Pythonで学ぶ音声合成を読む
対象
目的
Zoomでアバターを動かすの関連で、ボイスチェンジャー(声質変換)に興味が出たので基本知識として読む。(パラパラ見た感じ、声質変換がメインではないようではあるものの。)
1章
・広義の音声合成技術に声質変換がある。
2章
第1節
- 音声情報は次の三つに分類。
- 言語情報:テキスト化できる情報
- パラ言語情報:テキスト化できない情報。意図的に制御できるもの。態度、発話スタイルなど。
- 非言語情報:テキスト化できない情報。意図的に制御できない。年齢、性別など。
⇒声質変換はパラ言語情報と、非言語情報が重要っぽいけど、本書は言語情報からの合成音声がメイン。
- 言語から推定可能なコンテキスト
- 音素、モーラ、音節、語、句、呼気段落、文がある。
- 音素:母音(vowel)、子音(consonant)、ポーズ、無音
- 音節・モーラ:音声の聞こえの纏まり。母音(V)のみ、子音+母音(CV)など。
- 語1:内容語(意味)、機能語(文法)、複合語。複合語構成時に音素・音節・モーラが変化する
- 連濁(三本:さん+ほん→さんぼん)、母音交替(雨音:あめ+おと→あまおと)、音便(埼玉:埼+玉→さいたま)、連声(天皇:てん+おう→てんのう)
- 語2:アクセントを持つ。アクセント核とその位置により型が決まる。
- 句:語のアクセント位置は、句によって変わる
- 呼気段落、文:イントネーション。イントネーションを示すピッチカーブはしばしば「へ」の字型がある。
⇒最終的なピッチカーブはアクセント句レベルのピッチカーブと呼気段落レベルのピッチカーブの和であらわされる
- リズム
第2節
- フーリエ変換。振幅スペクトルと位相スペクトルで表現
- 音声生成過程を制御する器官は、呼吸器官、発声器官、調音器官からなる
- 呼吸器官:呼気を排出
- 発声器官:声帯を使用して有声音、無声音を作る
- 有声音は声門の開閉で音を出す。その周期を基本周期という。その逆数を基本周波数とよぶ。男性は100Hzくらい、女性は200Hzくらい。
- ⇒ ヘリウムを飲んで声が高くなるのは声門とどういう関係にあるの?(関係ない?)
- 無声音では声門は開きっぱなし。
- 調音器官:音色を付ける。周波数の共振により強調されるピークがある。これをフォルマントと呼ぶ。フォルマントの周波数をフォルマント周波数と呼ぶ。
- 音響間の連接として近似??
- ソースフィルタモデル:呼吸器官、発声器官、調音器官をモデル化したもの。
- ソースフィルタモデルは、ソース、声帯振動、声道フィルタ、放射特性から構成。
- 後ろ三つ(声帯振動、声道フィルタ、放射特性)はスペクトル包絡と纏めて扱われる。
- 声帯振動、放射特性は定数で表現できるみたい。
- 音声のパラメータ表現から音声波形を複合することをボコーダと呼ぶ。
- ボコーダはチャネルボコーダ、フェーズボコーダ、正弦波ボコーダがある。
- チャネルボコーダはソース・フィルタモデルを仮定
- フェーズボコーダはソースフィルタモデルを仮定しない。NNに基づく。
- 人間は位相には鈍感。パラメータとしては保存されない。が、音声を生成する際には必要になるので、決まったやり方で付与する。
- ゼロ位相、最小位相、無矛盾な位相、事前学習結果に基づく位相など。
追記 フォルマントが出てきた。
3章
第1節
統計的音声合成の定式化
(3.2) 既知のw,W,Xと未知のxの条件付確率にλを導入して、未知のλの積分にしている。(λの周辺分布になるだけだからいれてもいいよねということかな?)
