はじめに
WiseVineのバックエンドテックリードの bubusuke です。
WiseVineのプロダクト(Build&Scrap)は、2024年4月に一部機能を先行リリースしました。
その後も新規機能開発と既存機能の改善を続けています。
バックエンドコードのPRマージ数で見ると、先行リリース後の1年間でそれまでの2.5倍以上のPRをマージしています。何となく変化の規模がわかっていただけるかと思います。
| 期間 | バックエンドコードのPRマージ数 |
|---|---|
| 先行リリースまで | 約1,200 |
| 先行リリースから1年間 | 約3,300 |
| 次の半年間 | 約1,700 |
この変化の中で、バックエンドのアーキテクチャも変わっていきました。
Django REST framework(以下:DRF)に則った実装から、より早く安く旨くプロダクトを作るための変化です。
なにか新しいものを作る(Build)、そのために現状を見直していく(Scrap)、そんな想いのこもったプロダクト(Build&Scrap)の名に恥じないほど、コードもビルド&スクラップしてます。
本記事ではそんなバックエンドコードの変遷を振り返ろうと思います。
想定読者
- プロダクトの機能成長とともにアーキテクチャも整備していくリアルなケースを知りたい方
- Python(特にDRF)をつかってWebアプリケーションの開発に携わっている方
※PythonやDRFに馴染みのない方でも読めるよう配慮しましたが、特に詳しい方にはより楽しんでいただける内容です。
技術要素やアプリ構成など
- 言語:Python
- フレームワーク:
- API:Django、Django REST framework
- 構成:予算編成サブシステム、マスタ管理サブシステムなどの単位でサブシステムを定義しそれをDjangoのappsとして区別している構成。
※バージョンは適宜アップデートしているので割愛しています
先行リリースまで
※私自身は先行リリース後に参画したため、先行リリースの状況は伝え聞いた内容です。
とにかく作るに専念!並行開発でプロダクトの構築
とにかく動くモノがないと始まりません。限られたリソースで最大限のアウトプット量を意識した形で開発が行われました。
やったこと
DRFの登場人物(view, serializer, model, filter, queryset)と、helperファイルを中心に実装。
予算編成サブシステム (関連部分だけ記載、1000行を超えるファイルはコメントで注記)
├── __init__.py
├── migrations
├── tests
├── admin.py
├── apps.py
├── filters.py ※約1000行
├── helpers
│ ├── analysis_helpers.py ※約2000行
│ ├── api_helpers.py
│ └── continuation_helpers.py
├── models.py ※約1000行
├── querysets.py ※約2000行
├── serializers.py ※約1000行
├── summary.py ※約1500行
├── urls.py
├── utils.py
└── views.py ※約2000行
よかった点
- マスタ管理サブシステムのCRUDとDRFは相性はよく、早く効率的に開発ができていた。
改善すべき点、考慮事項など
- 予算編成サブシステムをこの構成で運用するのは無理が出てきていた。
- 自治体の予算編成という複雑な業務を上記登場人物だけで表現しきれない。
- 表現しきれない中での並行開発。コーディング規約も整えられていなかった結果、アプリケーションロジックや重要な業務ルールがview, serializer, model, helper, querysetに点在していた。
- 各登場人物を1ファイルで管理していたため、各ファイルが数千行のファイルになり、読み解きにくい。
- 型ヒントの不足やdictでのやり取りなどでインターフェース定義が弱く、読み解きにくい。
- スキーマ駆動開発が難しい。DRFのSerializerはOpenAPI(OpenAIじゃないよ)で定義したAPI定義からコード生成するツールがない。取り決めたAPI定義との乖離はよくある状態になっていた。
先行リリースから1年間
責務の整理方針が決まる
リリース後の保守と追加開発の中で、可読性と変更容易性の面で、現在のロジック点在の問題が喫緊の課題となります。そういった経緯から、自然と責務の整理が始まりました。
やったこと
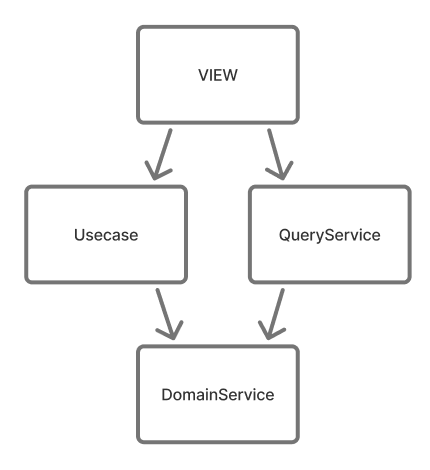
