TVM,VTAにおける2次元畳み込み演算の最適化


2次元畳み込み演算の最適化
Original Author: Thierry Moreau <https://homes.cs.washington.edu/~moreau/>_
Original Document https://tvm.apache.org/docs/topic/vta/tutorials/optimize/convolution_opt.html#sphx-glr-topic-vta-tutorials-optimize-convolution-opt-py
TVM,VTAシミュレーター インストール後
チュートリアルに従って計算、メモリ効率の最適化のためのレーテンシーを隠蔽する仕組み(virtual threading等)を使って2次元畳み込み演算子を実行する
データの並びはNCHW(Batch Channel Height Width)
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
from __future__ import absolute_import, print_function
import os
import tvm
import tvm.testing
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
from IPython.display import Image
RPC Setup(GEMMと同じ)
# Load VTA parameters from the 3rdparty/vta-hw/config/vta_config.json file
env = vta.get_env()
# We read the Pynq RPC host IP address and port number from the OS environment
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# We configure both the bitstream and the runtime system on the Pynq
# to match the VTA configuration specified by the vta_config.json file.
if env.TARGET == "pynq":
# Make sure that TVM was compiled with RPC=1
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# Reconfigure the JIT runtime
vta.reconfig_runtime(remote)
# Program the FPGA with a pre-compiled VTA bitstream.
# You can program the FPGA with your own custom bitstream
# by passing the path to the bitstream file instead of None.
vta.program_fpga(remote, bitstream=None)
# In simulation mode, host the RPC server locally.
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
計算グラフの定義
2D畳み込みの計算グラフをNCHW形式で記述する
バッチサイズ、空間次元、入力チャネル数、出力チャネル数、カーネルサイズ(2次元分)で
さらにpadding,strideの幅も設定する。
ここではResNet-18の9番目の畳み込み層を例にとる
固定小数点でのRelu(rectified linear activation.)を計算するためのシフト、クリップ演算も付け加える。

計算を複数のチャンクに分けて順次バッファ読み出し、計算を実行、書き出すことで大きなサイズのデータの畳み込みを行う。
TOPIライブラリというのを入力に対してspatial paddingをするために使う。
Spatial paddingとは2D CNNの文脈では
カーネルサイズが1以上の場合同じ座標x,yの入力値を複数回
CPUやGPUのメモリ読み出し効率を上げるためには データを並べ直す必要がある
(c.f. https://qiita.com/kuroitu/items/35d7b5a4bde470f69570
VTAのDMAはpaddingを自動で(on the fly)入れることで並べ直しを不要とする。

入出力データサイズ、カーネルサイズの設定
from tvm import topi
# 2D convolution layer dimensions taken from ResNet-18 architecture
# (9th convolutional layer)
batch_size = 1
height = 14
width = 14
in_channels = 256
out_channels = 256
kernel_h = 3
kernel_w = 3
pad_h = 1
pad_w = 1
stride_h = 1
stride_w = 1
assert batch_size % env.BATCH == 0
assert in_channels % env.BLOCK_IN == 0
assert out_channels % env.BLOCK_OUT == 0
# Input feature map: (N, IC, H, W, n, ic)
data_shape = (
batch_size // env.BATCH,
in_channels // env.BLOCK_IN,
height,
width,
env.BATCH,
env.BLOCK_IN,
)
# Kernel: (OC, IC, H, W, oc, ic)
kernel_shape = (
