AWS CDKとPrismaで実現するデプロイ時のDBマイグレーション
皆さんはRDBのマイグレーションはどのように実行されていますでしょうか?
手動で実行していますか?CIに組み込んでいますか?
戦略や重要視している指標次第では手動による完全なタイミング制御が必要な場合もありますし、ヒューマンミスを排除したい環境では継続的インテグレーションによる自動化を求めていると思います。
今回はそんなマイグレーションの仕組みをIaCであるAWS CDKに組み込み、Prismaによるマイグレーション自体をインフラストラクチャの一部として定義してみました。
何が嬉しいのか
この仕組みにすると嬉しいことがいくつかあるので紹介していきます。
CIサービスの実行に依存しない👍
CodeBuildやGitHub ActionのようなCIサービス上でマイグレーションを実行する場合、マイグレーション処理とIaCのデプロイタイミングにズレが生じることになります。例えば、個人のサンドボックス環境のような環境へお試しでデプロイしたい場合で考えます。ローカルから手動でIaCによるデプロイを実施する場合、デプロイ後にDBへ接続できる環境からマイグレーションを実行する必要があり、IaCで展開したにも関わらず手動作業が発生するためヒューマンミスの原因となる可能性があります。また、運用の仕組みと同様にCIサービスからデプロイする場合は検証したい変更をいちいちコミットする必要があります。
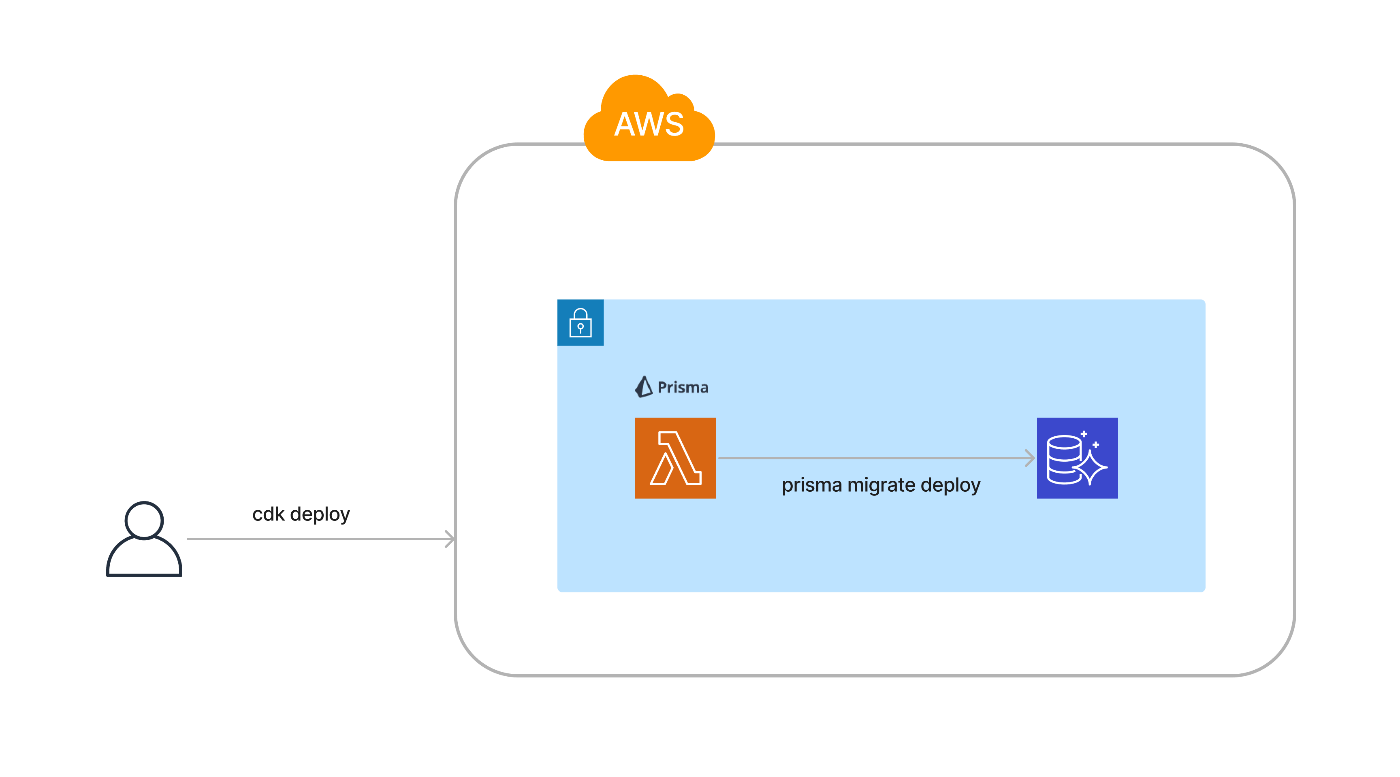
今回紹介する構成の場合、AWS CDKのデプロイの一部として実行されるためcdk deployコマンドさえ実行できればAWS環境と共に最新のRDBのテーブル構造も手に入るようになります。
CIサーバーのネットワーク構成が簡素化できる👍
また比較しますが、CodeBuildやGitHub ActionのようなCIサービス上でマイグレーションを実行する場合、CIサーバーをDBの存在するVPCに設置したりしてDBに対してネットワーク経路を確保すると思います。利便性のために外部から直接DBへ接続できる仕組みにすることはないでしょう。
今回紹介する構成の場合、VPC内に設置したLambdaでマイグレーションするためCIサーバーのネットワーク構成に悩まされることもなくなります。
CloudFormationのロールバック機能を享受できる👍
