One-Hot 表現を SVM に突っ込むとどうなる?
はじめに
正確には入力される説明変数に実数と One-Hot 表現が混在しているデータを、内部でカーネル関数を用いるアルゴリズムに入力するとどうなるのかという疑問です。そんなことをして OK なのか NG なのか。
職場で質問があって直感的に NG と言ったのですが「なんで」「具体的に」と言われてパッと答えられず、申し訳ない思いをしたので、One-Hot 表現がモデルに影響を与えるケースについていろいろ考察してみました。
結論から言えば、直感に反して、前処理としてスケーリングさえかけていれば SVM にそのまま突っ込んでも OK でした。
直感的に NG ?
内部でカーネル関数を用いるアルゴリズムとは、カーネル法やガウス過程に基づく手法のことです。非線形 SVM は線形 SVM をカーネル法で拡張したものなのでこれに該当します。
カーネル関数
カーネル関数は対称性と(半)正定値性さえ満たせば自由なものを選ぶことができます。これは逆に言えば、適切にデータの「近さ」を測れるように入力空間とそれに対応するカーネル関数を自分で設計しなければならないということでもあります。
scikit-learn の SVC や SVR はデフォルトで RBF カーネル、つまりガウスカーネルを用いています。ガウスカーネルの定義は
です(ただし
ここで生じる疑問として、ガウスカーネルはベクトルの一部に One-Hot 表現が含まれているときにうまくデータ間の「近さ」を測ってくれるのでしょうか?
これは他の職業の人はともかくとして、データサイエンティストを名乗る人間だけは「本当にそんなことしていいの?」と一度は問うべき問題です。
したがって「やっていいの?」と聞かれたら私は立場上、黄色信号を出さざるを得ないのです。
One-Hot 表現とは
とするような表現方法を One-Hot 表現といいます。
One-Hot 表現は有限個の状態に対して適当な値を割り振るのが難しいときによく用いられます。たとえば性別は
とするのが One-Hot 表現です。昨今の事情に配慮して「その他(
とすることで対応できます。多くのケースで、上記の各式の
他のあまりよくない表現
他にも簡単に思いつくのは
の二種類です(こちらも定数倍は無意味です)。
ここに「その他(
などとすることはできます。
これらの表現はどれもあまりよくない表現です。正負の符号は「反対方向」の構造を、1,2,3 といった数値は「順序」や「距離」の構造をデータに強制してしまうからです。また、
One-Hot 表現は「方向」の構造くらいしか持たないので、データに対する仮定が少ない表現と言えます。
実数/ One-Hot 混在表現
これは実際のデータ解析でよく発生するのですが、説明変数の組
のような形式を取ります。
実数/ One-Hot 混在表現(長いので今後は混在表現と呼ぶことにします)は、解釈としては One-Hot 表現により区別される実験系の入力データに対応します。
線形回帰と混在表現
混在表現を線形回帰に入力すると定数項(切片)の切り替えを意味します。混在表現の入力
です。
という二つの平行な直線の方程式に相当します。一般化すれば、One-Hot 表現で区別される複数の実験系において出力が完全に定数シフトの関係にあるときだけ、混在表現による線形回帰はうまくいくことになります(説明変数に任意の特徴量
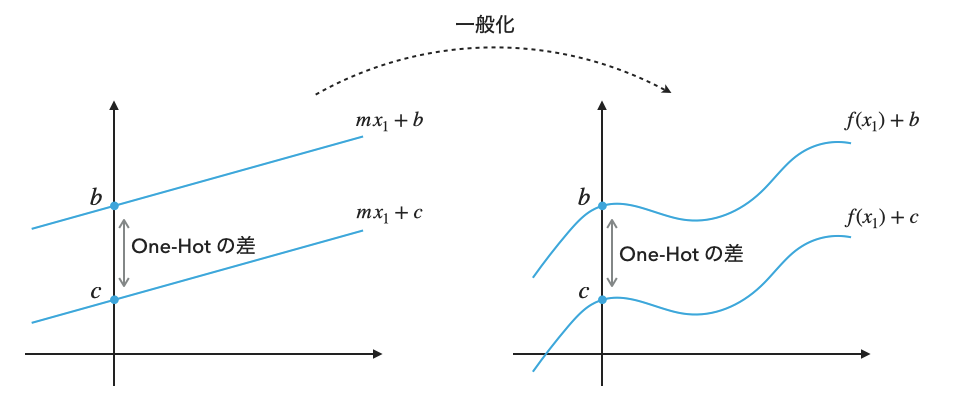
線形回帰と他のあまりよくない表現
先ほど紹介した「他のあまりよくない表現」は、One-Hot 表現の代わりに状態に適当な数値を割り振る表現でした。状態に適当な数値を割り振った集合を
です。つまり人為的に決めた状態の値で定数項(切片)が決まってしまうモデルとなり、
決定木と混在表現
RandomForest などの決定木系のモデルは、何も考えずに混在表現を入力したとしても、おそらくあまり問題がありません。もともと説明変数に対して条件分岐を繰り返すモデルなので、One-Hot の部分に対して