out_channels // env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
kernel_h,
kernel_w,
env.BLOCK_OUT,
env.BLOCK_IN,
)
# Derive output feature map dimensions
fout_height = (height + 2 * pad_h - kernel_h) // stride_h + 1
fout_width = (width + 2 * pad_w - kernel_w) // stride_w + 1
# Output feature map: (N, OC, H, W, n, oc)
output_shape = (
batch_size // env.BATCH,
out_channels // env.BLOCK_OUT,
fout_height,
fout_width,
env.BATCH,
env.BLOCK_OUT,
)
計算グラフの定義
# Convolution reduction axes
dy = te.reduce_axis((0, kernel_h), name="dy")
dx = te.reduce_axis((0, kernel_w), name="dx")
ic = te.reduce_axis((0, in_channels // env.BLOCK_IN), name="ic")
ic_tns = te.reduce_axis((0, env.BLOCK_IN), name="ic_tns")
軸の定義 reductionの順序などを決めるときに使う。
# Input placeholder tensors
data = te.placeholder(data_shape, name="data", dtype=env.inp_dtype)
kernel = te.placeholder(kernel_shape, name="kernel", dtype=env.wgt_dtype)
# Copy buffers:
# Apply spatial padding to input feature map
data_buf = topi.nn.pad(data, [0, 0, pad_h, pad_w, 0, 0], name="data_buf")
kernel_buf = te.compute(kernel_shape, lambda *i: kernel(*i), "kernel_buf")
入力、カーネル重みはプレースホルダーとして定義、バッファにはtopi.nn.padでSpatial paddingを適用する。
# Declare 2D convolution
res_conv = te.compute(
output_shape,
lambda bo, co, i, j, bi, ci: te.sum(
data_buf[bo, ic, i * stride_h + dy, j * stride_w + dx, bi, ic_tns].astype(env.acc_dtype)
* kernel_buf[co, ic, dy, dx, ci, ic_tns].astype(env.acc_dtype),
axis=[ic, dy, dx, ic_tns],
),
name="res_conv",
)
# Add shift stage for fix-point normalization
res_shr = te.compute(output_shape, lambda *i: res_conv(*i) >> 8, name="res_shr")
# Apply clipping between (0, input max value)
inp_max = (1 << (env.INP_WIDTH - 1)) - 1
res_max = te.compute(output_shape, lambda *i: tvm.te.max(res_shr(*i), 0), "res_max")
res_min = te.compute(output_shape, lambda *i: tvm.te.min(res_max(*i), inp_max), "res_min")
# Result Tensor
res = te.compute(output_shape, lambda *i: res_min(*i).astype(env.inp_dtype), name="res")
畳み込み計算の定義te.sumだけでよい。GEMMのときと同様に正規化、クリッピング処理も入れる。出力はres
環境変数を見てみる
vars(env)
{'pkg': <PkgConfig at 0x7f416932ef70>,
'TARGET': 'sim',
'HW_VER': '0.0.2',
'LOG_INP_WIDTH': 3,
'LOG_WGT_WIDTH': 3,
'LOG_ACC_WIDTH': 5,
'LOG_BATCH': 0,
'LOG_BLOCK': 4,
'LOG_UOP_BUFF_SIZE': 15,
'LOG_INP_BUFF_SIZE': 15,
'LOG_WGT_BUFF_SIZE': 18,
'LOG_ACC_BUFF_SIZE': 17,
'LOG_BLOCK_IN': 4,
'LOG_BLOCK_OUT': 4,
'LOG_OUT_WIDTH': 3,
'LOG_OUT_BUFF_SIZE': 15,
'INP_WIDTH': 8,
'WGT_WIDTH': 8,
'ACC_WIDTH': 32,
'OUT_WIDTH': 8,
'BATCH': 1,
'BLOCK_IN': 16,
'BLOCK_OUT': 16,
'UOP_BUFF_SIZE': 32768,
'INP_BUFF_SIZE': 32768,
'WGT_BUFF_SIZE': 262144,
'ACC_BUFF_SIZE': 131072,
'OUT_BUFF_SIZE': 32768,
'INP_ELEM_BITS': 128,
'WGT_ELEM_BITS': 2048,
'ACC_ELEM_BITS': 512,