(3.3) ベイズというより、乗法定理?。"既知のw,W,Xで導かれるλ"と、"w,W,X,λで導かれるx"の積に分解
https://www.hellocybernetics.tech/entry/2020/08/14/062109
(3.4) 左側はW,Xが与えられた場合にλとwは独立なので、wは条件から消せる。
右側はλ,wが与えられた場合にxとX,Wは独立なので、W,Xが条件から消せる。
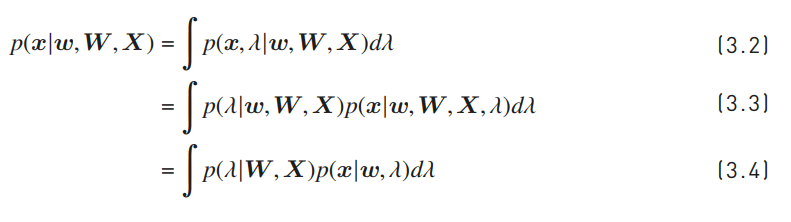
(3.6) W,Xから導き出されるλでもっともらしい点λ_hatをλの近似として(3.7)に使う。

第2節
音声合成の部分問題への分割
- 音響特徴量と言語特徴量を中間表現として導入。
- x,l,oに対する確率は、言語特徴量の予測、音響特徴量の予測、音声波形の合成の積(グラフィカルモデルから言えそう)
- 典型的なパラメトリック音声合成では、言語特徴量から音響特徴量を予測するモデルを主に統計モデルによってモデル化するらしい。⇒λ_Lとλ_Vを省略するようだが、なんで省略してよいのかわからん。(別のプロセスで用意する?p.56のテキスト解析とかがそれか?)
(3.10) "Wの時のλ_A,Xの確率"は、"Xの確率"と"X,Wの時のλ_Aの確率"の積に分解でき、両辺を"Xの確率"で割った感じ
(3.11) p(X)はarg max_λとは独立するから消してよい。ということかな?
(3.12) 乗法定理
(3.13)グラフィカルモデルから。Lは離散でOは連続。のようだが、その説明あった??

(3.17)(3.18)和積の近似がこれで良い理由がわからない。
そして、(3.19)~(3.24)に分割して良い理由がわからない。グラフィカルモデルから、要素はそうなのだろうと思うが。
⇒とりあえずそういうものとして飲み込む。
- 統計的パラメトリック音声合成の欠点で述べられている個別最適化になってしまう≒許容するというところが、上記の(3.19)~(3.24)の分割して良い論拠か?
第3節
一貫学習に基づく音声合成
- 統合の仕方は3パタン。音響特徴量予測と音声波形生成の統合、言語特徴量抽出と音響特徴量予測の統合、全ての統合。最後の以外は一貫学習といえるのかは謎。
4章
第1節
- 個人的にはJupyterはkaggleの全部入りdokcer imageを使うことが多いのだが、今回もそれを使おうと思う。
- kaggleイメージだとpip install ttslearnがこける。
- cmake moduleがないと言われてしまう。
- pip3 install cmakeしても解決しない。
- conda install cmakeをすると、pip install ttslearnが通るようになる。
第4節 フーリエ変換
- フーリエ変換。いつ見ても理解しようとする気をそぐ数式でよくわからんのだけど、まぁ飲み込む。
- パワースペクトル。振幅を2乗したもの。波(時間信号x(t))を周波数ごとのパワーを棒グラフに変換したもの。フーリエ変換の振幅を2乗したもの。これを見ておけばよい。