これも素敵ですね。
もしマイグレーションに失敗した場合、CIサーバーでインフラストラクチャ環境をロールバックする仕組みを考える必要があります。
今回紹介する構成の場合、CloudFormationの一部として定義されるためマイグレーションに失敗するとUPDATE_FAILEDステータスとなりAWS構成をデプロイ前の状態にロールバックしてくれます。
実践
やってみましょう。次の環境で実施します。
| 項目 | バージョン |
|---|---|
| Node.js | v18.0.0 |
| AWS CDK | v2.27.0 |
| Prisma | v3.15.1 |
| MySQL | v8.0.25 |
セットアップ
すぐに試せるプロジェクトをGitHubに公開してあるためコードをクローンしてきてください。
git clone https://github.com/WinterYukky/cdk-prisma-auto-migrate-example.git
また、プロジェクト内にRemote Container用の設定ファイルを用意しておきました。VSCodeのRemote Container拡張機能が利用できる場合はDBと言語環境を含めてReopen in Containerで環境が一発で手に入ります。
環境が開けたら次のコマンドでパッケージを取得します。
yarn install
Prismaの初期スキーマは次のようになっています。
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
title String @db.VarChar(255)
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
}
model Profile {
id Int @id @default(autoincrement())
bio String?
user User @relation(fields: [userId], references: [id])
userId Int @unique
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
birthday DateTime?
posts Post[]
profile Profile?
