TVMで効率的な行列行列積

TVMで行列行列積
Original Author: Thierry Moreau <https://homes.cs.washington.edu/~moreau/>_
元の英語記事は https://tvm.apache.org/docs//topic/vta/tutorials/matrix_multiply.html
です。
TVMで効率的に行列行列積を行う方法です。ニューラルネットワークの全結合層などで使われるでしょう。
TVMでのスケジュールの定義、小さなブロックに行列を分解することで組み込み系などリソースが限られたハードウェアで実行可能にします。
最適化を行わない単なる行列行列積はこちらの例があります https://tvm.apache.org/docs/topic/vta/tutorials/vta_get_started.html
でのインストールに引き続き実行していきます。
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
モジュールのインポート
from __future__ import absolute_import, print_function
import os
import tvm
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
from IPython.display import Image
rpcはターゲットハードウェアとの通信、vta.testing.simulatorはこのnotebookでのシミュレーションのために使います。
RPCの準備
# Load VTA parameters from the 3rdparty/vta-hw/config/vta_config.json file
env = vta.get_env()
# We read the Pynq RPC host IP address and port number from the OS environment
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# We configure both the bitstream and the runtime system on the Pynq
# to match the VTA configuration specified by the vta_config.json file.
if env.TARGET == "pynq":
# Make sure that TVM was compiled with RPC=1
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# Reconfigure the JIT runtime
vta.reconfig_runtime(remote)
# Program the FPGA with a pre-compiled VTA bitstream.
# You can program the FPGA with your own custom bitstream
# by passing the path to the bitstream file instead of None.
vta.program_fpga(remote, bitstream=None)
# In simulation mode, host the RPC server locally.
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
セッションを接続します。FPGAを使うときはFPGAボードと接続して回路情報(bitstrema)を書き込みます。
環境変数を見てみる
vars(env)
{'pkg': <PkgConfig at 0x7f442624ad90>,
'TARGET': 'sim',
'HW_VER': '0.0.2',
'LOG_INP_WIDTH': 3,
'LOG_WGT_WIDTH': 3,
'LOG_ACC_WIDTH': 5,
'LOG_BATCH': 0,
'LOG_BLOCK': 4,
'LOG_UOP_BUFF_SIZE': 15,
'LOG_INP_BUFF_SIZE': 15,
'LOG_WGT_BUFF_SIZE': 18,
'LOG_ACC_BUFF_SIZE': 17,
'LOG_BLOCK_IN': 4,
'LOG_BLOCK_OUT': 4,
'LOG_OUT_WIDTH': 3,
'LOG_OUT_BUFF_SIZE': 15,
'INP_WIDTH': 8,
'WGT_WIDTH': 8,
'ACC_WIDTH': 32,
'OUT_WIDTH': 8,
'BATCH': 1,
'BLOCK_IN': 16,
'BLOCK_OUT': 16,
'UOP_BUFF_SIZE': 32768,
'INP_BUFF_SIZE': 32768,
'WGT_BUFF_SIZE': 262144,
'ACC_BUFF_SIZE': 131072,
'OUT_BUFF_SIZE': 32768,
'INP_ELEM_BITS': 128,
