初めまして!woodstock.clubというスマホ投資SNSアプリでエンジニアとして働いているkasaiです。
woodstock.clubは従来の投資アプリとは違って、みんなで学んで、他の人の投資方法を見て自分の投資にも活かすという新しいアプリになっています。Xのようなタイムライン機能があって、ここで交流しながら投資ができます。若いユーザーがとても多いです!
前回の記事に続いて、第二弾は、生成AI(LLM)をwoodstockに実装した話をします。実装詳細までは踏み込みませんが、難しかったところ、工夫したところなどをまとめました。
読んで欲しい人
- LLMのケーススタディを探している人
- RAGがどのように実アプリケーションに使われてるか知りたい人
- 流行りのAI(ChatGPT)がどんな風に使われているかふんわり知りたい人
- LLM、RAGの成功例を知りたい人
どんな機能か
「AI Sensei」と呼ばれるAIがユーザーの投資に関する質問に対して何でも答えてくれる機能です。

投資を始めたばかりの人が最初に思うことは、とにかく知らないことが多すぎだと思っています。woodstockにはタイムラインがあって、そこで聞くこともできますが、聞きにくかったり、答えている方もまた同じ質問かと思ってしまうのではないかと感じていました。
そこでAIがこれらを全て答えてくれることで、初心者にも経験者にも優しいプラットフォームになるのではと思ったのがきっかけです。また、質問は他のユーザーにも表示されるので、他のユーザーの質問も参考にすることができます。
技術スタック
LLM関連のものだけでいうと、
- LLM model
- cloudflare workers AI
- azure openAI
- gemini
- Trace & Development
- langfuse
- langchain
- Vector DB & embedding model
- qdrant
- bge
このあたりを使って開発をしました。今回の記事では詳しく説明しませんが、特に知らなくても記事を読んでいけると思います。
リリース前に意識したところ
まだどれほどのニーズがあるか分からない中で開発していくので、どれくらいコストを削減してMVPを作れるかが特に重要でした。また、リリースした後に定量的に性能を測る必要があるので、どうやってトレースをとっていくかも重要なポイントです。
実装の大まかな説明
いわゆるRAG(Retrieval-Augmented Generation)と呼ばれるもので、LLM界隈ではとてもよく用いられる手法です。ChatGPTなどのLLMを使ったことある方はわかると思いますが、考慮すべき点として、
- 学習に時間がかかる
- 最新の情報を出力することができない
- 知らない問いに対して幻覚(Hallucination)を起こす
といったことがあります。ちなみにいつまでの情報が学習に使われているかは"cutoff date"などで調べるとヒットします。
そこで、最新のドメイン知識を手に入れるために、学習しなおす(fine-tuning)ことが考えられますが、
- データを用意するのが面倒
- GPUを用意する必要がある
- MLの知識が必要
など、とりあえず使ってみるか!ではなかなか手を出せないコストになっています。
そこでこれらの問題を回避するために、ランタイムで知識を与えて答えさせるというのがRAGです。
実際やっていることはすごく単純で、ユーザーがLLMに対して質問する際に、アプリケーションがinterceptして外部情報を付与します。