usecaseやserviceを増やし、複雑なアプリケーションロジックを整理していく方針に。
- view:serializerとusecaseを呼び出す担当。
- usecase:アプリケーションロジックを記載する担当(書き込み系)。
- queryservice:アプリケーションロジックを記載する担当(読み込み系)。
- domainservice:usecaseをまたがるような共通処理(業務ルールなど)を記載する担当。
※usecase, queryservice, domainserviceはクラス単位でファイルを分割する
既存のコードベースは実装前に可能な範囲でこの方針に変更。
新規のコードベースはこの方針で書いていく。
よかった点
- 担当分けすることで自然とSLAP(抽象度統一の原則)が満たされ、読む際も実装時も特定の関心事に集中できるようになった。
- これまでだと、querysetなどに記載されるものがqueryserviceなどに移っていき、コードも追いやすくなっていった(querysetの関数はIDEで関数定義にジャンプできないため開発者体験がよくなかった)。
改善すべき点、考慮事項など
- 方針の遵守度合いはまちまち。浸透していくには時間もかかった(数ヶ月程度)。
- 並行チーム開発を続けていたので、そのチーム間で差が出た形だった。
ファイル分割と型チェック導入
責務が決まり読みやすくなっていくと、各責務内での読みやすさと情報の受け渡しの質を改善していきたいと思うようになりました。ファイル分割とmypy導入の機運です。
やったこと
- 1000行超えのview, serializer, modelをファイル分割。
- 型ヒントの記載と、型チェック(mypy)の導入。
- 構造体はdictでのやり取りではなく Pydanticを利用するようにした。


よかった点
- ファイル分割することで見やすくなった(単純だけど、重要)。
- mypyチェックにより、勿体無いバグが生じにくくなった(特にnullableな値かどうかで指摘されることは多い)。
- Pydanticを介することで、型が厳密に保証されている&IDEの補完の効く形でデータをやり取りできることの安心感を持てた。
改善すべき点、考慮事項など
- クラス単位でファイル分割しようとしたが、密に依存しているクラスも一部あった。そういったものはそういう密な関係なのだとして捉え、無理に分割せずに1ファイルにまとめておくことにした。
DRFを薄く使う(SerializerからPydanticへ)
ここまでの取り組みで変化に強い構造になってきました。
新規参画者にとっても驚きが少なく、すんなり読める構造になってきた気はするのですが、まだDRFはキャッチアップコストが高い印象を何となく持っていました。それは何なのかをモヤモヤ考えた結果、「柔軟であるがゆえに複雑なSerializerがDRFのキャッチアップコストの高さのもとになっている」という見解に至ります。
Serializerへのリスペクト
DRFはPythonに型ヒントが入る以前からAPI開発を支えてきました。
型のない時代に、入力/出力の構造定義とバリデーションを行い、結果をvalidated_data(dict) で扱えるようにする設計は、当時として画期的だったと推察します。
いま私たちがPydanticを選ぶことは、型ヒント前提のエコシステムが成熟した現在の要件に合うからであって、Serializerの価値を否定するものではありません。歴史的背景と要件の変化に応じた最適化という位置づけです。
やったこと
- APIリクエスト、レスポンスの型にSerializerではなくPydanticを使う。
- 以下のような思考の流れで思いつき、提案して決まった。
- Serializerは本当に色々なことができる(できすぎる)が、責務も分けていったのでそのほとんどを使わなくなっていた。
- -> それであればもういっそバリデーション(とAPI定義)としてだけ使おう。
- -> それであればPydanticでいいじゃん。
- DRFからAPI定義を生成する drf-spectacularも0.27.0からPydanticを公式サポートしてます。もう、しない理由はないです。
- 以下のような思考の流れで思いつき、提案して決まった。
よかった点
- Serializerが扱えるのはvalidated_dataというdict型なのも課題だったが、Pydanticで解消。
- ModelSerializerを使うことで余計なレスポンスも少しあったが、そういうのがなくなってきた。
- Serializerがよしなに色々してくれることを全部取っ払ったため、自身のアプリケーションコードでDRFの学習なしにアプリケーションコードを読める、書けるようになった。