https://guides.lib.kyushu-u.ac.jp/c.php?g=846503&p=6051929- パワースペクトルのお気持ち。この動画がスーパーわかりやすい。2乗したもの以外は-π~πで積分すると消える。三角関数の直交性=自分以外との内積がゼロ。

- パワースペクトルのお気持ち。この動画がスーパーわかりやすい。2乗したもの以外は-π~πで積分すると消える。三角関数の直交性=自分以外との内積がゼロ。
- 普通によびのりもわかりやすい。

第5節 短時間フーリエ変換
- 短時間フーリエ変換:時間的に周波数成分が変化する特徴を捉えるための分析手法
- フレームを並べたものを振幅スペクトログラム、位相スペクトログラム
- ヒートマップっぽく表現される
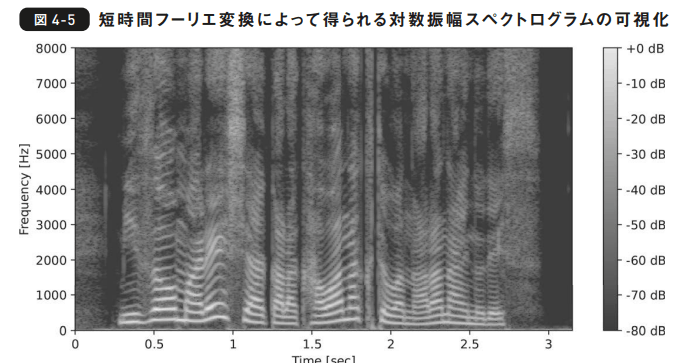
第6節 メルスペクトログラム
- メルスペクトログラム:人間の聴覚特性に合う周波数尺度で変換したもの
- 一貫学習で使う。
- 次元数が少なくて扱いやすい。フレーム長が1024のサンプルの場合、振幅だと513次元だがメルスペクトログラムだと80くらい。
- 振幅スペクトログラムにフィルタを通して生成
第7節 位相の復元
- あれ?位相って適当に決まったやり方で復元するじゃなかったっけ??(P.42)
- P.42の無矛盾な位相でGriffin-Lim法を説明すると書いてありました。
- ランダムに位相を初期化して、逆変換をして矛盾が無いように位相を更新する、を繰り返す。
- あまり品質が良くないのでニューラルボコーダにとってかわられている。(けど、本書10章ではつかうらしい。 )
5章
第1節
-
HMM音声合成、DNN音声合成
-
NN, RNN, LSTM
-
言語特徴量(例えば音素単位の系列)と音響特徴量(フレーム単位の系列)の系列長は異なる。
-
NNでは系列長が異なる特徴量間の変換を行うのは困難(??)。なので、言語構成単位言語特徴量から、フレーム単位の音響特徴量へ一気に変化することはできない、ということらしい。そこで、まず、言語構成単位の言語特徴量からフレーム単位の言語特徴量への変換する。そして、フレーム単位の言語特徴量から音響特徴量への変換する。このの2ステップをNNでモデル化している。⇒つまり、NNだと二つのモデルを有している。
-
継続長モデル:音素単位の言語特徴量から音素継続長を予測するモデル
- 音素継続長とは、各音素が占める音響特徴量のフレーム数。(これを予測することでフレーム単位での言語特徴量の切り出しができるってことかな?)
- 音響モデル:フレーム単位の言語特徴量から音響特徴量を予測するモデル
-
やはり言語特徴量を作ってから、どこで音素が切れるかを推測するフレーム単位の特徴量を切り出しているように見える。それを音響特徴量予測にかけて、音声波形生成につなげる。⇒さらに下の図5-2を見ると切り出すのではなくて、増幅するというイメージだな。

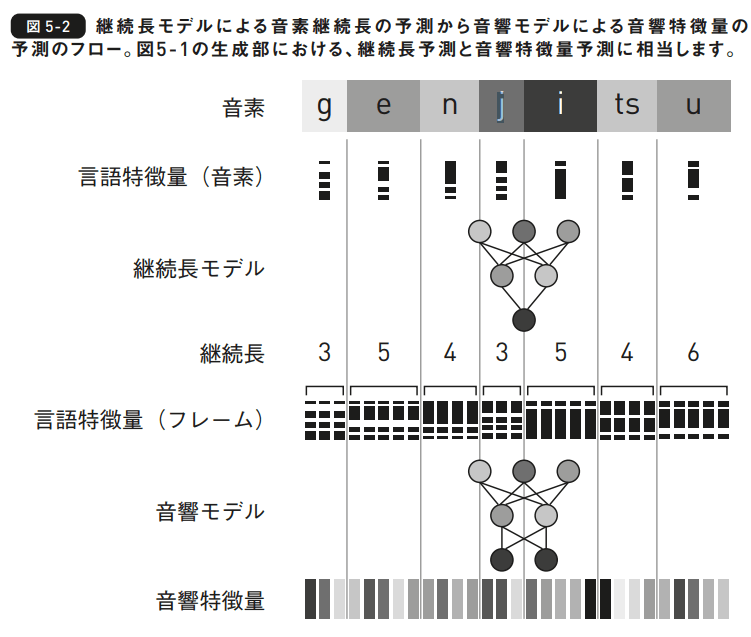
-
継続長モデルの学習のトレーニングデータは、隠れマルコフモデルなどを使う強制アライメントで作れられたり、人手によるアノテーションで作られたりする。(どういうデータの形になるのだ??文章を音素に分解して、それぞれに長さをアノテーションしていく感じ?)
