はじめに
2025/10/27に、「AIやろうぜ!勉強会」という社内メンバー向けの勉強会に登壇させて頂きました。
ベクトル検索の世界(沼)へようこそ!という題で、基本的な検索の仕組みから、ベクトル検索の原理、活用例、そして実際に運用する際の“沼”ポイントまでを紹介しました。
沢山の質問を頂いたので、今回はその発表の要約と補足、質問への回答と、個人的な振り返りを行おうと思います。
発表の個人的な目標
私は株式会社XAION DATAに入社する前、前職ではベクトル検索のプロジェクトの開発を担当していました。その経験から得た知見を社内のメンバーに共有するとともに、「相手にとって初めての分野の知識を分かりやすく説明する」ことへのチャレンジとも捉えておりました。
発表そのものの要約の後、この記事の最後にはこれらの目標を達成できたかどうかの振り返りを行っています。
ベクトルとは
まずはOpenAI社のウェブサイトから拝借したこちらの画像をご覧ください。

なんだか難しそうな図ですが、実は3つのパートからできています。「テキスト」「エンべディングモデル」そして「ベクトル」です。

「エンべディングモデル」は聞き慣れない言葉かもしれませんが、この発表では「文字列を入れて数字を列を出す箱のようなもの」と説明をしました。
そしてエンべディングモデルの出力である数字の列こそ、今回の話の主役であった「ベクトル」なのです。ただ、例えば 3.1415... みたいに数字が並んでいる1つの数ではなく、一つ目のポジションに -0.027, 次のポジションに -0.001, のようにポジションごとに並んでいるのがポイントです。
ベクトル同士の類似度、内積とは
2つのベクトルの「内積」を計算することで、どれくらい似ているかを数値化できます。計算の流れはシンプルで、同じ位置の数を掛け算してすべて足します。
発表では要素がそれぞれ3つあるベクトルaとベクトルbを使い、内積の計算の例を示しました。

(大学の講義みたいと評価?頂きました。この辺のスライドは凝って作ったので嬉しかったです)
値が大きいほど、2つのベクトルは「似ている」と判定できます。
ベクトルとは?
実はここまで説明するとベクトル検索は一言(二言?)まとめられます。
比較したい文字列のベクトル表現から、内積を求め、その値をその文字列同士の類似度とし、値が高いほど「似ている」判定とする。検索クエリに対して内積が大きい文字列順に、ユーザーに返す。
(一言が長いと突っ込まれました笑)
例えば、「楽しい」と「嬉しい」の類似度を測りたい時はまず「楽しい」をエンべディングモデルに通してベクトル表現を得て、「嬉しい」を同じようにエンべディングモデルに通してベクトル表現を得ます。
そして内積を計算します。(それぞれの位置の数を掛け算して、全て足す!)
すると0.7294と出ます。
今度は同じことを「楽しい」と「ラーメン」に対して行うと0.1837と出ます。
確かに「楽しい」と「嬉しい」は意味的に似ているので、この結果も納得です。

このように、文字が一致していなくても意味的に近いものを見つけるのがベクトル検索の強みです。
ただ、ベクトルや、内積とかの話をしたはいいけど、何の役に立つの?ということで、応用例を二つ紹介しました。
応用①:FAQチャットボット

まず「質問」と「回答」のペアを用意します。
そしてユーザーからの質問(この例では「半蔵門への行き方を教えて」)が来た時に、保存した質問との類似度を内積で測り、最も近い質問に対応する回答を返します。
つまり、「ユーザーの質問がFAQの質問完全一致しなくても、意味的に近い質問の答えを返せる」ボットが作れるのです。
応用②:RAG(検索拡張生成)

このように、社内のことをChatGPTに聞いても、答えてくれません。
ここで、LLMに聞くより前に「検索ステップ」を挟んでみます。

すると、LLMは検索ステップでマッチした文書を元に回答をしてくれるのです。
具体例として、「XAION DATAボット」の作り方を紹介しました。
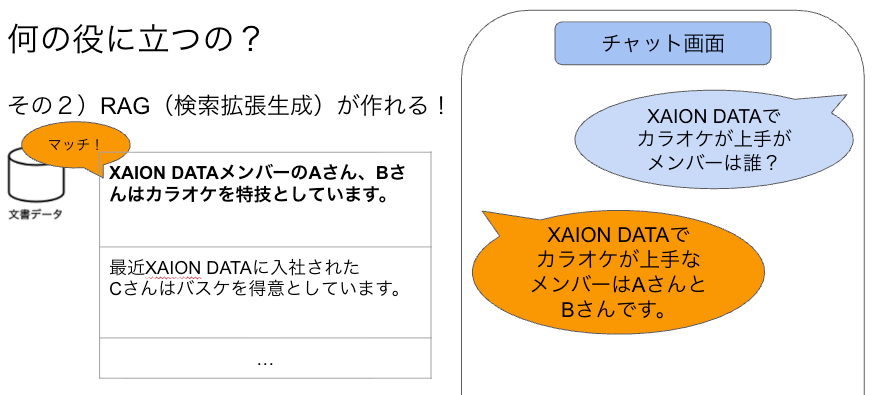
このように社内ドキュメント(左)を作っておけば、質問が来た時にドキュメントに対してベクトル検索をし、マッチした文書をもとに回答を作ってくれる「社内ボット」が作れるのです。
ベクトル検索の沼っぽいところ
ベクトル検索は便利な反面、実際に使うときには注意点があります。
沼っぽいところ①:閾値(しきい値)の設定が難しい
類似度が低いのに結果が返ってくる問題。
例えば、FAQの比較対象が1件しかないと、どんなに似ていなくてもそれが“最も高い”として返されてしまいます。

これを防ぐためには、0.55などの閾値を設定して無効なマッチを弾く必要があります。

沼っぽいところ②:「似ていない」をうまく捉えられない
色んなWebサイトを読むと、内積が1に近いほど「似ている」、0に近いほど「関係ない」、−1に近いほど「逆の意味を持つ」判定となる、と書いてあります。
それを知った上で、「嬉しい」と「悲しい」の類似度はいくらになると思いますか?