'OUT_ELEM_BITS': 128,
'INP_ELEM_BYTES': 16,
'WGT_ELEM_BYTES': 256,
'ACC_ELEM_BYTES': 64,
'OUT_ELEM_BYTES': 16,
'acc_dtype': 'int32',
'inp_dtype': 'int8',
'wgt_dtype': 'int8',
'out_dtype': 'int8',
'BITSTREAM': '1x16_i8w8a32_15_15_18_17',
'MODEL': 'sim_1x16_i8w8a32_15_15_18_17',
'mock_mode': False,
'_mock_env': None,
'_dev_ctx': None,
'_last_env': None}
Scheduling the Computation
計算効率化のために以下の処理を行うようにスケージュールを変換する。
- 計算のblocking
- 計算効率化のためのVirtual threading
- ハードウェアイントリンジックへのLowering
# Create TVM schedule
s = te.create_schedule(res.op)
# Let's look at the default TVM schedule
print(tvm.lower(s, [data, kernel, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 16, 14, 14, 1, 16), "int8"), kernel: T.Buffer((16, 16, 3, 3, 16, 16), "int8"), res: T.Buffer((1, 16, 14, 14, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_buf = T.allocate([65536], "int8", "global")
kernel_buf = T.allocate([589824], "int8", "global")
res_conv = T.allocate([50176], "int32", "global")
data_buf_1 = T.Buffer((65536,), "int8", data=data_buf)
for i1, i2, i3, i5 in T.grid(16, 16, 16, 16):
cse_var_1: T.int32 = i3 * 16
data_1 = T.Buffer((50176,), "int8", data=data.data)
data_buf_1[i1 * 4096 + i2 * 256 + cse_var_1 + i5] = T.if_then_else(1 <= i2 and i2 < 15 and 1 <= i3 and i3 < 15, data_1[i1 * 3136 + i2 * 224 + cse_var_1 + i5 - 240], T.int8(0))
kernel_buf_1 = T.Buffer((589824,), "int8", data=kernel_buf)
for i0, i1, i2, i3, i4, i5 in T.grid(16, 16, 3, 3, 16, 16):
cse_var_2: T.int32 = i0 * 36864 + i1 * 2304 + i2 * 768 + i3 * 256 + i4 * 16 + i5
kernel_1 = T.Buffer((589824,), "int8", data=kernel.data)
kernel_buf_1[cse_var_2] = kernel_1[cse_var_2]
res_conv_1 = T.Buffer((50176,), "int32", data=res_conv)
for co, i, j, ci in T.grid(16, 14, 14, 16):
res_conv_1[co * 3136 + i * 224 + j * 16 + ci] = 0
for ic, dy, dx, ic_tns in T.grid(16, 3, 3, 16):
cse_var_4: T.int32 = j * 16
cse_var_3: T.int32 = co * 3136 + i * 224 + cse_var_4 + ci
res_conv_1[cse_var_3] = res_conv_1[cse_var_3] + T.Cast("int32", data_buf_1[ic * 4096 + i * 256 + dy * 256 + cse_var_4 + dx * 16 + ic_tns]) * T.Cast("int32", kernel_buf_1[co * 36864 + ic * 2304 + dy * 768 + dx * 256 + ci * 16 + ic_tns])
res_conv_2 = T.Buffer((50176,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(16, 14, 14, 16):
cse_var_5: T.int32 = i1 * 3136 + i2 * 224 + i3 * 16 + i5
res_conv_2[cse_var_5] = T.shift_right(res_conv_1[cse_var_5], 8)
res_conv_3 = T.Buffer((50176,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(16, 14, 14, 16):
cse_var_6: T.int32 = i1 * 3136 + i2 * 224 + i3 * 16 + i5
res_conv_3[cse_var_6] = T.max(res_conv_2[cse_var_6], 0)
res_conv_4 = T.Buffer((50176,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(16, 14, 14, 16):