第2節 D N N 音 声 合 成 に必 要なデータ
- 教師データ:音声データ、テキストデータ、言語特徴量、音響特徴量、音素アライメント
- 言語特徴量:音素、モーラ、語、句などの言語的コンテキスト。自動抽出でもよい。
- 音響特徴量:基本周波数、スペクトル包絡など、音声の物理的な性質を表す特徴量。ボコーダで抽出できるようだ。
- 音素アライメント:テキストと音声の対応関係
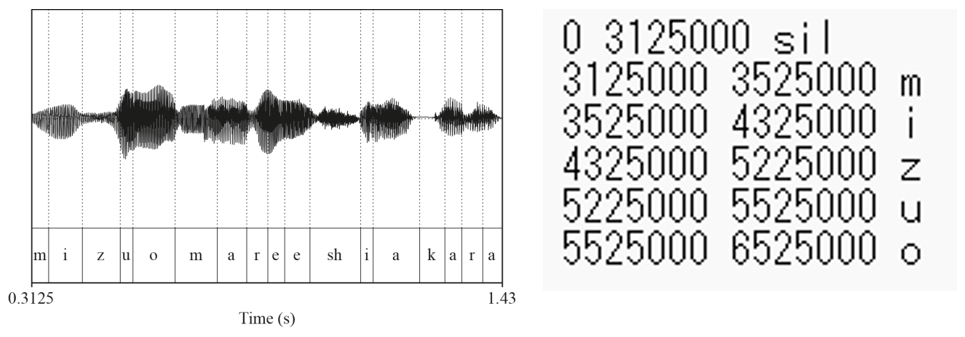
- 実用的に用いられるデータ形式は、音声データ(.wav)とフルコンテキストラベル(.lab)
- フルコンテキストラベル:音素を含むと言語特徴量と音素アライメントを格納したファイル
第3節 フ ル コンテキストラベ ル
-
モノフォンラベル:音素のみを含むラベルファイル。
-
フルコンテキストラベル:言語特徴量をすべて含む
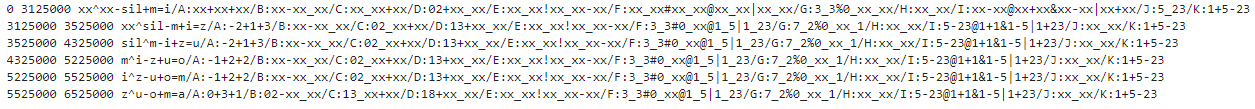
-
フルコンテキストラベルが読みにくいのは正規表現で操作しやすいように作られているため。
第4節 言語特徴量の抽出
- OpenJTalkを使うとテキストからフルコンテキストラベルが作れる。
- 音素アライメントは入っていない?とはいえ、合成音声時は継続長モデルで予測するのでいらないようだ。
- フルコンテキストラベルから必要な情報を抽出するには、HTS形式の質問ファイルを使う。質問は正規表現で表現される(ここでフルコンテキストラベルが正規表現フレンドリーな理由があるのか。)。質問の正規表現を適用して、フルコンテキストラベルから対応する情報を抜き出しているようだ。質問は2値特徴量を得るための300個と数値特徴量を得るための25個程度。意外に少ない。
第5節 音響特徴量の抽出
- 対数基本周波数、有声/無声フラグ、メルケプストラム、帯域周期性指標の4つ。