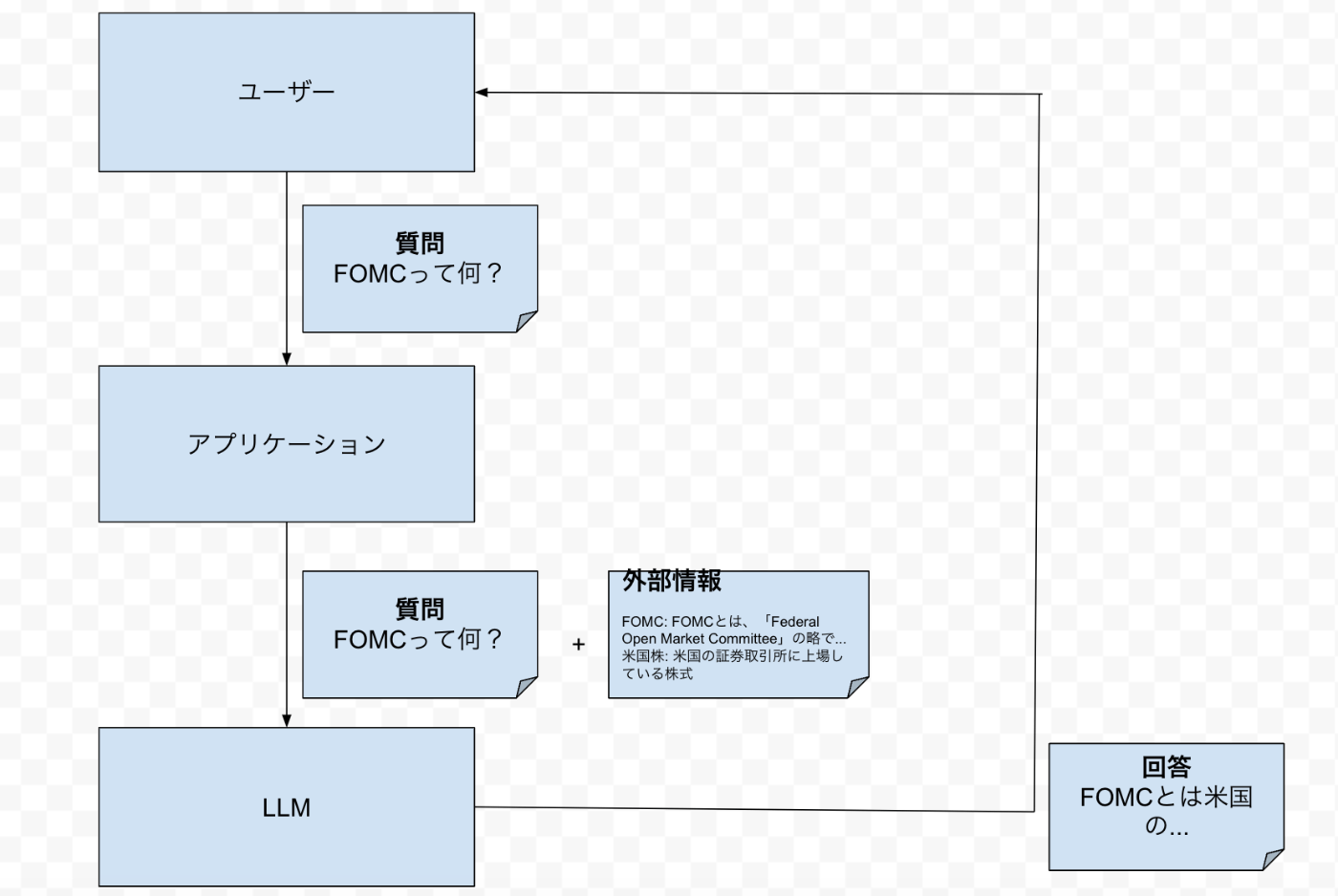
図のように、「FOMCって何?」という質問に対して、アプリケーションがそれに近い情報を付与してLLMに渡します。するとLLMは質問と外部情報を参照して必要な回答を組み立てます。
このような構造にするとLLMの知らないことでも答えてくれるようになります。(すごく単純な仕組み!)
RAGの難しいところ
ただ、RAGにも考慮すべき点がいくつかあります。
- LLMに一度に与えられるプロンプト量には限りがある
- 外部情報として付与するデータの検索方法
"context window"などで調べるとヒットしますが、LLMは無限の記憶を持っているわけではないので、記憶できるプロンプト量は制限されています。これを超えると、過去の入力は無かったことになります。つまり、あまりに長い文章を外部情報として入力するとすぐに枯渇します。
woodstockのAIは今現在チャット形式で会話を続けていくことは機能として提供していませんが、それはこれが理由になっています。チャットにすると考慮するべき点が増えるので、今はそれを無視しています。
少し前にgeminiが1Mのコンテキスト長に対応!やった!みたいに騒がれていたのは、ChatGPTが128Kなのと比較すると凄さがわかると思います。

次に2つめの検索方法についてですが、ここは工夫のしがいがあるところです。ここだけでひとつの記事になるかと思います。RAGの全てといっても過言ではないと思います。
例えば、検索にはよくVector DBが使われます。これを使うと文章の類似度順に結果を取得でき、RAGと相性が良いためです。「FOMCって何?」というクエリに対して、「FOMCとは「Federal Open Market Committee」(連邦公開市場委員会)の略で...」のような文章が返ってくるイメージです。woodstockではqdrantを使っています。文章の単語レベルで類似度検索するものもあれば、意味レベルで類似度検索するものもあります。 (それぞれsparse vector, dense vector) 今回の質問例の場合だと、「FOMC」という単語レベルでヒットしても良さそうに見えるので、そのようなモデルを使っても良いかもしれません。
このvectorを作るモデルはembedding modelと言います。LLMとは別物です。
一方、Vector DBで解決できないケースも存在し、それはリストで何かを取得するような場面です。「来週の決算予定の一覧を教えて」といった質問の場合、Vector DBだとうまく検索することができない可能性があります。それはVector DBにたとえ以下のようなデータが保存されていたとしても、
データ1
Nike (NKE)は2024-06-27に決算発表予定。
データ2
NVIDIA (NVDA)は2024-08-28に決算発表予定。
「来週の決算予定の一覧を教えて」との類似度を測るのは難しいからです。つまり、「来週」や「一覧」というメタデータに対してうまくヒットしない可能性があります。
woodstockではこういうケースがよくあるので、LLMにtool callingをしてもらって、来週のデータを取得する関数を呼び出してもらうようにしています。
つまり、あらかじめ
def _get_earnings_calendar(from_date: str, to_date: str):
"""Get earnings calendar within the date range.