cse_var_7: T.int32 = i1 * 3136 + i2 * 224 + i3 * 16 + i5
res_conv_4[cse_var_7] = T.min(res_conv_3[cse_var_7], 127)
for i1, i2, i3, i5 in T.grid(16, 14, 14, 16):
cse_var_8: T.int32 = i1 * 3136 + i2 * 224 + i3 * 16 + i5
res_1 = T.Buffer((50176,), "int8", data=res.data)
res_1[cse_var_8] = T.Cast("int8", res_conv_4[cse_var_8])
計算のBlocking
入力チャネル、出力チャネルをブロックに分割して VTAの制約のあるハードウェアで処理する。
HCHWの最内側の画像Widthに対してはブロッキングは適用しない。
# Let's define tiling sizes
b_block = 1 // env.BATCH
oc_block = 128 // env.BLOCK_OUT
ic_block = 16 // env.BLOCK_IN
h_block = 7
w_block = 14
# Tile the output tensor along the spatial and output channel dimensions
# (since by default we are doing single batch inference, the split along
# the batch dimension has no effect)
b, oc, y, x, b_tns, oc_tns = s[res].op.axis
b_out, b_inn = s[res].split(b, factor=b_block)
oc_out, oc_inn = s[res].split(oc, factor=oc_block)
y_out, y_inn = s[res].split(y, factor=h_block)
x_out, x_inn = s[res].split(x, factor=w_block)
s[res].reorder(b_out, oc_out, y_out, x_out, b_inn, oc_inn, y_inn, x_inn, b_tns, oc_tns)
# Move intermediate computation into each output compute tile
s[res_conv].compute_at(s[res], x_out)
s[res_shr].compute_at(s[res], x_out)
s[res_max].compute_at(s[res], x_out)
s[res_min].compute_at(s[res], x_out)
# Apply additional loop split along reduction axis (input channel)
b_inn, oc_inn, y_inn, x_inn, b_tns, oc_tns = s[res_conv].op.axis
ic_out, ic_inn = s[res_conv].split(ic, factor=ic_block)
軸のReorder(並べ替え)
- tensorizeするために内側からb_tns, oc_tns, ic_tnsに並べ替える
- ic_outのループは外にある
- b_inn, oc_inn, y_inn, x_inn, ic_innの順番になる
VTAランタイム、ハードウェアではテンソルの計算ごとに異なる領域にデータを出力しなければならないらしい(?意訳)
そのため、出力のindexに影響するため、oc_inn, y_inn , x_innのいずれかをb_tnsの前に持ってこないけならしい。
ここではx_innを内側に持っていく。
s[res_conv].reorder(ic_out, b_inn, oc_inn, y_inn, ic_inn, dy, dx, x_inn, b_tns, oc_tns, ic_tns)
Virtual Threading
タスクレベルパイプライン並列性(ヘネパタなどを参照)を実現してくれる仕組みらしい
メモリアクセスの期間を計算期間と重ねて隠蔽してくれる
ここでは出力を2スレッドに分割する(下図参照)
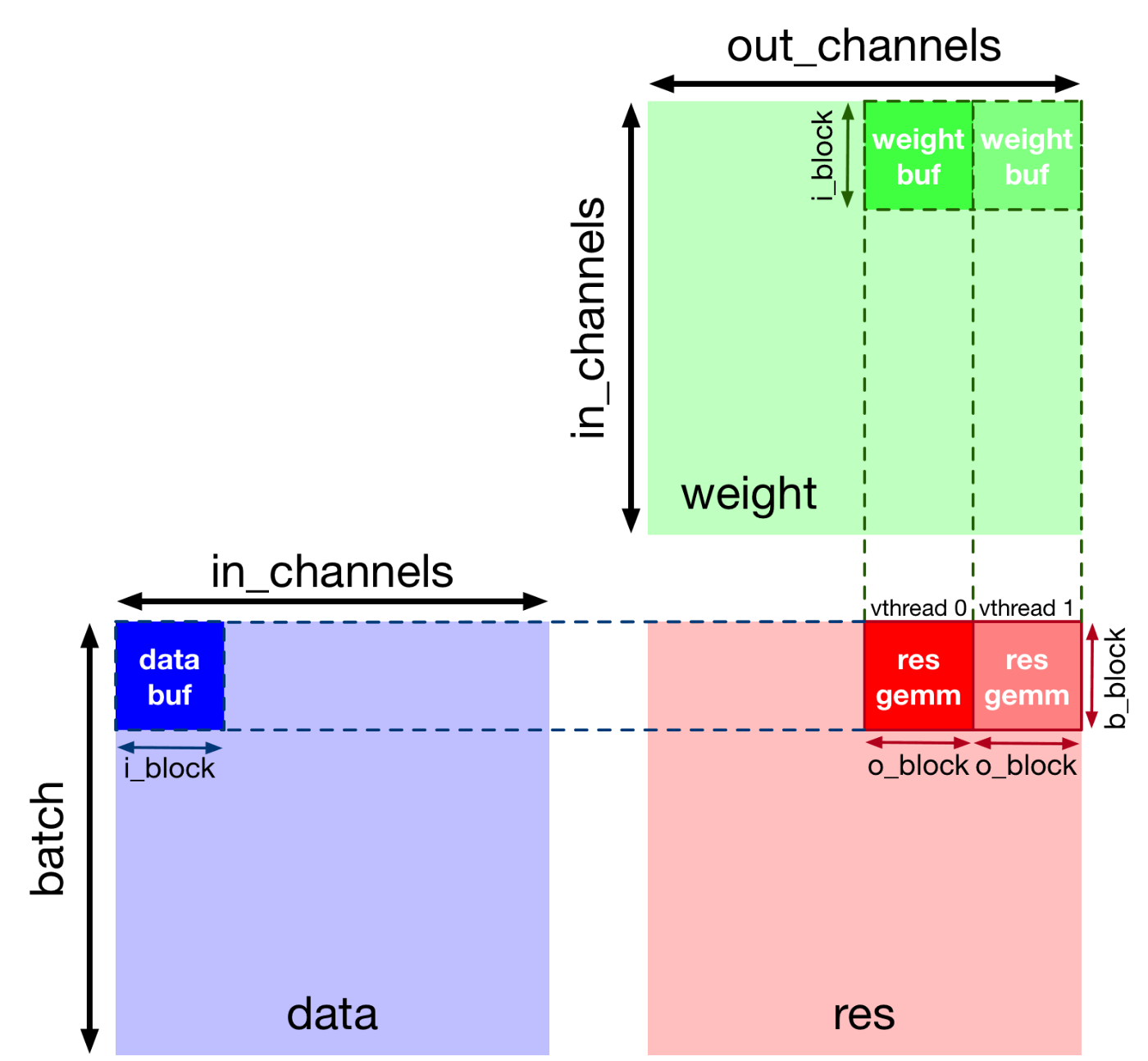
# VTA only supports 2 virtual threads (!) バックバッファということ?
v_threads = 2
# 出力軸oc_outに沿ってvirtual thread
_, tx = s[res].split(oc_out, factor=v_threads)
s[res].reorder(tx, b_out)
s[res].bind(tx, te.thread_axis("cthread"))
#lowerして表示
print(tvm.lower(s, [data, kernel, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 16, 14, 14, 1, 16), "int8"), kernel: T.Buffer((16, 16, 3, 3, 16, 16), "int8"), res: T.Buffer((1, 16, 14, 14, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_buf = T.allocate([65536], "int8", "global")
kernel_buf = T.allocate([589824], "int8", "global")
res_conv = T.allocate([25088], "int32", "global")
data_buf_1 = T.Buffer((65536,), "int8", data=data_buf)