- WORLDボコーダで抽出できる
- 基本周波数の非連続性:無声オンの時に声帯が振動しないので、周波数が未定義になる。⇒補完する(線形補完)。補完したものを連続基本周波数系列と呼ぶ。
- 帯域日周期性指標:スペクトラム包絡における角周波数のパワーのうち、非周期的な雑音に由来する成分が占める割合。声のカスレ具合を表す。
- 動的特徴量:音響特徴量は前後のコンテキストの影響を受けて変化する。≒時間変化する。時間変化をつかさどる特徴量を動的特徴量と呼ぶ。音響特徴量の時間方向の1次差分や2次差分で機械的に計算。
第6節 音声波形の生成
6章
第1節 日本語音声合成システム
- テキスト→OpenJTalkテキスト解析→継続長モデル→音響モデル→WORLDボコーダ→音声波形
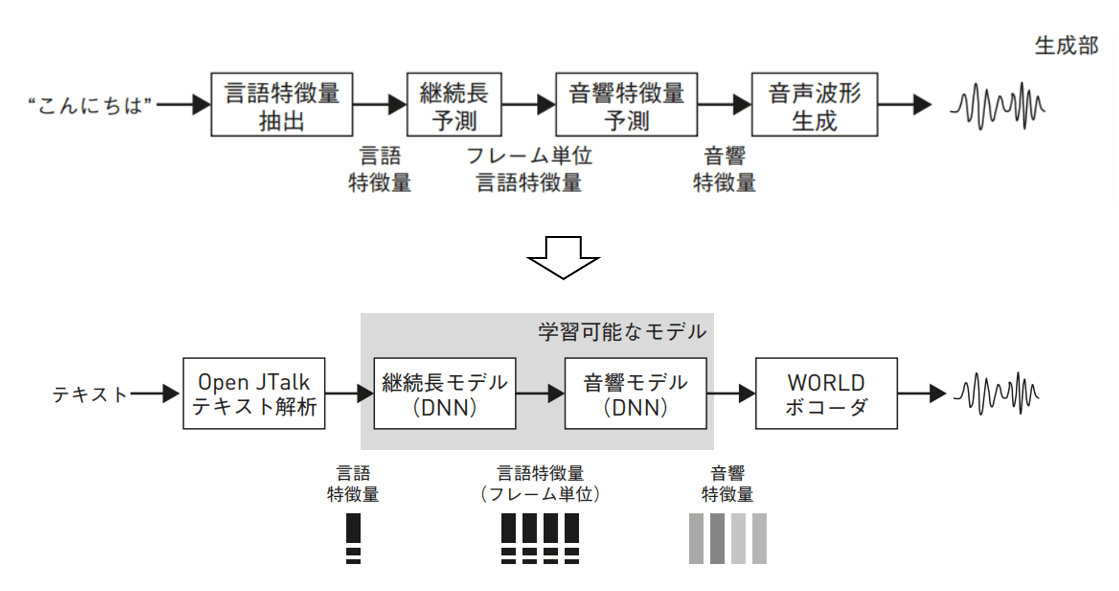
- レシピ:音声処理ツールキット(Kaldi, ESPnetなど)で採用されている実験を再現可能な形でまとめたシェルスクリプト群
- (-1)コーパスのダウンロード、(0)データ分割(学習・検証・評価)、(1)継続長モデルのためのデータ分割前処理、(2)音響モデルのためのデータ前処理、(3)特徴量の正規化、(4)継続長モデルの学習、(5)音響モデルの学習、(6)学習済みモデルを用いてテキストからの音声を合成
第4節 音響モデルのための前処理
- 「フレーム単位の言語特徴量は、音素単位の言語特徴量を抽出したあと、特徴量を音素継続長の数
だけ時間方向に繰り返すことで得られます」やはり抽出ではなく、抽出なんだな。
第6節 ニューラ ル ネットワークの 実 装
- 脚注部分:"全結合型ニューラルネットワークは、時変信号のモデル化に原理的に不向きですが、5.5節の「動的特徴量」の項で解説した動的特徴量を考慮することで、時間方向の依存関係を持つ音響特徴量を生成できます。" なるほど!!