}
スキーマを確認したところでローカルのDBに対してPrismaのマイグレーションを実行します。
yarn prisma migrate dev --name first

マイグレーションに成功するとprismaフォルダへ次のSQLが保存されます。
-- CreateTable
CREATE TABLE `Post` (
`id` INTEGER NOT NULL AUTO_INCREMENT,
`createdAt` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
`updatedAt` DATETIME(3) NOT NULL,
`title` VARCHAR(255) NOT NULL,
`content` VARCHAR(191) NULL,
`published` BOOLEAN NOT NULL DEFAULT false,
`authorId` INTEGER NOT NULL,
PRIMARY KEY (`id`)
) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- CreateTable
CREATE TABLE `Profile` (
`id` INTEGER NOT NULL AUTO_INCREMENT,
`bio` VARCHAR(191) NULL,
`userId` INTEGER NOT NULL,
UNIQUE INDEX `Profile_userId_key`(`userId`),
PRIMARY KEY (`id`)
) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- CreateTable
CREATE TABLE `User` (
`id` INTEGER NOT NULL AUTO_INCREMENT,
`email` VARCHAR(191) NOT NULL,
`name` VARCHAR(191) NULL,
`birthday` DATETIME(3) NULL,
UNIQUE INDEX `User_email_key`(`email`),
PRIMARY KEY (`id`)
) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- AddForeignKey