'WGT_ELEM_BITS': 2048,
'ACC_ELEM_BITS': 512,
'OUT_ELEM_BITS': 128,
'INP_ELEM_BYTES': 16,
'WGT_ELEM_BYTES': 256,
'ACC_ELEM_BYTES': 64,
'OUT_ELEM_BYTES': 16,
'acc_dtype': 'int32',
'inp_dtype': 'int8',
'wgt_dtype': 'int8',
'out_dtype': 'int8',
'BITSTREAM': '1x16_i8w8a32_15_15_18_17',
'MODEL': 'sim_1x16_i8w8a32_15_15_18_17',
'mock_mode': False,
'_mock_env': <vta.environment.Environment at 0x7f43fbb900d0>,
'_dev_ctx': <vta.environment.DevContext at 0x7f43fbeb9c70>,
'_last_env': None}
envは3rdparty/vta-hw/config/vta_config.jsonの内容を読み取っていて、デフォルトのバッチサイズ、ブロックサイズ、バッファサイズ、数値の精度(int8など)などが見て取れます。
計算グラフの定義
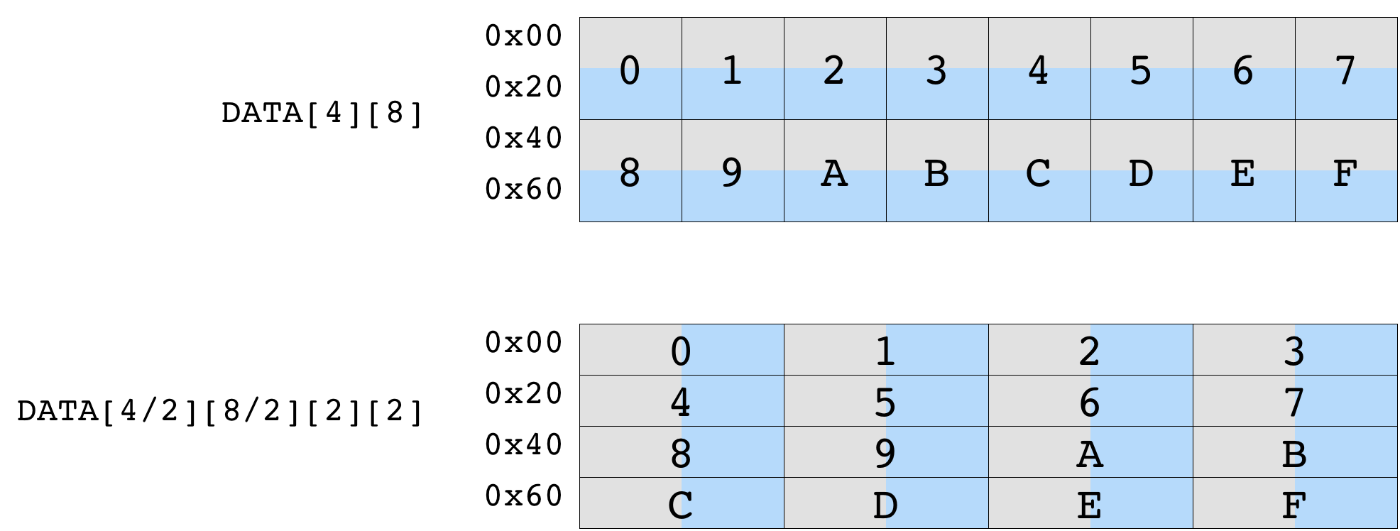
:code:BATCH, :code:BLOCK_IN, and :code:BLOCK_OUT の値を設定し、行列(一般にはテンソル)のサイズを指定する。
Image("TVM_VTA_153_220708.png")
計算を複数のチャンクに分けて順次バッファ読み出し、計算を実行、書き出すことで大きなサイズのデータの畳み込みを行う。
DMAでデバイスに行列A,Bを(少しづつ)ロードし行列行列積(GEMM)を行い結果CをDMAで書き戻す。
データサイズの定義
# Fully connected layer dimensions: 1024 x 1024
batch_size = 1
in_channels = 1024
out_channels = 1024
assert batch_size % env.BATCH == 0
assert in_channels % env.BLOCK_IN == 0
assert out_channels % env.BLOCK_OUT == 0
# Let's derive the tiled input tensor shapes
data_shape = (batch_size // env.BATCH, in_channels // env.BLOCK_IN, env.BATCH, env.BLOCK_IN)
weight_shape = (
out_channels // env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
env.BLOCK_OUT,
env.BLOCK_IN,
)
output_shape = (batch_size // env.BATCH, out_channels // env.BLOCK_OUT, env.BATCH, env.BLOCK_OUT)
num_ops = in_channels * out_channels * batch_size * 2
一度にデバイスに入れるデータサイズを計算する。
ここではバッチサイズ、入力、出力幅がちょうどデバイスに収まるような場合を想定している。
データの置き場、バッファの定義
# Reduction axes
ic = te.reduce_axis((0, in_channels // env.BLOCK_IN), name="ic")
ic_tns = te.reduce_axis((0, env.BLOCK_IN), name="ic_tns")
# Input placeholder tensors
data = te.placeholder(data_shape, name="data", dtype=env.inp_dtype)
weight = te.placeholder(weight_shape, name="weight", dtype=env.wgt_dtype)
# Copy buffers
data_buf = te.compute(data_shape, lambda *i: data(*i), "data_buf")
weight_buf = te.compute(weight_shape, lambda *i: weight(*i), "weight_buf")
placeholderで入力データを定義する。
デバイス内のバッファdata_buf, weight_buf はその値を返す関数として定義されている。
下の行列演算での内積をとる行列の方向を定義する(ic,ic_tns)。
Reduction Axesについては
https://marsee101.blog.fc2.com/blog-date-20220709.html も参照
print(ic)
print(data)