7章
第1節 WaveNet
- 統計的パラメトリック音声合成における音響モデルと信号処理ボコーダを、一つのニューラルネットワークに統合したもの。言語特徴量の抽出、音素継続長、基本周波数予測は依然として必要。
第2節 自己回帰に基づく音声波形の生成モデル
- 音声波形xに対する確率は、より前の時刻のサンプルにのみ依存と仮定。
- モデルパラメータをλとする。
- 条件付け特徴量(例えば言語特徴量 l )を加える。
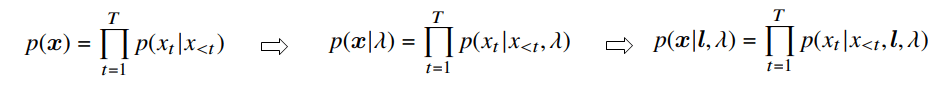
- 条件付特徴量は任意の形状。時間変化しないものをglobal conditioning, 時間変化するものをlocal conditioningとよぶ。
- Xは独立するn個の発話のサンプルxの集合。x^nは各フレーム(かな?)の集合。とすると次のような表現になる。
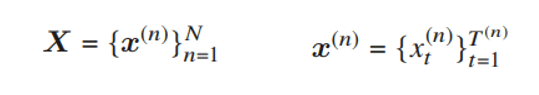
- 最尤推定でモデルパラメータλを推定するのは次のような式変形になる。三つめは一つのサンプルに対しての式。
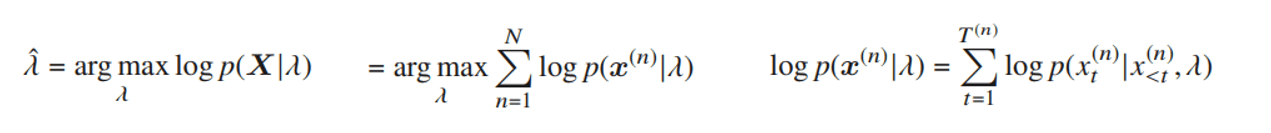
8章
第1節
- レシピは-1から8まで。レシピの数ってモデルごとに違うらしい。
第8節。
- 2080tiだとミニバッチ16はできなかった。8で実施。めっちゃ時間かかる。→GCPにお引越しするか。。。
9章
第1節
- Tacotron2はE2Eで学習。MOSで自然音声と同等の音声合成を実現。
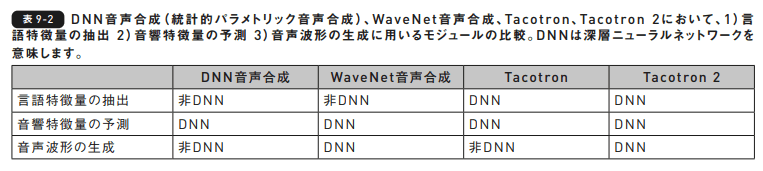
第2節
- Tacotron2の根幹はAttention mechanism付きSeq2Seq
- Seq2Seqのエンコーダは系列の構造を考慮したコンテキストベクトルを抽出。デコーダはコンテキストベクトルから構造を考慮した系列を出力。
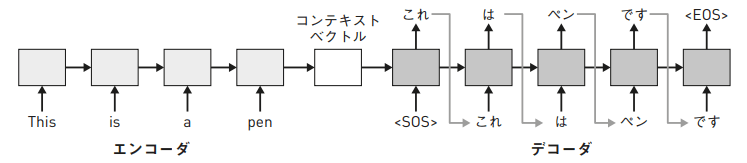
