2023弊研コンペ解法
はじめに
今年度、弊研究室では機械学習コンペが開催されました。
かくいう私も参加しそれなりのスコアを出せたので、後輩たちの後学のためにも自分の解法を解説したいと思います。
本記事は 法政大学理工学部 Advent Calendar 2023 6日目の記事です。
解法
スコアを上げるに当たっていくつかやったことがあるので、一つ一つ解説していきます。
前処理
画像認識タスクでまずはじめにやるべきは、生画像を見ることです。
本コンペで使用するデータセットの中身を確認すると、やばいデータが大量にあることが確認できます。

やばい例
こういったあからさまなノイズは学習・識別の邪魔になることが予想されます。
そこで、今回は事前に車の領域でクロップしてしまうことにしました。
しかし、大量の学習・テストデータ全てを手作業でクロッピングしていくのは無理です。
物体検出
そこで物体検出を使います。
物体検出とは画像の中から定められた物体の位置やクラスを検出することを言います。
この物体検出技術を用いて、車の領域を検出し、その領域を自動でクロップしたいと思います。
今日には様々な物体検出の事前学習モデルが公開されています。
今回はYOLOv8を使います。
YOLOは公式以外に開発元がいろいろあって各々がバージョンを勝手に付けてるので、どれがどの系列かよくわからないことになってます。
とりあえず最新っぽいのでv8を使いました。
クロップの方法ですが、単に検出した領域すべてでクロップしてしまうと、ほぼ同じような領域や車に関係のない領域までクロップされてしまいます。
なので、検出した領域の中で一番大きい部分のみクロップするようにしました。
また、一つも検出されなかった場合はその画像のまま用いることにしました。
自動クロップの結果が下です。

クロップ結果
事前学習のモデルでここまで高精度に検出できました。
使用したコードは下に載せておきます。
検出クロップコード
import glob
import os
import os.path as osp
import cv2
from ultralytics import YOLO
# image paths
path = "/kaggle/input/2023-iyatomilab-competition/train/train/4runner"
if not osp.exists(f"./dataset/detect/{path}"):
os.makedirs(f"./dataset/detect/{path}")
files = glob.glob(f"./{path}/*.jpg")
# model
model = YOLO("yolov8l.pt")
for f in files:
# detect
results = model(f)
img = cv2.imread(f)
# Find the largest bounding box
max_area = 0
max_box = None
for i, box in enumerate(results[0].boxes.xyxy.tolist()):
x1, y1, x2, y2 = box
area = (x2 - x1) * (y2 - y1)
if area > max_area:
max_area = area
max_box = box
if max_box is not None:
x1, y1, x2, y2 = max_box
crop_obj = img[int(y1) : int(y2), int(x1) : int(x2)]
file_name = osp.splitext(osp.basename(f))[0]
cv2.imwrite(f"./dataset/detect/{path}/{file_name}.jpg", crop_obj)
else:
file_name = osp.splitext(osp.basename(f))[0]
cv2.imwrite(f"./dataset/detect/{path}/{file_name}.jpg", img)
モデル
続いて使用した識別モデルについてです。
ここからはコードベースで解説していきます。
識別モデルコード
import torch.nn as nn
from torchvision.models import EfficientNet_V2_S_Weights, efficientnet_v2_s
class EfficientNetS(nn.Module):
def __init__(self, num_class, final_in_features=1280):
super().__init__()
self.encoder = nn.Sequential(
efficientnet_v2_s(weights=EfficientNet_V2_S_Weights.IMAGENET1K_V1).features,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(1),
)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(final_in_features, num_class),
)
def forward(self, x):
x = self.encoder(x)
x = self.classifier(x)
return x
識別モデルにはEfficientNetV2-SのIMAGENET_1K事前学習モデルを使用しました。
EfficientNetV2は我々Plant班でほぼデファクトスタンダードとなっているつよつよCNNです。
Transform
transformコード
from torchvision.transforms import v2
class TrainTransForms:
def __init__(self, input_size=384) -> None:
self.transforms = v2.Compose(
[
v2.RandAugment(5, 15),
v2.AugMix(3, 3),
v2.Resize((input_size, input_size)),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
def __call__(self, image):
return self.transforms(image)
class ValidTransForms:
def __init__(self, input_size=384) -> None:
self.transforms = v2.Compose(
[
v2.Resize((input_size, input_size)),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
def __call__(self, image):
return self.transforms(image)
データ拡張にはRandAugmentとAugMixを使用しました。
RandAugment
RandAugmentは複数種のデータ拡張操作のなかからランダムに

