Introduction
On October 27, 2025, I had the opportunity to speak at an internal study session called “Let’s Do AI! Study Group.”
The title of my presentation was “Welcome to the World (and Abyss) of Vector Search!” I introduced the basic mechanics of vector search, real-world applications, and the “pitfalls” you may encounter when deploying it in practice.
Since I received many insightful questions, I’d like to share a summary of the presentation along with additional explanations, answers to those questions, and some personal reflections.
Personal Goals for the Presentation
Before joining XAION DATA Inc., I worked on some projects involving vector search at my previous company.
From that experience, I aimed to share what I’d learned with my colleagues and also challenge myself to explain a new, technical topic in an easy-to-understand way for people encountering it for the first time.
After summarizing the talk, I’ll reflect at the end of this article on whether I achieved these goals.
What Is a Vector?
First, let’s take a look at this image borrowed from OpenAI’s website.

It might look complicated, but it’s actually made up of three parts: “Text,” “Embedding Model,” and “Vector.”

"Embedding model" might sound unfamiliar, but during the presentation, I described it as “a box that takes text as input and outputs a list of numbers.”
The output from that embedding model — the sequence of numbers — is what we call a vector. It’s not just one long number like 3.1415…, but rather a list such as “first position: -0.027, next: -0.001,” and so on — the positions matter.
Vector Similarity and the Dot Product
We can quantify how similar two vectors are by calculating their dot product. The process is simple: multiply corresponding elements and sum them up.
In the presentation, I used two 3-dimensional vectors a and b to show an example.

(Some said it felt like a university lecture — which was a compliment, since I put a lot of effort into these slides!)
The larger the resulting value, the more similar the two vectors are.
So, What Is Vector Search?
After understanding the above, vector search can be summarized (in one—well, two—sentences):
Take the vector representations of the strings you want to compare, calculate their dot product, interpret that value as their similarity, and return the strings with the highest similarity to the query.
(Yes, people said my “one sentence” was too long 😅)
For example, if we want to measure the similarity between “fun” and “happy,” we pass both through the embedding model to obtain their vector representations. Then we calculate their dot product (multiply each position and sum them all up).
The result was 0.7294.
If we do the same for “fun” and “ramen,” we might get 0.1837.
Clearly, “fun” and “happy” are semantically closer — and the numbers reflect that.

This demonstrates the strength of vector search: it can find meaningfully similar items even when the text doesn’t match exactly.
Next, I introduced two practical applications.
Application ①: FAQ Chatbot

First, we prepare a list of question-answer pairs.
When a user asks something like “How do I get to Hanzomon?”, we calculate the similarity between their question and the stored ones using dot products, then return the answer corresponding to the most similar question.
In other words, even if the user’s question doesn’t exactly match an FAQ entry, the bot can find the semantically closest question among the stored FAQ and return its corresponding answer.
Application ②: RAG (Retrieval-Augmented Generation)

For example, if you ask ChatGPT about something internal to your company, it won’t know the answer. But if we insert a retrieval step before asking the LLM…

…the model can use the retrieved documents to generate a grounded, accurate response.
I introduced the example of a “XAION DATA Bot.”
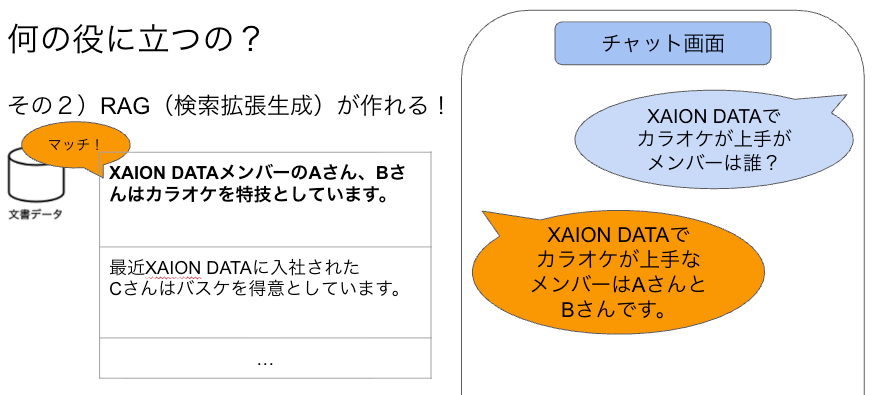
By storing internal documents (left), the bot can perform a vector search over them when a query arrives and generate an answer based on the most relevant content — essentially becoming a company knowledge assistant.
The “Abyss” of Vector Search
While vector search is powerful, deploying it in practice comes with challenges.
Pitfall ①: Setting the Similarity Threshold
A common issue is that irrelevant results can still be returned if the dataset is small. For instance, if there’s only one FAQ entry, even a poor match will be considered “the best.”