for i1, i2, i3, i5 in T.grid(16, 16, 16, 16):
cse_var_1: T.int32 = i3 * 16
data_1 = T.Buffer((50176,), "int8", data=data.data)
data_buf_1[i1 * 4096 + i2 * 256 + cse_var_1 + i5] = T.if_then_else(1 <= i2 and i2 < 15 and 1 <= i3 and i3 < 15, data_1[i1 * 3136 + i2 * 224 + cse_var_1 + i5 - 240], T.int8(0))
kernel_buf_1 = T.Buffer((589824,), "int8", data=kernel_buf)
for i0, i1, i2, i3, i4, i5 in T.grid(16, 16, 3, 3, 16, 16):
cse_var_2: T.int32 = i0 * 36864 + i1 * 2304 + i2 * 768 + i3 * 256 + i4 * 16 + i5
kernel_1 = T.Buffer((589824,), "int8", data=kernel.data)
kernel_buf_1[cse_var_2] = kernel_1[cse_var_2]
for i2_outer in range(2):
res_conv_1 = T.Buffer((157351936,), "int32", data=res_conv)
for co_init, i_init, j_init, ci_init in T.grid(8, 7, 14, 16):
cse_var_3: T.int32 = co_init * 1568 + i_init * 224 + j_init * 16 + ci_init
res_conv_1[cse_var_3] = 0
res_conv_1[cse_var_3 + 12544] = 0
for ic_outer, co, i, dy, dx, j, ci, ic_tns in T.grid(16, 8, 7, 3, 3, 14, 16, 16):
cse_var_8: T.int32 = j * 16
cse_var_7: T.int32 = co * 1568 + i * 224 + cse_var_8 + ci
cse_var_6: T.int32 = cse_var_7 + 12544
cse_var_5: T.int32 = co * 36864 + ic_outer * 2304 + dy * 768 + dx * 256 + ci * 16 + ic_tns
cse_var_4: T.int32 = ic_outer * 4096 + i2_outer * 1792 + i * 256 + dy * 256 + cse_var_8 + dx * 16 + ic_tns
res_conv_1[cse_var_7] = res_conv_1[cse_var_7] + T.Cast("int32", data_buf_1[cse_var_4]) * T.Cast("int32", kernel_buf_1[cse_var_5])
res_conv_1[cse_var_6] = res_conv_1[cse_var_6] + T.Cast("int32", data_buf_1[cse_var_4]) * T.Cast("int32", kernel_buf_1[cse_var_5 + 294912])
res_conv_2 = T.Buffer((157351936,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(8, 7, 14, 16):
cse_var_10: T.int32 = i1 * 1568 + i2 * 224 + i3 * 16 + i5
cse_var_9: T.int32 = cse_var_10 + 12544
res_conv_2[cse_var_10] = T.shift_right(res_conv_1[cse_var_10], 8)
res_conv_2[cse_var_9] = T.shift_right(res_conv_1[cse_var_9], 8)
res_conv_3 = T.Buffer((157351936,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(8, 7, 14, 16):
cse_var_12: T.int32 = i1 * 1568 + i2 * 224 + i3 * 16 + i5
cse_var_11: T.int32 = cse_var_12 + 12544
res_conv_3[cse_var_12] = T.max(res_conv_2[cse_var_12], 0)
res_conv_3[cse_var_11] = T.max(res_conv_2[cse_var_11], 0)
res_conv_4 = T.Buffer((157351936,), "int32", data=res_conv)
for i1, i2, i3, i5 in T.grid(8, 7, 14, 16):
cse_var_14: T.int32 = i1 * 1568 + i2 * 224 + i3 * 16 + i5
cse_var_13: T.int32 = cse_var_14 + 12544
res_conv_4[cse_var_14] = T.min(res_conv_3[cse_var_14], 127)
res_conv_4[cse_var_13] = T.min(res_conv_3[cse_var_13], 127)
for i1_inner, i2_inner, i3_inner, i5 in T.grid(8, 7, 14, 16):
cse_var_18: T.int32 = i2_inner * 224
cse_var_17: T.int32 = i3_inner * 16
cse_var_16: T.int32 = i1_inner * 1568 + cse_var_18 + cse_var_17 + i5