発表の時にも実際に問いかけ、-1, 0, 0.3 など、バラバラの答えを得ました。
そして正解はなんと。。。

そう、0.634 なのです。「似ている判定」なのです。
(発表でも驚かれました!驚きを演出できてよかったです。)
色々理由は考えられるのですが、「感情である」という点では似ているとも言えるかと思います。ただ、ときに予想の反する結果を返すという点に、ベクトル検索の運用の難しさが伺えます。
他にも沼っぽいところは色々あるのですが、これらは時間の都合上紹介しきれませんでした。

またどこかの機会で紹介できたらと思います。
発表のまとめ
ベクトル検索は、文字列のベクトル表現を用いて意味的な類似度による検索を実現します。
FAQボットやRAGなど、実用的な応用が豊富な一方で、閾値設定など、運用上の課題もある。
発表の時に頂いた質問
1. エンべディングモデルの出力はどう決まるのか?
エンべディングモデルの訓練の時に、同じような意味をもつ文字列のベクトル表現が(埋め込み空間上で)近くなるように訓練されます。ベクトル表現が近いと内積が高くなるので、結果として「楽しい」と「嬉しい」を似ていると判定できます。
2. ベクトルの位置ごとの意味はある?
あるベクトルが、例えば最初のポジションに0.1, 次のポジションに0.2があるとして、これらのポジションに意味はあるのか、例えば感情や食べ物などのカテゴリなどを表現しているのか、という質問でした。
結論、「このポジションにこの値があるからこのカテゴリの要素が強い」という議論は難しいです。
それぞれのポジション(軸)が何を意味するかは、人間が理解できるような明確な「感情」「食べ物」「動作」などのカテゴリに対応しているわけではありません。エンべディングモデルの学習の過程で「似た意味の単語は近くに来るように」最適化された結果として、モデル独自の抽象的な意味空間(latent space)が形成されています。
3. NotebookLMなどのツールでもRAGできそう.
そうですね!
NotebookLM は、Google が開発した AIリサーチアシスタント で、自分のアップロードした資料やノートをもとに質問したり、要約を作ったりできるツールです。
4. 例えば内積が 0.98 だとして、この 0.02 の差分が間違った回答、ハルシネーションを生み出すのか。
この因果関係が存在するかどうか、私は答えられず、もしかしたら研究のテーマにもなり得るかもしれません!
ちなみに、ハルシネーションを引き起こす原因については色んな研究がなされています。
例えば私が最近読んだこちらの論文には、モデルの訓練の段階で、試験で高い点数を取れるようにモデルを訓練したせいで、わからない場合もとりあえずランダムで答えるようになったそうです。
私も学生時代、「テストで分からなければとりあえずランダムな答えを書け」と教えられたものです。
ただ最近のモデルは分からない場合は分からないと答える割合が高いみたいで、例えば OpenAI社のgpt-5-thinking-mini と o4-mini を比べると、

(OpenAI)
1行目の Abstention rate が、回答を控えた割合になり、次のAccuracy rateが正解の回答をした割合、次のError rateが間違った回答を行った割合になります。
こうしてみると、確かにより新しいgpt-5-thinking-miniは、Abstention rateが高い代わりに、Error rateが低くなっています。もしかしたらこの先、「AIが自信満々に間違った答えを言う」ことが減っていくかもしれませんね。
目標の振り返り
この記事の最初にも書いた通り、二つの目標を立てて勉強会に臨みました。ここではそれらについて振り返りを行おうと思います。
1. ベクトル検索を社内に共有
勉強会当日はGoogle Meetで行われ、記憶が正しければ35人ほど参加してくれたので、社員の過半数の出席を頂きました。それぞれメンバーの向上心や、会社としてAIについて知ろう!のムーブメントが、この出席率をもたらしてくれたのだと思います。
2. 初学者にも分かりやすく
難しい数式よりも簡単な図、理論ばかりではなく実用例も紹介するなど、相手に伝わることを最優先にしようと色々工夫しました。その結果、「分かりやすかった」との声を頂きました。準備をした身としては大変嬉しく思い、この目標は達成できたのだと感じました。
改善点
最後に個人的な改善点ですが、やはり大人数の前で喋る時は緊張するので、台本を用意したのですが、ところどころ「台本の読み上げ」のように聞こえたのではないかと思います。次の機会では台本があっても、それを読み上げるのではなく会話のように自然の話せたらいいなと思います。
キーワードまとめ
ベクトル検索/エンベディングモデル/内積/意味的類似度/FAQチャットボット/RAG/閾値設定

Discussion