print(weight)
T.iter_var(ic, T.Range(0, 64), "CommReduce", "")
Tensor(shape=[1, 64, 1, 16], op.name=data)
Tensor(shape=[64, 64, 16, 16], op.name=weight)
計算グラフの作成
res_gemm = te.compute(
output_shape,
lambda bo, co, bi, ci: te.sum(
data_buf[bo, ic, bi, ic_tns].astype(env.acc_dtype)
* weight_buf[co, ic, ci, ic_tns].astype(env.acc_dtype),
axis=[ic, ic_tns],
),
name="res_gem",
)
行列行列積を定義し、同時に出力res_gemmの領域も定義する。
# Add shift stage for fix-point normalization
res_shr = te.compute(output_shape, lambda *i: res_gemm(*i) >> env.INP_WIDTH, name="res_shr")
# Apply clipping between (0, input max value)
inp_max = (1 << (env.INP_WIDTH - 1)) - 1
res_max = te.compute(output_shape, lambda *i: tvm.te.max(res_shr(*i), 0), "res_max")
res_min = te.compute(output_shape, lambda *i: tvm.te.min(res_max(*i), inp_max), "res_min")
# Apply typecast to input data type before sending results back
res = te.compute(output_shape, lambda *i: res_min(*i).astype(env.inp_dtype), name="res")
固定小数点の値に対するシフト演算(割り算による規格化)とクリッピング演算(Reluに相当する)も追加する。
スケジュールの作成
s = te.create_schedule(res.op)
計算全体のスケジュールを作成する。
一旦lowerして表示する
print(tvm.lower(s, [data, weight, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 64, 1, 16), "int8"), weight: T.Buffer((64, 64, 16, 16), "int8"), res: T.Buffer((1, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([1024], "int32", "global")
data_buf_1 = T.Buffer((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_1 = T.Buffer((1024,), "int8", data=data.data)
data_buf_1[cse_var_1] = data_1[cse_var_1]
weight_buf_1 = T.Buffer((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_1 = T.Buffer((1048576,), "int8", data=weight.data)
weight_buf_1[cse_var_2] = weight_1[cse_var_2]
res_gem_1 = T.Buffer((1024,), "int32", data=res_gem)
for co, ci in T.grid(64, 16):
res_gem_1[co * 16 + ci] = 0
for ic, ic_tns in T.grid(64, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast("int32", data_buf_1[ic * 16 + ic_tns]) * T.Cast("int32", weight_buf_1[co * 16384 + ic * 256 + ci * 16 + ic_tns])
res_gem_2 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1, i3 in T.grid(64, 16):
cse_var_7: T.int32 = i1 * 16 + i3
res_1 = T.Buffer((1024,), "int8", data=res.data)
res_1[cse_var_7] = T.Cast("int8", res_gem_4[cse_var_7])
ブロックサイズごとの計算
(1, 1024) x (1024, 1024)の行列行列積をアクセラレーターのSRAMに入るように複数の(1, 256) x (256, 256)に分割する。