cse_var_15: T.int32 = i1_inner * 3136 + i2_outer * 1568 + cse_var_18 + cse_var_17 + i5
res_1 = T.Buffer((50176,), "int8", data=res.data)
res_1[cse_var_15] = T.Cast("int8", res_conv_4[cse_var_16])
res_1[cse_var_15 + 25088] = T.Cast("int8", res_conv_4[cse_var_16 + 12544])
DMA転送設定
GEMMの場合と同じでset_scope(env.inp_scope)でSRAM割当、compute_atで入力dataとkernel cacheの設定 pragma(*,env.dma_copy)でDMAを使用する設定を行う。
# Set scope of SRAM buffers
s[data_buf].set_scope(env.inp_scope)
s[kernel_buf].set_scope(env.wgt_scope)
s[res_conv].set_scope(env.acc_scope)
s[res_shr].set_scope(env.acc_scope)
s[res_min].set_scope(env.acc_scope)
s[res_max].set_scope(env.acc_scope)
# Block data and kernel cache reads
s[data_buf].compute_at(s[res_conv], ic_out)
s[kernel_buf].compute_at(s[res_conv], ic_out)
# Use DMA copy pragma on DRAM->SRAM operations
s[data_buf].pragma(s[data_buf].op.axis[0], env.dma_copy)
s[kernel_buf].pragma(s[kernel_buf].op.axis[0], env.dma_copy)
# Use DMA copy pragma on SRAM->DRAM operation in each result block
# (this implies that these copies should be performed along b_inn, or result axis 4)
s[res].pragma(s[res].op.axis[4], env.dma_copy)
b_inn(result axis 4)の軸に沿ってSRAM->DRAMの出力DMAを行う。
VTAのIntrinsics設定
2D CNNとシフト、クリッピング処理をVTAのハードウェアに割り当てる。env.gemm, env.aluでそれぞれGEMMユニットとALUに割り当てられる。
# Apply tensorization over the batch tensor tile axis
s[res_conv].tensorize(b_tns, env.gemm)
# Add an ALU pragma over the shift and clipping operations
s[res_shr].pragma(s[res_shr].op.axis[0], env.alu)
s[res_min].pragma(s[res_min].op.axis[0], env.alu)
s[res_max].pragma(s[res_max].op.axis[0], env.alu)
DMAのloads/stores 設定とVTA intrinsics割当ができたあとの様子
print(vta.lower(s, [data, kernel, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 16, 14, 14, 1, 16), "int8"), kernel: T.Buffer((16, 16, 3, 3, 16, 16), "int8"), res: T.Buffer((1, 16, 14, 14, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
T.tir.vta.coproc_dep_push(3, 2)
T.tir.vta.coproc_dep_push(3, 2)
for i2_outer in range(2):
vta = T.int32()
for cthread_s in range(2):
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
T.tir.vta.coproc_dep_pop(3, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 8, 98, 0, 0)
T.call_extern("int32", "VTAUopLoopBegin", 7, 14, 0, 0)
for j_init in range(14):
T.tir.vta.uop_push(0, 1, cthread_s * 784 + j_init, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
for ic_outer in range(16):
cse_var_6: T.int32 = i2_outer * 7
cse_var_5: T.int32 = ic_outer * 9
cse_var_4: T.int32 = T.max(1 - cse_var_6, 0)
cse_var_3: T.int32 = T.max(cse_var_6 - 6, 0)
cse_var_2: T.int32 = 9 - cse_var_4 - cse_var_3
cse_var_1: T.int32 = ic_outer * 196 + i2_outer * 98 + cse_var_4 * 14 - 14