- Seq2Seqでは系列の先頭と末尾に<SOS>(start of sentence)と<EOS>(end of sentence)を入れる。
- Seq2Seqのエンコーダは系列の構造を考慮したコンテキストベクトルを抽出。デコーダはコンテキストベクトルから構造を考慮した系列を出力。
- 入力系列をw={w_1,w_2,...,w_I}, 出力系列をo={o_1,o_2,...o_M}とする。ということは、入力系列と出力系列の長さは違ってよいわけだな。
- エンコーダの隠れ状態をh={h_1,h_2,...,h_I}とする。各時刻のの隠れ状態は次のようになる。
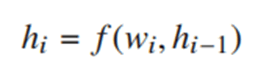
- 最後の隠れ状態がコンテキストベクトル。c=h_I
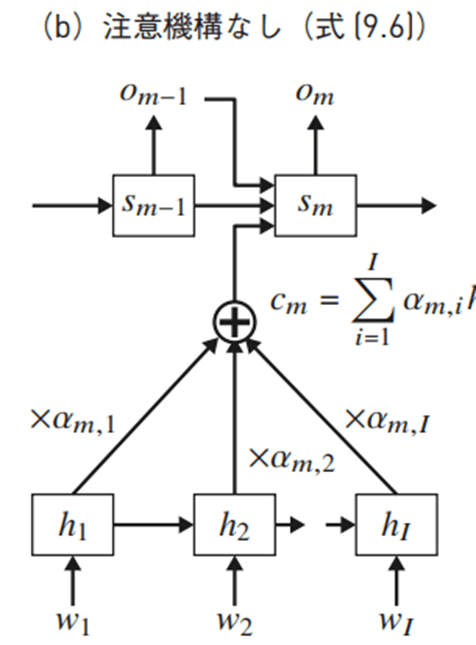
- 出力系列の条件付確率。この式だとs_mの表現がよくわからない。
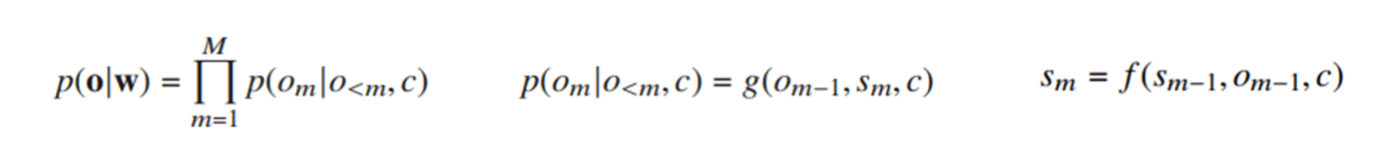
- 下図でs_mを説明している。これだとs_mの導出がわかるが、o_mがs_mからのみ算出されているように見えて、上記真ん中の式と整合性が取れない。どうなってるん?
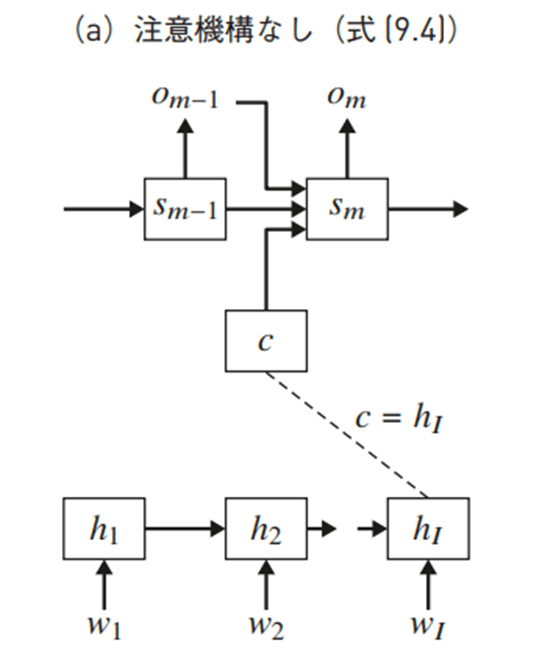
- アテンション機構を使うとコンテキストベクトルが時刻ごとに代わる。softmaxで重みづけられたh_nのになる。
第4節
- ハイブリッド注意機構:内容依存の注意機構と位置依存の注意機構を備える。
第5節
- PreNetではDropoutを行う。Dropoutは通常推論時には無効化されるが、Tacotron2では推論時にも使用する。
第7節
- Tacotoronの損失関数は三つ。メルスペクトログラムに対する損失関数(PostNet前)、メルスペクトログラムに対する損失関数(PostNet後)、stop tokenに対する損失関数。
10章
11章
その他
2022/08/06 完