RandAugment例
シンプルながら強力です。
ハイパーパラメータ
今回は
AugMix
AugMixは複数種のデータ拡張操作のなかからランダムに
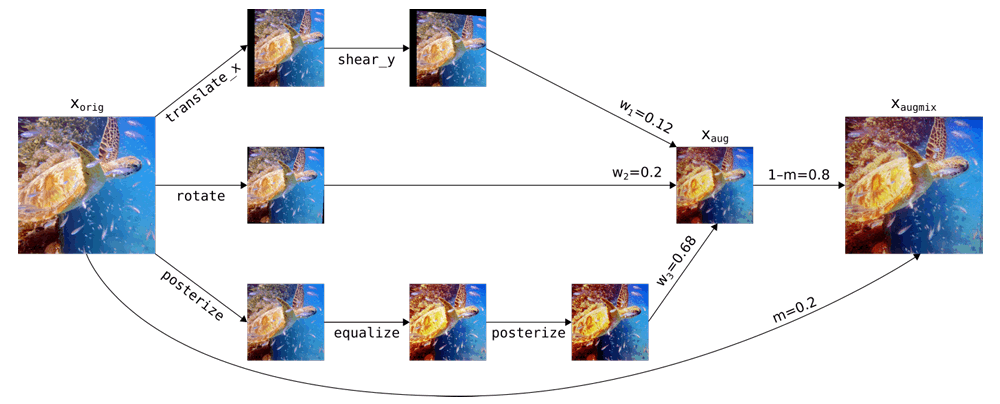
AugMix例
これまた強いです。
ハイパーパラメータはデフォルトの
データ拡張例
これらのデータ拡張をかけると次のような画像になりました。