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 1):
T.tir.vta.coproc_dep_pop(2, 1)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), data.data, cse_var_1, 14, cse_var_2, 14, 1, cse_var_4, 1, cse_var_3, 0, 2)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), kernel.data, cse_var_5, 9, 8, 144, 0, 0, 0, 0, 0, 1)
T.tir.vta.coproc_dep_push(1, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 1):
T.tir.vta.coproc_dep_pop(2, 1)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), data.data, cse_var_1, 14, cse_var_2, 14, 1, cse_var_4, 1, cse_var_3, 144, 2)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), kernel.data, cse_var_5 + 1152, 9, 8, 144, 0, 0, 0, 0, 72, 1)
T.tir.vta.coproc_dep_push(1, 2)
for cthread_s in range(2):
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
T.tir.vta.coproc_dep_pop(1, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 8, 98, 0, 9)
T.call_extern("int32", "VTAUopLoopBegin", 7, 14, 16, 0)
for dy, dx, j in T.grid(3, 3, 14):
T.tir.vta.uop_push(0, 0, cthread_s * 784 + j, cthread_s * 144 + dy * 16 + j + dx, cthread_s * 72 + dy * 3 + dx, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
T.tir.vta.coproc_dep_pop(2, 1)
T.tir.vta.coproc_dep_pop(2, 1)
for cthread_s in range(2):
cse_var_7: T.int32 = cthread_s * 784
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 784, 1, 1, 0)
T.tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 3, 1, 8)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 784, 1, 1, 0)
T.tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 1, 1, 0)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 784, 1, 1, 0)
T.tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 0, 1, 127)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 3)
for cthread_s in range(2):
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 3)
T.tir.vta.coproc_dep_pop(2, 3)
for i1_inner, i2_inner, i3_inner in T.grid(8, 7, 14):
cse_var_8: T.int32 = i2_inner * 14
T.call_extern("int32", "VTAStoreBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), cthread_s * 784 + i1_inner * 98 + cse_var_8 + i3_inner, 4, res.data, cthread_s * 1568 + i1_inner * 196 + i2_outer * 98 + cse_var_8 + i3_inner, 1, 1, 1)
T.tir.vta.coproc_dep_push(3, 2)
T.tir.vta.coproc_dep_pop(3, 2)
T.tir.vta.coproc_dep_pop(3, 2)
T.tir.vta.coproc_sync()
[21:52:56] /home/xiangze/work/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[21:52:56] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_sync
計算の実行
# This library facilitates 2D convolution testing
from tvm.topi.testing import conv2d_nchw_python
コンパイル
with vta.build_config(disabled_pass={"tir.CommonSubexprElimTIR"}):
my_conv = vta.build(