To fix this, you can set a threshold (e.g., 0.55) and filter out weak matches.

Pitfall ②: Difficulty in Capturing “Opposites”
You may have read that a dot product near 1 means “similar,” near 0 means “unrelated,” and near –1 means “opposite.”
So, what do you think the similarity is between “happy” and “sad”?

When I asked this during the presentation, the audience gave various guesses — -1, 0, 0.3…
And the actual result was:

0.634 — surprisingly similar!
(This moment got a great reaction — I was glad it worked as a surprise element.)
While “happy” and “sad” are opposites, they both express emotions, which could explain why they’re placed close in embedding space.
It shows how vector search can sometimes yield counterintuitive results — a reminder of its complexity.
There are many more “abyss-like” aspects, but time didn’t allow me to cover them all.

Hopefully, I can share these another time.
Summary of the Presentation
Vector search uses vector representations of text to enable semantic similarity–based retrieval.
It has powerful applications such as FAQ bots and RAG, but also practical challenges like threshold tuning.
Questions from the Audience
1. How is the embedding model’s output determined?
During training, the model is optimized so that semantically similar strings are represented by nearby vectors in embedding space.
As a result, “fun” and “happy” have high dot products, reflecting their semantic closeness.
2. Do individual vector dimensions have meaning?
Someone asked whether specific vector positions — e.g., first = 0.1, second = 0.2 — correspond to specific concepts like “emotion” or “food.”
The answer: not directly.
Each position doesn’t have a clear human-interpretable meaning.
Rather, during training, the model constructs an abstract latent space, where semantic relationships are captured implicitly. So while nearby vectors are related in meaning, the individual dimensions themselves don’t map neatly to human categories.
3. Could we implement RAG using tools like NotebookLM?
Yes!
NotebookLM (developed by Google) is an AI research assistant that lets you upload your own materials and then ask questions or generate summaries based on them — essentially, a RAG-based system.
4. If two vectors have a dot product of 0.98, could the 0.02 difference cause hallucinations?
I couldn’t give a definite answer — it could even be a research topic!
There’s active research into the causes of hallucinations. For example, this paper suggests that models trained to maximize test performance may “guess randomly” when unsure — similar to how some of us were taught to do on exams!
Interestingly, newer models tend to say “I don’t know” more often.
For instance, comparing OpenAI’s gpt-5-thinking-mini with o4-mini:

(from OpenAI)
Here, Abstention rate shows how often the model refused to answer, Accuracy rate shows correct answers, and Error rate shows incorrect ones.
As shown in the above figure, the newer gpt-5-thinking-mini has a higher abstention rate but lower error rate. So perhaps in the future, we’ll see fewer cases of AI confidently giving wrong answers.
Reflections on My Goals
As mentioned at the beginning, I had two goals for this talk.
1. Sharing Knowledge of Vector Search Internally
The study session was held on Google Meet, and if I recall correctly, around 35 colleagues joined — more than half of the company. I believe this turnout reflects both individual curiosity and the company’s growing enthusiasm for AI.
2. Making It Understandable for Beginners
I prioritized clarity over technical depth — using visuals instead of formulas and including real-world examples. As a result, I received feedback that it was “easy to understand,” which made me very happy. I feel this goal was achieved.
Areas for Improvement
I think I got nervous and relied on my script a bit too much — it might have sounded like I was reading. Next time, I’d like to deliver the talk more naturally and conversationally, even if I have a script on hand.
Key Terms
Vector Search / Embedding Model / Dot Product / Semantic Similarity / FAQ Chatbot / RAG / Threshold Setting

Discussion