改善すべき点、考慮事項など
- これまでの責務分けの取り組みなども相まって、Serializerの複雑な機能を使っていた部分はほぼ置き換えられたが、まだ、既存コードでSerializerを使っているものは多く残っている状態。
2025-09までの半年間
一部appsでのDDD導入
業務理解が深まるにつれ、現在の延長では対応が難しいサブシステムが見つかりました。
そして、そのサブシステムの再構築PJが始動しました。
そのサブシステムでは、複雑な業務ルールと階層化された業務モデルが必要になるため、それらを集約するドメイン層を作るDDD(ドメイン駆動設計)的アプローチで変化に強いものを目指しました。
やったこと
- 該当のサブシステムでは、presentation/usecase/domain/infraの4レイヤーによるオニオンアーキテクチャで実装。
- WebAPI的な関心事(DRF関連のあれこれ)はpresentation層に、DjangoのORMのようなDBの関心事などはinfra層に閉じ込めた。
- 業務ルールはdomain層に。この層やusecase層はDjangoの制約を受けない形で実装した。
- DDDの文脈での、集約やRepository, CQRSなどを使って実装。
- 重要なフィールドはValueObjectとして定義し、そこに業務ルールを内包させた。

よかった点
- ドメインモデルに業務ルールが集まり、全体の見通しがよくなった。
- 開発チームでDDDの輪読会が行われるなど、変化に強いコードをチーム全体で改めて考えるきっかけになった。
改善すべき点、考慮事項など
※執筆時点でまだ道半ばなので、考えが変わるかもしれません。あくまで現時点の所感です。
- コンストラクタDI(依存性注入)もやったが、ここまでしなくてもよかったかも。
- 引数なしのコンストラクタで直接他の層の情報をnewしてもよかったかも。
- Pythonはこの形でもMockできるので、オニオンアーキテクチャの文脈でDIする必要はないかも。
- 依存性を逆転させてまで usecase -> domain <- infra にする必要はなかったかも。
- 依存性逆転を実現するためのインターフェース定義や、IDEでインターフェースの実装先にコードジャンプできない(Pythonならでは)のは、トレードオフとして適切かは後で振り返りたい。
- domain層に配置していたrepositoryのインターフェースは廃止して、infra層にだけ配置するような割り切り(以下のような依存関係)もありかもしれない。
- usecase->domain(ドメインモデルを使うための依存)
- infra->domain(ドメインモデルを使うための依存)
- usecase->infra(repositoryを使うための依存)
DjangoNinjaとSchemaコード生成の試験的導入
PydanticでAPIのリクエストレスポンスを定義し始めたことでOpenAPIで記載したAPI定義からSchema定義をコード生成できることに気づきました。また同じく、DRFに依存する部分がほぼなくなったことにも気づきました。
そこでDjango Ninjaと、リクエストレスポンス定義のコード生成(datamodel-code-generator)を試験的に導入することにしました。
Django NinjaはDjango向けの高速なAPI開発フレームワークです。FastAPIの思想を取り入れつつ Django ORMと親和性が高いことが特徴です。
これまでのコード資産をそのまま使える、かつ、DRFに比べ定型的なコード(ボイラープレート)が少なく、直感的でわかりやすいものだと感じます。

まだ道半ばなので、DjangoNinja導入の振り返りは避けますが、少なくとも2025年10月現在、DRFとDjangoNinjaを共存して開発できています。コード生成も相まって実装時の煩わしさが少なくなっており、自分としてはかなりの好感触です。今後が楽しみです。
おわりに
プロダクト成長の裏で進んでいるコードのビルド&スクラップの生々しい歴史を記載してみました。
本記事では書ききれなかった小さな改善や失敗もいくつもあります。
お気づきの方もいるかもしれませんが、変更頻度の低いサブシステムは、まだ改善途中のため、サブシステムごとにコーディングスタイルが異なるようなことも起きているのが実情です。それも今後の課題ですね。
「早い・安い・旨い」プロダクト開発のために、「早く失敗・安く失敗・賢く失敗」、そして『許可より謝罪』をモットーに日々精進しています。本記事が、同じように悩みながらプロダクトを育てている方の参考になれば幸いです。

Discussion