ALTER TABLE `Post` ADD CONSTRAINT `Post_authorId_fkey` FOREIGN KEY (`authorId`) REFERENCES `User`(`id`) ON DELETE RESTRICT ON UPDATE CASCADE;
-- AddForeignKey
ALTER TABLE `Profile` ADD CONSTRAINT `Profile_userId_fkey` FOREIGN KEY (`userId`) REFERENCES `User`(`id`) ON DELETE RESTRICT ON UPDATE CASCADE;
デプロイ(1回目)
次のコマンドでデプロイします。 ※AWSのプロファイル設定はしておいてください。
yarn cdk deploy
デプロイ完了後にクエリエディタでテーブルを確認してみると、Prismaのマイグレーションによってテーブルが作成されていることが分かります。
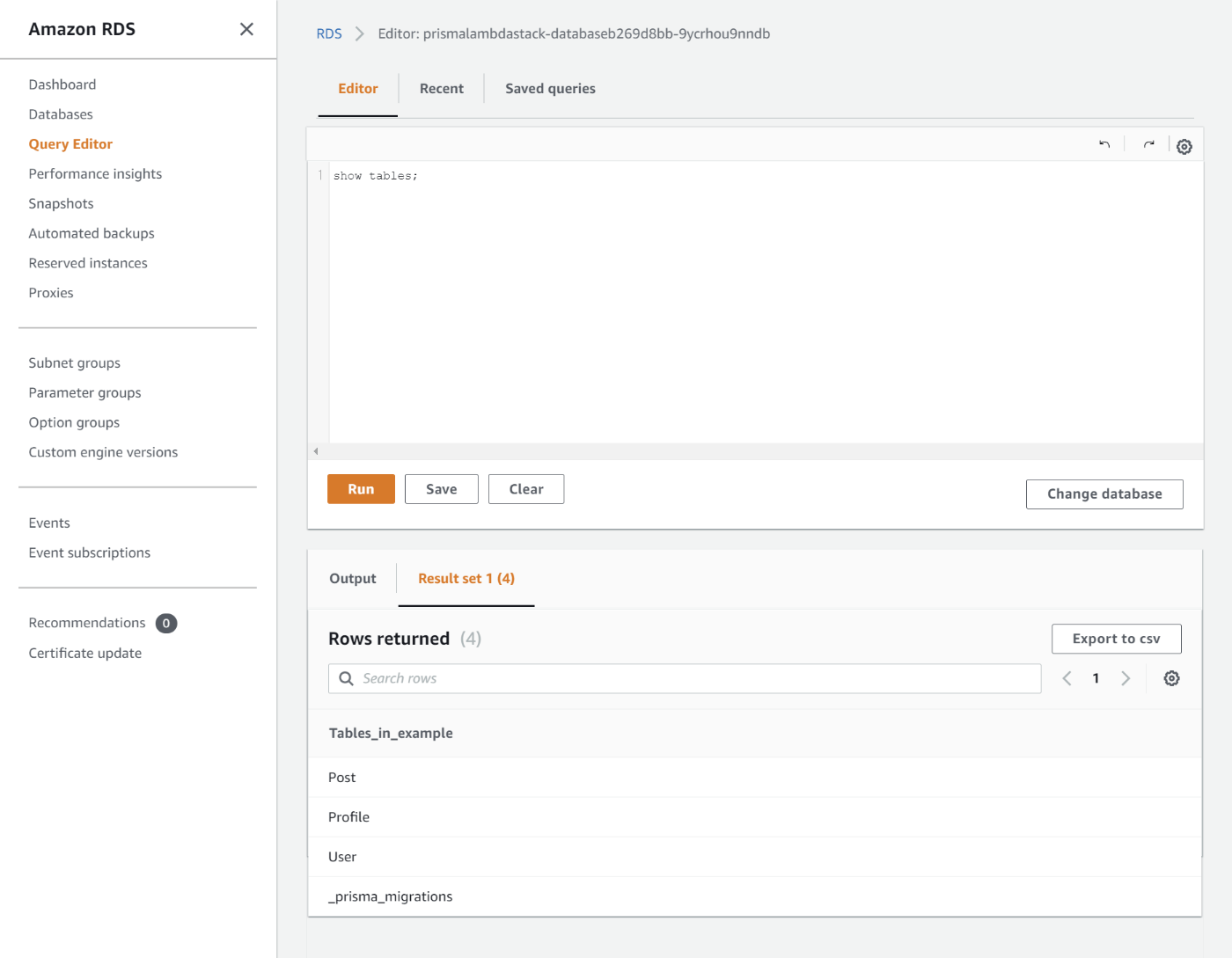
この後にUserテーブルの構造を変更する予定のためテーブル構造を確認しておきます。
スキーマ変更
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
title String @db.VarChar(255)
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
}
model Profile {
id Int @id @default(autoincrement())
bio String?
user User @relation(fields: [userId], references: [id])
userId Int @unique
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
+ gender String?
- birthday DateTime?
posts Post[]
profile Profile?
}
スキーマを変更後、ローカルのDBに対してPrismaのマイグレーションを再度実行します。
yarn prisma migrate dev --name second

prismaフォルダへ次のSQLが作成されます。
/*
Warnings:
- You are about to drop the column `birthday` on the `User` table. All the data in the column will be lost.
*/
-- AlterTable
ALTER TABLE `User` DROP COLUMN `birthday`,
ADD COLUMN `gender` VARCHAR(191) NULL;
デプロイ(2回目)
次のコマンドで再度デプロイします。
yarn cdk deploy
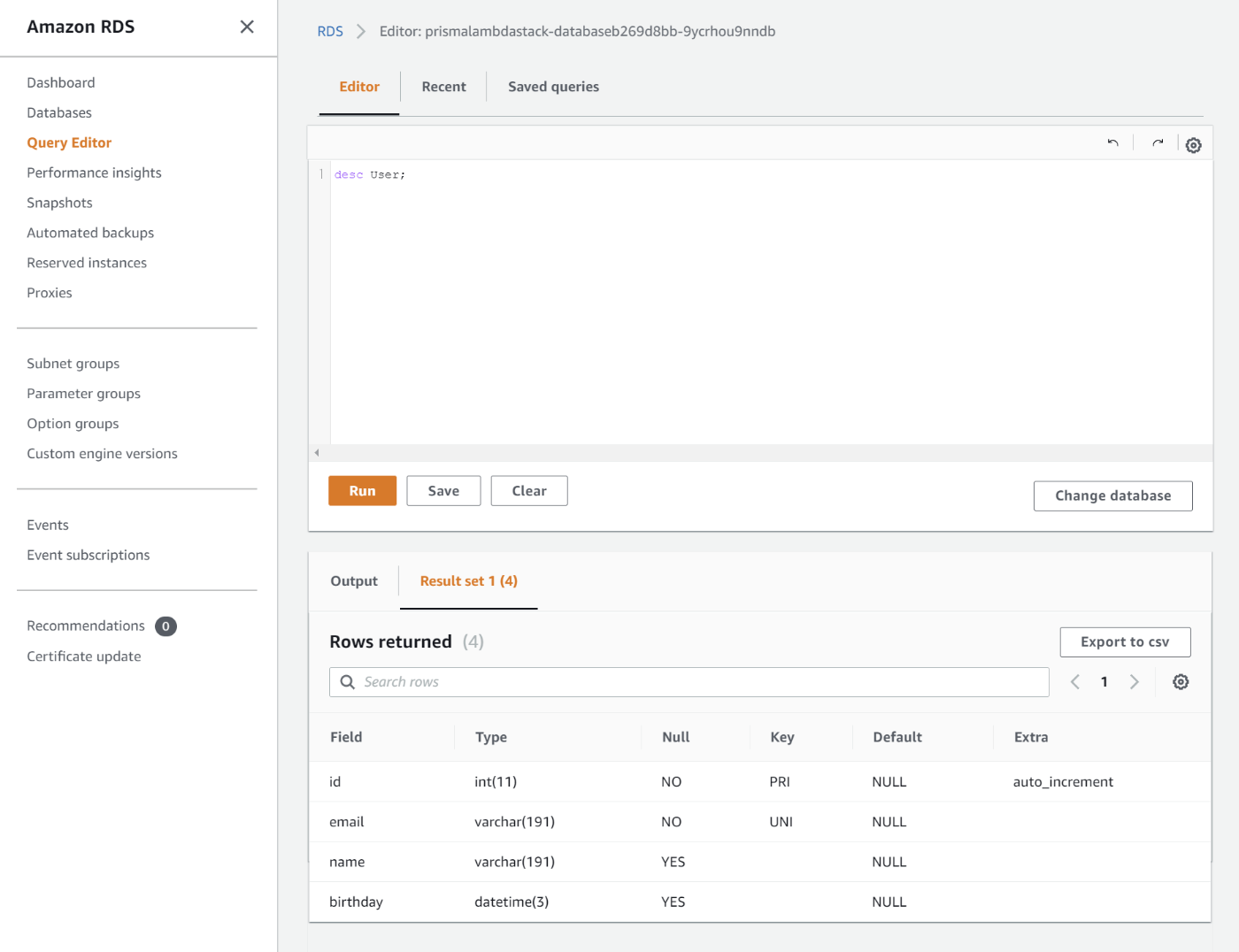
デプロイ完了後にクエリエディタでUserテーブルの構造を確認してみると、Prismaのマイグレーションによってテーブルが更新されていることが分かります。

以上で実践は終了となります。
実装のポイント
PrismaのマイグレーションをCDK内で行う方法
これにはカスタムリソースを利用します。
カスタムリソースとはAWS CDKがバックグラウンドで利用しているCloudFormationの機能の1つです。カスタムリソースを用いることでCloudFormationで管理できないリソースをLambdaやSNSで管理することが可能です。
なお、CDK内ではカスタムリソースを簡単に定義できるようにProviderというクラスが用意されており、実際に次の記述だけでマイグレーション関数を定義できています。
Prismaのスキーマ変更時のみマイグレーションを実行する方法
カスタムリソースはカスタムリソースに割り当てられたpropertiesに変更がない限り再度実行されることはありません。この仕組みを利用してPrismaによって発行されるマイグレーションフォルダの名称をアルファベットの降順で取得し、最後のフォルダ名をpropertiesに渡すことで変更があった時のみに実行という要件を満たしています。
さいごに
CDKを利用することでかなり簡単に実装することができました。
RDBのマイグレーションは規模が大きくなってくると時間がかかってしまうためLambdaの特性上15分以上かかる場合は利用できないように思えますが、CDKではこれをカバーしていて15分以上かかる処理は非同期プロバイダーを利用して実装することで15分の壁を取り除いてくれます。
こんな自由なことができるのはCDKだからこそですね。
皆さんも是非CDKをすこってください。
参考
Discussion