なんなら「他のあまりよくない表現」で紹介した表現でも、木の深さとデータ数が十分なら特に問題なく学習してくれそうな感じがします。
線形回帰や SVM と違って理論的に評価するのが難しいので実験してみないとわからないですね。
SVM と混在表現
カーネル法で拡張された SVM は「入力空間で近くにあるデータは出力も近い値を取るはず」という、k-近傍法に近い考え方をモデル化したものになっています。
いまは何も考えずにガウスカーネルを使った場合に着目して議論しているので、ガウスカーネルについて式変形してみましょう。
One-Hot 表現の部分がデータ間の距離に与える影響は、
です。
One-Hot 表現は異なる実験系の切り替えを意味していたことを思い出せば、これは
- 同じ実験系で
(x _ 1 ^ {(i)} - x _ 1 ^ {(j)}) ^ 2 = 2 - 異なる実験系の
x _ 1
の二つをまったく同じ重要度で評価することを暗黙に仮定してしまいます。異なる実験系でのデータが、必ずしももう一方の実験系でのデータを説明するために役に立たないケースは問題を発生させるかもしれません。
しかしこの仮定は、
- 前処理としてスケーリングを行なっている
- 実数変数の個数が十分に少ない(
\mathbb{R} \times \mathbb{I}_m \mathbb{R} ^ 2 \times \mathbb{I}_m
という条件が満たされる限り、ほとんど問題になりません。メカニズムとしては、スケーリングによってほとんどの場合、同じ実験系の点が異なる実験系の点よりも近くにくるからです。
スケーリングは各変数からその平均を引き、標準偏差で割ったものです。One-Hot 表現は値が
となり、距離
一方で実数変数については、あるデータ点から
M. W. Toews - 投稿者自身による作品, based (in concept) on figure by Jeremy Kemp, on 2005-02-09, CC 表示 2.5, https://commons.wikimedia.org/w/index.php?curid=1903871による
まとめると、
- 前処理としてスケーリングを行わなかったとき
-
\mathbb{R} ^ n \times \mathbb{I} _ m n
の少なくとも一方を満たすときは気をつける必要があります。
実験
混在表現はまったく異なる実験系を同じデータシートにまとめてしまうことができるので、たとえば以下の図のようなケースも当然あり得ます。
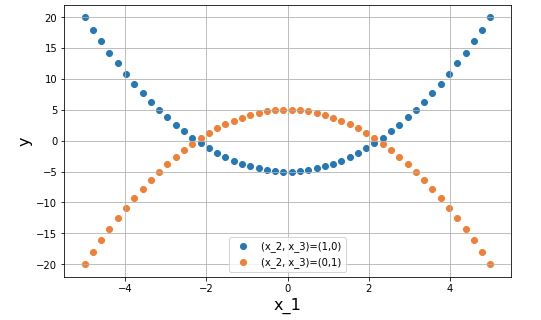
青、橙の曲線はいずれも二次関数ですが、
を用いて、
と変数変換して描画したものですから、実際の現象としては下図のような構造を取っていて、たまたま私たちが
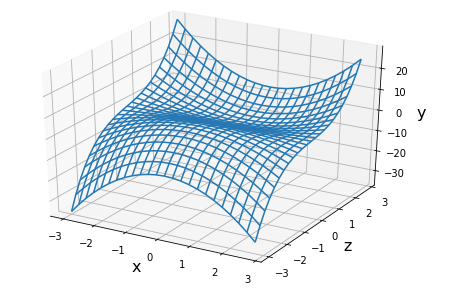
さて、実際のデータはこんなに均等にデータ点を収集できず、以下の図のように歯抜けになっていることがほとんどです。

いま、橙色の
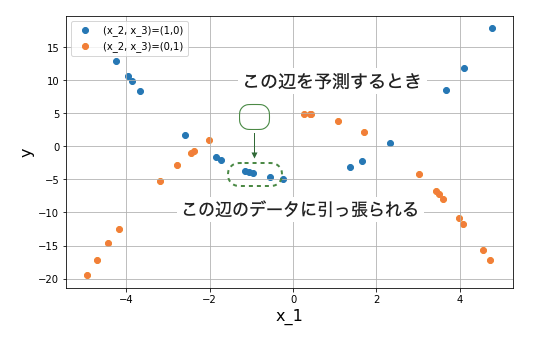
これはおそらく、橙色のデータと青色のデータをそれぞれ別々に SVR で回帰するよりも悪い予測結果になるでしょう。別の実験系のデータが影響を与えないくらい高密度でデータを観測すればこの問題は起こらないかもしれませんが、最初から分けておけば、より少ないデータ数で精度よく近似ができるはずです。
おわりに
実数/ One-Hot 混在表現がモデルに与える影響について考察しました。みなさまのデータ解析に役立てていただければ幸いです。
-
たとえば線形回帰、決定木、ニューラルネットなどに基づくモデルでは定数倍をモデルが吸収してくれますし、モデルが吸収してくれない場合でも前処理としてスケーリングを行えば定数倍は打ち消されます。 ↩︎
-
身長と体重はいずれも正の値のみを取るので、厳密に言えばこの場合も
\mathbb{R} _ + \mathbb{R} -
データ数が奇数個か偶数個かによって若干変わり、データ数が無限大の極限で
0.5
Discussion