s, [data, kernel, res], tvm.target.Target("ext_dev", host=env.target_host), name="my_conv"
)
[21:57:10] /home/xiangze/work/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
temp = utils.tempdir()
my_conv.save(temp.relpath("conv2d.o"))
remote.upload(temp.relpath("conv2d.o"))
f = remote.load_module("conv2d.o")
2023-06-15 21:57:30.334 INFO load_module /tmp/tmpuvnbzehk/conv2d.o
とりあえずセーブして再ロード
ctx = remote.ext_dev(0)
RPCによる通信
データ、カーネル(重み)行列の値の初期化
NCHW 形式
data_np = np.random.randint(-128, 128, size=(batch_size, in_channels, height, width)).astype(
data.dtype
)
kernel_np = np.random.randint(
-128, 128, size=(out_channels, in_channels, kernel_h, kernel_w)
).astype(kernel.dtype)
# Apply packing to the data and kernel arrays from a 2D NCHW
# to a 4D NCHWnc packed layout
data_packed = data_np.reshape(
batch_size // env.BATCH, env.BATCH, in_channels // env.BLOCK_IN, env.BLOCK_IN, height, width
).transpose((0, 2, 4, 5, 1, 3))
kernel_packed = kernel_np.reshape(
out_channels // env.BLOCK_OUT,
env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
env.BLOCK_IN,
kernel_h,
kernel_w,
).transpose((0, 2, 4, 5, 1, 3))
tvm.nd.arrayへ変換
# Format the input/output arrays with tvm.nd.array to the DLPack standard
data_nd = tvm.nd.array(data_packed, ctx)
kernel_nd = tvm.nd.array(kernel_packed, ctx)
res_nd = tvm.nd.array(np.zeros(output_shape).astype(res.dtype), ctx)
初期化して実行
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
f(data_nd, kernel_nd, res_nd)
numpyの結果と比較して確認
res_ref = conv2d_nchw_python(
data_np.astype(env.acc_dtype),
kernel_np.astype(env.acc_dtype),
(stride_h, stride_w),
(pad_h, pad_w),
).astype(env.acc_dtype)
res_ref = res_ref >> env.INP_WIDTH
res_ref = np.clip(res_ref, 0, inp_max)
res_ref = res_ref.astype(res.dtype)
res_ref = res_ref.reshape(
(
batch_size // env.BATCH,
env.BATCH,
out_channels // env.BLOCK_OUT,
env.BLOCK_OUT,
fout_height,
fout_width,
)
).transpose((0, 2, 4, 5, 1, 3))
tvm.testing.assert_allclose(res_ref, res_nd.numpy())
# Print stats
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful 2D convolution test!")
Execution statistics:
inp_load_nbytes : 114688
wgt_load_nbytes : 1179648
acc_load_nbytes : 0
uop_load_nbytes : 1144
out_store_nbytes: 50176
gemm_counter : 451584
alu_counter : 9408
Successful 2D convolution test!
まとめ、感想
2次元CNN計算をVTAで実行してみた。
- spatial paddingの設定がGEMMとの大きな違いでそれ以外はあまり変わらない。
- DMAでうまくデータ転送を隠蔽するにはデータの流れとハードウェアを意識して軸の定義と並べ替えをする必要がある。
- alu,gemmなどはprint(env)では見れなかった。
- 専用HWを作った場合にはtensorize, pragmaで同様に設定できるのだろうか。
- Atennsion(注意機構)、ViT(Visual Transformer)などを実装してみたい。
- 自作HW仕様 https://github.com/xiangze/CNN_FPGASoC_report/blob/master/FPGA SoCを用いてCNN演算.ipynb に当てはめたい
参考
CNN-based End-to-end Autonomous Driving on FPGA Using TVM and VTA
Discussion