Args:
from_date: The start date in the format of 'YYYY-MM-DD'.
to_date: The end date in the format of 'YYYY-MM-DD'.
Returns: A list of earnings calendar.
"""
# 実装詳細が続く...
のような関数を書いておいて、ランタイムでLLMに必要があればこの関数を呼び出してもらいます。そうすれば、Vector DBなど使わずとも来週の決算情報が取得できるようになります。
tool callingはLLMに備わってきた一般的な機能で、最近のLLMではどれも使えるようになってきています。llama3.1も対応しているとのことでした。
すでに想定されている質問トピックがあるのであれば、このtool calling用の関数を用意してしまうのが良いかと思います。woodstockではtool calling用のLLMと回答作成用のLLMを分けています。
仕上げ
RAGがうまく機能してきた後に感じたこととしては、出力の微調整です。例えば、LLMがLatexを出力してきたが、フロントエンドは対応していないので、簡単な数式だけで出力して欲しいといったことや、かなり長いリストはある程度でカットして欲しいといった要望です。
これに関してはtool callingと同じく、新しくLLMを用意することで解決しています。このようにすることで指示が明確になり、LLMの出力が向上するためです。
つまりwoodstockでは3つのLLMを機能的に分けて上流の出力を下流のLLMが利用するように工夫しています。
- tool calling用のLLM
- 回答作成用のLLM
- 文章校正用のLLM
それぞれのLLMに渡すsystem promptはコードベース上で管理すると毎回デプロイするのが面倒なので、別の場所に定義してそれをランタイムで読み込むという形にしています。
そこで使えるのがlangfuseのprompt managementという機能です。これはlangfuse上のダッシュボードでpromptを定義して保存すれば、ランタイム時にfetchして読み込んでくれる機能です。for-answer-prompt-templateという名前で保存すれば、以下のようにして使えます。
def _get_template() -> TextPromptClient:
client = langfuse_client()
return client.get_prompt(f"for-answer-prompt-template")
コストカット
OpenAIのモデルは比較的安価になってきたとはいえ、抑えられるところはコストを抑えて運用したいところです。そこで、「AI sensei」をリリースした初期段階では極限までコストをカットしてリリースしました。
ポイントとしては、「一番コストがかかるところを一番安いモデルで対応し、最後の出力は高性能なモデルで対応する」ということです。
当初、選べるLLMの選択肢としては
- ChatGPT
- Gemini
- llama
がありました。このうち、Geminiとllamaに関しては無料枠が用意されていて、それぞれGoogleとCloudflareから今も提供されています。cloudflareではllama3.1 8bのモデルをベータ版の間は無料で利用することができます。(ちなみに8bなど接尾についている数字はLLMのパラメータ数のことを言います。これが大きいほど基本的には優秀ですが、メモリが大量に必要になります)
先ほど、3つのLLMを使い分けていると言いましたが、
- tool calling用のLLM
- 回答作成用のLLM
- 文章校正用のLLM
tool callingにgemini、回答作成にllama、文章校正にchatGPTを使っていました。回答作成に一番コストがかかるので、これをllamaで対応できたのはとても大きいと思います。最後にChatGPTに校正してもらえば、表現も自然になって、出力が納得いくものになりました。こういう風に工夫したことで、1回の回答作成に0.01ドル以下しかかからないようになりました。
評価
リリースした後、ユーザーのフィードバックを2値で集めるようにしました。その結果によると、80%以上が「Good」で非常に価値のある機能になったと思います。🎉(約300件のフィードバックのうち)
これから
改善できるところはあり、Vector DBのembedding modelはどうするのか、他のデータソースの利用、チャット形式で連続会話に対応、検索エンジンの改善などまだまだやることは沢山あります!
まとめ
- LLMを実アプリに導入した
- 検索エンジンの部分をtool callingやvector DBで工夫した
- 出力を安定させるために、三層構造にして役割を明確化した
- コストをカットするために一番コストがかかる部分を一番安いモデルで対応した
- 80%以上が良いフィードバックだった
興味があればぜひアプリを使って「AI Sensei」に質問をどうぞ!

Discussion