GPUやCPUのキャッシュヒットを狙ってデータを分割する手法と同様のものらしい
処理に対応したC言語コードは以下のようなものになる(clippingは含んでいない)
for (int oc_out = 0; oc_out < 4; ++oc_out) {
// Initialization loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][j] = 0;
}
}
for (int ic_out = 0; ic_out < 4; ++ic_out) {
// Block loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int ic_inn = 0; ic_inn < 16; ++ic_inn) {
// Tensorization loop
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
for (int ic_tns = 0; ic_tns < 16; ++ic_tns) {
int i = (ic_out * 16 + ic_inn) * 16 + ic_tns;
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][i] = C[0][i] + A[0][i] * B[j][i];
}
}
}
}
}
}
}
分割の様子は以下のようになる

タイルの定義
出力テンソルを出力次元とバッチ(推論の場合は1次元なので変化なし)の方向にタイリング分割する
b_block = 1 // env.BATCH
i_block = 256 // env.BLOCK_IN
o_block = 256 // env.BLOCK_OUT
b, oc, b_tns, oc_tns = s[res].op.axis
b_out, b_inn = s[res].split(b, b_block)
oc_out, oc_inn = s[res].split(oc, o_block)
s[res].reorder(b_out, oc_out, b_inn, oc_inn)
reorderで並び替えを行う(numpy参照)。
# Move intermediate computation into each output compute tile
s[res_gemm].compute_at(s[res], oc_out)
s[res_shr].compute_at(s[res], oc_out)
s[res_max].compute_at(s[res], oc_out)
s[res_min].compute_at(s[res], oc_out)
中間変数すべてにタイル化を反映させなければいけないらしい(面倒)
# Apply additional loop split along reduction axis (input channel)
b_inn, oc_inn, b_tns, oc_tns = s[res_gemm].op.axis
ic_out, ic_inn = s[res_gemm].split(ic, i_block)
# Reorder axes. We move the ic_out axis all the way out of the GEMM
# loop to block along the reduction axis
s[res_gemm].reorder(ic_out, b_inn, oc_inn, ic_inn, b_tns, oc_tns, ic_tns)
入力チャネルのループを追加する処理があり、その後出力テンソル(行列)s[res_gemm]の軸をic_out, b_inn, oc_inn, ic_inn, b_tns, oc_tns, ic_tns) の順番にreorderする。
ブロックをタイリングした様子は以下のように描ける
Image("tensor_core.png")

lowerで現時点のスケジュールを表示する
print(tvm.lower(s, [data, weight, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 64, 1, 16), "int8"), weight: T.Buffer((64, 64, 16, 16), "int8"), res: T.Buffer((1, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([256], "int32", "global")
data_buf_1 = T.Buffer((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_1 = T.Buffer((1024,), "int8", data=data.data)
data_buf_1[cse_var_1] = data_1[cse_var_1]