データ拡張例
整形
データの整形は入力サイズ
入力サイズに合わせるときにRandomCropやRandomResizedCropなどで行うこともありますが、今回の場合は識別対象(車)とする領域のみが入力されているので、入力全体が入るようにResizeでやったほうがよさそうでした。
また、ある程度入力サイズは確保したほうがよさそうだったため
学習
学習コード
import os
import os.path as osp
import warnings
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.io import read_image
from tqdm import tqdm
class TrainDataset:
def __init__(self, root, transform) -> None:
self.classes = os.listdir(root)
self.classes.sort()
self.items = []
for i, c in enumerate(self.classes):
for f in os.listdir(osp.join(root, c)):
self.items.append((osp.join(root, c, f), i))
self.transform = transform
def __len__(self):
return len(self.items)
def __getitem__(self, idx):
img_path, label = self.items[idx]
img = read_image(img_path) / 255.0
img = self.transform(img)
return img, label
DATA_DIR = "/kaggle/input/2023-iyatomi-kaggle-crop/detect/train/"
INPUT_SIZE = 384
BATCH_SIZE = 96
LR = 1e-3
NUM_EPOCHS = 100
warnings.filterwarnings("ignore")
torch.backends.cudnn.benchmark = True
device = torch.device("cuda")
# dataset
train_dataset = TrainDataset(root=DATA_DIR, transform=TrainTransForms(input_size=INPUT_SIZE))
train_dataloader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=os.cpu_count(),
pin_memory=True,
)
# model
model = EfficientNetS(num_class=12)
model = nn.DataParallel(model)
model.to(device)
# weights
num_images = []
for cls in os.listdir(DATA_DIR):
num_images.append(len(os.listdir(osp.join(DATA_DIR, cls))))
weights = 1.0 / torch.tensor(num_images).to(device)
print(weights)
# learning settings
criterion = nn.CrossEntropyLoss(weights)
optimizer = torch.optim.RAdam(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=NUM_EPOCHS)
scaler = torch.cuda.amp.GradScaler(2**12)
# training
model.train()
print("Start training...")
for epoch in range(NUM_EPOCHS):
epoch_loss = 0.0
for images, labels in tqdm(train_dataloader):
images, labels = images.to(device, non_blocking=True), labels.to(device, non_blocking=True)
# forward
with torch.autocast(device_type=device.type):
outputs = model(images)
loss = criterion(outputs, labels)
# backward
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
optimizer.zero_grad(set_to_none=True)
epoch_loss += loss.item()
epoch_loss /= len(train_dataloader)
print(f"Epoch: {epoch+1}/{NUM_EPOCHS} Loss: {epoch_loss:.4f}")
print("Finish training!")
torch.save(model.module.state_dict(), "./model.pth")
長ったらしいのでピックアップしながら解説します。
ハイパーパラメータ
INPUT_SIZE = 384
BATCH_SIZE = 96
LR = 1e-3
NUM_EPOCHS = 100
ここら辺は感覚です。経験則的にこのくらいがいいだろうで決めてます。
バッチサイズをできるだけ大きくするために工夫した点が2つあるので、それについては後の項目
で解説します。
並列化
# model
model = EfficientNetS(num_class=12)
model = nn.DataParallel(model)
model.to(device)
Kaggle NotebookではNVIDIA Tesla T4(16GB) ×2を使用できます。
2つ使わない手はないのでDataParallelで並列化しましょう。
単純に使えるGPUメモリが増えるのでバッチサイズを大きくできます。
学習設定
# weights
num_images = []
for cls in os.listdir(DATA_DIR):
num_images.append(len(os.listdir(osp.join(DATA_DIR, cls))))
weights = 1.0 / torch.tensor(num_images).to(device)
print(weights)
# learning settings
criterion = nn.CrossEntropyLoss(weights)
optimizer = torch.optim.RAdam(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=NUM_EPOCHS)
scaler = torch.cuda.amp.GradScaler(2**12)
Lossにはデータ数の逆比に基づくWeighted Cross Entropyを使用しました。
学習データに不均衡性がみられる場合に効果的です。
OptimizerにはRAdamを使用しました。
一般的に使われている最適化手法のAdamをベースとしつつ、これよりも汎化性能が高いらしいです。
SchedulerにはCosineAnnealingLRを使用しました。
コサインカーブに基づいて学習率をエポックごとに変化させます。
Scalerは次に解説する Automatic Mixed Precision(AMP) で使用します。
Automatic Mixed Precision(AMP)
# forward
with torch.autocast(device_type=device.type):
outputs = model(images)
loss = criterion(outputs, labels)
# backward
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
optimizer.zero_grad(set_to_none=True)
Automatic Mixed Precision(AMP) とは通常float32で行われるPytorchの計算の一部をfloat16で行うシステムです。
性能を下げずに、省メモリ化、計算の高速化が可能です。
省メモリ化によりバッチサイズを大きくできます。
前述のScalerは勾配に倍率をかけるもので、半精度にしたために起こる勾配のアンダーフローを防ぐことができます。
テスト
submissionのためのコードも載せておきます。
テストコード
import os
import os.path as osp
import warnings
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.io import read_image
from tqdm import tqdm
class TestDataset:
def __init__(self, root, transform) -> None:
self.items = []
for f in os.listdir(root):
self.items.append(osp.join(root, f))
self.transform = transform
def __len__(self):
return len(self.items)
def __getitem__(self, idx):
img_path = self.items[idx]
img = read_image(img_path) / 255.0
img = self.transform(img)
return img, osp.basename(img_path)
TEST_DIR = "/kaggle/input/2023-iyatomi-kaggle-crop/detect/test/"
INPUT_SIZE = 384
TEST_BATCH = 256
warnings.filterwarnings("ignore")
torch.backends.cudnn.benchmark = True
device = torch.device("cuda")
# dataset
test_dataset = TestDataset(root=TEST_DIR, transform=ValidTransForms(input_size=INPUT_SIZE))
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size=TEST_BATCH,
shuffle=False,
num_workers=os.cpu_count(),
pin_memory=True,
)
# model
model = EfficientNetS(num_class=12)
model.load_state_dict(torch.load("./model.pth"))
model = nn.DataParallel(model)
model.to(device)
# csv
csv = open("./submission.csv", "w")
csv.write("image,number\n")
# testing
model.eval()
print("Start testing...")
with torch.inference_mode():
for images, files in tqdm(test_dataloader):
images = images.to(device, non_blocking=True)
outputs = model(images)
_, preds = torch.max(outputs.data, 1)
for file, pred in zip(files, preds):
csv.write(f"{file},{pred}\n")
print("Finish testing!")
おわりに
以上が私の解法になります。
基本的に特別なことはしていなくて、SoTAとなっているような技術を組み合わせただけです。
新しい技術を取り入れていくことは研究においてとても重要なので、そういったことを意識しながら研究していくといいモノができるんじゃないかと思います。

本記事を見てくださった方、および当コンペを開催してくださった弊研究室の皆様に深く御礼申し上げます。
Discussion