrumentor().instrument()
このコードの役割について
Langfuseは、アプリケーションの動作を可視化するための標準規格であるOpenTelemetryを利用しています。しかし、Google ADKは標準ではこの規格に対応していません。
そこでGoogleADKInstrumentor().instrument()を実行することで、ADKの内部動作に動的に割り込み、OpenTelemetry形式のデータをLangfuseに送信する「計装(Instrumentation)」という処理を行っています。
これにより、ADKのコードを直接変更することなく、LLMの呼び出しやツールの使用状況といった詳細な情報をLangfuse上で追跡できるようになります。なお、この計装はサードパーティのライブラリ (openinference) によって提供されるため、ADKのメジャーアップデートへの追随には時間差が生じる可能性がある点には留意が必要です。
3. AIエージェントの作成と実行
セットアップが完了したので、実際にAIエージェントを動かしてみます。今回は、Google検索ツールを使って最新の情報を回答できるエージェントを作成します。
# エージェントの定義
from google.adk.agents import Agent
from google.adk.tools import google_search
agent = Agent(
name="research_agent",
model="gemini-2.0-flash",
instruction="Web検索を用いて最新の情報を確実に提供してください。",
tools=[google_search],
)
# セッション管理サービスの設定
from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()
# Runnerの作成
from google.adk.runners import Runner
APP_NAME = "test"
USER_ID = "demo-user"
SESSION_ID = "demo-session"
await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
runner = Runner(agent=agent, app_name=APP_NAME, session_service=session_service)
tip Google ADKの主要コンポーネント
- Agent: LLMのモデル、指示(instruction)、利用可能なツールなどを定義します。エージェントの核となる部分です。
-
SessionService: ユーザーとの対話履歴を管理します。
InMemorySessionServiceは開発用の簡易的なもので、メモリ上に履歴を保存します。本番環境ではデータベースなど永続的なストレージに保存するサービスを使用します。 - Runner: ユーザーIDやセッションIDに基づいて対話履歴を管理し、エージェントを実行する役割を担います。これにより、マルチターンの対話型アプリケーションを容易に構築できます。
エージェントに質問を投げかけて、応答を確認してみましょう。
from google.genai import types
# ユーザーからのメッセージを作成
user_msg = types.Content(role="user", parts=[types.Part(text="現在の自民党総裁は誰ですか?")])
# エージェントを実行し、応答を待つ
response_generator = runner.run(user_id=USER_ID, session_id=SESSION_ID, new_message=user_msg)
final_response = list(response_generator)[-1]
# 応答内容を表示
print(final_response.content.parts[-1].text)
実行すると、エージェントがWeb検索を行い、最新の情報に基づいた回答を生成します。
現在の自民党総裁は高市早苗氏です。彼女は2025年10月4日に自民党総裁選で勝利し、第29代総裁に選出されました。高市氏は、自民党史上初の女性総裁です。
※上記は2025年10月時点の実行結果の例です。
4. Langfuseでトレース結果を確認
Jupyter Lab上では最終的な回答しか見えませんが、この背後でエージェントがどのように動作したのかをLangfuseで確認してみます。
ブラウザでLangfuseのUI(http://localhost:3000)に戻り、プロジェクトの「Traces」タブを開くと、先ほどのやり取りが記録されています。

Langfuseのトレーシング画面
このトレース詳細画面からは、以下のような情報が読み取れます。
-
ツールの使用:
- エージェントが
google_searchツールを呼び出すことを決定したこと。 - その際、検索クエリとして「who is current president of LDP」というキーワードを生成したこと。
- エージェントが
- ツールからの出力: Google検索から複数のWebサイトの情報(この例では2件)が返されたこと。
- 最終的な生成: 検索結果を元に、Geminiモデルが最終的な回答文章を生成したこと。
このように、Langfuseを使うことで、単なるprintデバッグでは追跡が困難なLLMアプリケーションの内部的な「思考プロセス」を時系列で可視化できます。
まとめ
本記事では、DockerとJupyter Labを用いて、ローカル環境にLangfuseの検証環境を構築する手順を解説しました。
この環境を活用することで、LLMアプリケーション開発の初期段階において、以下のようなメリットを享受できます。
- LLMがどのようなツールを、どのようなパラメータで呼び出しているのかを正確に把握できる。
- 予期せぬ挙動をした際に、どのステップで問題が発生したのかを効率的に特定できる。
- 取得したトレース情報をチームメンバーと共有し、デバッグや改善策の議論を円滑に進められる。
複雑なAIエージェントを開発・運用していく上で、Langfuseのような観測ツールは必須だと思っています。Dockerさえあれば上記手順で簡単に使えるので、ぜひ手元で試してみてください。
Discussion