weight_buf_1 = T.Buffer((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_1 = T.Buffer((1048576,), "int8", data=weight.data)
weight_buf_1[cse_var_2] = weight_1[cse_var_2]
for i1_outer in range(4):
res_gem_1 = T.Buffer((256,), "int32", data=res_gem)
for co_init, ci_init in T.grid(16, 16):
res_gem_1[co_init * 16 + ci_init] = 0
for ic_outer, co, ic_inner, ci, ic_tns in T.grid(4, 16, 16, 16, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast("int32", data_buf_1[ic_outer * 256 + ic_inner * 16 + ic_tns]) * T.Cast("int32", weight_buf_1[i1_outer * 262144 + co * 16384 + ic_outer * 4096 + ic_inner * 256 + ci * 16 + ic_tns])
res_gem_2 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1_inner, i3 in T.grid(16, 16):
cse_var_7: T.int32 = i1_inner * 16
res_1 = T.Buffer((1024,), "int8", data=res.data)
res_1[i1_outer * 256 + cse_var_7 + i3] = T.Cast("int8", res_gem_4[cse_var_7 + i3])
Image("data_tiling.png")
DMA転送の設定
# Set scope of SRAM buffers
s[data_buf].set_scope(env.inp_scope)
s[weight_buf].set_scope(env.wgt_scope)
s[res_gemm].set_scope(env.acc_scope)
s[res_shr].set_scope(env.acc_scope)
s[res_min].set_scope(env.acc_scope)
s[res_max].set_scope(env.acc_scope)
# Block data and weight cache reads
s[data_buf].compute_at(s[res_gemm], ic_out)
s[weight_buf].compute_at(s[res_gemm], ic_out)
set_scopeでSRAM bufferにscopeを設定する。env.acc_scope,env.wgt_scopeはVTAのハードウェアに用意された場所らしい。
転送期間を隠蔽するためDMA転送(load)を行列積計算のループの中に入れる
s[data_buf].pragma(s[data_buf].op.axis[0], env.dma_copy)
s[weight_buf].pragma(s[weight_buf].op.axis[0], env.dma_copy)
# (this implies that these copies should be performed along b_inn, or result axis 2)
s[res].pragma(s[res].op.axis[2], env.dma_copy)
DMA copy pragmaをDRAM->SRAM転送とSRAM->DRAM転送に用いる
pragma(*,env.dma_copy)でDMA load/storeが行われる(最内ループの)方向(axis)を対応付ける
ここではaxis2に沿ってコピーが行われる
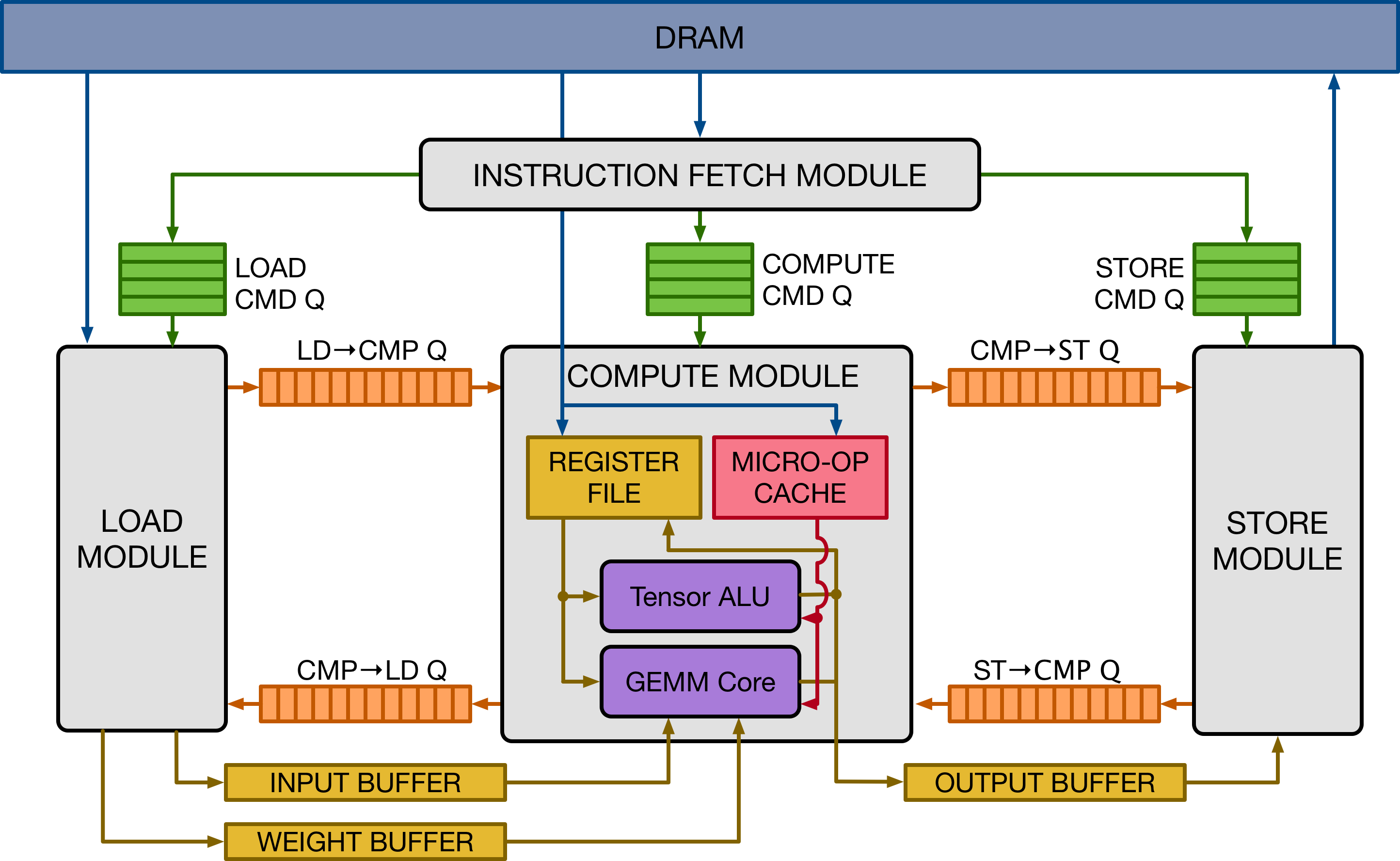
VTAへ計算を転送する割り当てる
Hardwareへの計算の割り当て
# Apply tensorization over the batch tensor tile axis
s[res_gemm].tensorize(b_tns, env.gemm)
s[res_shr].pragma(s[res_shr].op.axis[0], env.alu)
s[res_min].pragma(s[res_min].op.axis[0], env.alu)
s[res_max].pragma(s[res_max].op.axis[0], env.alu)
tensorize(*,env.gamm)で行列演算をhardware intrinsicsに割り当てるらしい。VTAにはGEMMユニットが用意されておりそれに割り当てるということらしい。
shift,clipping演算をpragmaで計算をALUに割り付ける
GEMMユニット,ALUは下図の紫の部分
最後にできたスケジュールをlower, printして確認
DMAへの loads/storesとVTAでの計算が含まれている
