【Google ADK】検索品質を求めて「Deep Research」を自作してみた話
はじめに
ChatGPTやGeminiに搭載されているDeepResearchなどの「深掘り調査」ができるAIエージェントって便利ですよね。ただ、エンジニアとしては「深掘り回数を変えたり検索対象を限定したりともっと挙動を制御したい」という欲求が出てきます。そこで今回は、Googleの Agent Development Kit (ADK) を使用して、独自のDeep Researchアプリを作成しました。
実装してみた結果得られた、ADKならではのメリットや、エージェント設計の「深さ」に関する知見を共有します。

作成したアプリの画面
作成したアプリのコードは以下にありますので、ぜひお手元でお試しください💡
なぜ今、ADKで自作するのか?
1. Google検索という「最強の武器」が標準装備
Deep Research系のタスクにおいて、命綱となるのは「検索品質」です。どんなに賢いLLMを使っても、拾ってくる情報が微妙であればアウトプットの質は上がりません。
ADKを採用した最大の理由は、Google検索が標準でサポートされていることです。現代において最も信頼性が高く広範なGoogle検索を、エージェントがツールとして自然に使いこなせる点は、他のフレームワークにはないメリットです。
2. 「ブラックボックス」を開けたい
Gemini Advancedなどの既製品を使えばDeep Researchは可能ですが、以下の点が不満でした。
- 「あと何回深掘りするか」を指定できない
- 使用するモデル(ProなのかFlashなのか等)を明示的に選べない
自作すれば、これらのパラメータを完全に制御下に置くことができます。
3. RAGチャットボットのDeepResearch化への応用(本命)
実はこれが一番の動機ですが、この手法が確立できれば、Google検索だけでなく特定のドキュメントのみを参照するRAGチャットボットのDeepResearch化もできると思いました。特定の事柄に関する深い調査は、需要が大きいのではないかと考えています。
こだわった設計思想:「広さ」より「深さ」
今回の実装で最もこだわったのは、「クエリを叩く → 結果を分析する → その結果からさらにクエリを叩く」というシーケンシャルなプロセスです。
別の実装方法として、最初に複数のクエリを生成して並列で叩く(広さ重視)ものがありますが、今回はあえて「深さ」に振りました。人間が本気で調査する時と同じように、一つ判明した事実から次の疑問を見つけ、真相に迫っていく動きを再現したかったからです。
なお、ADKのGoogle Searchツールはデフォルトである程度並列で動くため、「広さ」もある程度カバーできていると考えられます。

検索の広さと深さについて
エージェント構成:対立構造を作る
より深い情報を引き出すため、以下の3つのエージェントを連携させました。
- Research Agent(調査役): 一生懸命情報を探してくる。
- Questioner Agent(質問役): 調査結果に対して「ここが足りない」「もっと詳しく」と執拗に深掘りを要求する。
- Reporter Agent(報告役): 上記2者のやり取りを最終的に綺麗なレポートにまとめる。
あえて「調査役 vs 質問役」という対立構造を作ることで、妥協のないリサーチ結果が得られるようにしています。
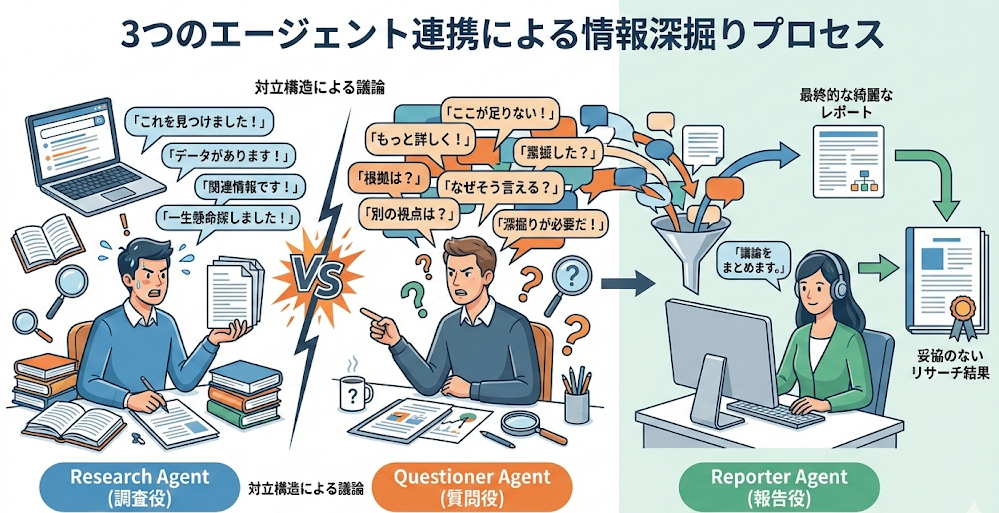
エージェント構成のイメージ