print(vta.lower(s, [data, weight, res], simple_mode=True))
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(data: T.Buffer((1, 64, 1, 16), "int8"), weight: T.Buffer((64, 64, 16, 16), "int8"), res: T.Buffer((1, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
T.tir.vta.coproc_dep_push(3, 2)
for i1_outer in range(4):
vta = T.int32()
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
T.tir.vta.coproc_dep_pop(3, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 0)
T.tir.vta.uop_push(0, 1, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
for ic_outer in range(4):
cse_var_1: T.int32 = ic_outer * 16
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 1):
T.tir.vta.coproc_dep_pop(2, 1)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), data.data, cse_var_1, 16, 1, 16, 0, 0, 0, 0, 0, 2)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), weight.data, i1_outer * 1024 + cse_var_1, 16, 16, 64, 0, 0, 0, 0, 0, 1)
T.tir.vta.coproc_dep_push(1, 2)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
T.tir.vta.coproc_dep_pop(1, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 16)
T.call_extern("int32", "VTAUopLoopBegin", 16, 0, 1, 1)
T.tir.vta.uop_push(0, 0, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
T.tir.vta.coproc_dep_pop(2, 1)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 3, 1, 8)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 1, 1, 0)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 0, 1, 127)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 3)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 3)
T.tir.vta.coproc_dep_pop(2, 3)
for i1_inner in range(16):
T.call_extern("int32", "VTAStoreBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), i1_inner, 4, res.data, i1_outer * 16 + i1_inner, 1, 1, 1)
T.tir.vta.coproc_dep_push(3, 2)
T.tir.vta.coproc_sync()
T.tir.vta.coproc_dep_pop(3, 2)
[11:08:00] /home/xiangze/work/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_sync
[11:08:00] /home/xiangze/work/tvm/src/script/printer/tir/expr.cc:249: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
TVMでの計算
スケジュールができたので計算グラフのコンパイル(build)、計算を行う。
RPCを介して計算グラフをデバイスに送る。
計算を実行して結果をnumpyの計算経過と比較して確認する
コンパイル
# Compile the TVM module
my_gemm = vta.build(
s, [data, weight, res], tvm.target.Target("ext_dev", host=env.target_host), name="my_gemm"
)
temp = utils.tempdir()
my_gemm.save(temp.relpath("gemm.o"))
remote.upload(temp.relpath("gemm.o"))
f = remote.load_module("gemm.o")
コンパイルしてセーブ&ロード
リモートデバイスのコンテクストを得る
ctx = remote.ext_dev(0)
data,weightの初期値設定(int)
data_np = np.random.randint(-128, 128, size=(batch_size, in_channels)).astype(data.dtype)
weight_np = np.random.randint(-128, 128, size=(out_channels, in_channels)).astype(weight.dtype)
numpyのdata,weightを4次元にしてtvm.nd.array形式にする
# Apply packing to the data and weight arrays from a 2D to a 4D packed layout
data_packed = data_np.reshape(
batch_size // env.BATCH, env.BATCH, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
weight_packed = weight_np.reshape(
out_channels // env.BLOCK_OUT, env.BLOCK_OUT, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
# Format the input/output arrays with tvm.nd.array to the DLPack standard
data_nd = tvm.nd.array(data_packed, ctx)
weight_nd = tvm.nd.array(weight_packed, ctx)
res_nd = tvm.nd.array(np.zeros(output_shape).astype(res.dtype), ctx)
デバイス(or シミュレーター)の初期化
# Clear stats
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
ようやく計算の実行 関数fになっているのでそれを実行する。
f(data_nd, weight_nd, res_nd)
numpyの計算経過と比較して確認する
# Verify against numpy implementation
res_ref = np.dot(data_np.astype(env.acc_dtype), weight_np.T.astype(env.acc_dtype))
res_ref = res_ref >> env.INP_WIDTH
res_ref = np.clip(res_ref, 0, inp_max)
res_ref = res_ref.astype(res.dtype)
res_ref = res_ref.reshape(
batch_size // env.BATCH, env.BATCH, out_channels // env.BLOCK_OUT, env.BLOCK_OUT
).transpose((0, 2, 1, 3))
np.testing.assert_equal(res_ref, res_nd.numpy())
# Print stats
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful blocked matrix multiply test!")
[11:08:53] /home/xiangze/work/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
2023-03-07 11:08:53.489 INFO load_module /tmp/tmp5t1mgirn/gemm.o
Execution statistics:
inp_load_nbytes : 4096
wgt_load_nbytes : 1048576
acc_load_nbytes : 0
uop_load_nbytes : 20
out_store_nbytes: 1024
gemm_counter : 4096
alu_counter : 192
Successful blocked matrix multiply test!
まとめ
VTAによる効率的な行列行列積の実行方法について記載した。
効率的な計算のためにはHWに合わせてtilingやDMA転送の隠蔽の処理、tensorizeによる計算のVTAハードウェアへの割当などをする必要があり面倒なことがわかる。
シミュレーターで実行を確認するできるのは便利
参考
中国語での同様の説明
Discussion