開発で得られた技術的知見 (Tips)
開発中に直面した課題や、ADK特有の挙動についての学びです。
1. Sub Agent vs Agent as a Tool
ADKではエージェントの連携方法として主に2つのパターンがありますが、今回は Sub Agent(Sequential Agent) を採用しました。
- 懸念だった点: Sub Agentを使うと、ユーザーに見えるエージェント自体が切り替わってしまう(UXが悪くなる)のでは?と思っていましたが、今回の用途では毎回エージェント自体を定義しなおすため、そこは問題になりませんでした。
- Agent as a Toolの課題: エージェントをツール化して呼び出す方法は、ADK Web上でツールの内部が見えないためデバックが難しいという課題がありました。一方Sub Agentは、各エージェントの挙動を追いやすかったです。
2. Streamlit連携とデプロイのトレードオフ
今回はUIにStreamlitを採用し、画面上から「使用モデル」や「深掘りの回数」を指定できるようにしました。
- 実装の工夫: ADKの標準的な使い方では動的な設定変更が難しいため、クラス化してリクエストの都度エージェントインスタンスを生成する仕様にしました。
- 副作用: この仕様変更により、ADKの Agent Engine へのデプロイはできなくなりました(仕様上の制約)。ただ、「使用モデル」や「深掘りの回数」などのパラメータ調整がエージェント外部からできること自体は、それなりに需要がある機能な気がするので、今後ADK側で柔軟に対応できるようになることを期待しています。
3. 参照元(Citations)の明示は必須
Deep Researchの要件として、「情報のソース」は最重要項目です。
今回は参照元リンクを全て表示するように実装しました。ハルシネーションのチェックはもちろんですが、「実際に商品を購入する」「一次情報を確認する」といったアクションに繋げるため、リンク先への導線は必須条件です。
以下のように、「eventにgrounding_metadataが存在するときに取り出す」のような感じで実装可能です。「event」というのは、ADKのrunnerを実行すると返ってくる戻り値です。エージェントの各ステップごとに1eventあり、検索ステップの時はeventの中にgrounding_metadataが存在していて取り出すことができるといった具合です。
4. 頻繁に起こるmodelのrate_limit等のエラー回避
今回Geminiの無料版のAPIを使っているのもあり、ちょっと使いすぎるとすぐにrate_limitエラーが起きてしまいます。そのため、そういったエラーが起きた際にリトライする機構がないと、DeepResearchをやり切るのは不可能に近いです。そのため、今回は、以下のコードのようなリトライ設定を組み込みました。
こちらの実装は以下の記事を参考にしました。
まとめ
Google ADKを使ってDeep Researchを自作することで、Google検索の強みを活かしつつ、独自の「深掘りロジック」を実装することができました。
今回はWeb検索が対象でしたが、この「調査役と質問役を戦わせて、深さを追求するアーキテクチャ」は、あらゆるドキュメント検索RAGチャットボットにもそのまま応用できるはずです。
コードはGitHubで公開していますので、ADKでのエージェント開発やDeep Researchに興味がある方はぜひ触ってみてください。
Discussion